涉海翻译中的机器翻译应用效能:基于BLEU、chrF++和BERTScore指标的综合评估
2024-05-15刘世界


摘 要:深度学习技术和生成式人工智能技术已在机器翻译领域引发质的变革,为该领域的进步开辟了新径。为综合评价不同技术和算法背景下的机器翻译在涉海领域的应用效能,构建涵盖100个代表性涉海例句的中英双语方向的测试集,基于涉海文本的语言结构特点选取BLEU、chrF++和BERTScore 3种自动评估指标,对人工智能助手ChatGPT(4.0)和文心一言(4.0),及Google Translate、Microsoft Translator、DeepL Translate、Tencent TranSmart、百度翻译和有道翻译等六大主流翻译引擎的译文进行定量定性评估。实验结果既为理解机器翻译系统在涉海领域的应用效能提供了实证支撑,又为机器翻译技术开发者提供了关于算法优化和翻译精度提升方面的见解,同时为涉海专业人士选择合适的翻译系统提供了实用指引。
关键词:涉海翻译;机器翻译应用效能;BERTScore;BLEU;chrF++
中图分类号: I305.9文献标识码:A文章编号:1672-335X(2024)02-0021-11
DOI:10.16497/j.cnki.1672-335X.202402003
机器翻译,尤其是随着深度学习的发展而兴起的神经机器翻译,已成为突破语言障碍、提高交流效率的关键。随着全球海洋经济的增长,特别是在涉海领域,对跨语言信息交流的高效、精确需求日增。尽管深度学习和生成式人工智能技术显著提升了机器翻译的质量与效率,但处理涉海文本仍具挑战。这类文本常含密集的专业术语、领域知识和复杂概念,翻译精确度和专业性要求较高。因此,评估机器翻译在此领域的应用效能,对推动技术进步和满足行业需求具有重要意义。
当前,机器翻译质量评估领域常用的评估指标包括BLEU[1]、METEOR[2]、chrF[3]、chrF++[4]、BERTScore[5]、COMET[6]和BLEURT[7]。这些指标从词汇准确性、语法流畅度以及语义保留等维度评估翻译质量,为不同领域中机器翻译的应用效能提供了量化评估基准。为此,本研究尝试构建中英双语的涉海领域测试集,选取包括大语言模型支持的人工智能助手ChatGPT(4.0)、文心一言(4.0)及其他六大主流翻译引擎作为评估对象(统称为“翻译系统”),针对涉海文本的独特语言结构,采用BLEU、chrF++和BERTScore三个自动化评估指标,旨在综合评估机器翻译在涉海领域的应用效能与局限。通过定量指标数据和定性案例分析,深入探讨翻译系统在处理专业术语、领域知识、复杂句式方面的能力,为机器翻译在涉海领域的应用提供新见解。
一、BLEU、chrF++和BERTScore评估指标
本部分将探讨与解析本研究所采用的三种评估指标——BLEU、chrF++和BERTScore。
BLEU(Bilingual Evaluation Understudy)由Papineni等人于2002年提出,它通过计算机器翻译输出与一组参考翻译之间的n-gram重叠来评估翻译的准确性。[1]BLEU的核心在于n-gram匹配,涉及1-gram到4-gram的匹配,并通过修正的精确度计算来避免过度惩罚短译文。由于其简单性和高效性,BLEU成为当前机器翻译评估的黄金标准,但它也因在翻译的语义准确性和流畅性方面缺乏敏感性而受到批评。[8]尽管如此,BLEU仍然被广泛用作机器翻译性能评估的指标之一,特别是在WMT(Workshop on Machine Translation)等国际机器翻译评测活动中。BLEU分数的范围是0到1,其中0表示完全不匹配,1表示完全匹配。在行业评估实践中,BLEU分数通常转换为百分制,以使得评估结果易于理解和比较,也方便非专业人士快速把握翻译系统的性能水平。
chrF++(Character n-gram F-score)是由Popovic′于2017年提出的機器翻译评估指标chrF的改进版本,它通过计算字符级的n-gram F-score来评估翻译质量,以此来补充基于词级别n-gram计算的传统评估方法(如BLEU)的不足。这种方法适用于处理语言结构差异大或非标准表达的语言,因为它能更细致地捕捉语言的微妙差异(如拼写、词形变化等)。[4]chrF++还引入了加权因子,以平衡不同长度n-gram的影响,从而提高评估的准确性和公平性。由于这些特点,chrF++已经被纳入WMT评测活动的评估指标体系中,作为补充BLEU和其他评估指标的一部分,帮助研究人员和开发者从多个角度评估和理解机器翻译系统的性能。
BERTScore由Zhang等人于2020年提出,是一种利用预训练的BERT模型计算候选翻译和参考句子之间语义相似度的评估指标。在研究中他们采用BERTScore及相关指标评估363个机器翻译和图像描述系统的输出,实验结果表明BERTScore与人类评价的相关性更好,鲁棒性更强,并且相比现有的评估指标,BERTScore提供了更强的模型选择性能。[5]BERTScore通过计算词嵌入之间的余弦相似度来评估翻译质量,为评估提供了基于语义的新视角,这使得BERTScore在处理同义词和复杂句子结构时能够更好地捕捉到翻译中的细微语义差异。具体计算过程如图1所示。
二、研究方法
(一)数据收集
在构建英译中(E2C)和中译英(C2E)两个方向的涉海翻译测试集(各50条例句)的过程中,采用严格的标准选取测试例句,确保测试集最大程度地覆盖涉海领域的关键概念、专业术语和主要场景。这些内容包括但不限于法律与政策(海事海洋法律法规、海事审判报告)、工程与技术(船舶工程、海洋工程)、环境与生态(海洋环境、海洋生物资源)、文化与社会(海洋文化、海洋史)、经济与发展(航运业发展)等。对于部分缺少参考译文的例句,邀请三位涉海领域专家讨论确立高质量参考译文,保证专业性和准确性。此外,为避免任何潜在的顺序效应(order effects),[9]测试集例句随机打乱编码,确保评估的客观性和公正性。
(二)系统/助手选取
本研究选取具有代表性的神经机器翻译系统和大语言模型支持的人工智能助手(翻译功能)进行评估,包括Google Translate(Google)、Microsoft Translator(Microsoft)、DeepL Translate(DeepL)、Tencent TranSmart(TranSmart)、百度翻译、有道翻译,以及人工智能助手ChatGPT(4.0)(GPT)和文心一言(4.0)(文心一言)。虽然ChatGPT(4.0)和文心一言(4.0)本质上不是专门设计用于机器翻译的系统,但它们作为大语言模型支持的人工智能助手,同样具备处理翻译任务的能力。选择这些系统和助手是基于它们的技术领先地位和广泛应用,以及它们在训练过程中使用的不同规模和领域的数据集,这些因素可以反映出各自的性能特点和应用差异。每个翻译系统或人工智能助手的背后,都是数十亿甚至数万亿个词汇的庞大训练数据集,覆盖广泛的主题和领域,适合作为工业界机器翻译技术的代表,评估机器翻译在涉海领域的应用效能和局限。在译文输出过程中,人工智能助手未使用结构化的提示词进行引导,所有机器译文输出时间均为2024年2月18日。
(三)实验参数
在计算BLEU指标评分时,在Python中采用jieba分词处理汉语译文(英文译文无需额外的分词处理),并调用NLTK库中的SmoothingFunction().method4作为BLEU得分计算的平滑方法,旨在解决当测试集中出现未在训练集中见过的n-gram时BLEU得分计算结果为零的问题。同时将n-gram权重等同设置(每个1-gram到4-gram的权重为0.25),这种权重分配方法符合BLEU评分中广泛认可和默认采用的标准实践。
在计算chrF++指标评分时,本研究遵循Popovic′于2017年所提出的方法[4]进行编程,调用sacreBLEU库中的CHRF模块对测试译文进行评分。在初始化CHRF对象的过程中,特别设置了几个关键参数,以确保评分体系既能反映词序与字符序的重要性,又能保证评分的稳定性和可靠性。具体而言,词序权重设为2,旨在适度惩罚译文中的词序错误,以体现词序在翻译质量中的作用;字符序权重则设为6,强调字符级别匹配的重要性,以捕捉翻译中的部分正确匹配情况;平滑因子beta设为2,目的是平衡精确率(precision)和召回率(recall),避免极端情况下的评分失衡。
BERTScore指标评分的计算涉及E2C和C2E两个方向的模型选择及参数设置。在E2C方向的BERTScore指标得分计算中,基于BERTScore库的默认设定,采纳预训练的bert-base-chinese模型处理中文译文。该模型作为专为中文文本设计的BERT模型版本,能够有效地揭示中文文本間的语义相似性,被认为是进行中文得分计算的理想工具。针对C2E方向的得分计算,则选用了microsoft/deberta-xlarge-mnli模型。DeBERTa模型(Decoding-enhanced BERT with disentangled attention)通过解耦注意力机制和增强解码功能,在文本理解及表达上超越标准BERT架构,而microsoft/deberta-xlarge-mnli作为一种扩展规模的DeBERTa模型,在多项自然语言理解(NLU)任务上的预训练背景赋予了其在处理英文文本时,特别是在解析英文中复杂的语义关系与识别句间隐含意义上的卓越性能。因此,通过指定microsoft/deberta-xlarge-mnli模型来执行C2E方向上的BERTScore指标计算,可确保研究获得更精细准确的语义相似度评估结果。
三、结果与讨论
(一)定量分析
1.BLEU和chrF++指标评分结果
对两个翻译方向的测试集进行BLEU及chrF++指标评估,具体得分结果整理成表1。通过表格数据的横向及纵向分析,初步观察到:(1)文心一言在E2C方向的BLEU指标及E2C和C2E两个方向的chrF++指标上表现良好;(2)TranSmart在E2C方向的chrF++指标得分显著;(3)有道翻译在C2E方向的BLEU得分较高,显示出其在中译英方面的优势;(4)GPT在两个翻译方向的BLEU和chrF++指标表现最差;(5)在chrF++指标评估中,C2E方向上的得分普遍高于E2C方向,这可能归因于英语作为目标语言时,翻译输出中字符级别的匹配和词序的正确性相对更易于实现,与chrF++自身的评估方法与原理有较强的关联性;(6)即便是在两个指标中表现最佳的翻译系统,得分也主要集中在20至60分之间,这一分布可能受文本测试集规模、复杂度和评估方法自身局限性的影响。上述观察和初步分析是基于量化结果的探索性总结,为了综合评估各翻译系统在处理涉海文本翻译中的应用效能,还需结合BERTScore指标的评分结果及定性案例分析来进一步验证。
2.BERTScore指标评分结果
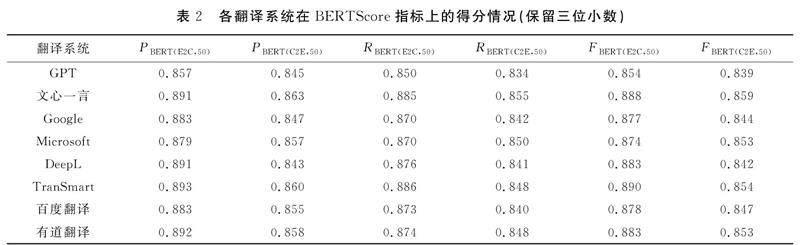
依据Zhang等人所提出的BERTScore评估方法,[5]并针对具体任务特性进行编程,以实现对E2C及C2E两个翻译方向上的测试集进行详细的评估。具体而言,计算测试集中各个测试句在BERTScore指标上的得分表现(如表2所示),绘制各翻译系统在两个翻译方向上的F1得分分布图(如图2所示)和比较图(如图3所示)。尽管BERTScore提供包括精确率、召回率和F1得分在内的三项评估指标,但F1得分作为精确率与召回率的调和平均值,能够提供一个平衡两者的综合效能评价指标。在机器翻译质量的评估过程中,依赖单一的精确率或召回率指标可能无法全面揭示翻译质量的多维度特征。高精确率可能反映出翻译过度保守,而高召回率可能意味着翻译输出包含较多的不精确元素。F1得分通过平衡精确率和召回率,能够全面评价翻译系统的应用效能,反映其在保持翻译准确性与覆盖原文意义之间的平衡能力。因此,本研究选用F1得分作为评估翻译系统应用效能的主要指标。
基于图表信息及测试集评分数据,归纳出以下关键发现:(1)在E2C方向上,TranSmart的平均F1得分最高(0.890),而在C2E方向上,文心一言的平均F1得分最高(0.859);(2)在E2C方向上,TranSmart的标准差最大(SD=0.046),而在C2E方向上,DeepL的标准差最大(SD=0.045),反映了这些系统在处理不同句子时性能的波动性较大;(3)文心一言在两个翻译方向上均展现了最大的F1得分(E2C为0.986,C2E为0.974);(4)各翻译系统在E2C方向的F1得分普遍高于C2E方向。
在实施单因素方差分析(ANOVA)之前,采用Shapiro-Wilk检验[10]对数据集的正态分布假设进行验证,以确保满足ANOVA分析的前提条件。Shapiro-Wilk检验的结果揭示,部分翻译系统在特定翻译方向上的数据未能通过正态性检验,具体包括GPT、DeepL、TranSmart、有道翻译在E2C方向上,以及Google与Microsoft在C2E方向上,均显示p值小于0.05,表明这些系统的F1得分分布不符合正态分布,抑或揭示了机器翻译系统性能分布的内在复杂性。
鉴于部分数据未满足正态分布的假设,研究又采用Kruskal-Wallis检验[11]作为ANOVA的非参数替代方法,以评估不同翻译系统间F1得分的统计学差异。该检验不依赖于数据的正态分布假设,也不要求各组方差一致,适用于本研究。检验结果显示,在E2C方向上,不同翻译系统的应用效能存在统计学意义上的显著差异(H(7,400)=24.308,p<0.05),这表明至少一个翻译系统的应用效能显著不同于其他系统。而在C2E方向上,未观察到统计学意义上的显著差异(H(7,400)=9.894,p=0.195),这表明所有翻译系统在该方向任务上的应用效能相对一致。
为进一步考察在E2C方向上特定翻译系统间的应用效能差异,进行Kruskal-Wallis检验拒绝零假设之后适用的Dunn的多重比较检验,[12]并依据Dunn于1961年所提出的建议[13]对结果进行Bonferroni校正,以降低在多重比较过程中产生第一类错误(即假阳性)的风险。Dunn测试的结果表明,GPT与DeepL、TranSmart、文心一言及有道翻译之间在E2C方向上存在统计学意义上的显著应用效能差异(GPT的应用效能相对较差)。这一发现得到表2和图3数据的支持,而其他翻译系统之间无显著差异。
针对上述发现与统计分析,发现两个值得深入讨论的问题:
(1)文心一言与GPT作为大语言模型支持的人工智能助手,为何表现出显著的应用效能差异?
(2)翻译系统在E2C方向的应用效能普遍优于C2E方向,可能原因是什么?
对于第一个问题,尽管二者均由大语言模型支持,但在设计理念、训练数据、优化目标以及实现技术等方面存在显著差异。这些差異可能导致二者在特定任务,如机器翻译上的表现有所不同,以下是可能的原因:首先,专业化知识整合程度不同。文心一言强调通过整合领域知识来增强其语言模型的能力,尤其通过ERNIE模型融合知识图谱信息,优化模型对专业术语和领域背景知识的理解能力。相比之下,GPT虽然接受了大量的数据训练,但它可能没有像文心一言那样针对特定专业领域进行优化。其次,文心一言可能接入了更广泛的专业数据集,尤其是在百度上的海量中英文资源,而GPT基于广泛的互联网文本进行训练,可能在特定领域覆盖和深度上与专门优化的模型有所差距。其他原因包括任务专注度的优先级、实时更新频次和学习能力的差异。
对于第二个问题,可能因素包括:首先,在涉海领域,多数行业术语、操作指南、法律法规以英语制定,这意味着在该领域内,英语作为源语言的翻译任务(即E2C)能够直接利用已标准化的术语和表达。这种规约性的存在,为机器翻译模型训练提供了丰富的英文输入,助力提升模型对专业术语和固定表达的识别与翻译能力;其次,英语作为主要的国际交流语言,提供大量的专业文献和文本资源,这些资源的广泛可用性不仅加深了模型对特定术语的理解,也增强了模型的语言理解能力和泛化能力。这使得模型即使面对未曾见过的专业术语和表达,也能在其训练数据和算法的基础上,尝试进行识别和翻译,从而在概率意义上提供较为准确的翻译选项。不过,这种自动翻译仍可能需要人工审核或后处理以确保最终翻译的准确性和适应度。在机器翻译评估领域,准确使用术语对确保文本语义准确性和整体翻译质量提升至关重要,尤其在专业化翻译任务中更是评价质量的关键。
(二)定性分析
为深入分析各翻译系统在涉海领域的应用效能及显著差异的潜在原因,本研究选取在E2C和C2E方向上,各翻译系统F1得分排名前三和后三的测试例句。基于这些例句的重复情况,构建可视化网络图,如图4和图5所示。
在图4和图5中,第一行和第三行区分了F1得分排名前三和后三中重复出现的测试例句编号,以突出不同翻译系统中表现最佳和最差的测试例句。此方法旨在通过聚焦分析与探讨具体案例,展现各翻译系统的优势和共同挑战,为提升翻译系统在涉海领域的应用效能提供洞见。
1.EC2翻译方向的案例分析
在E2C方向上,通过分析F1得分前三中重复的测试例句,发现翻译系统在专业术语识别与语义解析方面表现出一定的能力。例如“voyage charters”(航次租船)、“time charters”(定期租船)、“bareboat charters”(光船租船)、“innocent passage”(无害通过)、“Ro-Ro deck”(滚装甲板)以及“traffic separation schemes”(分道通航制)等,均被准确识别和翻译。专业术语的精确识别与转换对保持语义完整性与准确性至关重要,这一点在F1评分结果中同样得到充分验证。然而,也发现一些不足之处,特别是GPT将“flag State”(船旗国)(编号30)处理为“旗国”,这可能因为GPT训练语料中涉及特定领域(特别是涉海领域)专业术语的数据不足或缺乏充分的上下文信息。观察到该句话的F1得分(0.897)相对于其他翻译系统较低,这一结果可能与专业术语翻译不准确有关联。此观察提示了翻译过程中专业术语准确性对于整体翻译质量可能持有关键性影响。
案例分析还显示,即使是表现较好的翻译系统,处理涉海法律英语中复杂句式时仍显不足。例如,在案例(1)(编号35)中,“to the extent appropriate”这一修饰语的插入,导致多个翻译系统错误地将“The master, officers and, to the extent appropriate, the crew are fully conversant with and”处理为“船长、高级船员和船员(在适当情况下)完全熟悉并……”,从而影响了句子原意图的完整传达。这一错误翻译产生了两种潜在的解读:一种是对所有提及群体做出普遍性限定,另一种是专门针对船员的限定。这导致法律条文的传达产生了歧义,可能会引起不同的解释和实施问题,而原文的意图是将这一限定条件特定地应用于“船员”这一群体,表达出不同群体可能根据情况存在不同程度的遵守规定的要求。
涉海法律因涉及国际性(跨国界)和多辖区复杂性,要求专业术语和条款翻译不仅语义准确,还必须遵循涉海法律的专业表述,确保不同国家和地区对涉海法律体系有统一的理解和应用,达到法律功能对等。这种准确性和一致性是促进国际海事合作、确保航海安全及在全球范围内有效管理海洋资源的基石。此外,海上活动的安全和责任进一步强调了术语精确性和法律条款明确界定与传达的重要性,确保所有参与方清楚自身权利和责任,减少因误解引发的风险。因此,开发涉海领域的术语自动抽取模型尤为关键,此举旨在确保涉海法律文档、操作规范以及安全指导原则等涉海关键信息的准确传递,减少因专业术语和法律条款翻译不当而导致的误解与潜在风险,保障国际海事和海洋活动的安全、效率及法律法规遵守。
案例(1)
原文:The master, officers and, to the extent appropriate, the crew are fully conversant with and required to observe the applicable international regulations concerning the safety of life at sea, the prevention of collisions, the prevention, reduction and control of marine pollution, and the maintenance of communications by radio. (来源:《联合国海洋公约》)
参考译文:船长、高级船员和在适当范围内的船员,充分熟悉并须遵守关于海上生命安全,防止碰撞,防止、减少和控制海洋污染和维持无线电通信所适用的国际规章。
分析F1得分后三名中的重复句子发现,这些例句多涉及涉海法律法规,其特点在于密集的专业术语、深入的领域知识和复杂的法律构造,对翻译系统的能力提出了较高要求,特别是在理解和表述相关法律专业术语及其所涵盖的领域知识方面。例如,在案例(2)(编号45)中,翻译系统对于“able seafarer deck”和“certification of ratings”等专业术语及其领域知识的处理,展示了其在术语识别与准确转换方面的不足,影响整个句子的意图传达。例如,GPT将其翻译为“能够胜任甲板船员工作的最低要求”,而其他系统的翻译为“合格海员甲板认证的强制性最低要求”,均未能准确捕捉原文意义。
依据《1987年海员培训、发证和值班标准国际公约》,“ratings as able seafarer deck”指满足特定资格、技能和经验要求,能在甲板部门担任高级角色(如高级值班水手)的船员,显示了从普通船员到高级值班水手的资质等级差异。“certification”指正式认证过程,确保船员资格和能力达到国际认可标准。在参考译文中,这些原文中的隐含背景信息都得到了明晰化处理,而现有翻译系统在精确处理这些术语和领域知识细节上还存在挑战。
案例(2)
原文:Mandatory minimum requirements for certification of ratings as able seafarer deck. (来源:《1987年海员培训、发证和值班标准国际公约》)
参考译文:对作为高级值班水手的普通船员发证的强制性最低要求。
2.C2E翻译方向的案例分析
在C2E方向上,F1得分前三名中的重复句子主要涉及海事仲裁和海洋环境保护等话题,翻译系统在处理这些涉海场景中的专业术语和法律程序时展现出较强的能力。例如,“船舶实时定位分析”(analysis of real-time positioning of ships)、“海上船舶碰撞动态模拟分析”(dynamic simulation analysis of ship collisions at sea)、“船舶碰撞损害责任纠纷”(cases of disputes over liability for damage caused by vessel collision)、“海上货运代理合同纠纷”(disputes over contracts for sea freight forwarding)等术语,都被大部分系统准确地识别和翻译。这类测试例句的高F1得分与E2C方向中得分高的句子分析结果一致,凸显了正确表达专业术语在提高翻译质量上的重要性。
F1得分后三名中的重復句集中在航运发展、海洋石油勘探和海商法等专业领域,文本充斥着如“冷藏舱”(refrigerating chamber)、“冷气舱”(cool chamber)、“航道整治”(fairway/waterway regulation)、“江海直达船型”(ship types for sea-river direct shipping)、“数字航道”(digital fairways/waterways)、“冷藏集装箱船”(reefer container ships)、“亏舱费”(dead freight)等一系列的专业术语。在处理这些专业术语时,多数系统未能充分体现术语的精确含义,导致文本语义传达出现严重偏差。例如,“亏舱费”这一专业术语被不同系统翻译为“shortage freight”(Google)、“loss of space”(DeepL)、“demurrage”(百度翻译、有道翻译),表述各异。在专业且严谨的涉海领域,这种术语的不精确使用显著阻碍了行业内的交流与沟通,增加了误解和潜在风险。
此外,这些句子还涉及复杂的海商法条款。案例(3)(编号19)讨论海商法中关于航海操作过程中责任和准备工作的规定,从句式结构上也展现了涉海法律文本在逻辑、专业术语方面的特点。分析发现,大多数翻译系统倾向于简化内容,牺牲了涉海法律文本的严谨性和正式性。例如,“适拖”(tow-worthy)和“被拖物适合拖航的证书”(certificate of tow-worthiness)被通俗化为“ensure the towed object is in a condition/state suitable for towing/towage”“relevant certificates and documents issued by relevant inspection agencies indicating that the towed object is suitable for towing/towage.”,影响法律效力。对于涉海法律文件的翻译,需要字字斟酌,以求译文措辞准确,力求具有与原文相差无几的法律效应。[14]相对而言,在追求法律文本的正式性与精确性方面,文心一言的处理显得过于刻板,尤其是在其对“被拖物”一词的处理上。通过四次冗余地使用“the object to be towed”进行表述,违背了涉海法律翻译应遵循的精确性和经济性原则。
案例(3)
原文:被拖方在起拖前和起拖当时,应当做好被拖物的拖航准备,谨慎处理,使被拖物处于适拖状态,并向承拖方如实说明被拖物的情况,提供有关检验机构签发的被拖物适合拖航的证书和有关文件。(来源:《中华人民共和国海商法》)
参考译文:The tow party shall, before and at the beginning of the towage, make all necessary preparations therefor and shall exercise due diligence to make the object to be towed tow-worthy and shall give a true account of the object to be towed and provide the certificate of tow-worthiness and other documents issued by the relevant survey and inspection organizations.
E2C和C2E方向的案例分析表明,如TranSmart和文心一言等现代翻译系统在涉海文本处理上已取得显著进步,在识别和精确翻译通用术语及解析语境方面,体现了对专业知识的深刻洞察。然而,分析也指出这些翻译系统在处理特定法律文本时遇到的挑战,特别是在精确识别和翻译涉海专业术语方面存在的困难,直接影响了语义的准确传递,成为制约机器翻译在涉海法律领域中有效应用的主要障碍。开发涉海领域的术语自动抽取模型,可以显著解决这一问题,整体提升翻译质量,增强机器翻译在该领域的应用效能。
四、结语
在涉海专业领域,高质量的机器翻译服务至关重要,它不仅可以为专业人士提供便捷,还能够促进全球海事、海洋科学以及相关领域的知识共享和国际合作。本研究通过应用BLEU、chrF++以及BERTScore 3种评估指标,对国内外多个主流机器翻译系统及人工智能助手(翻译功能)在涉海文本中的应用效能进行综合评估。结果表明:(1)在识别和翻译通用术语以及解析语境、语义方面,各翻译系统均表现出较好的性能,译文准确性和流畅性达到了可接受水平,能够在一定程度上提升涉海文本翻译的效率,例如与航运发展、海洋文化、海洋历史、海洋环境相关的文本;(2)在翻译方向方面,各系统在E2C方向上的应用效能优于C2E方向,这一现象可能源于英语作为涉海领域的通用语言,在专业领域内拥有较为统一和广泛认可的术语和表达体系,当从英语翻译到中文时,系统能够直接借鉴这些标准化的专业用语和表述,较为准确地进行术语和固定句式表达的识别、匹配和转换;(3)在翻译质量方面,各系统之间存在显著差异,文心一言和TranSmart在E2C和C2E两个翻译方向的多项评估指标上表现较为优异,其输出的译文仅需轻度的译后编辑即可达到使用标准,而GPT在两个翻译方向的三项指标上均是表现最差的,与其他系统相比,应用效能差距显著。(4)在处理专业领域知识密集型、术语精确度要求高及逻辑结构严密的文本方面,特别是涉及海事法律法规的文本,即使是性能最优的翻译系统也遭遇严峻挑战,这一情况在EC2和C2E两个翻译方向上均显著。
本研究针对机器翻译技术在涉海领域的未来发展与应用提出两个建议。首先,翻译系统开发者应深度剖析在多系统评估中普遍表现不佳的测试案例,这有助于改善翻译模型在处理与解析专业术语和领域知识时的局限;其次,术语具有认知、语言、传播三个维度,分别指向的是概念知识体系、术语话语体系和受众传播体系,[15]学界和业界应重视涉海垂直领域语料库的构建,[16]融合大语言模型与高质量领域标注数据集,开发涉海领域的术语自动抽取模型,以显著提升术语识别、翻译和传播的精確度,这对于提高翻译系统在涉海领域的应用效能,增强涉海领域中的跨语言交流和话语体系建构极为关键。未来的研究将包括扩展测试集的规模与多样性,开发更全面、精确的评估指标,专注于构建涉海领域的术语自动抽取模型,进一步促进机器翻译在涉海领域的集成与应用。
参考文献:
[1] Papineni K, Roukos S, Ward T, & Zhu W J. BLEU: a method for automatic evaluation of machine translation[A]. In Isabelle, P. et al. (eds.). Proceedings of the 40th Annual Meeting on Association for Computational Linguistics[C]. Philadelphia, USA: Association for Computational Linguistics, 2002: 311-318.
[2] Banerjee S, Lavie A. METEOR: an automatic metric for MT evaluation with improved correlation with human judgments[A]. In Goldstein, J. et al. (eds.). Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization[C]. Michigan, USA: Association for Computational Linguistics, 2005: 65-72.
[3] Popovic′ M. chrF: character n-gram F-score for automatic MT evaluation[A]. In Bojar, O. et al. (eds.). Proceedings of the tenth Workshop on Statistical Machine Translation[C]. Lisbon, Portugal: Association for Computational Linguistics, 2015: 392-395.
[4] Popovic′ M. chrF++: words helping character n-grams[A]. In Bojar, O. et al. (eds.). Proceedings of the Second Conference on Machine Translation[C]. Copenhagen, Denmark: Association for Computational Linguistics, 2017: 612-618.
[5] Zhang T, Kishore V, Wu F, Weinberger K Q, & Artzi Y. BERTScore: evaluating text generation with BERT[A]. Proceedings of the eighth International Conference on Learning Representations[C]. Online: Association for the Advancement of Artificial Intelligence (AAAI), 2020: 1-43.
[6] Rei R, Stewart C, Farinha A C, & Lavie A. COMET: a neural framework for MT evaluation[A]. In Webber, B. et al. (eds.). Proceedings of the 2020 conference on Empirical Methods in Natural Language Processing (EMNLP)[C]. Online: Association for Computational Linguistics, 2020: 2685-2702.
[7] Sellam T, Das D, & Parikh A. BLEURT: learning robust metrics for text generation[A]. In Jurafsky, D. (eds.). Proceedings of the 58th annual meeting of the Association for Computational Linguistics[C]. Online: Association for Computational Linguistics, 2020: 7881-7892.
[8] Callison-Burch C, Osborne M, & Koehn P. Re-evaluating the role of BLEU in machine translation research[A]. In McCarthy, D., & Wintner, S. (eds.). Proceedings of the 11th conference of the European Chapter of the Association for Computational Linguistics[C]. Trento, Italy: Association for Computational Linguistics, 2006: 249-256.
[9] Perreault W D. Controlling order-effect bias[J]. The Public Opinion Quarterly, 1975, 39(4): 544-551.
[10] Shapiro S S, Wilk M B. An analysis of variance test for normality (complete samples) [J]. Biometrika, 1965, 52(3/4): 591-611.
[11] Kruskal W, Wallis W A. Use of ranks in one-criterion variance analysis[J]. Journal of the American Statistical Association, 1952, 47: 583-621.
[12] Dinno A. Nonparametric pairwise multiple comparisons in independent groups using Dunn's test[J]. The Stata Journal, 2015, 15(1): 292-300.
[13] Dunn O J. Multiple comparisons among means[J]. Journal of the American Statistical Association, 1961, 56(293): 52-64.
[14] 任東升, 白佳玉. 涉海法律英语翻译[M]. 青岛: 中国海洋大学出版社, 2015.
[15] 高玉霞, 任东升. 中国海洋政治话语翻译语料库的建构与研发[J]. 中国海洋大学学报 (社会科学版), 2020(6): 107-116.
[16] Zhang Y, Liu S. The maritime domain-specific corpus: compilation and application[J]. Pedagogika-Pedagogy, 2023, 95(5s): 139-156.
Evaluating the Application Efficacy of Machine Translation in Maritime Contexts: A Rigorous Evaluation via BLEU, chrF++, and BERTScore Metrics
Liu Shijie
(College of Foreign Languages, Shanghai Maritime University, Shanghai 201306, China)
Abstract: The advent of deep learning technologies and generative artificial intelligence has catalyzed a qualitative shift in the machine translation landscape, forging novel avenues for advancement in this arena. This investigation endeavors to conduct a comprehensive evaluation of the application efficacy of machine translation within the maritime sector, set against a backdrop of diverse technological and algorithmic frameworks. To this end, a curated test dataset comprising 100 emblematic bilingual (Chinese-English) sentences pertinent to maritime contexts was developed. Leveraging the unique linguistic structural nuances of maritime texts, three automatic evaluation metrics-BLEU, chrF++, and BERTScore-were employed to facilitate both quantitative and qualitative analyses of translations rendered by AI assistants ChatGPT (4.0) and ERNIE Bot (4.0), alongside six leading translation engines: Google Translate, Microsoft Translator, DeepL Translate, Tencent TranSmart, Baidu Translate, and Youdao Translate. The findings of this study not only furnish empirical evidence underpinning the application efficacy of machine translation systems within the maritime domain but also elucidate considerations for algorithmic refinement and translation precision enhancement for machine translation technology developers. Moreover, this research proffers a pragmatic blueprint for maritime professionals in the selection of apt translation systems.
Key words: maritime translation; application efficacy of machine translation; BERTScore; BLEU; chrF++
责任编辑:王 晓
收稿日期:2024-02-23
基金项目:国家社会科学基金项目“海洋强国视域下海事语言标准化及国际海事话语研究”(21BYY017);2023年教育部产学合作协同育人项目“基于海事语言数据的人才培养实践条件与实践基地建设研究”(230801549211644);上海海事大学2022年研究生拔尖创新人才培养项目“基于深度学习的海事领域术语自动抽取及分析研究”(2022YBR020)
作者简介:刘世界(1994- ),男,河南永城人,上海海事大学外国语学院博士研究生,专业方向为海事术语自动抽取与文本挖掘、计量语料库语言学(QCL)、翻译技术。
