基于多数据源融合的变电站设备状态评估方法
2024-05-07王文华陈定标张旭东李发元
王文华 陈定标 张旭东 赵 耀 李发元
(贵州电网六盘水供电局)
0 引言
变电站设备状态对变电站整体运行有着重要影响,通过状态评估研究的现状分析,采取有效措施确保电力系统的稳定运行,提高设备的运行效率[1]。从维护电力系统的稳定运行角度分析,变电站设备状态评估可以在未出现故障之前预测设备健康状况,并及时采取维修和保养措施,避免设备故障[2],确保电力系统的稳定运行。从提高变电站设备的运行效率角度分析,经过一定的使用期限,一些设备由于受到环境、电压等多种因素影响,会出现性能下降等问题[3]。在此时,通过状态检修可以及时发现和修复设备存在的问题,使设备恢复到最佳工作状态,从而提高设备的运行效率和性能指标。现阶段,变电站设备状态监测技术还有待提高。尽管现有的监测技术取得了一定的进展,但在实时性、可靠性和准确性方面仍存在一定的局限性[4]。例如,对于一些关键设备的微小故障或潜在问题难以准确识别和诊断。另外,电站设备状态评估工作涉及大量的数据处理和分析,需要专业的技术人员进行操作和管理[5]。然而,目前部分发电厂在这方面的人力资源配置相对薄弱,技术人员的培训和管理也不够完善,影响了设备状态评估的效率和准确性[6]。
在此基础上,本文提出基于多数据源融合的变电站设备状态评估方法研究,并设置了对比测试环境,分析验证了设计评估方法的应用性能。
1 变电站设备状态评估
1.1 多源变电站设备状态数据关联关系分析
在分析多源变电站设备状态数据之间的关联关系时,较为常见的方法为统计分析方法,包括相关性分析、主成分分析、聚类分析等,这也是研究不同数据源之间关系的重要手段之一[7]。考虑到变电站设备状态自身的属性特征,本文采用主成分分析(PCA)方法,计算和分析多源变电站设备状态数据之间的关联关系。
主成分分析(PCA)作为一种常用的降维方法,它通过将原始特征线性组合成一组新的特征,这组新的特征被称为主成分。主成分之间的正交性意味着对应的多源变电站设备状态数据之间没有相关性[8],同时它们也尽可能地包含了原始数据的变异性。因为,本文借助主成分分析减少多源变电站设备状态数据集的维度,以此最大限度保留多源变电站设备状态数据中尽可能多的信息[9]。计算过程如下:
(1)原始多源变电站设备状态数据标准化:由于不同数据源的量纲可能不同,首先需要对数据进行标准化处理。具体计算公式如下:
式中,xi*是标准化后的变电站设备状态数据,xi是原始变电站设备状态数据,是原始变电站设备状态数据的均值,s是原始变电站设备状态数据的标准差。
(2)计算多源变电站设备状态数据协方差矩阵:协方差矩阵可以衡量数据源之间的相关性。具体计算公式如下:
式中,Cij是变电站设备状态数据协方差矩阵的元素,xij*是变电站设备状态数据源的标准化数据,和分别是第i和第j个数据源的均值,N是样本数量。变电站设备状态数据协方差矩阵元素的构成受变电站设备的具体情况影响,本文设置了以下四类矩阵元素构成,具体如表1所示。
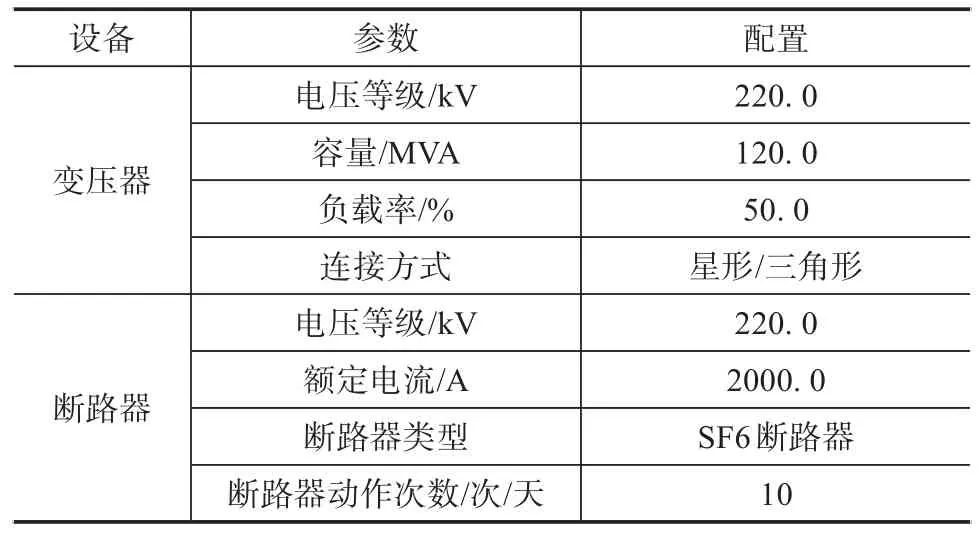
表1 变压器和断路器相关参数信息统计表
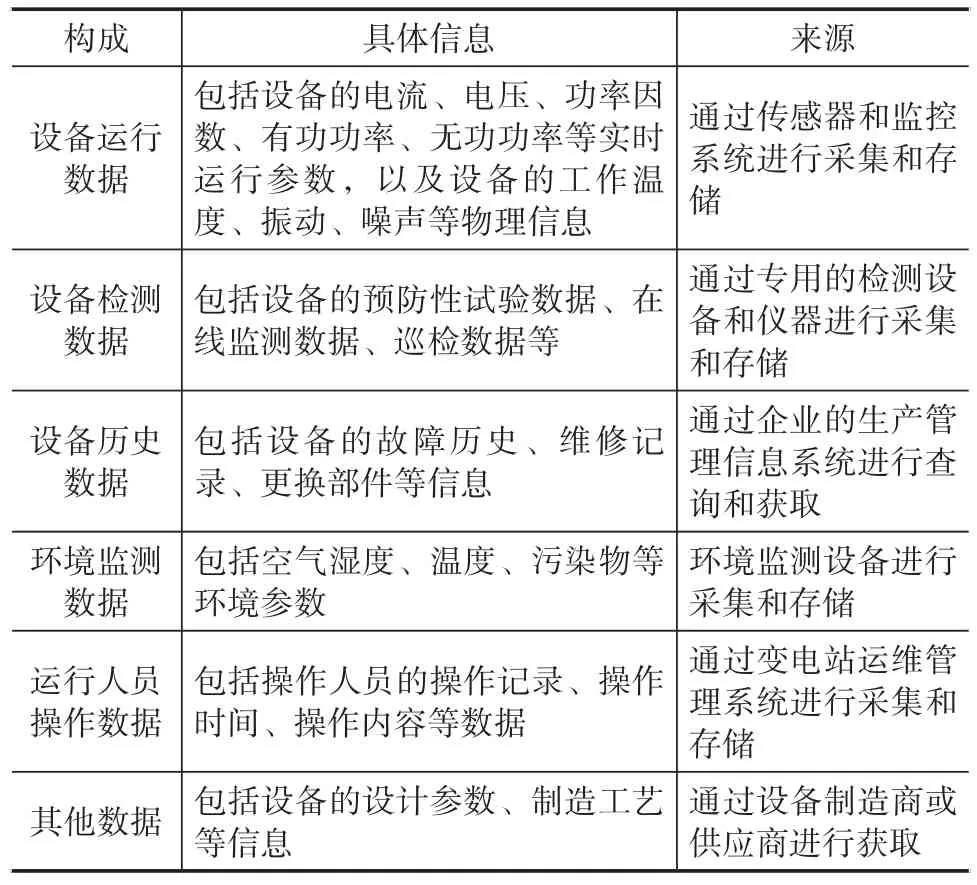
表1 变电站设备状态数据协方差矩阵元素构成
依据表1所示的变电站设备状态数据协方差矩阵元素的构成设计情况,最大限度保障分析结果的可靠性。
通过以上计算过程,可以得到一组不相关的主成分,这组主成分可以用来表示原始变电站设备状态数据中的主要信息。如果主成分之间存在相关性,则说明它们之间存在信息重叠,这时可以选择更少的主成分来保留更多的信息。
1.2 变电站设备状态评估
结合上述分析结果,本文在变电站设备状态进行评估时,主要是根据实际变电站设备状态数据与计算得到的相关系数特征分布阈值之间的关系实现的。
对于计算多源变电站设备状态数据特征值和特征向量,协方差矩阵的特征值和特征向量可以表示变电站设备状态数据源之间的相关性。具体计算公式如下:
式中,C是变电站设备状态数据的协方差矩阵,λ是变电站设备状态数据的特征值,E是单位矩阵。通过求解方程可以得到特征值和特征向量。
对于设备状态评估阶段主成分的选择,本文将特征值从大到小排序,选择前k个最大的特征值对应的特征向量,则k个特征向量是最终的主成分。
在此基础上,具体的评估方式可以表示为
式中,y表示实际变电站设备状态数据,a表示特征向量的置信区间,结合选择前k个最大的特征值对应的特征向量充分,ka的主要作用是对变电站设备状态数据进行修正。那么则有,当修正后的变电站设备状态数据在变电站设备状态数据的协方差矩阵范围时,则设备处于正常状态;相反地,当修正后的变电站设备状态数据不在变电站设备状态数据的协方差矩阵范围时,则设备处于异常状态。
按照上述所示的方式,实现对变电站设备状态的评估分析,为实际的变电站设备安全稳定运行以及相关维护措施的有序开展提供有价值的帮助。
2 应用测试
2.1 测试环境
本实验旨在验证基于多数据源融合的变电站设备状态评估方法的有效性。为了对比分析,另外设置两种变电站设备状态评估方法作为对照组:基于单数据源的变电站设备状态评估方法和基于传统监测设备的变电站设备状态评估方法。
在具体的实验准备阶段,需要选择合适的测试环境参数,收集了一座220kV变电站的主站和子站的历史数据,包括变压器、断路器、隔离开关等设备的运行数据、故障历史、维修记录等。该变电站共有20个设备,收集了每个设备连续12个月的数据包括电压等级、设备类型和系统结构等。在具体的测试阶段,本文主要以变压器和断路器作为状态评估对象。其中,变压器和断路器的相关参数信息如表1所示。
在上述基础上,为了能够更加客观地对本文设计的基于多数据源融合的变电站设备状态评估方法性能进行评估,设置三种方法在相同的测试工况下进行设备状态评估测试。通过对比不同方法的评估效果,对其进行分析。
2.2 测试结果与分析
在分析不同方法的变电站设备状态评估效果时,本文将故障误报次数和故障漏报次数作为具体的评价指标,其中,故障误报次数用于衡量设备状态评估方法错误地检测到设备故障的能力。故障误报次数越小,说明在避免误报方面的性能越好。故障漏报次数用于衡量设备状态评估方法未能检测到设备故障的能力。故障漏报次数越少,说明在检测设备故障方面的性能越好。其中,具体的测试结果如图1所示。
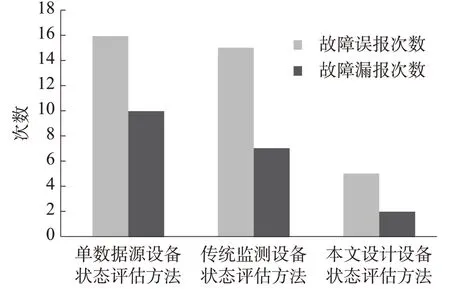
图1 不同方法测试结果对比结果
结合图1所示的测试结果可以看出,基于单数据源的变电站设备状态评估方法下,故障误报次数和故障漏报次数均处于较高水平,分别达到了16次和10次;在基于传统监测设备的变电站设备状态评估方法的测试结果中,虽然故障误报次数和故障漏报次数与基于单数据源的变电站设备状态评估方法相比有所下降,但仍存在进一步优化的空间。相比之下,在本文设计方法的测试结果中,故障误报次数分别低于对照组11次和10次,故障漏报次数分别低于对照组8次和5次。综合上述测试结果可以得出结论,本文设计的基于多数据源融合的变电站设备状态评估方法具有良好的实际应用价值。
3 结束语
本文设计基于多数据源融合的变电站设备状态评估方法。通过整合多个数据源的数据,能够更全面、准确地评估设备的状态,从而为电力系统的稳定运行提供有力支持。经实验验证,设计方法的故障误报次数和故障漏报次数均较低,其在未来将具有更广泛的应用前景。未来的研究方向包括改进数据预处理方法、优化特征提取技术以及引入更先进的机器学习算法等,进一步提高变电站设备状态评估的深度、广度和精度。
