基于ElasticS earch的科技服务推荐系统设计与实现
2024-04-29刘勇,刘菲,蒙杰
刘 勇,刘 菲,蒙 杰
(甘肃省科学技术情报研究所∕甘肃省科技评价监测重点实验室,甘肃 兰州 730000)
1 研究概述
1.1 研究背景与意义
随着更多的社会资源进行网络化和数据化,大数据所能承载的价值不断提升,应用边界不断扩大,使用户获取各方面的信息更加便捷,帮助用户在繁复的信息中能够精准快速的筛选出自己所需的信息至关重要。推荐引擎技术已经渗入生活之中,如淘宝的猜你喜欢、QQ 的好友推荐、今日头条的文章推荐、网易云音乐的曲目推荐、Gmail 的广告推送等。用户看似使用的是同一款软件,但呈现的页面结果却是千人千面,这都与基于大数据不同维度的个性化推荐有关[1]。对于用户而言,提高单位时间的信息价值,减少噪声干扰的同时得到更好的信息体验;从应用角度来说,可以精准地定位到不同的用户,提高推广效果,减少用户流失的可能性。推荐系统已成为互联网公司营销体系中非常重要的一环并有实际的收益[2]。
1.2 研究现状
推荐是各大互联网公司十分重要的营收手段,一直备受工业界与学术界的关注。过去几年,推荐系统由早期的协同过滤算法[3]发展到MF模型、再到之后的Wide&Deep,以及基于Network Embedding的方法,可以明显地看到基于神经网络的方法正在逐渐占据主要位置,而GNN的出现又一次加速了技术趋势[4]。由于机器学习、深度学习技术的成熟,以及对各种复杂特征的应用方法逐步稳定。
在工业界,国内科技公司如京东、淘宝等都在普遍利用机器学习来构建推荐系统,推荐系统普遍应用于生活中并且取得了明显进步,但也面临着数据稀少、用户行为的复杂性、业务的多样性、冷启动、精确性的两难窘境。
在学术界,中国学者在推荐系统中广泛应用深度学习技术,如卷积神经网络(CNN)和循环神经网络(RNN)等,以提高推荐性能[5]。一些研究关注将社交网络信息整合到推荐系统中,以提高个性化推荐的准确性。针对多种类型的数据(文本、图像、音频等)进行推荐的研究逐渐增多,这有助于更全面地了解用户兴趣。针对实时性要求较高的应用,研究者致力于设计能够快速适应用户兴趣变化的实时推荐系统。
1.3 创新点及优势
(1)系统采用ElasticSearch 搜索引擎,相较于关系型数据库,检索速度更快。
(2)系统采用ElasticSearch 搜索引擎,引用第三方插件IKAnanlyzer分词器,增加自定义词库对数据进行分词处理,让搜索引擎更加高效和准确。
(3)系统有效的解决了冷启动问题。对于用户冷启动问题,解决办法是将所有用户近几天查看的相关产品推荐给新用户。对于物品冷启动问题,文章的解决办法是增加资源最近上新时间权重,将新增的物品推荐给可能会感兴趣的用户。
(4)对于开发者而言,无需了解太多复杂算法,大大减少了学习成本,极大地提高了开发效率。
2 推荐系统的设计
该系统以科技创新公共服务平台积累的大量科技服务、科研店铺、科学仪器、技术转移、专家信息等数据为支撑,依托ElasticSearch 大数据分析挖掘技术,采用TF-IDF、LUCentere、热词统计发现算法等算法,计算每个文档的相关性得分,对其进行推荐排序。系统功能结构如图1所示。
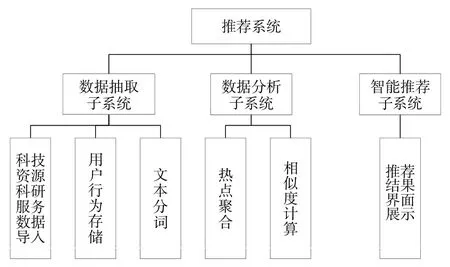
图1 系统功能结构图
2.1 数据抽取子系统
(1)数据导入
将科技资源、科研服务等数据信息从SQLServer关系型数据库中采用Python 程序异步批量导入ElasticSearch 中,其中数据字段包含主要介绍内容、时间、名称、所属科学领域、收藏数、收藏区间上升数、点击量、点击区间上升数、点赞数、点赞区间上升数,每12 h 运行一次Python 程序进行一次定时数据更新。
(2)用户行为存储
在ElasticSearch 中创建一个用于存储用户搜索、浏览、购买、评论等信息的索引,将用户的id、所查看服务的分类、服务名称、服务内容、服务所属店铺等信息存入该索引中。数据类型见表1。
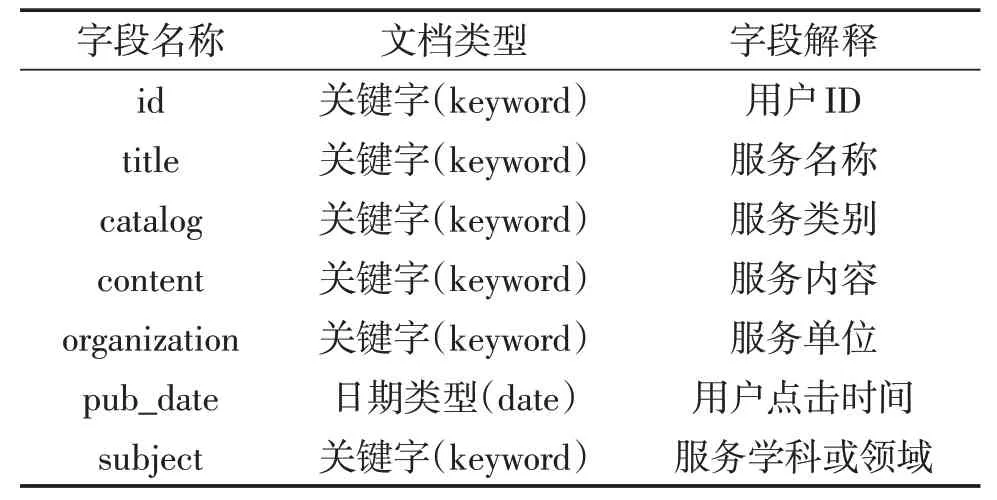
表1 数据存储类型
其中用户点击时间存储为日期类型,便于后续进行时间区间检索;服务名称与服务内容存储为全文本(text)类型,便于日后进行排序聚合,其他存储均为关键字(keyword)类型。
ElasticSearch 中字符类型包括text 类型与keyword类型,text类型的数据被用来索引长文本,在建立索引文档之前会被分词器进行分词,转化为词组。经过分词机制之后ES 允许检索到该文本切分而成的词语,但是text类型的数据不能用来过滤、排序和聚合等操作。keyword 类型不支持文本分词但可以进行过滤、排序和聚合。
text 类型的字段若想进行排序和聚合,则需要在设置字段时设置fielddata为“true”。fielddata的结构与正排索引非常相像,构建和管理都在内存中并常驻于JVM内存堆,加载太多的数据到内存会导致垃圾回收(gc)缓慢,甚至可能导致OutOfMemory 异常,一般不推荐使用[6]。为了限制fielddata使用大量的内存,则需要设置indices.fielddata.cache.size 参数,该参数控制fielddata 堆内存分配。当执行一个查询需要访问新的字段值的时候,将会把值加载到内存,然后试着把它们加入到fielddata。如果fielddata大小超过指定的大小,为了腾出空间,别的值就会被驱逐出去。默认情况下,这个参数设置的是无限制,即Elasticsearch 将永远不会把数据从fielddata里替换出去,这个设置是一个保护措施,而不是一个内存不足的解决方案。使用默认的设置,来自老索引的fielddata不会被清除出去,fielddata会一直增长直到阻止你继续加载fielddata,在那时程序将会被卡住。为了避免这类情形产生,需在config∕elasticsearch.yml 文件里加上indices.fielddata.cache.size的值为20%的配置给fielddata 设置一个上限,最久未使用(LRU)的fielddata 将会被回收,给新加载的数据腾出空间。
(3)文本分词
由于ElasticSearch 的内置分词器对中文有一定的局限性,本系统引用第三方插件IKAnanlyzer分词器,IK分词器包含ik_max_word和ik_smart两种分词模式[7]。ik_max_word 为最大限度分词,而ik_smart尽量以词语的形式分词。IK分词器虽然优于ES提供的默认分词器,但是仍存在一个弊端,即不能识别网络中的热词或者一些小区名等,故需自定义一些词汇用于分词处理。首先定义扩展字典,如“兰州大学”“科学技术”“高新技术企业”等的专有名词,可在分词时不拆分;再定义扩展停止词字典,如“①”“&”“虽说”等一些无关紧要的语气助词、动词、形容词等,可在分词时对停用词进行屏蔽与过滤处理[8]。
2.2 数据分析子系统
(1)过滤与聚合
根据用户ID 对近1 个月到近7 d、近7 d 两个时间段的行为进行聚类统计,再对所有用户近1 个月到近7 d、近7 d两个时间段的行为进行聚类。
采用热词统计发现算法中的加权变化率对热词进行计算。首先对近7 d聚类的采录访问主题词进行循环,当其中元素的字符长度小于2,跳出本次循环执行下一次循环。否则,判断其中元素是否存在于近1 月至7 d 聚类出现结果全集中。若匹配到之前存在这个词,则令匹配到之前的次数为近1 月至7 d聚类出现结果全集中该元素出现的总次数,否则令匹配到之前的次数为0。该元素加权变化率:
其中:CZ为近7 d 搜索次数,Cqq为匹配到之前的次数。若加权变化率小于0,则将该元素放入停用词数组中,否则判断停用词数组中是否包含该元素。若停用词数组包含该元素则跳出此次循环进入下一循环,若不包含该元素则令该元素权重为1.1×该元素加权变化率,将该元素和权重放入热词数组中,具体流程如图2所示。
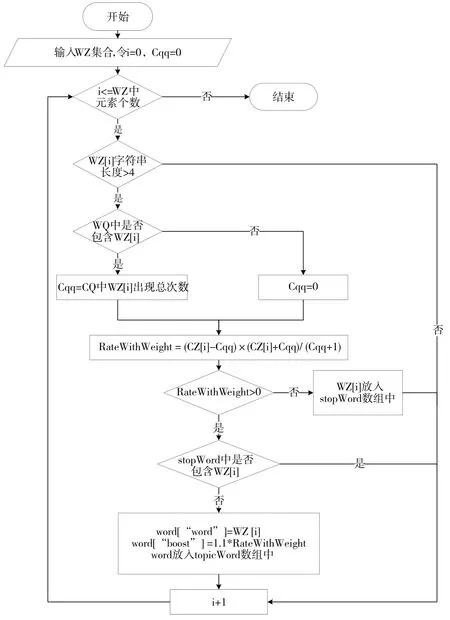
图2 热词加权流程图
其中WQ为近1月至7 d聚类出现结果全集,CQ为近1月至近7 d聚类检索总次数,WZ为近7 d搜索词全集,CZ为近7 d搜索总次数,Cqq为匹配到为近1 月至近7 天的搜索次数,stopWord 为停用词,topicWord为热词,RateWithWeight为加权变化率。
(2)相似度计算
采用TF-IDF、LUCentere相关性等算法,将热词集合与库中数据进行相似度计算排序。
首先提取热词,通过标题、内容、单位等字段进行匹配,将最小匹配度设置为80%,按照相关度进行排序显示。其中在标题字段上加权重,使得词干出现在标题字段上比出现在其他字段上的文档匹配分值高。
其次,按受欢迎度提升权重,将收藏数、收藏区间上升数、点击量、点击区间上升数、点赞数、点赞区间上升数、产品上新时间作为考虑因素分别设置权重进行分值处理计算。公式为:
其中:old_score 为之前分数值;new_score 为现在分数值;number_of_votes表示收藏数;收藏区间上升数等考虑因素的值,factor 值大于1 会提升效果,factor值小于1会降低效果。
然后,对文档中的发布时间字段设置一个理想的值,如果实际的值越偏离这个理想值(无论是增大还是减小),就越不符合期望,分数就越低。系统采用高斯衰减函数,若将当前日期设的为原点,所有距原点前7 d 范围内的位置的评分是1.0,距原点30 d的位置评分是0.5。
最后,将各个部分分值相加合并成一个综合的分值,然后再将综合的分值与查询分数相乘,见表2。

表2 文档得分表
2.3 智能推荐子系统
经过数据采集、清洗、导入、用户行为存储、文本分析、过滤、聚合、相似度计算、倒排索引等操作,采用Bootstrap 框架进行前端页面的显示,利用Ajax技术实现前后端交互,采用HTTP 协议与数据库通信,网络采用FTTX+LAN 光纤线路实现访问ChinaNET和CerNET自动分流。
2.4 系统性能测试
系统测试数据主要源于科技创新公共服务平台经过特殊处理后的历史数据,数据量约有1万条,搜索性能见表3。

表3 搜索测试结果
从表3 分析可知,对于大量的数据检索,ES 检索所花费的时间远低于传统的数据库检索。
3 相关技术
3.1 热词统计发现算法
求热词时,单纯比较每天词条的出现次数是不行的,主要是需要比较多天之间的出现次数。具体有以下算法。
(1)排位差
算法的核心思想是根据词语每天出现次数求出其排在第几,之后计算2 d的排位差,根据排位差求热度。
首先,统计每一个词在昨天和前天出现的次数,并找出排位前N 的词语集合。其次,计算每个词两天的排位差。最后,根据词语的排位差进行排序,其中排位变化最大的就是最热的词。
如果昨天出现的词前天也同样存在则排位差的公式为:
式中:Position(w,昨日)表示词条昨日排位,Position(w,前日)表示词条前日排位。若昨天出现的词前天并未出现则排位差的公式为:
式中:N为词条前日全部排位数。词条这两天的排位差PositionChange越小,表示其越火。虽然此算法比较笨,必须作三次排序,但是挑选出的词语效果还是比较好的。
(2)变化率
算法核心思想是根据词语2 d的出现次数求出其出现次数的比值,根据比值求出其热度。
首先,统计每一个词在昨天和前天出现的次数,并找出排位前N 的词语集合。其次,计算每个词这两天的变化率,即今日次数∕昨日次数。最后,根据词语的变化率进行排序,其中变化率最大的就是最热的词。公式如下:
式中:Cz为某词昨日访问频次,Cq为某词前日访问频次。该算法虽然简单,但是对于访问次数少但变化率大的词语会占便宜。
(3)加权变化率
加权变化率是对于算法2 的修正,考虑搜索量因素,根据词语2 d 的出现次数和其在总搜索次数的站的份额求出比值,根据比值求出其热度。
首先,统计每一个词在昨天和前天出现的次数,并找出排位前N 的词语集合。
其次,对每一个词,计算每个词这2 d的加权变化率。
式中,CZ为昨日搜索总频次,CQ为前日搜索总频次。最后,根据词语的加权变化率进行排序,其中加权变化率最大的就是最热的词。
3.2 Lucene的实用评分函数
Lucene[9]的评分是叫做TF∕IDF 算法,根据分词词库,所有文档在建立索引的时候进行分词划分。进行搜索的时候,也对搜索的短语进行分词划分。lucene的算法简单来说就是将搜索的短语进行分词得出分词项,每个分词项和每个索引中的文档根据TF∕IDF进行词频出现的评分计算[10]。然后每个分词项的得分相加,就是这个搜索对应的文档得分,公式为:
式中:score(q,d)是文档d与查询q的相关度评分。
queryNorm(q)为查询归一因子,查询归一因子将查询归一化,使最终的得分不至于太大,从而具有一定的可比性。
coord(q,d)是协调因子表示输入的Token 被文档匹配到的比例,可以为那些查询词包含度高的文档提供奖励,文档里出现的查询词越多,它越有机会成为好的匹配结果。如果检索“你好朋友”,设每一个词的权重为1.2,若没用协调因子,最终评分会是文档里所有词权重的总和。比如文档里有“你好”这一词则评分为1.2;文档里有“你好朋友”则评分为2.4。协调因子将评分与文档里匹配词的数量相乘,然后除以查询里所有词的数量,如果使用协调因子,文档里有“你好”评分会变成1.1×1∕2=0.6,文档里有“你好朋友”评分会变成2.4×2∕2=2.4。
tf(tind)是词t 在文档d 中的词频,频率越高,得分越高。
idf(t)指的是词在集合所有文档里出现的频率越高,权重越低,可以快速缩小范围找到感兴趣的文档。
t.getBoost()是查询中使用的权重。
norm(t,d)为长度的加权因子,主要是为了在文档都匹配的情况下将较短的文档增加权重排在前面。
∑(tinq)是查询q中每个词t对于文档d的权重和。
3.3 聚合分析
聚合分析运算是数据库中重要的特性,对于数据分析场景尤为重要。类似于关系型数据库中的SUM、AVG、GROUP BY 等,ElasticSearch 也提供了丰富的聚合运算方式,可以满足大部分分析和查询场景。桶的叫法和SQL 里面分组的概念是类似的,一个桶就类似SQL 里面的一个group,多级嵌套的aggregation,类似SQL 里面的多字段分组。基于分析规则的不同,ES 将聚合分析主要划分为Metric、Bucket、Pipeline及Matrix[11]。
(1)Metric
Metric 是指标分析聚合,其主要分为单值分析和多值分析这两类。
单值分析可以同时使用多个单值分析关键词返回多个结果。主要包括以下:
min:返回数值类型字段的最小值。
max:返回数值类型字段的最大值。
avg:返回数值类型字段的平均值。
sum:返回数值类型字段值的总和。
cardinality:返回不重复的总个数。
weight avg:在计算平均数时会使用另外一个字段作为每个文档的权重。
value count:统计某字段所有有值的文档数。
多值分析可以输出多个结果。主要包括以下:
stats:一次性返回所有单值结果。
extended_stats:对stats进行扩展,包含更多,如:方差,标准差,标准差范围等。
percentile:百分位数统计,比如用于统计95%的员工工资都小于某个值或者大于某个值。
percentile rank:和percentile 统计方向相反,比如用于统计工资小于2 万的员工落在哪个百分比上。
top hits:一般用于在查询结果中返回每个桶(bucket)中的顶部N 个文档,使用时一般需要带上排序信息。
(2)Bucket
分桶聚合,将满足同一种条件的数据放在一个桶中,类似于关系型数据库中的group by 语法,根据一定规则按照维度进行划分成不同的桶。与指标聚合不同的是,桶聚合可以进行嵌套,大桶里面可以套小桶,对大桶的数据再次筛选并且可以嵌套多层。常见的有以下5类:
Terms:直接按照term 进行分桶,类似数据库group by 以后求和,如果是text 类型,按分词后的结果分桶。
Range:按指定数值范围进行分桶。
Date Range:按指定日期范围进行分桶。
Histogram:直方图,按固定数值间隔策略进行数据分割。
Date Histogram:日期直方图,按固定时间间隔进行数据分割。
(3)Pipeline
管道分析类型,支持对聚合分析的结果再次进行聚合分析,且支持链式调用。pipeline的分析结果会输出到原结果中,因输出位置不同,分为:Parent和Sibling。Sibling 是同级聚合,对当前同一级的聚合数据进行处理,操作后的数据不会影响其他聚合的输出,会生成新的桶,使用兄弟管道聚合同级必须有两个或以上的聚合。Parent是对父聚合处理后的数据进行处理,返回值不会生成新桶,而是在原有桶内。
(4)Matrix
矩阵聚合,类似于分别使用Metric 的多值聚合对数据进行聚合,并且不支持脚本。
4 结语
文章依托ElasticSearch 大数据分析挖掘技术,通过热词统计算法挑选出个人用户和全部用户的前100的热词,再将其与库中文档进行相似度计算,对科技服务的喜爱度、点击率权重提升,最后进行综合评分。结合个人用户与全部用户喜爱度,通过设置不同权重来推荐商品,不仅满足用户个性化推荐,而且使推荐商品更加多样。使用ElasticSearch提高了推荐速度、简化开发步骤,采用文章推荐方法提高了推荐的准确性,并且有效的解决了“冷启动”问题。但还存在不足,之后将深度挖掘数据,发现更多符合用户感兴趣的信息,进一步提高推荐的多样性。
