英文文本情感分析在跨境电商评论中的应用
2024-05-06单菲杰
单菲杰
(浙江邮电职业技术学院 浙江绍兴 312000)
1 引言
目前,中国电商进入高质量发展阶段,越来越多跨境电商企业入驻亚马逊、wish、eBay、速卖通、Shopee等跨境电商平台。与国内天猫、京东等电商平台的中文评论数据不同,这些跨境电商平台的评论数据多为英文文本,给电商企业通过评论数据进行顾客对产品的喜好程度分析及利用评论指出的缺点来提升产品性能等方面带来了一定困难。情感分析是近年来国内外研究的热点,其任务是帮助用户快速获取、整理和分析相关评价信息,对带有情感色彩的主观性文本进行分析、处理、归纳和推理。情感分析包含较多的任务,如情感分类、观点抽取、观点问答和观点摘要等,情感分析方法可从评论的文本中提取出评论的实体,以及评论者对该实体所表达的情感倾向,并从评论者褒义和贬义的评论中形成商业洞察。因此,自然语言技术中的情感分析在跨境电商英文评论中的应用,对于企业得到负面情绪的英文文本内容及所对应的产品和评论等信息,可以针对性地分析客户对企业产品的体验感受,对企业提高自身产品的竞争力有一定的帮助作用。
2 相关技术
2.1 特征提取
跨境电商英文评论数据属于计算机无法直接识别并使用的文本数据,因此需将文本数据转化为数值型数据,通常为向量形式。随着利用自然语言处理情感分类问题研究的发展,把文本数据转化成计算机系统能够读取和利用的向量形式经历了很大的创新与优化。其中,词向量具有良好的语义特性,是表示词语特性的常用方式。
2.1.1 词袋模型
词袋模型(Bag of words)是最早以词为基本处理单元的文本向量化方法。首先,词袋模型通过构建一个包含语料库中所有词的词典,每个词的向量长度都是词典的大小;其次,向量中元素全是0,除了一个位置的元素是1,这个位置是词在词典中的index;最后,根据词典完成对每个词的向量化,进而完成文本向量化,这种表示方法称为one-hot向量表示。完成对所有词的向量化之后,就可以得出文本的向量化结果。每个文本的向量长度都是词典的大小,向量中的每个位置的元素代表词典中该位置的词在文本中出现的次数,维度灾难、未保留词序和语义鸿沟是词袋模型存在的几个比较明显的问题。
2.1.2 TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency)是一种针对关键词进行统计分析的重要方法。它用于评估一个词对一个文件集或语料库的重要程度。一个词的重要程度与其在文章中出现的次数成正比,而与其在语料库中出现的次数成反比。这种计算方式能够有效避免常用词对关键词的干扰,从而提高关键词与文章之间的关联性。
其中,TF指的是关键词在特定文件中的出现次数与文件总词数的比值,通常会被归一化,以防止结果偏向过长的文件。IDF代表逆向文档频率,表示包含特定关键词的文件数量越少,IDF值就越大,说明该关键词具有很强的区分能力。IDF的计算公式为log10(语料库中文件总数/含有该关键词的文件数+1),其中+1是为了避免分母为0。TF-IDF是TF和IDF的乘积,表示关键词在特定文件中的重要程度,因此TF-IDF值越大,表示该特征词对文本的重要性越大。
TF-IDF具有简单、快速且容易理解的优点。然而,其缺点是仅使用词频来衡量文章中一个词的重要性可能不够全面,有时重要的词可能出现的次数不够多。此外,这种计算方法无法考虑词语在上下文中的重要性,也无法体现词语在文章中的位置信息。
2.1.3 神经网络语言模型
神经网络语言模型(NNLM )由Bengio于2003年提出,神经网络模型包含三层:第一层是输入层,然后经过非线性变换tanh到达第二层,最后经过非线性变换softmax输出结果。但神经网络语言模型包含两个非线性层,训练复杂度很高。Mikolov等(2013)提出了Word2vec,与神经网络语言模型不同的是,Word2vec去掉了最耗时的非线性隐藏层,可以用来快速有效地训练词向量。Word2vec包含两种训练模型,分别是COBW和Skip_gram。其中,COBW模型通过上下文来预测当前词;Skip_gram模型则通过当前词来预测上下文。CBOW训练时有一个target word和多个context words;Skip-gram训练时则有一个context word和多个target word。
2.2 机器学习和深度学习
2.2.1 机器学习
机器学习是一个包含多种算法的领域,这些算法致力于深入分析大量历史数据,从中挖掘出隐藏规律,并应用于预测或分类。更具体地说,机器学习可以被视为寻找一个函数,这个函数以样本数据为输入,并以期望的结果为输出。有一个重要的点需要理解,那就是机器学习的目标是使学习到的函数能够在新样本上表现良好,而不仅仅是在训练样本上表现优秀,这个函数对新样本的适用性称之为泛化(Generalization)能力。
2.2.2 深度学习
深度学习是机器学习的一个子类别,它是基于机器学习发展出的一个全新领域。深度学习的灵感来源于人类大脑的工作方式,它利用深度神经网络来解决特征表达的学习过程。随着大数据和计算能力的提高,深度学习带来了一系列新的算法。为了提升深层神经网络的训练效果,人们对神经元的连接方法和激活函数进行了调整,其目标是建立、模拟人脑进行分析学习的神经网络,模仿人脑的机制来解释数据,例如文本、图像、声音。当面临一个机器学习问题时,通常的处理流程可分为以下几个步骤:数据收集与探索性分析、数据预处理与特征工程、数据集分割、模型的训练和模型的评价。
3 试验配置
3.1 数据集介绍
本文用来训练预测文本属于积极还是消极的模型的数据,采用由斯坦福学生Alec Go、 Richa Bhayani、 Lei Huang创建的sentiment140官网(http://help.sentiment140.com/)下载的。用于情感分类模型训练的数据sentiment140作为模型训练数据,该数据集是一个包含1600000条从推特爬取的英文文本的CSV文件。数据文件共有 6个字段,分别是the polarity of the tweet (0 = negative,4 = positive);the id of the tweet;the date of the tweet;the query(If there is no query,then this value is NO_QUERY);the user that tweeted;the text of the tweet。
3.2 数据预处理
通过上述方法收集到实验数据后,本文需要对数据进行数据预处理和特征工程。首先,用P y thon读取sentiment140的数据文件,检查数据中是否含有缺失值(null value),发现在sentiment140中没有缺失值的存在;其次,考虑到计算机的计算能力有限及深度学习模型的训练需要消耗大量时间,同时对于情感分类问题,数据偏斜不能过于严重,不同类别的数据数量不能有数个数量级的差距。因此,本文从sentiment140中随机选取了1/10的数据,共160000条推特作为训练和评估模型的数据集,其中包含80000条标记为积极的推特和80000条标记为消极的推特。
考虑到用户隐私问题,在处理数据时删除了用户名字段,同时删除了与模型训练的无关字段,包括the id of the tweet ;the date of the tweet ;the query和the user that tweeted,只留下了the polarity of the tweet (0 = negative,4 =positive)及the text of the tweet。
但是,英文文本数据普遍包含特殊符号、文本格式不统一等问题,需借助Python对数据进行清理。首先,用Python去除链接(以http开始)、表情和标点等特殊符号;其次;通过分词、标准化处理、去除停用词、词性还原和词干提取等步骤将文本数据进行进一步清洗。
3.3 模型配置
3.3.1 特征提取方法
本文通过四种机器学习方法,分别对T F-I DF 和Word2vec词向量化的数据进行评估。由表1可以看出,除了Lightgbm算法下两种词嵌入方法准确率相近外,其他方法均为使用Word2vec的准确率高于TF-IDF的。因此,在这两种特征提取方式中,本文选择了Word2vec。

表1 使用TF-IDF和Word2vec的四种不同机器学习算法的准确性
3.3.2 模型选择
本文选择了四个机器学习模型(KNN,LightGBM、XGBoost和Catboost)和两个深度模型(textCNN和BiLSTM)进行比较,得到的结果如表2所示。

表2 不同机器学习和深度学习算法的准确性
通过比较可以发现,深度学习模型的准确率普遍优于机器学习模型,且在两个深度学习模型中,textCNN的表现好于BiLSTM。综上所述,本文选择textCNN作为本文预测目标数据的模型。
3.3.3 模型训练与评价
经过数据处理得到干净的文本数据以后,本文使用特征工程将计算机无法直接使用的文本数据通过word2vec中的CBOW作为词嵌入技术,转化为计算机可以识别和使用的词向量。在本文中,CBOW的参数设置为:min_count=5,window=5,size=300,workers=16,batch_words=1000,即目标词前后各取五个词来预测目标词,向量d的维度为300维。训练1000轮后,CBOW收敛,训练得到了最优的词嵌入并将其保存,为之后训练模型时调用做好准备。
训练完词嵌入以后,就是对数据集的划分、模型的训练与评估。本文将sentiment140的160000条推特样本以Train:Test =8:2分成独立的两部分:训练集(train set,128000)和测试集(test set,32000)。其中,训练集用来训练模型;测试集则用来检验模型的性能。根据算法模型的结果,本文使用的模型是textCNN,是一个三层神经网络模型,由输入层、隐藏层和输出层构成,其中隐藏层包括卷积层、pooling层和全连接层。
首先,对输入层的MAX_LEN进行调优,过长的MAX_LEN会有太多的填补,而过短的容易丢失有效信息。本文在实验过程中初始设定MAX_LEN = 50,但在调优过程中发现MAX_LEN = 20好于50,而MAX_LEN = 30又优于20,所以最终使MAX_LEN = 30。其次,确定好MAX_LEN以后,将清洗好的文本分词,并用预训练好的Word2vec做词嵌入得到词向量, 将词向量经过卷积层对每一个卷积核进行卷积操作,在pooling层将不同卷积核得到的结果进行拼接得到最终的特征向量。在pooling层后设置了一个Dropout参数防止过拟合,默认的Dropout = 0.5,但经过实验发现,Dropout = 0.2比Dropout = 0.5表现更好,而Dropout = 0.1又优于Dropout = 0.2,因此最终把Dropout设为0.1。最后,将输出外接一个激活函数来对数据进行分类,本文的目的是把英文文本数据分为积极和消极两方面,属于二分类模型,所以选择sigmoid作为激活函数,binary_crossentropy作为损失函数。
图1 展示了模型accuracy和loss的学习曲线,发现当epoch=2时,训练集有最高的准确率,此时最优的textCNN模型的实验参数为:batch_size = 128;卷积核的大小filter_sizes = [1,2,3,5];卷积核的数量num_filters = 256;词向量的维度embed_size = 300;MAX_LEN = 30;Dropout =0.1。此外,用测试集数据对训练好的模型进行模型效果评估,得到测试集的准确率为83.45%。与其他使用同样的词嵌入技术和深度学习模型的学者相比,周敬一等(2018)使用SVM、Bi-LSTM和CNN模型对使用Word2vec方法向量化后的电影评论数据进行训练,分别得到63.45%、80.19%和81.7%的准确率。本文的模型与其他学者的模型在不同数据集上表现出相似的准确率,说明用该模型来预测新的数据是合理的。
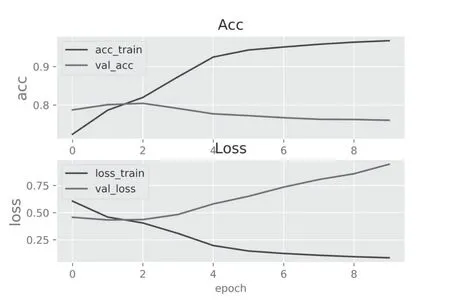
图1 accuracy和loss学习曲线
4 结语
本文建立了基于textCNN的英文文本情感分析模型,通过textCNN训练sentiment140的英文情感倾向分析,可以达到83.45%的准确率。通过该英文文本情感分析模型,对我国跨境电商企业通过分析亚马逊、wish、eBay、Shopee等国外电子商务网站上本企业产品的英文评论数据,探究产品的受客户欢迎程度及客户对企业产品提出的一系列问题具有较高的参考价值。该模型的应用与分析可以得到积极和消极评论数据的占比,同时可以通过负面情绪的英文文本内容及所对应的产品和评论等信息,帮助企业针对性地分析客户对企业产品的体验感受,对企业提高自身产品的竞争力有一定的帮助作用。
