云环境下海量数据组织与资源共享的存储模型研究
2024-05-03钱文君
钱文君
(芜湖高级职业技术学校 安徽 芜湖 241000)
0 引言
云存储作为延伸云计算的并行计算核心技术,已经成为新型网络数据存储与管理新技术。云计算技术的迭代,分布式存储系统、虚拟化技术与容灾技术的应用,促使云存储技术得到全面的性能提升。以分布式、并行化方式存储大数据已经成为云计算主流趋势,云数据库系统大多数情况下基于键值模型设计,由于非关系数据存储不存在固定表结构,事务一致性并不严格,因而在数据模型上相对松散,能够自动切分数据至不同服务器,支持并发写入与查询,扩展水平呈现较大规模。
1 云环境下的海量数据管理概述
1.1 简述云计算和大数据
在存储与计算过程中,云计算利用规模庞大的数据与应用中心,在服务过程中,通过互联网随时访问、分享、管理与使用相关资源,根据计算资源数量,进行可用资源匹配,快速弹性提供资源,在大数据领域发挥横向扩展与优化的基础作用,支撑大数据实际实施。大数据是TB 级结构化传统数据与非结构化新数据的新处理模式,能够在合理时间内,高效处理海量数据,大数据相当于海量数据的“数据库”[1]。大数据处理无法运用单台计算机实施,主要采取分布式计算架构挖掘海量数据,依托云计算分布式处理、分布式数据库、云存储和虚拟化技术,完成海量数据抓取、管理、处理,从数据中快速获取具有价值的信息资讯。
1.2 云存储技术
云存储技术应用过程中,将数据存放于第三方服务器,为确保数据隐私性和安全性,需要采取数据加密、身份认证与访问控制等一系列措施,建立健全的安全审计机制,提升数据权限管理层级,防止出现数据泄露与恶意攻击风险。为降低云存储技术发展与云存储设备更新维护成本,采用更高标准的存储设备和存储技术,迅速提升数据可靠性与可恢复性,便于应对硬件故障、灾害性和损坏性突发情况,确保数据备份、容灾与恢复的重要性。
1.3 海量数据组织和索引方法
海量数据索引分析过程中,关系型数据库管理系统提供性能分析命令,能够对选择语句予以分析,输出执行详细信息后,供针对性优化应用,便于通过索引查询主键值,进行聚簇索引查询记录信息。解释命令输出结果的附加字段为使用索引时,触发索引覆盖。实现索引覆盖最为常见的方法为,将被查询字段建立到组合索引中。复合索引使用最左前缀原则,查询过程中使用最左边列。关系型数据库管理系统查询支持管理系统排序与指示函数数组两种排序方式。使用index 需要利用索引实现自动排序,效率相对较高。
2 存储模型设计与实现
2.1 存储需求分析
存储模型设计与实现能够有效解决海量数据存储过程中的数据存储问题,在批量应用数据过程中形成数据存储方案,规划低成本数据高并发读写操作路径;利用分布式文件系统、数据仓库与关系数据库,完成对结构、半结构与非结构化海量数据的高效并发与访问;一旦某个节点产生故障并被标记为不可用,快速完成数据恢复,保证高级别数据安全性,呈现出较为显著的扩展能力。
2.2 存储模型设计原则
第一,在设计原则上,需要以存储设备为核心,通过应用软件进行数据存储备份服务,根据不同逻辑功能,完成云环境下海量数据组织与资源共享的存储模型的分层。
第二,海量数据组织与资源共享的存储模型的设计需要符合具体业务需求与数据特征,有效确保数据存储高效性。
第三,在数据存储总体结构上需要以适应海量数据载量与业务需求增长为前提进行可扩展性的设计,要求考虑到海量数据规模的增大、系统运行负载的增加等综合因素,进行适配的大数据分区、分表与集群等[2]。
第四,数据存储模型总体结构设计需要高度关注大数据的安全性,在设计过程中需要针对性设计出合理的必要的数据访问权限、数据加密传输、数据备份与传输机制、防止数据泄露、网络攻击等安全防护措施。
第五,易用性是存储模型总体架构设计过程中需要遵循的原则之一,在设计过程中应当优先考虑数据存储实际需求和使用习惯,在模型架构设计上需要以简单易懂、易于维护和扩展的结构为首选。
2.3 存储模型架构和组织方式
2.3.1 基础设施服务层
基础设施服务层主要提供最为基本的计算资源、基础设施,在架构的这一层,通过虚拟化技术能够集成多种存储设备与物理服务器,在虚拟化实现方式上主要是在主机级别、存储设备级别与存储网络级别,借助虚拟化软件与系统完成存储设备的连接与运行逻辑虚拟化。
2.3.2 数据资源服务层
数据资源服务层通过集群功能实现、网络技术运行、分布式文件系统或类似虚拟服务器的联合,完成云环境下多存储设备的互联设置,在高度协同条件下达到运行目标,完成对各类数据的建立与维护,对空间与非空间进行索引,为数据组织提供数据管理与访问服务,体现出高效的访问效果。与此同时,利用数据与系统备份、容灾技术等,确保在处理海量数据过程中,不产生任何数据的丢失,保证云存储模型运行的数字化程度与安全化标准,与云存储系统的稳定性。
2.3.3 业务管理层
业务开放标准协议(Web-based distributed authoring and versioning, WeBDAV) 是基于超文本传输协议(hypertext transfer protocol, HTTP)1.1 的通信协议,能够直接添加其他新方法,同时能够对文件版本进行有效控制的管理,带有预见性地完成云环境下云存储系统不同服务内容的管理。
2.3.4 云应用服务层
云应用服务层支撑应用隔离、应用安全与服务集成整合等服务,能够在提供应用、服务的过程中实现针对海量数据的高速浏览,在完成数据统计分析过程中,提供门户服务等云环境下的云应用服务。具备授权的任何用户,可以通过较为标准的系统云应用接口进行系统登录,在运行模型的过程中,使用云存储模型中的海量数据资源及相对应的服务内容。见图1。
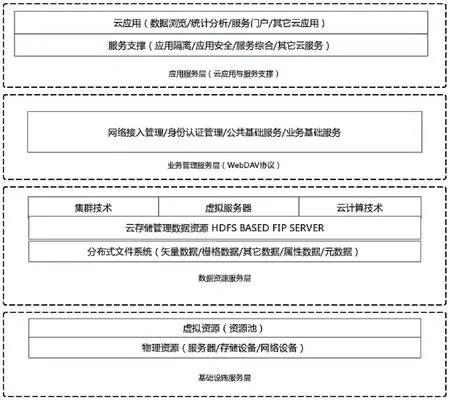
图1 存储模型架构图
3 资源共享机制研究
3.1 资源共享需求分析
进行资源共享过程中,需要构造资源标识,进一步完成寻址定位,通过统一资源标识符(uniform resource identifier, URI)对资源表现出的相应特征进行描述性分析,具有相同特征的资源应当根据属性的一致性放置于同一层,应当包含请求过程中所需要的全部信息。
针对本次研究所提出的云环境下的云存储模型结构对应的构造所产生的资源表示,在资源共享需求上,需要对应性预设索引中的时间与地理位置等,在设置完成后,将对应管理需求修改目录。
3.2 资源共享模型设计原则
资源共享模型设计强调以合作和共享的方式实现资源共享,通过建构共享资源平台、协同型项目或共同进行设备使用等方式予以实现。在设计过程中,资源共享模型更加关注资源的公平分配,在分配资源过程中,需要制定出公正的分配准则和标准,建立透明化的资源分配机制,通过公平的资源评估过程语义模型设计实现。资源共享模型设计的目标之一在于提升资源实际利用能效,规避资源重复浪费与购买行为,达成更高资源利用效率。
3.3 资源共享机制实现方法
定义资源共享目录的基础属性与数据指标,通过生成资源目录及相应的元数据,描述资源目录的指标项,进而建立和资源目录相关的数据表,在数据表属性与元数据属性上需要保持一一对应的效果。将元数据部分指标和全部指标作为数据查询基本条件进行发布,通过验证资源使用端口资源申请权限的有效性,构建服务接口,确保这些接口包含的资源查询条件能够满足实际的资源共享需求。[3]。假如资源共享申请权限已经通过验证,则对应性构建已经被选中的资源查询条件对应的服务接口,假如验证所属共享资源过程中使用端口的资源获取权限已经通过,则需要根据所描述的资源共享获取请求,进行相应数据表的调用和获取。
4 实验与结果分析
4.1 实验设置和数据集介绍
研究在通用识别任务完成过程中及识别任务上进行评估,在数据集中,为公平比较,研究使用标准数据集划分,运用数据增广和数据训练策略,通过训练确保子集间不产生类别的重叠,实验使用224×224 大小的图像进行输入,其他实验使用84×84 分辨率进行输入。模型经由连续3 个通道数完全一致的卷积层共同构成,网络的每个通道数量分别为64/160/320/640,基础架构–残差块(residual block, RB)数量为1/1/1/1。
4.2 存储模型和资源共享机制的性能评估
建构通用的存储模型和资源共享机制的性能评估框架,需要建立与存储模型和资源共享机制性能评估对应的性能评测指标[4]。通过借鉴存储系统性能评估指标,研究面向多维性能的评估指标,典型应用性能需要针对不同的测试类型、环境等进行性能测试,可以在确定测试环境的基础上完成测试实践等。较为常见的云存储系统应用如表1 所示。

表1 云环境下海量数据组织与资源共享存储模型典型应用表
面向不同接口访问类型的具体评测指标如表2 所示。

表2 云环境下海量数据组织与资源共享存储模型不同接口评估指标表
在性能分析评估过程中:第一阶段的因素分析主要针对模型性能与实例类型间关系、最优文件大小、云存储模型支持最大用户数量进行评估;第二阶段的分析在详细规划长期动态运行过程的条件下,对统筹性目标、内容、布局与规模的变化予以实时调整,在有效空间资源的条件支撑下,为系统优质的性能调整分析结果,最终提出具有针对性的导引建议[5]。
4.3 结果分析和讨论
4.3.1 评估指标及环境
针对存储模型的评估指标如表3 所示,评估拓扑图如图2 所示。

表3 云环境下海量数据组织与资源共享存储模型云存储接口评估指标表

图2 性能评估环境拓扑图
4.3.2 结果与分析
为排除异常数据干扰,评估通过去掉一个最大值和一个最小值的方式,进行评估结果的平均值取值。不同实例的配置信息如表4 所示。

表4 云环境下海量数据组织与资源共享存储模型不同实例配置信息表
文件传输速率与API 响应时间相对于其他实例配置明显更为优质,主要原因为上述两个类型实例为双中央处理器,内存为8GB,t2.large 实例类型的API 响应时间为上传6.917 s、下载8.701 s,m4.large 实例类型的API 响应时间为上传6.857 s、下载8.554 s。
5 结语
伴随互联网信息爆炸式剧增,云计算大数据技术的应用,海量数据的高效存储面临巨大难题。研究出于对海量数据统一组织与资源共享的实际需求,建立基于云计算与大数据技术的云存储模型,该模型能够实现分析、计算与存储海量数据的效率提升, 采用映射与归约(Map&Reduce)计算模型与优化策略,减少无关数据项的访问,保持海量数据写入过程的高效性、一致性。最终,通过实验测试,该海量数据组织与资源共享的存储模型能够有效克服传统存储模型在存储海量数据过程中存在的低效性。
