大规模图数据处理系统的分布式算法设计与性能优化
2024-05-03雷希媛李晓龙
雷希媛,李晓龙
(1 襄阳职业技术学院 湖北 襄阳 441022)
(2 武汉理工大学 湖北 武汉 430070)
0 引言
随着社交网络、生物信息学、网络安全等领域数据的爆发性增长,大规模图数据的处理成为一项极具挑战性的任务。传统的单机处理方式已无法满足日益增长的数据规模和处理需求,因此引入分布式系统成为处理大规模图数据的必然选择。然而,分布式图数据处理系统面临着复杂的算法设计和性能优化的问题。本文旨在通过深入研究图数据的特点、分布式算法的设计原理以及性能优化策略,为解决大规模图数据处理系统中的问题提供有效的解决方案。
1 大规模图数据处理系统概述
1.1 图数据模型特点与挑战
图论作为数学的重要分支,以图为研究对象,涵盖了超图理论、极图理论、拓扑图论等多个方面,丰富了图的表达方式。在大规模图数据管理中,采用多种数据模型,包括简单节点图模型和复杂节点图模型,以及简单图模型和超图模型,如图1 所示。
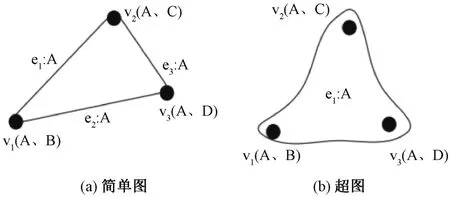
图1 简单图模型和超图模型示意图
简单图模型中,边连接两个顶点,允许存在环路,适用于一般应用,如PageRank 计算和最短路径查询。相比之下,超图模型允许一条边连接任意数量的顶点,更适用于保留更多信息的复杂联系,如社交网络和生物信息网络。
在图数据模型中,简单图模型存储和处理较为容易,适用于一般应用。超图模型则以超边连接任意数量的图顶点,保留更多信息,例如,用图顶点代表文章,边代表文章共享作者。对于复杂联系的应用,超图模型更具优势。图数据库系统如Trinity 支持超图模型管理大规模图数据[1]。
在大规模图数据处理中,图数据模型的特点和挑战是多方面的,主要包括图的复杂性、顶点和边的属性,以及对不同模型的存储和处理需求。解决这些挑战需要深入理解图数据的特性,合理选择适当的数据模型,并设计高效的处理系统以满足大规模图数据的管理和分析需求。
1.2 分布式系统应用于图数据处理的必要性
大规模图数据处理的必要性在于其庞大的规模和复杂的结构,传统的单机系统难以满足其高效处理的需求。分布式系统的应用成为必然选择,因为它能够克服单一计算节点的性能瓶颈,实现图数据的并行处理和存储。大规模图数据往往包含数以亿计的节点和边,而分布式系统可以通过将图数据划分为多个子图,并在不同计算节点上并行处理这些子图,从而提高处理效率。此外,分布式系统的弹性和容错性也为大规模图数据的处理提供了可靠的支持,保证了系统的稳定性和可靠性。因此,借助分布式系统的优势,能够更好地应对大规模图数据处理的挑战,提高系统的性能和可伸缩性。
2 分布式算法设计原理
2.1 图数据表示与存储模型
图数据的表示与存储模型是分布式算法设计的关键,图数据表示与存储模型的选择直接影响了算法的性能和效率。在大规模图数据处理中,通常采用邻接表或邻接矩阵等方式来表示图。设图G =(V, E)为包含顶点集合V和边集合E 的图,其中n为顶点数,m为边数。
邻接表表示方式通过一个顶点数组和一个邻接表数组来描述图,其中每个顶点数组元素v[i]包含一个链表,链表中存储与顶点i相邻的顶点信息。具体而言,邻接表的数据结构可表示为式(1)所示:
式(1)其中,Adj表示邻接表,vi为顶点i,{vj,vk}为与顶点i相邻的顶点集合。
而邻接矩阵采用矩阵A表示图,其中A[i][j]的值表示顶点i和j之间是否存在边,通常用0 和1 表示不存在和存在。邻接矩阵的表达式为式(2)所示:
这两种图的表示方式在分布式算法设计中的选择需根据具体问题和算法特点进行权衡。邻接表适用于稀疏图,能够有效节省存储空间;而邻接矩阵适用于稠密图,提供了更便捷的边存在查询[2]。因此,设计分布式算法时应结合图的特性,选择适当的表示方式以优化算法性能。
2.2 分布式图算法基础
在分布式图算法的基础中,Pregel 图计算模型是一种重要的设计原理。该模型以顶点为中心,通过将图计算任务分解为多个超步,在超步内并行执行每个顶点的计算,实现全局同步。
Pregel 采用了整体同步并行(bulk synchronous paralle,BSP)计算模型,将整个计算过程划分为多个超步。在每个超步中,图中的所有顶点都并行执行计算,然后通过全局同步来确保超步间的顺序关系。这种模型保证了计算的顺序性和一致性,有助于处理大规模图数据的复杂计算。
同时,Pregel 还使用了基于顶点的编程模型,其中每个顶点都有一个值。图计算的编码者可以采用Compute函数,在每个超步中,同步图系统对每个顶点调用一次Compute 函数,如图2 所示。Compute 函数通常包括接收消息、计算和发送消息等步骤,通过这种方式实现了以顶点为中心的图计算。

图2 图计算框架
最后,Pregel 图计算框架将顶点分为两种状态,即活跃态(Active)和非活跃态(Inactive)。只有活跃态的顶点才会在每个超步中执行Compute 函数,一旦某个顶点的Compute 函数调用Volt to Halt(停止运算),该顶点将变为非活跃态。当所有顶点都处于非活跃状态时,图系统结束本次图运算。
2.3 算法设计的可扩展性与容错性考虑
在大规模图数据处理中,分布式算法设计原理至关重要,尤其需要充分考虑可扩展性和容错性。可扩展性方面,算法必须能够在面对不断增长的图规模时实现高效性能提升,通过横向扩展、并行性和负载均衡机制应对图规模的动态变化。在容错性方面,算法应具备对节点故障和通信故障的灵活应对策略,包括节点故障的检测与处理、通信故障的处理机制以及保障数据一致性。这样的设计不仅确保了系统能够处理大规模图数据的挑战,还提高了系统的稳定性和可靠性,使其更适应复杂的分布式环境。以Pregel 图计算模型为例,该模型以顶点为中心,通过超步间的全局同步实现图计算,有效解决了多种大规模图计算问题,展现了在分布式环境下图算法设计原理的成功应用。
3 性能优化策略
3.1 数据分布与划分优化
在大规模图数据处理系统中,数据分布与划分的优化是性能优化的重要策略之一。合理的数据分布和划分可以有效减少通信开销,提高计算效率。具体而言,数据分布与划分的目标是使得每个计算节点能够尽可能地只处理与之相关的图数据,减少不必要的数据传输。常见的优化方法包括以下几个方面:
(1)顶点划分策略。将图的顶点划分到不同的计算节点上,使每个节点负责处理局部的图结构。这可以通过公式(3)表示:
式(3)中,P(v) 表示顶点v的分区;N(v)表示与顶点v相邻的顶点集合;I是指示函数,表示当括号内条件成立时取值为1,否则为0。这样的划分使得相邻的顶点尽可能被分配到相同的计算节点,减少跨节点的通信。
(2)边划分策略。将图的边划分到不同的计算节点上,降低节点间通信的数据量。边划分的目标是使得每个节点只需处理其相邻边的信息。这可以通过公式(4)表示:
式(4)中,P(e)表示边e的分区,V(e)表示边e相邻的顶点集合。通过合理的边划分,可以减少每个节点需要处理的边数,提高计算效率。
(3)负载均衡策略。在进行顶点或边的划分时,要考虑负载均衡,使得每个计算节点的计算任务相对均匀[3]。负载均衡可以通过考虑顶点或边的度数、计算复杂度等因素进行调整。
(4)动态划分策略。针对图数据动态变化的情况,设计能够自适应调整划分的策略,以适应图数据的变化。
通过以上优化策略,可以在大规模图数据处理系统中降低通信开销,提高计算效率,从而优化系统的性能。
3.2 通信与同步机制的优化
在大规模图数据处理系统中,通信与同步机制的优化是确保系统性能高效的关键策略。通信开销和同步操作对系统性能有重要影响,因此需要采取一系列优化手段。
首先,采用异步通信机制来减少通信开销。在传统的图计算系统中,节点间的消息传递通常是同步的,即每个超步结束时,所有节点进行消息的发送和接收。为了减少等待时间,可以引入异步通信机制,即节点在计算完成后立即发送消息,而无需等待其他节点。这种机制可以减少节点间的等待时间,提高通信效率。
其次,优化同步机制以提高计算节点的并行度。传统的同步机制要求所有节点在一个超步结束后进行同步,而采用细粒度同步机制,可以让部分节点先完成计算,而不必等待其他节点。通过引入细粒度同步,可以提高计算节点的并行度,充分利用计算资源,减少整体计算时间。
再次,采用压缩和精简消息的方式减小通信开销。在图计算中,节点之间的消息传递是常见的通信操作,通过对消息进行压缩和去冗余处理,可以减小数据传输量,提高通信效率。
最后,通过以上优化手段,可以有效降低通信开销,提高系统的整体性能。这些优化措施综合应用,能够使大规模图数据处理系统更加高效、可扩展。
3.3 分布式存储系统的性能优化
在大规模图数据处理系统中,分布式存储系统的性能优化是确保高效数据管理和访问的关键。为达到这一目标,系统需要综合考虑多方面的技术细节。
首先,数据分布与划分优化是优化分布式存储系统性能的基础。通过采用智能的数据分布策略,将图数据均匀划分存储在不同节点上,减少热点数据的集中,实现负载均衡。此外,采用分区策略,使得相关的数据存储在相邻的节点上,以最小化跨节点的通信开销,提高数据的本地性。
其次,通信与同步机制的优化对于分布式存储系统的性能提升至关重要。采用高效的通信协议和同步机制,减少节点之间的通信开销和同步等待时间。通过异步通信和轻量级同步方式,提高分布式计算的效率,保证系统在大规模图计算任务中的稳定性和可靠性。
最后,采用分布式存储系统的性能优化策略,包括数据压缩、索引技术以及缓存机制。数据压缩降低了数据在存储系统中的占用空间,提高了存储密度。同时,通过智能索引技术,加速数据检索过程,减少读取时间[4]。引入分布式缓存系统,将热点数据缓存在内存中,减少磁盘输入输出(I/O)开销,进一步提高数据的读写速度。
综合考虑上述策略,通过合理的数据分布、通信机制和存储系统优化,可以显著提升分布式存储系统在大规模图数据处理中的性能,实现更高效的数据管理和计算。
3.4 分布式计算资源动态调度策略
在大规模图数据处理系统中,分布式计算资源动态调度策略是确保系统在不同计算负载下高效运行的关键环节。该策略旨在实现对计算资源的灵活分配和优化利用,以适应动态变化的计算需求。
动态调度策略的核心在于实时监测系统中各个节点的计算负载和资源利用情况。通过使用监控指标,如CPU利用率、内存使用情况等,系统能够实时获取节点的运行状态。基于这些信息,动态调度系统可以智能地分配任务到相对空闲的节点,以保持系统整体的负载均衡。
一种常见的动态调度机制是基于负载预测的方法。通过历史负载数据和算法模型,系统可以预测节点未来的计算负载,从而提前做好资源调配的准备。这样的预测性调度可以有效降低系统的响应时间,提高资源利用率。
此外,动态调度策略还应考虑容错性,确保在节点故障或异常情况下能够迅速做出调整。通过实时监测节点的可用性,并及时将任务重新分配到其他可用节点,系统能够在不影响整体稳定性的情况下应对节点故障。
综合而言,分布式计算资源动态调度策略通过实时监测、负载预测和容错机制,使系统在不同计算负载下能够高效运行。
4 结语
在大规模图数据处理系统中,分布式算法的设计与性能优化是确保系统高效运行的关键因素。通过深入研究图数据模型的特点与挑战,本文探讨了分布式系统在图数据处理中的必要性,并提出了基于分布式算法设计原理的性能优化策略,为图数据处理领域的研究和实践提供了有力的理论支持。未来的工作可以进一步探讨新的算法设计原理和性能优化策略,以适应不断演进的大规模图数据处理需求。
