基于Simhash 算法的题库查重系统的设计与实现
2024-05-18熊良钰邓伦丹
熊良钰,邓伦丹*
(南昌大学科学技术学院,江西共青城)
引言
随着互联网技术的发展和普及,在线教育和在线学习已经成为一种必然趋势。利用数据算法进行智能化计算来满足一些教育应用场景也越来越普遍。国内各种线上教学平台也在不断满足新的个性化的线上学习和教学的需求[12]。
在这些平台上,题库是重要学习资源之一。然而随着题库规模的不断扩大,题目的重复或相似问题日益突出。这些重复或相似的题目不仅会浪费存储空间,还会给教师带来教学困扰;给学生的练习带来误导,影响做题效率。尤其是在线教育平台和考试机构需要保证题目的独特性和原创性的情况下,开发基于文本相似度的理论研究的一种高效准确的题库查重系统对于题库管理和优化具有重要意义。
目前已经有一些题库查重方法被提出,比如基于文本相似度计算[4]、基于词向量的方法[4]等。但是基于文本相似度计算的方法需要对文本进行较复杂的处理和计算,耗时较长;基于词向量的方法对于长文本的处理效果不佳。为此,本研究提出了一种基于Simhash 算法的查重系统[1-3]设计。
Simhash 算法通过哈希函数和位运算提高了处理大规模题库的效率。它能迅速生成题目的哈希值并进行比较,不仅能检测完全相同的题目,还能识别相似或近似语义的题目。通过设定阈值将相似度高于此阈值的题目判定为重复。
综上所述,本系统将极大地提升用户在查找相似题目时的效率。系统设计与实施将涉及分词处理、哈希加权、数据合并、降维处理,以及文本相似度评估等多个技术步骤的细致开发。同时,将利用jieba 分词工具[9]、sklearn 库[9]、Flask 后端框架[4]、streamlit 框架以及html 等技术构建一个题库系统。
1 系统设计
1.1 算法设计
相对于MD5[10]和SHA-1 哈希算法,Simhash 算法[11]的哈希值碰撞概率极低,同时比Minhash 算法具有更低的哈希冲突率和更好的性能,而且还具有局部敏感性。具体来说,相似的文本在Simhash 值中具有较高的相似比特位,这使得Simhash 算法对于处理文本中的局部变化[13]具有一定的容忍能力。因此,它是本项目的最优选择。Simhash 算法的基本原理包括分词和文本特征[13]提取、特征加权、哈希、指纹生成以及相似度计算这五个步骤[9]。
首先,我们使用jieba 分词工具对输入的题目进行分词处理。在实际操作中我们还能根据不同科目的需求手动添加专业领域的词汇以提高分词准确性。将语句分词完成后我们需要去除一些对文本特征基本没有意义的停用词[8]。对分词结果用我们先使用Python 中的NLTK[9]去除停用词。之后再采用TF-IDF方法[11]来提取文本特征。
TF(词频)指的是一个词在文本中出现的频率。计算某个词的TF 值[5]可以使用以下公式:
式中:Vt为词t 在文本中出现的次数;D 为文本中的总词数。
IDF(逆文档频率)指的是一个词在整个文本集合中的重要程度。计算某个词的IDF 值[5]可以使用以下公式:
式中:O 为文本集合的总文档数;Ot为包含词t 的文档数;在计算IDF 时,分母中加1 是为了避免当某个词在所有文档中都出现时,分母为0 导致的除零错误。加1 的作用是平滑处理,确保即使某个词在所有文档中都出现,它的IDF 值也不会变为无穷大。
TF-IDF 用于衡量一个词在文本中的重要性。计算某个词的TF-IDF 值可以使用以下公式:
式(3)是将式(1)和式(2)的TF 和IDF 进行相乘运算。
TF-IDF 的思想是,如果一个词在某篇文本中出现的频率较高(TF 较大),同时在整个文本集合中出现的频率较低(IDF 较大),那么这个词对于该篇文本的区分度较高,被认为是重要的词。基于TF-IDF 方法我们对TF-IDF 值进行归一化处理,将TF-IDF 值映射到[0,1]内。最大- 最小归一化的计算公式如下:
式中:X 为原始值;Y 是归一化后的值;Xmin和Xmax分别为原始数据的最小值和最大值。
对于题库查重文本生成hash 值这一步我们应当选取适合的哈希函数。这个哈希函数应该满足生成的哈希值应该有较低的碰撞率,即不同的文本应该生成不同的哈希值以确保查重的准确性。还要能够在短时间内对文本进行哈希计算,尤其是针对大规模的题库,需要保证计算效率。哈希值还应该具有均匀的分布特性,以便在哈希表等数据结构中减少冲突,提高查重的效率。
基于这些需要,开源的MurmurHash 系列哈希函数是一个很好的选择。其中MurmurHash3 相对于前两个版本在设计上考虑了更好的碰撞率,减少了哈希冲突的可能性,提高了哈希算法的稳定性并且还进行了一些安全性方面的改进。它在处理大规模数据时具有更好的性能,适合于我们的数据处理需求。其生成哈希值时具有更均匀的分布特性,有助于减少哈希表等数据结构中的冲突。并且支持几种不同的输出位长度,如32 位或128 位。所以我们选择它作为算法中生成哈希值的哈希函数。
接着,对于每个哈希值的每个位(比特),根据高位或低位的位置来分配不同的权重,然后将每个位的哈希值乘以相应的权重。最后将所有位的加权哈希值相加,得到最终的Simhash 值。为了降低维度方便计算比对,要对其进行降维处理。我们对Simhash 值的每个位进行特征选择,只选择对相似性判断有重要影响的位作为降维后的特征。在具体过程中对哈希值的每个位计算其对相似性判断的信息增益。信息增益通过熵和条件熵的计算来得到,用于衡量每个位对于相似性判断的重要性。根据计算得到的信息增益,选择信息增益高的位作为降维后的特征。这些位对于相似性判断有重要影响,因此可以作为降维后的特征进行保留。根据选择的信息增益高的位,构建降维后的Simhash 值。
其中信息熵的计算公式如下:
式中:D 为总样本数;Pi是样本属于第i 个类别的概率。
条件熵的计算公式如下:
式中:Pi是样本属于第i 个类别的概率;Ci是集合中第i 个类别的样本个数。
条件熵的计算公式如下:
式中:v 为属性A 的取值个数;Dv为选出属性A 取值为v 样本集合。
信息增益的计算公式如下:
式中:Gain(D,A)为信息增益;H(D)为信息熵;H(D|A)为条件熵。
最终我们选取前128 位的Simhash 值[5]为题目文本的固定指纹。如果题目文本的hash 值无法达到128位就不断在后位补0 直至达到128 位。最后,对比不同文本的Simhash 指纹[8],通过计算汉明距离[12]来衡量它们之间的相似度。
对于两个等长的字符串A 和B,其中每个字符串的长度为n,汉明距离[6]可以通过以下公式计算:
式中:D 表示汉明距离最终数值;A[i]表示字符串A 中的第i 个字符;B[i]表示字符串B 中的第i 个字符;∑表示求和运算。公式中,当A[i]和B[i]不相等时,计数器加1,最终得到的计数器值即为D 汉明距离。汉明距离越大,表示两个字符串之间的差异越大。
1.2 数据库设计
根据本项目需求我们创建了students、teachers、subjects、questions、answers 五张数据表[7]。其中用户数据表包括学生和教师表,题库信息表包括了科目表、题目表和答案表。E-R 如图1 所示。
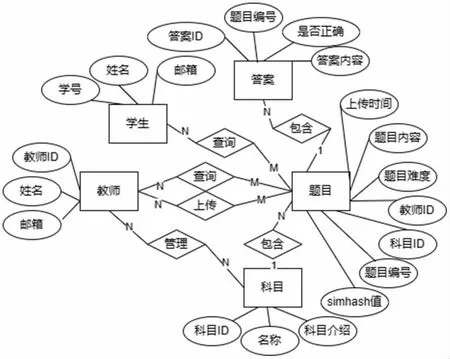
图1 系统E-R
2 系统展示与测试
2.1 功能展示
2.1.1 题目导入
用户可以通过系统提供的题目导入功能,将题目文本文件上传至系统。系统支持常见的文本文件格式上传,如.txt、.csv 还有word、excel 文档。用户可以选择单个文件或批量文件导入进行查重分析。
2.1.2 个性化配置
系统支持用户自定义的配置,包括相似度阈值设置添加科目和删除题目等。用户可以根据实际需求对系统自行设置以满足不同场景下的查重需求[7]。
2.2 系统界面
登录界面可供学生和老师进行注册的登录,使用html 结构和css 样式并且使用JavaScript 实现交互。
使用界面使用streamlit 实现。以教师使用界面为例用户可以增加和删除科目,并对科目进行上传题目文档操作。输入题目文本并选择科目可以进行查重并且显示查重结果。发现题目相似性较高时还能输入题目ID 进行删除操作。在题库查重时还能根据需要调整相似度阈值。
2.3 系统测试
为了验证基于Simhash 算法的题库查重系统的准确性,我们采用了人工构造测试数据和真实场景测试的方法。
我们构造了一批具有不同相似度的题目样本,包括完全相同的题目、部分相似的题目和完全不同的题目用于测试系统对不同相似度情况的识别和判断能力。我们根据测试的结果不断修改保证了系统算法在90%以上的正确率。此外还从校内的真实的题库中提取了一部分题目作为测试样本,用于测试系统在实际应用场景下的查重效果和性能表现。在测试中题库基本可以查询到类似题目并且显示结果。
3 项目评估与展望
本项目还能继续在算法设计的各个环节使用不同的方法技术并且结合其它的算法根据新的应用场景进行更加全面或者个性化的处理。在数据库设置上还能加上新的结果表将查询结果保存以便后续回顾查询记录。还可以进一步完善系统的查重报告展示,引入数据可视化技术,提供更直观、易懂的查重结果展示方式。能将系统应用拓展至更多领域,如学术领域的论文查重、知识产权领域的文本相似度分析等,为更多领域提供可靠的相似度分析解决方案。
结束语
基于Simhash 算法的题库查重系统是一种高效、准确的题目查重解决方案。通过Simhash 算法的相似度计算,系统能够快速、准确地识别题目之间的相似度,为用户提供可靠的查重结果。系统具有用户友好的界面设计和灵活的配置选项,为用户提供了便捷、高效的使用体验,为教育、考试等领域提供了有力的支持。
