基于特征提取的数字识别算法研究
2024-05-03赵丽
赵 丽
(河南工业贸易职业学院信息工程学院 河南 郑州 450053)
0 引言
针对工业现场的数字仪表,传统的数字识别方法通常是模板匹配、特征匹配、神经网络等。由于图像阈值化处理后的二值图像的字符位置分布不一致,基于模板匹配的数字识别方法匹配率比较低;由于光线等噪声干扰,基于特征匹配的数字识别方法的准确率比较低[1];基于神经网络的数字识别方法的准确率与特征选取以及训练时间有关,且达不到当前数字识别对准确度的要求。
日常生活中常见的数字识别的方法具有较高的准确率,并且都已经广泛应用在各个场所。但是上述算法得到广泛推广的前提条件是图像背景简单,前景区域与背景区域的差别比较明显,如车牌号的数字识别[2-3]。车牌号的背景为蓝色,数字为白色,两者所构成的图像对比度比较明显,并且车主经常洗车或者擦拭,所以图像具有较好的清晰度。但是工业现场的情况比较复杂,产品生锈、老化,背景杂乱、污浊,打雷刮风、雨雪冰雹都会直接导致获得的图像清晰度下降,所以识别难度大大增加。
针对上述存在的问题,本文提出了一种基于方向梯度直方图(histogram of oriented gradients, HOG)特征提取的数字识别算法研究。主要的识别过程可以分为以下四个部分,分别为预处理、数字分割、支持向量机(support vector machine, SVM)训练和识别数字。整体的数字识别流程图如图1 所示。
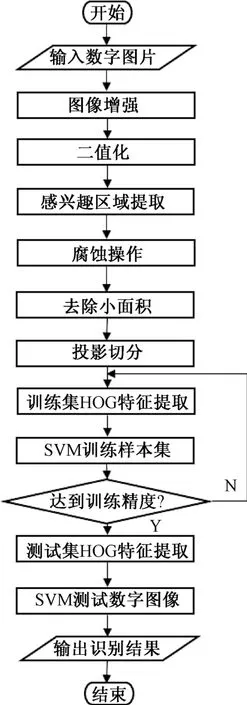
图1 数字识别流程图
1 图像预处理
工业现场情况复杂,导致获得的图像清晰度不佳,所以需要对图像进行预处理操作。预处理过程比较多,一般有图像灰度化、去雾、滤波、亮度对比度提升、图像增强和二值化等步骤[4]。
首先,采用图像增强的方法对图像进行处理[5],通过一定手段对原图像附加一些信息或变换数据,有选择地突出图像中感兴趣的特征或者抑制图像中某些不需要的特征,使图像与视觉响应特性相匹配。其次,对图像进行二值化处理[6],使图像变成只有黑白两种颜色,方便后续的分割识别。再次,对图像进行腐蚀操作。经历了该操作之后,数字区域变细,从而可以保证数字识别的精度会更高。最后,去除二值化后的图像中的小面积干扰。设定连通区域[7]的临界面积是100,所有小于100 的都认定为噪声区域,将其像素值以0 替代。
2 图像分割
本文采用投影方法对数字表进行切分。投影法[8]包括水平投影S(x)和垂直投影P(y)。水平投影指将图像投影到y轴上,得到每一行像素的数量;垂直投影指图像投影到x轴上,得到每一列像素的数量。二者分别反映了图像在水平和垂直方向上的特征。具体的算法步骤描述如下:
第一步:数字图像列扫描。对数字图像先进行从上到下逐列扫描,记录每列白色像素点的个数,并将其投影到水平面上,得到垂直投影图,再用确定好的垂直阈值对图像进行分割,得到垂直分割的图像。
第二步:数字图像行扫描。对数字图像先进行从左到右逐行扫描,记录每行白色像素点的个数,并将其投影到垂直面上,得到水平投影图,再次用确定好的水平阈值对垂直分割后的图像进行水平分割,最终得到分割后的效果图。
3 SVM+HOG 训练
本文选用SVM+HOG 的方法进行数字表的读数识别。首先,使用HOG 的方法进行特征提取;其次,选用SVM 的方法对数字读数进行训练;最后,用SVM 的方法进行识别。
3.1 SVM
SVM 将线性不可分的样本映射到高维的线性空间,在这个高维空间中使其线性可分,并且加入了核函数的使用,因此减少了计算的复杂性,也减少了“维数灾难”。SVM 的核心思想是寻找一个最优的超平面,这个超平面不仅可以分类,还可以让类之间的差异达到最大。
3.2 HOG 特征提取
HOG 是一种描述图像特征的描述子,它描述的是图像局部区域的梯度方向直方图的相关信息。为了提取到数字区域的HOG 特征,需要将图像进行分割,分成多个小的区域。因为分割后的区域比较小,可以将其视为细胞单元。对于每个细胞单元,提取其中各像素点的梯度的或边缘的方向直方图,并分析统计其方向特性,最终把所有的特性进行汇总,输送给后端识别算法模块。
3.3 SVM+HOG 特征提取
训练SVM 分类器的HOG 特征向量是从训练图像中提取的。从图2 中可以看到细胞的大小参数对特征向量编码的影响:[8×8]的细胞大小含有较少的编码形状信息,而[2×2]细胞大小包含较多编码信息,但与此同时HOG 特征向量的维数会显著增加。一个折中的方法是使用[4×4]的细胞大小,这个大小的设定既可以获得足够的特征信息,又不会造成特征的冗余,有利于分类训练。

图2 样本特征提取
假定图像大小为16×16,使用4×4 的大小作为细胞大小,2×2 的大小作为移动块,那么在水平方向和垂直方向上就会分别有3 个扫描窗口。每个细胞有9 个特征,所以每个块内有4×9=36 个特征。那么16×16 大小的图像,特征总数就为36×3×3=324。
所有样本数据经过HOG 算法特征提取后得到一组特征数据,将其输入到唯一的SVM 训练函数中,选择适当的核函数进行SVM 训练,即通过SVM 训练将线性不可分的特征向量变换到线性可分的高维空间寻求最优分类面,从而得到一个二分类器的最优解。其中每个样本都需要使用专用的SVM 训练器进行训练,得到各类SVM 结构。
HOG+SVM 特征提取的流程图如图3 所示。
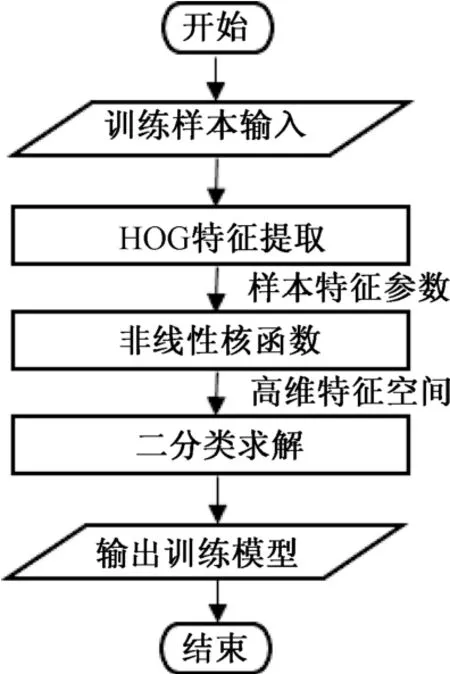
图3 HOG+SVM 特征提取
3.4 基于SVM 训练的具体步骤
(1)读取汽车车牌号训练集数据。因仪表数字图像与车牌号数字图像字体相似,本文选用车牌号数据集作为训练数据集。据观察,该数据集里共有500 张图像,其中0~9 每个数字分别有50 张训练样本,包含各种大小、各种位置的数字,具有较好的代表性,有利于后续的特征提取。
(2)HOG 提取特征。将输入的汽车车牌号训练集送入特征提取环节,用HOG 算法提取每个数字特征,并记录每个数字之间的特征差别。
(3)分类器训练。用非线性核函数训练样本的特征参数,并将其映射到高维特征空间,将线性不可分问题转换为高维线性可分问题,保存训练好的分类模型。
(4)对现场数字图像进行识别。因为之前已经训练好SVM 的模型,所以经过了投影分割和预处理操作的数字图像可直接送入SVM 分类器中对数字进行分类,输出即为该图像所代表的数字。
4 实验结果分析
因仪表数字图像与车牌号数字图像字体相似,本文采用HOG+SVM 对车牌号训练集进行训练,用HOG 算法提取车牌号训练集的数字特征,再用SVM 对其进行训练。训练之后对经过分割和预处理操作的数字进行识别预测,预测效果如表1 所示。

表1 图像识别预测结果
观察以上数据可以发现,本文算法均能正确识别出每个图像所代表的数字,识别效果较好,算法具有较强的鲁棒性,且在0 和8 较为相似的情况下也能正确识别,因此具有较强的推广价值。
此外,本文与其他论文进行了一系列对比,如表2所示。

表2 识别结果对比表
观察表2,发现本文的识别准确率最高,为95.5%,远远高于文献[9]和文献[10],虽然准确率与文献[11]接近,但是本文的识别速度要远远高于文献[11]。综合所有因素,本文在具有最高的准确率的同时,也具有最高的识别速度,由此说明了本文改进算法的有效性。
5 结语
本文主要是针对在复杂的工业现场,数字识别精度不高的情况下,所作的一系列优化。首先,对图像进行一系列的预处理;其次,采用投影法对数字进行分割;最后,采用HOG+SVM 的方法测试分割后得到的多张单个数字图像,从而精确地预测正确的数字。一系列的实验证明了本文算法具有较高的准确率,并且具有较高的识别速度,具有较好的推广意义。
