一种360°全景视频自适应FEC编码算法研究
2024-04-28周简心高廷金张森林
周简心,高廷金,张森林
(1.福州大学 先进制造学院,福建 福州 350000;2.福州大学 物理与信息工程学院,福建 福州 350000)
0 引言
全景视频以其带来的沉浸式、交互式体验,受到人们的广泛关注,并成为虚拟现实(Virtual Reality,VR)技术和增强现实(Augmented Reality,AR)技术中最热门的业务[1]。在全景视频的传输过程中,根据用户不停的视角转变,向用户端实时传输视频数据。在此过程中,全景视频传递的比特数是传统视频的4~6倍,同时其所产生的头动相应时延(Motion To Photon,MTP)需要控制在20 ms以内,才不会使用户出现眩晕感,这体现出全景视频数据量大、对时延敏感的特点[2-3]。在带宽受限网络情况下,如何在保障用户体验质量(Quality of Experience,QoE)的过程中进行低时延的全景视频传输,已经成为当前全景视频研究的重点。
为解决全景视频传输数据量大的问题,一般采用基于Tile的视口自适应传输方案。OZCINAR引入一种自适应全景视频流框架,通过视觉注意力度来决定不同图块的比特率分配[4]。虽然该方案能够减小全景视频传输的数据量,但是大部分宽带用于传输非视口区域,导致优化视口质量不足。LYU针对时延敏感的特点,提出一种根据图块的帧间和层间解码依赖性的前向纠错(Forward Error Correction,FEC)编码率优化方法,通过提供不等错保护(Unequal Error Protection,UEP)进行可靠的低时延视频传输,但是并没有考虑传输过程中的编码率不同对FEC的影响[5]。
为了解决这些关键问题,文章提出一种360°全景视频自适应FEC编码策略。采用线性回归来估计视口区域,并构建一个概率模型得出视口图块的权重。通过该权重建立一种针对360°全景视频的视频失真度模型,以此提高视频质量的评估准确度。通过时延约束评估不同帧的编码比特率和FEC编码率上限,再根据视口优先级进行优化匹配,最大限度提升全景视频的传输质量。实验结果表明,该策略能够在时延的约束下实现高质量的全景视频传输。
1 系统模型及问题描述
1.1 360°全景视频失真模型
在传统视频失真模型中,端到端失真Dt通常为源失真Ds和通道失真Dc的叠加,即
式中:Ds为视频在编码过程中的失真,主要由视频源码率R和视频序列参数R0决定,Dc为网络传输中的通道失真,取决于有效丢失率Π,而有效丢失率由视频数据包的传输丢失和过期到达引起,D0、α、ω为特定视频编解码器和视频序列的常数。
经过FEC编码后能够容忍的丢包率为
式中:F为FEC冗余包数量,K为源包数。
如果丢包数少于式(2)计算出的数值,证明可以完全恢复丢包,即Π=0,否则Π=η。但是,以上分析都没有考虑全景视频中不同区域的重要性不同。因此,针对全景视频的特点提出一种全景视频失真度模型,以便更准确地测量全景视频的质量。
使用等距形投影,将360°视频从观看周围的球形域展平到2D矩形表面,并将投影后的每一帧分为w×h块,每一块分配编号i,并将视点坐标定义为(X,Y)。令μx∈[0,ω)和μy∈[0,h),表示分别矩形域中视口中心的X、Y坐标期望值,这些值是根据先前的视口位置估计的。对于图块i,其重要性权重γi,j计算为其与视口的预期重叠面积。定义(pi,qi)为图块i的中心坐标,i∈{1,2,…,wh}。Si(X)为以(X,μY)为中心的视口与以(pi,qi)为中心的图块之间的重叠区域,计算公式为
如果(u,v)在以(x,μY)为中心的视区中,F(u,v,X)=1,否则F(u,v,X)=0。其中,(u,v)代表视角实际的坐标值。
通过该概率模型,可以估计全景视频流的不同图块权重,有效减少以往视口估计的不确定性,由此可以得出全景视频失真模型为
式中:γi,j为图块的权重,为视频失真度,ri,j为FEC冗余度,j为帧序列数,最大值为m,i为图块序列数,最大值为n,Q为图块对应的量化参数(Quantizer Parameter,QP)值。
1.2 问题定义
介绍上述模型并推导出全景视频失真度后,可以制定如下优化措施:在给定网络条件下,找到全景视频每个瓦片的最佳QP值和每帧的最佳FEC编码参数,使视频失真最小化。优化问题可以表述为
式中:Γtar为视频帧的目标时延,T为各块的时延,Nr为客户端能够接收到当前视频帧总数据包的个数,K为源包的个数,ω为包的长度,Snmin为关键帧的比特资源下限。约束C1是为了保证视频帧的总时延上限,约束C2表示理论条件下满足客户端可以恢复原始数据帧,约束C3表示关键帧比特数的最小阈值。
2 360°全景视频自适应FEC编码算法
在全景视频传输过程中,端到端时延是一个影响交互能力和视频质量的重要因素,一旦视频帧传输超过时延约束,该视频帧将会被丢弃[7-8]。因此,本算法通过视频传输的时延约束决定链路的比特数上限。数值主要受传播时延、传输时延和排队时延影响,结合约束C1可以推导出总视频帧的比特数Lall为
式中:S为源包比特数,R为FEC包比特数,u为带宽,η为丢包率,tRTT为视频帧的往返时间,L~为队列链路的比特数。
理论上,只要接收端可以收到不少于K个FEC数据包,就可以恢复损失的数据包,也就是FEC包数R需要大于传输中损失的包数,即
因此,结合约束C2可以推出总视频帧的码率和FEC分配码率的上限。
在视频编码中,I帧作为关键帧,一旦出现损失,则会影响后面非关键帧P帧的编解码工作,因此I帧的优先级高于P帧。在分配资源过程中,应对此采取不同的视频帧和冗余率的分配策略。对于P帧,视频帧总比特数Lall应采取时延约束的上限,而FEC的比特数R取数据恢复的下限值,即
根据实际往返时延(Round Trip Time,RTT)判断网络状态,调整每帧的总视频帧比特数,再结合式(8)得出该帧和图块对应的码率和冗余率。
对于关键帧I帧,关键帧的比特数应低于关键帧的比特资源下限。当S≤Snmin时,与非关键帧策略相同就可以保证数据的丢失在FEC恢复能力之内。当S>Snmin时,应提前为FEC预留比特资源,此时关键帧的比特数取S=[Lall×(1-η)+Snmin]/2,然后重新计算FEC的冗余率和QP值。详细算法步骤如下。
得到总帧的码率比特率后,对每块进行相应的码率资源分配。优化问题被规划成多项式复杂程度的非确定性(Non-deterministic Polynomial,NP)完全的背包问题,用快速搜索算法进行求解。进行多次迭代,每次迭代会将一个QP值分配给当前局部最优的图块。具体地,先计算将当前QP值分配到每一个Tile能够带来的视频质量提升值,然后选择本轮迭代中质量提升最多的Tile进行最优QP值分配。不断重复迭代过程,直到将所有码率比特资源分配完成。
3 实验分析
3.1 实验环境及参数配置
本次实验采用C++语言进行系统设计。从公开的360°全景视频数据集中选定Stage、Ocean、Boating和Forest共4个视频,每个视频配置为YUV 420、长度5 000帧、分辨率3 840×2 048像素。在预视频处理阶段,采用高效率视频编码(High Efficiency Video Coding,HEVC)作为视频编码器,并结合Kvazaar对视频进行切8×3图块操作。其中,量化参数合集QP={32,34,38,40,43},编码码流帧率为每秒25帧。设置GOPSize=1,IntraPeriod=25,表示“IPPP”的GOP结构,即一个I帧和24个P帧为一个GOP。实验采用Raptor-FEC系统实现FEC编码,通过Holowan网络仿真仪模拟出真实的网络条件。视频传输时延约束为150 ms,网络丢包率为10%。
3.2 实验结果与分析
将AR-FEC算法与传统的视频传输方案PENA和DASH进行比较。PENA是一种码率由时延约束执行在GOP级别的JSCC变速率控制算法,而DASH是传输360°全景视频的普遍方法,主要基于在传输层的传输控制协议(Transmission Control Protocol,TCP)协议,并且具有感知视场角(Field of View,FOV)的能力。
所提算法与对比算法在不同视频序列上所取得的有效丢失率如图1所示。有效丢失率用于评估数据经过网络传输后的完整性。可以看出本算法的有效丢失率低于6%,是3个算法中丢失视频数据最少的。PENA算法由于失真模型在GOP级别执行,导致其对网络状态变化不敏感,平均丢失率为8%。而DASH算法虽然可以进行FOV感知,但是由于采用TCP重传机制,导致大量视频数据因为超过传输时间而被丢弃,最终丢失率最高,为34%。

图1 总体视频有效丢失率对比图
各算法的峰值信噪比(Peak Signal to Noise Ratio,PSNR)性能对比,如图2所示。PSNR值越大,证明视频质量越好。从图2可以看出,AR-FEC算法的PSNR数值优于其他算法。这是因为本算法将码率资源分配给影响全景视频最重要的FOV视区,同时利用FEC对丢失的视频数据进行恢复,使得视频质量得到最大限度的保障。
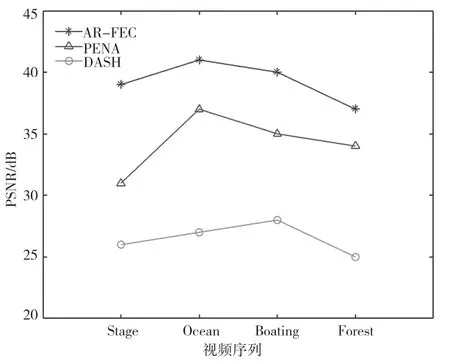
图2 总体视频PSNR对比图
4 结语
为了满足360°全景视频低时延、高质量传输的要求,首先利用全景视频的特点建立360°全景视频失真度模型。然后,设计一种360°全景视频自适应FEC编码算法。该算法是在时延约束下分配比特资源,实现对图块码率的优化分配,并且对关键帧和非关键帧提供FEC保护。实验证明,该算法不仅能够提高系统传输效率,而且在视频质量方面优于传统视频传输算法。
