随机森林法对北京移动用户体验影响因素研究
2024-05-18黄霜聆康湖滨
黄霜聆,谢 健,李 荣,康湖滨
(广东东软学院信息管理与工程学院,广东佛山)
引言
由于移动通信技术的飞速发展,人们越来越离不开移动通信技术带来的便捷。这导致各个移动运营商越来越重视客户的网络使用体验。据统计,北京移动用户体验影响因素主要有语音业务和上网业务,影响语音业务和上网的业务还有其他因素。因此客户满意度成为了体现各大运营商市场运营状况的重要体现。根据客户投诉,对影响用户体验的问题进行解决,是提升客户满意度的方法。本次研究需要拟通过分析影响用户满意度的各种因素,为决策提供依据,从而实现更早、更全面提升用户满意度,中国移动通信集团北京公司采用不同办法对用户的体验影响因素进行研究。
1 数据来源
本文的数据来源主要是MathorCup 高校数学建模比赛中北京移动用户体验影响因素研究问题的数据。样本包含了4 个附件,对于语音业务用户满意度而言有54 个,对于上网业务满意度有124 个;对于语音业务用户满意度预测值有43 个,对于上网业务用户满意度预测值有86 个。根据数据整理出相关特征数据如表1 所示。

表1 移动用户体验影响因素相关特征数据
2 数据预处理
为了使模型有较高的精确度并且确保结果的准确率高,对数据进行预处理:对数据进行探索进行缺失值和异常值的查看;进行特征编码、标签编码、独热编码、特征的删除、异常值处理、缺失值处理;利用Python 内置函数查看缺失值。对于语音业务用户满意度有脱网次数、当月MOU 等。对于上网业务用户满意度有爱奇艺、梦幻西游等;利用最值归一化和均值方差归一化对数据进行异常值处理;利用零值填充和KNN 模型对数据进行缺失值处理。
3 模型建立与求解
3.1 基于随机森林对影响因素进行打分
随机森林[1]具有很高的预测准确率,对异常值和噪声有很强的容忍度,能够处理高维数据,有效地分析非线性、具有共线性和交互作用的数据,能够在分析数据的同时给出变量重要性评分。使用斯皮尔曼相关性分析影响语音业务和上网业务的主要因素,建立随机森林模型求解出最终结果。
3.1.1 斯皮尔曼相关性分析
斯皮尔曼是衡量两个变量的依赖性的无母数指标。利用单调方程评价两个统计变量的相关性。若数据中没有重复值,且当两变量完全单调相关时,斯皮尔曼相关系数为+1 或-1。因此,设n 为样本数量,f 为数据x和y之间的等级差。fi为第i个数据对的位次值之差,ρ为相关系数。因此可以建立如下模型:
3.1.2 基于随机森林对重要因素打分
设VIM 为变量重要性评分,Gini 指数用GI 来表示,假设有m 个特征a1,a2,a3,……,ac,现在要计算出每个特征aj的指数评分V,即第j 个特征在RF 所有决策树中节点分裂不纯度的平均改变量[2]。随机森林分类器原理示意图如图1 所示。

图1 随机森林分类器原理示意图
首先需要对Gini 指数进行计算,就是从节点m 中随机抽取两个样本,其类别标记不一致的概率,设k为有k 个类别,pmk表示节点m 中类别k 所占的比例。因此可以建立如下模型:

如果,特征aj在决策树中出现的节点在集合M中,那么可以计算aj在第i 棵树的重要性。设特征为aj,具体模型如下:
如果,在RF 中有n 棵树,那么模型会变为:
最后,把所求的的重要性评分做一个归一化处理,具体模型如下:
3.1.3 因变量与自变量
根据对以上模型建立与求解,得到语音业务和上网业务的对应因变量影响排序。对于语音业务而言,可以将语音通话整体满意度、网络覆盖与信号强度、语音通话稳定性和语音话清晰度看做因变量,其余看做自变。对于上网业务而言,将上网整体满意度、网络覆盖与信号强度、手机上网速度和手机上网稳定性看做因变量,其余看做自变量。使用随机森林模型[4]对其进行重要性特征排序,得到结果语音业务中通话中有杂音、听不清、断断续续,等影响因素重要性较高。上网业务中网络信号差/没有信号,重定向次数等影响因素重要性较高。
3.2 基于随机森林对结果进行预测
利用随机森林进行结果预测,是通过投票得出最终结果。在此过程中会对数据集进行随机抽样,因此进行平衡数据集。针对于平衡数据集而言,采用的方法有上采样、下采样和混合采样。为了提高模型和最终结果的精确度,对参数进行调参,提高精确度。得到最终结果。
3.2.1 利用随机森林进行结果预测
通过对模型进行比较,选择随机森林模型对结果进行预测[3],随机森林算法采用Boot-strap 重抽样技术从原始数据集随机抽样,构成n 个不同的样本数据集,根据这些数据集搭建n 个不同决策树模型,根据这些决策树模型的平均值(针对回归模型)或者投票情况(针对分类模型)获取最终结果。
3.2.2 平衡数据集
通过对语音业务中的语音通话整体满意度,网络覆盖与信号强度,语音通话稳定性,语音通话清晰度;上网业务中的上网整体满意度,网络覆盖与信号强度,手机上网速度和手机上网稳定性的数据集进行观察,发现数据不平衡。针对于语音通话整体满意度而言,观察到有1~10 的评分,对其进行分类处理,并且统计出各评分的占比,具体如图2 所示。
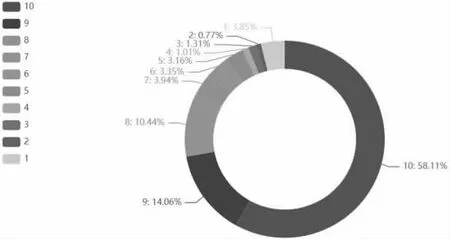
图2 语音通话整体满意度评分占比
对图进行观察,发现评分为10 的占比为58.11%超过了50%,最小的为评分2,只有0.77%,得到评分不平衡的结论,进行平衡数据集。采用基于上采样、下采样和混合采样的方法比较出最优平衡数据集的方法。通过以上方法的采用,导入平衡数据集的模型,得到了八个因变量对应的最好平衡数据集的方法,得到每个因变量使用的方法以及方法精度。
一共使用三种平衡数据集的方法,分别为Neighbourhood Cleaning Rule,Edited Nearest Neighbours和Repeated Edited Nearest Neighbours。第一种方法使用3 个最近邻删除不符合此规则的样本。第二种方法应用最近邻算法,通过删除与邻域“不够一致”的样本来“编辑”数据集。第三种方法是Edited Nearest Neighbours 的扩展,通过多次重复该算法形成Edited Nearest Neighbours。
这里选取了语音通话整体满意度为例。通过三个平衡数据集的方法进行比较后,选择了精度较高的Neighbourhood Cleaning Rule 方法。得到平衡数据集过后的1~10 的评分占比都变成10%。
3.2.3 模型调参
为了提高模型的精度以及预测结果的精度,对八个因变量使用的模型利用网格搜索法进行模型调参。网络搜索方法主要用于模型调参,帮助找到一组最合适的模型设置参数,使得模型的预测值达到更好的效果,通过交叉验证的方法去寻找最优的模型参数。
对于语音通话整体满意度而言,首先制定一个参数。随后对其进行训练,得到了第二个参数max_depth为10。再对其进行训练,得到第三个参数min_samples_split 为2。最后对第三个参数进行训练,得到第四个参数max_features 为0.2。表明一共有四个参数。得到模型交叉验证过后精度。
3.2.4 结果
通过平衡数据集,模型调参提高精度模型精确度为89%,得到最终预测结果,结果如表2 所示。
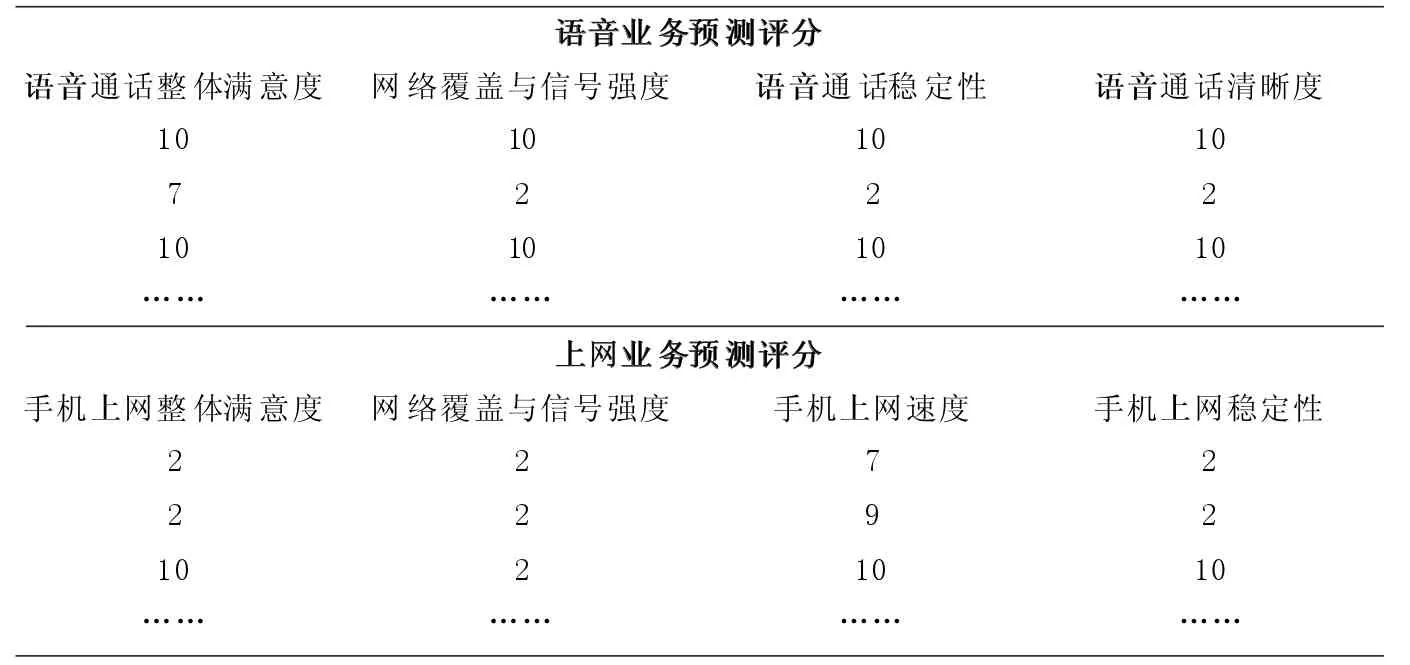
表2 语音业务预测评分和上网业务预测评分
4 结论
基于随机森林模型对影响因素进行打分和结果预测,帮助北京移动公司更好分析出影响用户语音通话满意度和上网业务满意度的主要影响因素,可以让北京移动公司以后更加着重于这方面从而提高用户的体验度。此方法同时对当代社会手机的发展有比较大的影响作用。手机公司可以通过此模型进行语音和上网业务的改进,提高用户满意度和提升自己的业绩。
