基于双重注意力残差模块的低照度图像增强
2024-04-29杜韩宇唐保香廖恒锋叶思佳
杜韩宇,魏 延,唐保香,廖恒锋,叶思佳
(重庆师范大学计算机与信息科学学院,重庆 401331)
0 引 言
低照度条件下获取的图像存在亮度偏低、大量噪声、细节模糊等问题,受这些因素影响,图像处理的高层任务(如目标检测[1]、图像分割[2])的效果也较差。因此学者们针对低照度图像增强(Low Light Image Enhancement,LLIE)进行了大量的研究工作[3~7],LLIE成为了图像处理领域的热门研究内容。
传统LLIE 算法包括基于直方图均衡化的方法[8-9]和基于Retinex 理论的方法[10~12]。这些方法在一定程度上提高了低照度图像的亮度和对比度,但是需要根据先验知识手动设置参数,对不同类型图像的适应能力较差,并且对大规模数据测试的效果不佳。
近年来基于深度学习的LLIE 方法由于其优异的性能,逐渐成为主流的研究方向。Lore 等人[13]提出了基于深度学习的LLIE算法LLNet,这是一种采用深度自编码器对低照度图像进行对比度增强和去噪的方法,缺点是没有使用真实场景下的低照度图像进行训练。Wei 等人[14]将Retinex 理论与深度学习方法结合,提出了Retinex-Net。该模型包括一个将输入图像分解为与光无关的反射图和结构感知的光照图的分解网络和一个调整光照图,从而达到低照度增强的增强网络,并且贡献了第一个在自然真实条件下拍摄的数据集:LOL数据集。但该方法存在的问题是分解网络采用浅层的上/下采样设计,得到的分解图比较模糊且存在大量噪声。Wang 等人[15]提出了一种能感受和提升全局光照与细节的端到端网络GLADNet,但其基于纯卷积网络设计,缺少语义信息的指导,导致增强结果存在伪影。Lyu 等人[16]提出了一种端到端的多分支LLIE 模型MBLLEN,该模型使用了特征提取、融合和增强3 个模块来高效地增强低照度图像。Jiang 等人[17]提出了EnlightenGAN 模型,该模型使用了无监督学习方法,摆脱了必须用成对的数据集训练的约束,但在GAN 上的训练却是不稳定的,需要仔细选择非配对的训练数据。Guo 等人[18]提出了一种无参考深度曲线估算网络Zero-DCE,通过直观和简单的非线性曲线映射来实现图像增强,后续又提出了更为轻量快速的模型Zero-DCE++[19],但是由于训练的曲线只能调整光照,没有同步去噪,对极暗图进行增强后噪声也会被放大。Kwon 等人[20]提出了DALE 算法,该方法能够精确识别黑暗区域并增强,使图像光照更平滑。Zamir等人[21]提出了MIRNet,该模型通过递归残差模块学习图像的深层特征,充分还原了图像细节,但是计算复杂度高,需要消耗大量计算资源。Zheng 等人[22]提出了一种自适应展开全变分网络UTVNet,该网络通过学习基于模型的全变分正则化去噪方法中的平衡参数来逼近真实图像的噪声水平。
尽管基于深度学习的LLIE 算法能改善低照度图像的光照,但仍存在以下几点问题:1)上述许多深度LLIE模型仅使用堆叠卷积或上/下采样的方式设计网络,网络层数过浅无法提取图像深层特征,导致图像噪声消除不彻底,网络层数过深则可能导致反向传播过程中损失图像细节;2)许多算法的损失函数对网络训练约束不全面,导致的增强图像细节损失和色彩失真严重;3)上述方法中,很多使用了合成的低照度图像作为训练集,但现实世界中图像会有不同情况的照明条件以及噪声情况,合成图像不能准确代表现实情况。
为缓解以上问题,本文设计一种基于残差网络与视觉注意力的LLIE 算法。该算法将双重注意力与残差模块融合作为主干网络的主要构成部分,并添加卷积神经网络构成细节恢复子网络。网络中使用了双重注意力单元(Dual Attention Unit,DAU)用于捕获图像空间域和通道域的信息,并附上相应权重。特别地,本文提出一种融合双重注意力的残差模块(Dual Attention Residual Block,DA-ResBlock),利用残差网络的“残差连接(Shortcut)”机制[23],减少模型提取图像深层特征时的损失;DAU 使网络在训练时更注重对黑暗区域的增强以及抑制噪声和伪影产生;在DA-ResBlock 内部的卷积使用了具有多级感受野的膨胀卷积,可以获取更丰富的上下文信息,进一步减少图像特征的损失。在损失函数上,本文使用注重恢复图像色彩和亮度的L1损失和注重恢复图像纹理的多尺度结构相似度(Multi-scale Structural Similarity,MS-SSIM)损失。通过在现实场景中拍摄的公共数据集上进行大量实验验证,本文算法在亮度提高、色彩与细节恢复、噪声与伪影控制这几个方面取得了令人满意的视觉效果,在评价指标PSNR(Peak Signal-to-Noise Ratio)、SSIM(Structural Similarity)与LPIPS(Learned Perceptual Image Patch Similarity)上,与近些年主流算法相比取得了更好结果。
总之,为了缓解上面提出的几点问题,本文主要做以下3点工作:
1)针对上述问题1,提出融合了DAU 的残差模块DA-ResBlock,用于图像深层特征的提取和噪声的抑制。DAU 可以增强卷积神经网络对于图像细节的感知,提高网络的非线性表示能力。DA-ResBlock 中的残差结构可增强网络的信息传递能力。
2)针对上述问题2,本文使用将MS-SSIM 损失和L1 损失结合起来的复合损失函数,以便更好地平衡图像色彩和纹理的恢复。通过使用这种复合损失函数,可以保证图像增强效果的全面性和准确性。
3)针对上述问题3,提出基于双重注意力残差模块的低照度图像增强网络,在多个提供真实图像的公共数据集上进行训练,从而提高算法的鲁棒性和泛化能力。
1 相关研究
1.1 ResNet
在LLIE 任务中网络层数越深越能提取到低照度图像的深层特征,但是过深的网络模型会导致数据浅层特征丢失以及梯度消失问题。He 等人[23]设计的ResNet 解决了此问题。ResNet 的基本单元为残差模块(Residual Block,ResBlock),它由2个权重层、1个激活函数和1 个“残差连接(Shortcut)”组成,如图1 所示。假设输入为x,理想输出为F(x),普通的2层卷积网络(Conv)要学习复杂的非线性映射来拟合F(x)。Shortcut 直接把输入特征图和ResBlock 的输出相连,只需拟合F(x)-x,优化后更简单,也减少了梯度消失和特征丢失的风险。
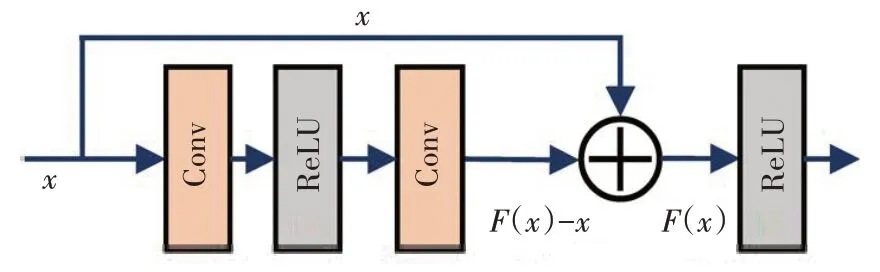
图1 ResBlock结构
近年来,很多研究者受ResNet 启发,提出应用了残差结构的LLIE 算法,如潘晓英等人[24]提出的FRED-Net。它利用了残差块和密集上下文特征聚合模块来增加特征多样性和聚合全局多尺度特征,但残差块的结构较为简单,可能限制了网络对复杂特征的提取效率。
1.2 视觉注意力
视觉注意力在LLIE 中的应用主要是通过引入注意力模块对图像的特征进行加权,使得模型能够更加关注有用的特征,从而提高图像增强的效果。这种方法能够克服低照度图像增强中光照不均匀、图像噪声等问题。一般可将注意力按域划分为通道域、空间域以及混合域。
1.2.1 通道注意力
对于通道注意力(Channel Attention,CA),在LLIE 中输入的图像一般都是三通道,每个通道经过不同卷积核后产生不同的特征图,为了更好地保存与该通道相关的信息,应给每个通道附上权重,权重越大的通道所包含的信息与任务相关性越大,再使用CA 学习每个通道的权重,以产生通道注意力图。具体如图2 所示,CA 通过挤压(Squeeze)和激励(Excitation)操作[25]学习每个通道的权重,并利用卷积特征映射通道间的关系。给定特征图F∈RC×H×W(R 为实数集,C、H、W为通道数、高、宽),挤压操作使用全局平均池化(Global Average Pooling,GAP)来编码全局上下文,从而产生一个特征描述符d。激励操作将d通过2个卷积层,第一个卷积用ReLU 激活,第二个卷积用Sigmoid 激活,生成特征描述符d′∈RC×1×1,最后将d′与输入特征图相乘(⊗)得到通道注意力图Mc。

图2 通道注意力
1.2.2 空间注意力
为了对图像中黑暗区域进行针对性增强,使用空间注意力(Spatial Attention,SA)对输入图像中与增强任务相关的特征位置信息添加权重。SA 利用卷积特征的空间相关性,能实现输入图像的空间信息在不同空间的转换,以提取低照度区域关键位置信息并附上相应权重,最后输出相应的空间注意力图。具体如图3 所示,首先独立地沿着通道维度对特征F进行全局平均池化(GAP)和全局最大池化(Global Max Pooling,GMP)操作,并将输出进行拼接,形成特征图f,通过卷积和Sigmoid 激活得到空间注意映射f′,最后将f′与输入特征图相乘得到空间注意力图Ms。
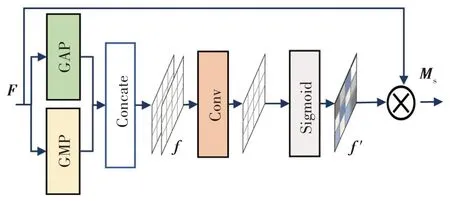
图3 空间注意力
混合域注意力机制的实现通常使用通道注意力和空间注意力来提取不同域的特征,然后将2 种注意力机制生成的加权特征进行融合,得到最终的特征表示。本文算法中使用的DAU 属于混合域注意力,具体将在2.1节进行描述。
近年来,很多研究者已经将视觉注意力结合到LLIE 算法中,如谌贵辉等人[26]提出的MMCA-Net,它利用多阶段并结合注意力机制实现低照度图像增强的方式,有效克服了因图像内容重叠和亮度差异大的影响,得到的图像细节更丰富,但所提出的注意力模块较为复杂,模型整体参数量较大。
2 基于双重注意力残差模块的LLIE算法
本文将LLIE 任务分解为光照增强和细节恢复2个子任务,分别对应子网络增强网络(Enhancement Network,EN)和细节恢复网络(Detail Restoration Network,DRN),分步骤完成这些子任务产生最终输出。
2.1 增强网络
增强网络部分的主要任务是完成光照增强和色彩恢复,但图像边缘细节可能仍不完善。如图4(a)所示,该网络首先经过卷积核为3×3 的卷积层将3 通道调整为64 通道,再通过3 个串联的DA-ResBlock,块内分别使用了膨胀因子从3 到1 的膨胀卷积,以序列的形式协同渐进地提取不同尺度的上下文特征,处理输入的低照度图像数据流。然后将所有DAResBlock 在通道维度拼接为192通道,通过DAU 给拼接后图像的通道和空间赋予相应的权重,提取出包含图像空间信息与通道色彩信息的注意力图。最后经过2个3×3的卷积层将通道调整为64通道,同时学习注意力图中的特征信息。
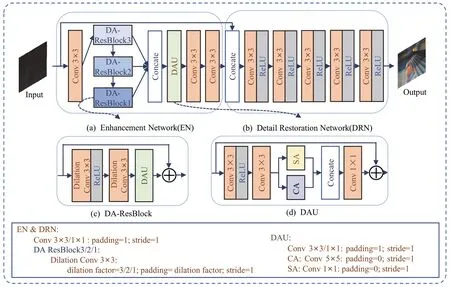
图4 本文方法的网络结构图
本文1.2 节提到CA 对通道内的信息进行全局平均池化,但这样无法关注每个通道内的局部信息,而SA 将每个通道中的图像特征做一样的处理,但在图像特征提取阶段,通道中的信息却被忽略了。为了结合2 种注意力各自的优势,本文的模型中使用将CA与SA 结合的DAU 来共享通道与空间维度的信息,具体实现参考文献[21]所提出的双重注意力模块,结构如图4(d)所示。
2)DA-ResBlock。
为了实现高效稳定地提取图像的深层特征,同时减少浅层特征损失,本文将DAU 与膨胀卷积融入ResBlock 内部设计了DA-ResBlock,结构如图4(c)所示。该模块利用了残差网络中的“Shortcut”机制,保证了提取深层特征的同时不会丢失浅层特征,提高了训练的稳定性。DAU 的加入使得网络更加关注图像黑暗区域的增强,并减少噪声和伪影,从而提高了网络应对复杂场景的泛化能力和鲁棒性。此外还借助调整膨胀因子大小来增大网络的感受野,获取更丰富的上下文信息,进一步减少了图片细节在训练过程中的损失。
2.2 细节恢复网络
经过增强网络处理后的低照度图像的亮度和色彩已经得到了一定程度的增强,为了使结果图像更接近标签图像,本文设计一个细节恢复网络对增强图像做进一步优化,结构如图4(b)所示。因为原始输入含有更多图像细节,所以首先将增强网络的输出与原始输入图像拼接,然后依次通过5 层ReLU 激活的卷积层来还原更多图像的细节特征。其中拼接后输出通道为67 通道,经过第一层卷积调整为128 通道,之后3 层卷积通道数不变,最后一层卷积将通道数调整回3通道得到最终输出。
2.3 损失函数
L1损失能够保护色彩和亮度,但是它会忽略局部结构,MS-SSIM 损失保留了结构和纹理,但是对均匀的误差敏感性较低,会使处理结果偏暗并且色彩失真[27]。于是本文选择将L1损失与MS-SSIM 损失结合,使得两者优势互补。定义为:
式中,λ为平衡2种损失的权重参数,通常λ的取值小于0.5,因为MS-SSIM 损失更能反映人眼对图像质量的感知,这里取λ=0.16[27]。
L1损失取值为(0,∞),其值的大小与增强后图像与标签图像的绝对误差呈线性关系,能够很好地衡量增强图像与标签图像的差异,并且L1损失对于部分偏移正常范围的样本具有鲁棒性。在LLIE 任务中不管图像的纹理结构如何,惩罚错误的权重都是相同的,所以能够很好地保护图像色彩和亮度[27]。定义为:
高职院校实施二级财务管理是提升高职院校二级学院地位的必然之举 高职院校在发展之初,规模较小,每个系部的教师和学生数量较少,一般高职院校很难实施二级管理。伴随着近十余年的高速发展,高职院校的学生数量和每个系部的教师数量呈现直线上升的趋势,每个系部开设的专业也越来越多,原有的模式很难推动高职院校进一步发展。在此背景下,实施二级财务管理,通过建立对等的责、权、利经济责任,可以很好地调整二级学院工作积极性和主动性。此外,实施二级财务管理体制,可以很好地引导二级学院面向市场设置专业,提升职业教育人才培养质量。
式中,N表示样本数,IGT和IEN分别表示标签图像和增强图像。
SSIM用于计算2张图片的相似程度,对图片纹理结构的变化敏感,所以作为损失函数能很好地约束图像的结构损失。MS-SSIM 相较于SSIM 考虑了图片的分辨率,能更好地保留高频信息,即图像的边缘细节,作为损失函数能够在增强过程中引导网络很好地保护图像的结构和纹理[28]。定义为:
式中,x、y表示增强图像和标签图像,M表示不同尺度,μx、μy为x和y的像素平均值,、为方差,σxy为协方差,βm和γm表示2项之间的相对权重,C1和C2为避免分母为0的常数。
3 实验结果与分析
本文实验在Windows10 64 位操作系统上用Python 语言进行设计,在Pytorch 框架上进行实验。硬件条件为Intel Core i9-10920X 处理器,NVIDIA Ge-Force RTX3090 24 GB 图形处理器,内存为128 GB。
3.1 数据集及实验参数配置
本文选取2 个常用公共数据集进行实验,分别为LOL数据集[14]以及MIT-Adobe FiveK 数据集[29]。
LOL 数据集是在真实场景中拍摄的低照度与正常照度图像的配对图像数据集,使用变更曝光时间和ISO 的方式获得低照度图像。LOL 数据集中包括500幅尺寸为400×600 的低照度/正常照度图像,图像格式为RGB 格式。本文选取其中485 幅图像作为训练数据,15对图像作为测试数据。
MIT-Adobe FiveK 数据集包含5000 幅由专业摄影师拍摄的高质量图像,图像格式为raw 格式。因为本文能够处理的图像格式为RGB 格式,为了能有效训练,本文使用Adobe Lightroom 软件按照大多数实验配置,将图像预处理为保持纵横比长边为500 像素的RGB图像。使用数据集前4500幅图像作为训练数据,后500幅图像作为测试数据。
在参数配置方面,本文使用Adam 优化器对模型参数进行优化,初始学习率设置为0.0001,每训练10个epoch 将学习率下调4%。在LOL 数据集上训练批次大小设置为4,迭代1000 次。在MIT-Adobe FiveK数据集上训练批次大小设置为1,迭代100次。
3.2 实验分析
为了评估算法的性能,将本文与近几年主流LLIE 算法GLADNet[15]、MBLLEN[16]、DALE[20]、MIRNet[21]、Zero-DCE[18]、Zero-DCE++[19]、UTVNet[22]等在LOL 数据集和MIT-Adobe FiveK 数据集上进行对比实验,为了确保公平性,所有实验在相同环境下进行。
3.2.1 主观评价
首先对比近几年主流模型在LOL 数据集上的增强结果,如图5 所示。本文从测试图像中选择“书橱”和“泳池”2幅图像作为示例对比。

图5 不同方法在LOL数据集上增强结果的视觉对比
从图5 中可以看出,本文对比的算法在LOL 数据集上都能对低照度图像进行一定程度的增强,但GLADNet 和UTVNet 的增强结果在红色方框框出的“书橱”图像右侧以及“泳池”图像的墙壁上存在一定程度的白色伪影;MBLLEN 的增强结果存在色彩失真问题,在“泳池”图像中蓝色方框框出的“电子钟”边缘部分存在黑色伪影;DALE 的增强结果图像平滑,但相较其他算法亮度偏暗;MIRNet 增强结果与本文提出的算法增强结果在亮度上差距不大,但对于“泳池”图像中绿色方框框出的“电子钟”部分的色彩和细节还原上还有些欠缺;Zero-DCE 和Zero-DCE++增强后图像色彩偏绿,并且存在大量噪声。综合对比,本文算法在对低照度图像进行有效增强的同时,避免了产生噪声和伪影,并且对图像细节和色彩的还原也得到了令人满意的效果。
在实际应用中,LLIE 算法能否对现实世界复杂光照场景进行有效增强也是一大考验,为此本文在包含丰富场景的数据集MIT-Adobe FiveK 上也进行了对比实验来验证算法的泛化能力和鲁棒性。如图6所示,本文从测试图像中选取“雕塑”和“街道”2 幅图像作为示例对比。通过对比可以看出,DALE 增强结果存在色彩失真问题,GLADNet、MBLLEN、Zero-DCE和ZERO-DCE++在色彩与细节纹理的还原上稍有欠缺,MIRNet、UTVNet 与本文算法都到达了令人满意的效果,但本文算法的增强结果与标签图像相比,在阴影处细节、图像清晰度以及色彩还原方面更加接近。结果表明本文算法在有效提高低照度图像亮度的同时,面对不同场景依然具有一定的鲁棒性与泛化能力。

图6 不同方法在MIT-Adobe FiveK 数据集上增强结果的视觉对比
3.2.2 客观评价
为了定量评估实验结果,本文选取峰值信噪比(PSNR)、结构相似性(SSIM)、学习感知图像块相似度(LPIPS)这3 个评价指标。PSNR 是用来衡量增强图像和标签图像相比质量的好坏,PSNR 值越大代表着图像质量越好。SSIM 是用来衡量增强图像与标签图像相似度的指标,取值为0到1之间,值越大表示增强图像与标签图像越相似。LPIPS 也是用于度量增强和真实2 张图像之间的差别,相比PSNR 和SSIM 更为符合人类的感知情况,LPIPS 的值越低表示2 张图像越相似,反之差异越大。表1、表2展示的实验结果为各验证集上3 个指标的平均值,最优结果用粗体表示,次优结果用下划线表示。
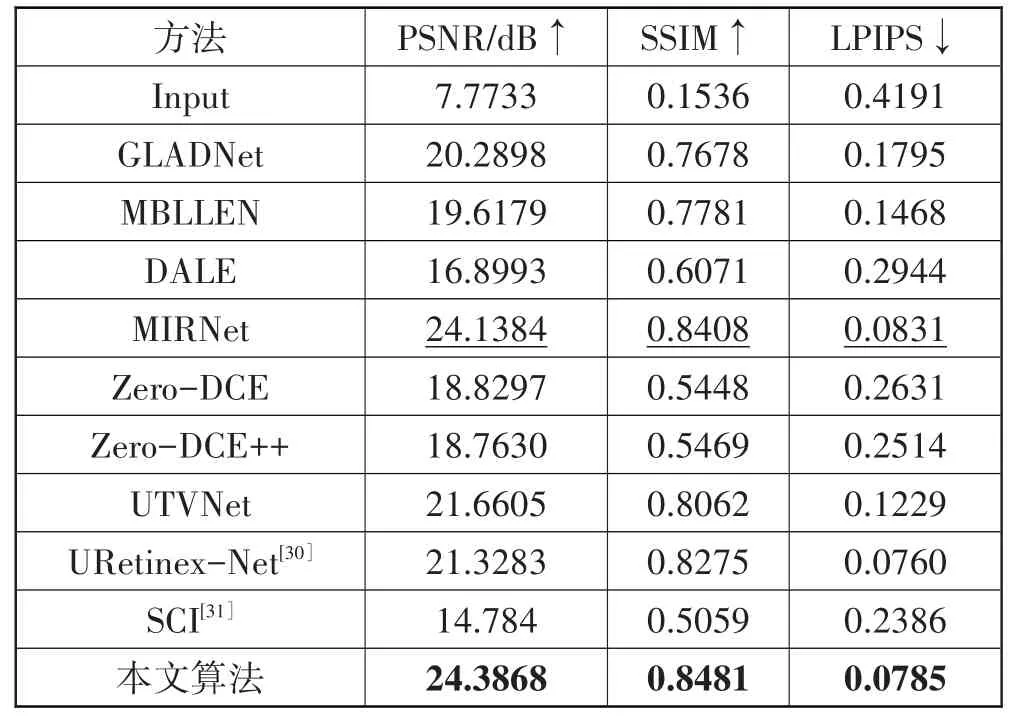
表1 LOL数据集上增强结果的定量评价
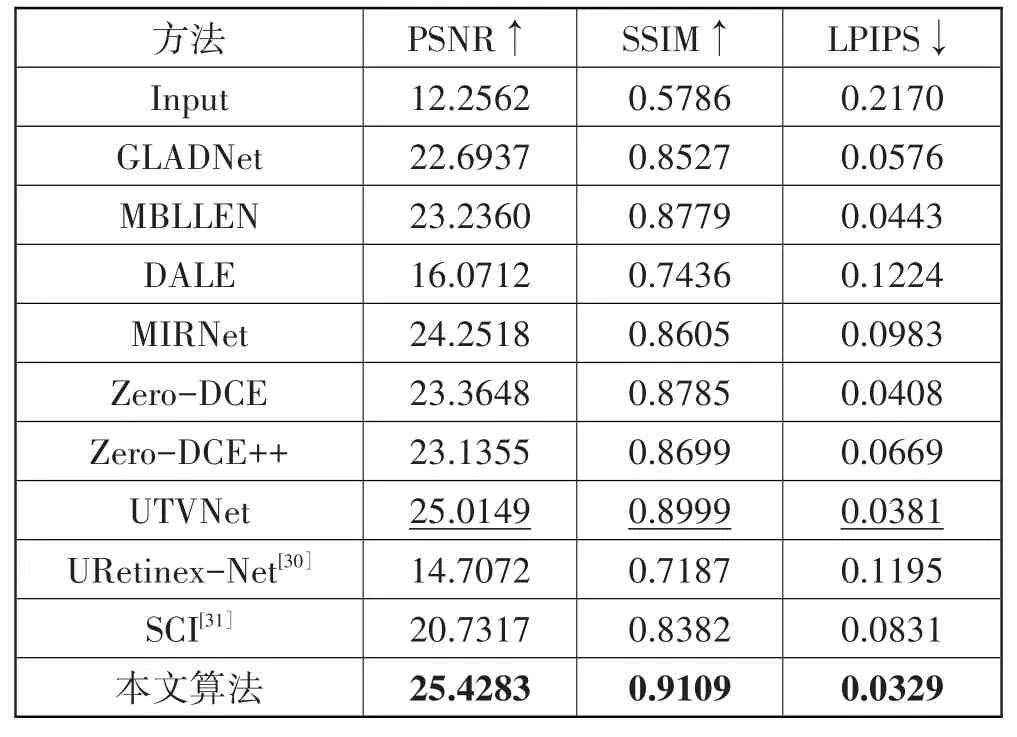
表2 MIT-Adobe FiveK 数据集上增强结果的定量评价
不同算法在LOL 数据集上的客观评价结果如表1 所示,本文算法与所对比的主流算法相比在PSNR、SSIM 以及LPIPS 这3 个评价指标上都达到了最优,相较于次优算法PSNR 提高了0.2484 dB、SSIM 提高了0.0073、LPIPS 降低了0.0046,这表明本文算法在提高低照度图像亮度、抑制噪声以及恢复图像细节与色彩方面相较于对比算法具有明显的优势。
表2 展示了不同算法在场景更丰富的MITAdobe FiveK 数据集上的定量对比结果。本文算法在3 个评价指标上同样达到了最优,相较于次优算法PSNR 提升了0.4134 dB、SSIM 提升了0.011、LPIPS 降低了0.0052。这表明本文算法相较于对比算法,在面对现实世界复杂场景下也能有更好的处理效果,也从客观数据上验证其具有较好的鲁棒性和泛化能力。
3.3 消融实验
为了验证本文所设计的DA-ResBlock 模块和DRN 网络的有效性,本节设计7 种不同的消融实验,并将它们在LOL 数据集上进行测试。分别为M1(未使用注意力);M2(仅使用空间注意力SA);M3(仅使用通道注意力CA);M4(未使用DRN);M5(使用2 层DA-ResBlock);M6(使用4 层DA-ResBlock);M7(未使用膨胀卷积);M8(使用SSIM 损失替换MS-SSIM 损失);M9(本文完整模型)。表3为所有模型对比结果,表4 与图7 分别为使用DAU 前后的复杂度对比以及主观视觉对比。
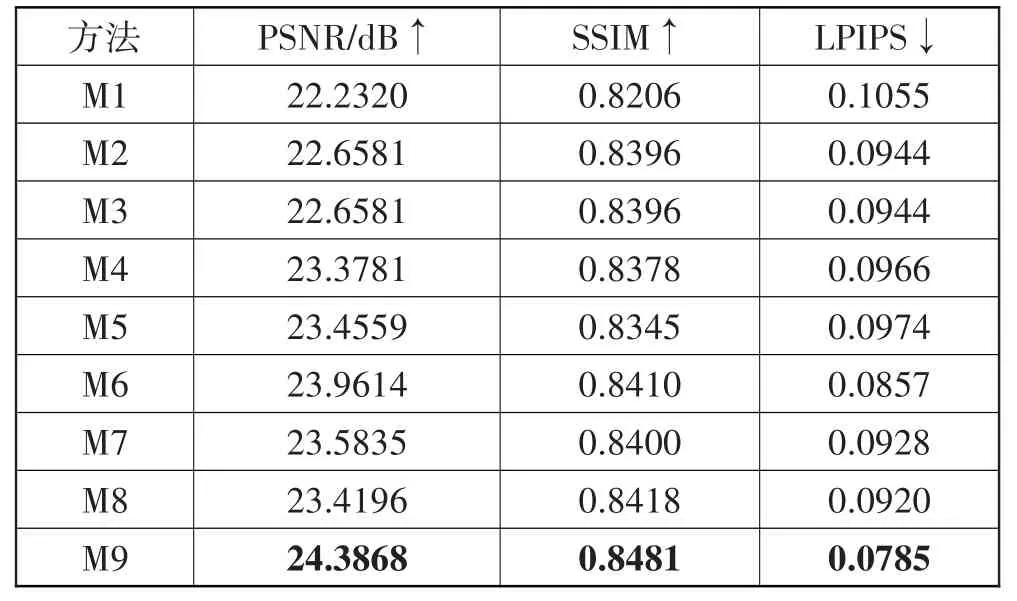
表3 不同模块消融实验对比结果
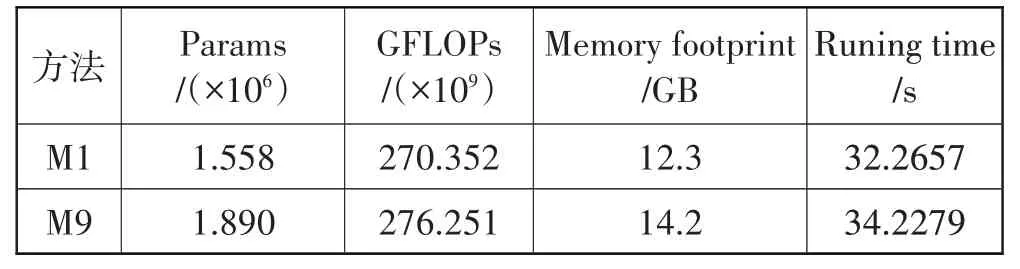
表4 使用DAU前后模型复杂度对比

图7 使用DAU前后增强结果视觉对比
由表3 可知,完整模型的指标优于其他模型。其中由M1~M4 的实验结果可知,未使用注意力的模型指标最低,单独使用空间或通道注意力以及未使用DRN 的模型指标都低于完整模型指标。并且从M5、M6 的实验结果可知,相较于3 层DA-ResBlock,使用2 层指标有所降低,使用4 层指标并未提高,M7 和M8的实验结果表明本文使用MS-SSIM 损失和膨胀卷积可以给模型带来有效提升。
由表4 可知,使用DAU 后模型复杂度略有提高。由图7 可知,DAU 能够有效控制噪声和伪影,显著提高图像质量。
综上所述,本文模型中DAU、DA-ResBlock 和DRN 都能够有效地提高低照度图像亮度并优化图像质量,本文模型结构具有一定合理性。
4 结束语
针对常见的基于深度学习的LLIE 算法对低照度图像增强后导致的噪声增多、色彩失真、细节丢失等问题,本文提出了一个融合残差网络与视觉注意力的LLIE算法,该算法分为增强网络和细节恢复网络2个部分。增强网络部分主要包含DA-ResBlock、DAU 以及卷积神经网络。利用残差网络的“Shortcut”机制在不丢失浅层特征的情况下对低照度图像的深层特征进行提取。DAU 能够引导增强网络更加关注任务相关的特征,抑制了噪声和伪影。使用了不同膨胀因子的膨胀卷积,可以增大网络感受野,获取更丰富的上下文信息。细节恢复部分拼接了原始的输入图像,使用卷积神经网络进一步还原了图像细节。通过大量实验验证,本文算法在能有效对低照度图像进行增强,增强图像的亮度、色彩和细节纹理都达到了很好的视觉效果,并且抑制了噪声和伪影。通过与近几年主流算法在LOL 数据集和MIT-Adobe FiveK 数据集上对比PSNR、SSIM、LPIPS这3个客观评价指标,本文算法都得到了更好的结果,展现了其优秀的性能和潜力。在未来的研究中,将考虑提高模型在光照条件更加复杂的低照度场景下进行增强的泛化能力与鲁棒性。
