基于BS架构的分布式文件数据并行访问方法
2024-05-07刘春伟
刘春伟
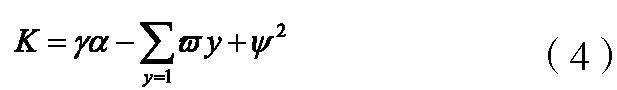
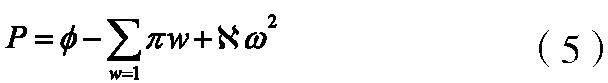
摘要:当前的分布式文件数据并行访问矩阵多为单结构,且访问的识别范围较小,导致访问耗时延长。为此,本文对基于BS架构的分布式文件数据并行访问方法进行设计与分析,根据实际的访问需求和标准,进行基础并行访问数据预处理;采用多阶的形式,扩大访问的识别范围,设计多阶交叉并行访问矩阵,构建BS架构分布式文件数据并行访问模型;采用自适应转换修正实现并访问处理。测试结果表明,对比于传统Spring分布式文件数据并行访问测试组、传统CP-ABE分布式文件数据并行访问测试组,此次设计的BS架构分布式文件数据并行访问测试组最终得出的分布式文件数据并行访问耗时均被较好地控制在0.2s以下,说明此种访问方法的针对性和稳定性更高,在BS架构的辅助下,可以加强对访问误差的控制,具有实际的应用价值。
关键词:BS架构;分布式文件;文件数据处理;并行访问;访问方法;文件识别
一、引言
文件数据的并行访问是一种多维访问方式,具有一定的針对性,可以在不同的环境下对数据和信息进行协同处理整合,进而达到预期访问目标。当前,较为常用的文件数据并行访问方式一般为单程序,例如参考文献[1]和文献[2]设定传统Spring分布式文件数据并行访问方法、传统CP-ABE分布式文件数据并行访问方法。这类访问方法虽然可以实现预期目标和任务,但是缺乏稳定性和转换性,所述访问目标也不明确,容易造成访问失败、文件数据丢失、文件丢失等情况,产生不可控的损失[3]。此外,单结构文件数据并行访问形式执行效率较低,覆盖的访问范围也受到限制,约束较多,容易影响最终的访问结果[4]。为此,本文对基于BS架构的分布式文件数据并行访问方法进行设计与验证分析。BS架构指的是浏览器、服务器架构模式,在实际应用过程中随目标变化作出对应的改进调整,形成三层逻辑结构,为日常生产生活提供了极大的便利条件[5]。将该项技术与分布式文件数据并行访问方法相融合可以进一步扩大访问范围,形成更灵活、多变的访问结构,同时,面对复杂的访问环境,也可以逐步强化访问程序,与初始数据库搭接,形成更安全、稳定的文件数据访问环境,便于交互的同时,为后续相关访问技术和行业发展奠定基础[6]。
二、设计分布式文件数据BS架构并行访问方法
(一)基础并行访问数据预处理
通常情况下,分布式文件数据量十分庞大,因此在对其进行并行访问之前,需要搭建多维访问结构的支撑,并对基础并行访问数据进行预处理[7]。传统的访问格式是单向的,对数据、信息的采集效率较低,导致后续访问指令执行出现阻碍[8]。因此,首先进行基础数据的采集和设置,设置并行访问数据指标,分别是并行栅格数量/个、独立访问次数/次、数据读入比、吞吐力变动比、访问映射点/个;接着,依据指标设置基础参数标准值,分别为5、12、6.33、3.2、10;最后,依据指标设置实测参数标准值,分别为8、18、7.15、4.2、16。其次,在完成对并行访问数据采集的设置与分析后,结合分布式文件数据的访问需求及标准,在标定的范围之内设置多个访问节点。需要注意的是,节点在设置时互相独立,需要建立对应的接入关系,以形成循环式的数据采集形式,提升后续的并行访问效率。最后,以此为基础,将获取的并行访问数据进行分类、筛选,消除采集的数据误差及相关问题,确保数据的真实性和可靠性,实现对文件数据并行访问的预处理。需要注意的是,采集数据一般是实时的,所以在进行预处理时,设置的标准也不固定,需要随着实际访问需求和标准作出定向调整,以此提升数据访问处理的灵活度。
(二)设计多阶交叉并行访问矩阵
在完成基础并行访问数据预处理后,设计多阶交叉并行访问矩阵。当前应用的访问矩阵多为单结构,虽然可以完成对分布式文件数据的并行访问目标,但是访问效率及速度均有待提升,且有不可控性。而多阶交叉访问矩阵在实际处理过程中可将访问误差降至最低,确保访问结果的真实可靠。以下建立基础的并行访问测定结构,并计算出访问互斥比,如公式1所示:
在上式中,M表示并行访问互斥比,A表示转换访问定值差,θ表示访问总范围,C1和C2分别表示定向访问单元值和实测访问单元值,λ表示分离访问节点数量,ε表示并行处理极限值。结合计算得出的并行访问互斥比,调整矩阵的访问基准值,并设定并行访问约束条件,形成更完整、具体的访问矩阵结构。
以此为基础,结合BS架构,设计多维的并行访问空间,以访问目标为引导,设置多个文件访问层级,每个层级均需设置对应访问标准,目的是强化矩阵访问精准度,消除过程中存在的并行访问误差。同时,采用交叉方式执行矩阵中的访问目标,以此输出模糊的访问结果。
(三)构建BS架构分布式文件数据并行访问模型
在完成多阶交叉并行访问矩阵设计后,结合BS架构,构建分布式文件数据并行访问模型。首先,对所选分布式文件进行分类和筛选,保障数据信息的真实与稳定;随即利用设置的矩阵进行数据格式转换,重新调整并行访问标准;最后,再结合BS架构,构建分布式文件数据并行访问模型的执行结构。
通过BS架构来建立分支式并行访问结构,可以输出模糊的访问处理结果。需要注意的是,每个访问结果均为初始结果,在模型中构建分布式并行访问逻辑需要利用BS架构进行多维限制,针对每个目标进行排序处理,获取结构后,并对模糊结果做修正及整合处理,以提升并行访问结果的精准度和可靠性。
(四)自适应转换修正实现并访问处理
在完成BS架构分布式文件数据并行访问模型的设计后,采用自适应转换修正方式实现并行访问处理。为了更好解决分布式文件数据并行访问的一致性问题,需要建立相对的访问修正关系,采用自适应方式建立智能修正程序。具体流程是:首先,进行基础数据采集,并根据基础数据设定缓冲区域和基础访问目标;接着,进行日志修正处理和数值读取;最后,输出自适应修正结果。
依据上述流程对并行访问获取结果进行修正,接着进行并行访问修正限值差的计算,具体如公式2所示:
在上式中,X表示访问修正限值差,τ表示并行约束值, 表示单元修正比,μ表示单元修正次数,ρ表示堆叠值。结合访问修正限值差,进行访问结果比对,最大程度地降低并行访问误差,确保最终访问结果的可靠性和稳定性。
三、方法测试
本次主要对基于BS架构的分布式文件数据并行访问方法的应用效果进行分析验证,考虑到测试结果的真实性和可靠性,采用对比方式展开分析,选定A企业平台的分布式文件作为测试的主要目标对象,参考文件设定传统Spring分布式文件数据并行访问测试组、传统CP-ABE分布式文件数据并行访问测试组以及此次所设计的BS架构分布式文件数据并行访问测试组,根据当前测试需求和标准的变化,对最终的并行访问结果进行对比研究。
(一)测试准备
结合BS架构,对A企业平台分布式文件数據并行访问测试环境进行搭建与关联。首先,在A企业平台中随机定位4个分布式,标定出所属的分布式文件,汇总整合后以待后续使用。调整当前平台的控制基础数值,采用I5 CPU、12 GB 内存及 Linux 操作系统作为本次测试的主要支撑,调整E3-1230 处理器的运行频率为 3.5 GHz,调用 MIRACL 库与测试的访问程序进行搭接,形成循环性的并行处理结构。设置主控节点和I/O双向控制节点。为了确保访问处理结果的真实性和可靠性,将设置的节点相关联,构建并行访问矩阵,同时计算基础并行效率,具体如公式3所示:
在上式中,D表示访问并行效率,θ表示覆盖访问范围,m表示转换并行比,n表示访问次数, 表示网络运行效率。结合当前测试需求,将计算得出的访问并行效率设置为对应的并行访问标准。
接下来基于BS架构,构建初始并行访问结构:第一,设置访问目标和访问标准;第二,设置访问矩阵并调整访问需求;第三,使用bs架构进行访问引导;第五,进行分布式文件标定和数据汇总整合;第六,输出访问结果。
在完成对BS架构文件数据并行访问结构的设计后,在此基础上,设置分布式数据并行访问指标及参数,具体如表1所示:
根据表1,首先设置分布式数据并行访问指标及参数;接着,以此为基础,进行基础测试环境的调整,确保测试过程中的稳定与安全;最后,综合BS架构,对A企业平台中的分布式文件数据的并行访问方法进行测试研究。
(二)测试过程及结果分析
在上述搭建的测试环境中,结合BS架构,对A企业平台中的分布式文件数据的并行访问方法的实际应用效果进行分析和验证研究。首先,利用设定的节点进行实时数据以及信息的采集,针对选定的4个区域,标定出一定数量的为分布式文件,分别为12份、16份、21份、25份,利用专业的软件及设备进行分布式文件中基础性数据以及信息的提取,汇总整合后,测算出单元文件数据访问并行量,具体如下公式4所示:
在上式中,K表示单元文件数据访问并行量,γ表示访问基准值,α表示访问次数, 表示运行时间,ψ表示并行效率,y表示并行加速比。结合当前的单元文件数据访问并行量,针对选取的文件数据,进行并行访问耗时,具体如下公式5所示:
在上式中,P代表访问所耗时间,?代表覆盖的范围,π代表单次访问的效率,w代表访问的频次, 代表读取的次数,ω代表读取访问的单元值。结合当前的测试需求,对测试结果比照研究,如图1所示。
分析上图测试结果可知,对比于传统Spring分布式文件数据并行访问测试组、传统CP-ABE分布式文件数据并行访问测试组,此次所设计的BS架构分布式文件数据并行访问测试组最终得出的分布式文件数据并行访问耗时均被较好地控制在0.2s以下,说明此种访问方法的针对性与稳定性更高,在BS架构的辅助下,可以加强访问误差控制,具有实际的应用价值。
四、结束语
本文基于BS架构的分布式文件数据并行访问方法进行设计与验证分析,与初始的访问结构相对比,此次结合BS架构设计的针对文件数据的并行访问方法具有更加灵活、更加多变的特性,同时具有更强的针对性。在复杂的环境背景下,当前的访问程序可以精准定位到对应的访问区域以及位置,存在多任务、综合化、模块化、统一网络、高度集成等特点,结合分布式文件数据的访问需求及标准,加强对文件数据并行访问误差的控制,推动数据并行访问技术迈入新的发展台阶。
参考文献
[1]张彤,严南.基于Spring的轻量级数据访问框架扩展点研究[J].计算机仿真,2023,40(02):380-384.
[2]朱莉.基于CP-ABE的云存储数据访问控制方案研究[J].船舶职业教育,2023,11(01):74-77.
[3]赵慧.命名数据网络中基于CP-ABE算法构建区块链数据访问控制系统[J].数字通信世界,2023(01):46-48.
[4]韩刚,王嘉乾,罗维,等.公共卫生事件中医疗数据访问控制与安全共享研究[J].信息安全学报,2023,8(01):40-54.
[5]刘秋明,许泽峣,姚哲鑫,等.融合属性基加密和信用度的水利数据访问控制模型[J].科学技术与工程,2023,23(01):263-273.
[6]王洪亮,叶翔.数据访问权的构造——数据流通实现路径的再思考[J].社会科学研究,2023(01):71-84.
[7]李静元,张珂,杨东裕.基于雾计算的工业互联网安全数据访问方法[J].计算机与现代化,2022(12):118-122.
[8]蒋伟进,罗田甜,杨莹,等.物联网环境下基于区块链技术的私有数据访问控制模型[J].物联网学报,2022,6(04):169-182.
