Associative Tasks Computing Offloading Scheme in Internet of Medical Things with Deep Reinforcement Learning
2024-04-28JiangFanQinJunweiLiuLeiTianHui
Jiang Fan ,Qin Junwei,* ,Liu Lei ,Tian Hui
1 School of Communications and Information Engineering,Xi’an University of Posts and Telecommunications,Xi’an 710121,China
2 State Key Laboratory of Networking and Switching Technology,Beijing University of Posts and Telecommunications,Beijing 100876,China
Abstract: The Internet of Medical Things(IoMT)is regarded as a critical technology for intelligent healthcare in the foreseeable 6G era.Nevertheless,due to the limited computing power capability of edge devices and task-related coupling relationships,IoMT faces unprecedented challenges.Considering the associative connections among tasks,this paper proposes a computing offloading policy for multiple-user devices(UDs)considering device-to-device(D2D)communication and a multi-access edge computing(MEC)technique under the scenario of IoMT.Specifcially,to minimize the total delay and energy consumption concerning the requirement of IoMT,we frist analyze and model the detailed local execution,MEC execution,D2D execution,and associated tasks offloading exchange model.Consequently,the associated tasks’offloading scheme of multi-UDs is formulated as a mixed-integer nonconvex optimization problem.Considering the advantages of deep reinforcement learning (DRL) in processing tasks related to coupling relationships,a Double DQN based associative tasks computing offloading(DDATO)algorithm is then proposed to obtain the optimal solution,which can make the best offloading decision under the condition that tasks of UDs are associative.Furthermore,to reduce the complexity of the DDATO algorithm,the cacheaided procedure is intentionally introduced before the data training process.This avoids redundant offloading and computing procedures concerning tasks that previously have already been cached by other UDs.In addition,we use a dynamic ε-greedy strategy in the action selection section of the algorithm,thus preventing the algorithm from falling into a locally optimal solution.Simulation results demonstrate that compared with other existing methods for associative task models concerning different structures in the IoMT network,the proposed algorithm can lower the total cost more effectively and effciiently while also providing a tradeoff between delay and energy consumption tolerance.
Keywords: associative tasks;cache-aided procedure;double deep Q-network;Internet of Medical Things(IoMT);multi-access edge computing(MEC)
I.INTRODUCTION
Internet of Things(IoT)is widely deployed in numerous application feilds thanks to the advancement of wireless communication technology,with the Internet of Medical Things(IoMT)being one of the most important applications[1].IoMT is referred to as a subset of IoT that encloses and interconnects medical information technology applications and also healthcare devices such as wearable devices,diagnostic tools,and hospital equipment [2].Nowadays,IoMT has been widely deployed in feilds such as health treatment,health monitoring,and medical education,which provides secure healthcare service by simplifying access to real-time patient data and enabling remote and selfmonitoring of patients [3,4].Furthermore,the combination of artifciial intelligence,machine learning schemes,and sensor techniques with IoMT enables doctors to deliver quality diagnostic service outside of the hospital is very convenient for the patient.Especially important for those patients who are isolated due to their geographical location[5].
In a typical IoMT scenario,network latency and device energy consumption are usually regarded as the key performance indicators to fast and effciiently transmit the data from the patient to the healthcare center.Although the wide application of IoT devices such as medical sensors,smartwatches,and smart bracelets have been embraced by many customers recently,IoMT development is still hampered by the fact that many of these user devices (UDs) usually have poor computational capabilities and short battery lives.
Fortunately,the introduction of multi-access edge computing (MEC) can effectively address the aforementioned challenges by offloading diffciult-toprocess tasks generated by UDs to access points(APs)for task processing [6],hence reducing the delay and energy consumption of UDs and considerably simplifying the development and maturation of IoMT.Simultaneously,device-to-device(D2D) is also a technology that can reduce task processing latency and energy consumption by offloading complex tasks to user equipments(UEs)for execution.However,concerning the distributed nature of the IoMT infrastructure,challenges concerning the combination of MEC,D2D and IoMT has become the hotspot research aspect[7].
Nevertheless,it is rather problematic that tasks of UD sometimes display coupling characteristics under some scenarios of IoMT,where the output of one device may be the input of another device as demonstrated in [8].For instance,assume a data collection equipment,a monitoring terminal,a doctor’s workstation,and diagnostic equipment make up the system as a whole in a remote monitoring system of smart healthcare.Under this system,the data collection equipment will gather patient-related data and send it to the diagnostic equipment for data analysis.Consequently,the diagnostic equipment will transmit the results to the monitoring terminal and the doctor’s workstation.Finally,the workstation will decide whether to automatically sound an alarm in response to the analysis results to achieve the effect of remote monitoring.As can be seen from the above example,the tasks’associative relationship demands that the execution of tasks must follow a specifci sequence,which imposes extra prerequisites to ensure the performance of the task offloading scheme.Therefore,due to the additional prerequisites introduced by task coupling,the research on task offloading schemes faces unexplored challenges under multi-user associated task scenarios.
In this paper,we propose a cache-aided Double DQN based multi-user associative tasks offloading algorithm considering D2D communication.First,we introduce D2D offloading method on top of edge offloading to further reduce latency and energy consumption.At the same time,we adopt a cache-aided strategy,which is able to reduce the repeated computation of already cached tasks.With the optimization objective of minimizing the weighted sum of overall latency and energy consumption,we establish the problem as a mixed-integer nonconvex optimization problem.Finally,we use the Double DQN algorithm to obtain the optimal task offloading strategy.The main contributions are as follows:
• This paper considers the associativity task concerning IoMT implementation,an important topic that has received limited attention in many previous works.Unlike previous work where only a single task model was studied,we experiment with multiple structures of associative tasks.This makes our research results more appropriate and applicable.
• We formulate a mixed integer optimization model to optimize multiple UDs’ offloading strategies to minimize the weighted sum of delay and energy consumption under the multi-APs conditions.The multi-UDs and multi-APs prototype makes our research more in line with realistic IoMT application scenarios.
• The cache-aided procedure is proposed,which is an innovative method that combines content caching and task offloading technology.We frist let the agent identify the amount of tasks that have been already cached before the offloading session.Then,UDs only need to process and offload the content that has not been already cached,which avoids duplicate processing of tasks and further improving the work effciiency.
• Compared to other algorithms,our algorithm has the best performance and stability in optimizing the offloading of related tasks,this is because not only the current network but also the target network is utilized to predict the Q value.Thus,the obtained Q value will be more accurate.And we also use a dynamicε-greedystrategy,thus preventing the algorithm from falling into a local optimum.
The rest of this paper is organized as follows.The related work is introduced in Section II.Section III outlines the system model and problem formulation.The proposed Double DQN based associative tasks offloading algorithm is illustrated in Section IV.Simulation results are demonstrated in Section V.Finally,conclusions are presented in Section VI.
II.RELATED WORK
At present,MEC has been widely involved in many wireless connection-related feilds,such as unmanned aerial vehicles (UAV),Internet of Vehicles (IoV) and fog radio access networks (F-RAN) [9].A threetier system model computation task offloading scheme based MEC is developed in [10],which overcomes the shortcomings of the sink node with limited energy resource and computing capability.Aiming at meeting the quality of service (QoS) requirements of low latency and low energy consumption in healthcare monitoring,an improved particle swarm optimizationbased computation offloading approach is proposed in [11],which combines combinatorial auctions.In Ref.[12],Rahul Yadav et al.proposed computation offloading using a reinforcement learning (CORL)scheme to minimize latency and energy consumption.From the above contributions,it can be deduced that researches on MEC is entering a more mature stage gradually.D2D is a proximity communication technology that allows UDs to offload tasks to surrounding UEs for processing,where UDs have more offloading options.Ref.[13] and [14] show the application of D2D combined with MEC technology in IoV and F-RAN,respectively.Simulation results demonstrate that their work can further reduce system latency compared to the case without D2D.However,MEC and D2D techniques are still immature when it comes to their potential implementation in IoMT.In this paper,we consider the advantages of combining MEC and D2D technology and apply it to the correlated task scenario of IoMT.
In related literature,many researchers have focused on dealing with the above associated tasks through the design of offloading algorithms.For instance,Ref.[15] proposes a deep reinforcement learning (DRL)framework based on the actor-critic learning structure to address the offloading and resource allocation of tasks.A graph task offloading mechanism by integrating DQN with a breadth-frist search technique is proposed in [16] to minimize the weighted sum of timeenergy consumption.But those aforementioned works only consider the association of single-user’s subtasks.Moreover,multi-user devices’task associations are actually more complicated and applicable to the experimental IoMT system.[17] studies a multi-layer task offloading framework for dependency-aware multiple tasks,which aims at minimizing the total energy consumption of mobile devices.Ref.[18] proposes a dependency-aware offloading scheme with edge-cloud cooperation under multi-task dependency constraints to improve performance in terms of application fniishing time.Simulation results demonstrate that the proposed method outperforms the comparison algorithm by about 23% to 43.6%.In order to minimize the average completion time of multiple applications,an effciient task scheduling algorithm whose basic idea is to encompass multiple applications and prioritize multiple tasks for dependency-aware tasks is proposed in [19].However,the above studies only optimizes a single metric between the model latency and energy consumption.A novel multi-user computation offloading framework for long-term sequential tasks is proposed and the multi-user sequential task offloading problem is defnied in[20].To minimize the weighted sum of the computation time of the task and the energy drained from the respective vehicle,[21]studies the problem of dependency-aware task offloading and service caching.Ref.[22] constructs sequential execution windows by incorporating the hybrid dependencies among subtasks to reduce the processing latency and energy consumption.However,these results consider only one associative task model and do not demonstrate the applicability to other structural tasks.In summary,some of the above studies consider the case of subtask correlation,some focus solely on optimizing either latency or energy consumption,and some only consider one associative task model.In contrast,our research takes a comprehensive approach that concurrently optimizes both latency and energy consumption in scenarios,where multiple UDs’tasks are associated with each other rather than subtasks.Additionally,we also simulate diverse task topologies,enhancing the practicality of our research and ensuring the accuracy of our experimental results.
Furthermore,we analyzed the algorithms for solving the task offloading problem in the related works.With a massive influx of multimodality data and the proliferation of sophisticated smart devices,the role of data analytics in health informatics has developed rapidly in the last decade.This has also prompted increasing interest in the generation of analytical,data driven models based on deep learning in health informatics [23].[24] proposes a model-free approach based on the Q-learning approach to optimize the offloading decision and energy consumption jointly for associative tasks.However,Q-learning is only applicable when the action space is small [25],and when there are more tasks,the action space and state space will be larger,which will cause the performance of the DQN algorithm to deteriorate.Therefore,concerning the offloading policy designed for related tasks in the IoMT scenario,the proposed algorithm needs to not only solve the complicated task coupling relationships,but also have stronger robustness and stability.
III.SYSTEM MODEL AND PROBLEM FORMULATION
3.1 System and Task Model
As shown in Figure 1,we consider a multi-UDs,multi-UEs and multi-APs scenario in IoMT dealing with associative tasks.The system consists of one base station(BS),KAPs,MUDs andIUEs.The BS is only responsible for cell communication and control.KAPs are denoted byK={1,2,···,k,···,K},which can communicate and exchange data within communication range and each AP is equipped with an edge server with more powerful computing and storage capabilities compared with UDs.The UD set is indicated byM={1,2,···,m,···,M}.We further assume that each UD has a computationally intensive task to complete,denoted byLm=(Bm,Dm),whereBmis the size of computation task,Dmrepresents the number of CPU cycles required to complete taskLm.IUEs are denoted byI={1,2,···,i,···,I}.The computational power of UEs is assumed to be higher than UDs and lower than APs,and they can both receive and execute tasks that offloaded from UDs.
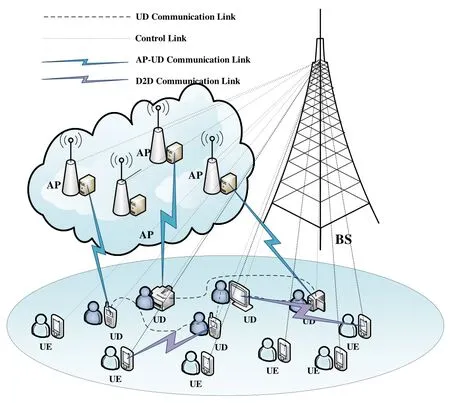
Figure 1.System model.
The tasks studied in this paper are supposed to be associated,the output of one UD may be all or part of the input of other UDs.As shown in Figure 2,let rectangles represent UDs,and circles stand for tasks.Furthermore,let connecting lines represent inter-task data exchange links,and the size of the associated data is denoted byBn,m.Assume each UD only has a limited amount of processing capacity,which is insuffciient to process all tasks under the low latency and low energy requirements.Hence there are three execution strategies available:local execution,MEC execution and D2D execution,respectively.For further explanation,local execution means that UDs do not offload tasks,MEC execution is that UDs offload tasks to AP for execution and D2D execution stands for UDs select UEs offload and perform tasks.Suppose taskLm’s execution decision is denoted byαm,αm ∈{0,1,2,···,k,···,K,K+1,···,k+i,···,K+I},whereαm=0 represents local execution,αm=krepresents offloading the task to APkfor execution andαm=K+irepresents offloading the task to UEifor execution.

Figure 2.Examples of associated tasks.
With the above system model,this paper aims to obtain the optimal offloading strategy for all UDs under associative tasks assumption.First,we need to analyze the mathematical modeling of the delay and energy consumption for the above three execution methods of the task.Then,owing to the complicated nature of the correlation relationship among tasks built in our model,we need to describe the data exchange procedure for associated tasks.Hence,in the following section,we will describe the following fvie parts,which are local execution,MEC execution,D2D execution,associated tasks data exchange and problem formulation.
3.2 Local Execution Model
When UDmdecides to execute taskLmlocally,there is no related transmission or propagation delay,hence the latency mainly consists of processing latency and queuing latency.We defnieas the computational capacity of UDm,then the local processing delay concerning taskLmis given as:
the energy consumption of UDmduring the local execution can be expressed as:
whereκrepresents the effective switching capacitance,whose value depends on the CPU chip architecture.
Due to the associative nature of tasks,taskLmexecution must wait for the completion of its forwardrelated task and then transfer the execution results to UDm.For this reason,we consider the forwardrelated task execution delay and the associated data transmission delay as two main components of the queuing delay.The queuing delay of taskLmis represented byTready,m,the detailed variable defniition will be elaborated in Section 3.5.Finally,taskLmlocal execution completion delay represented bycan be calculated as:
3.3 MEC Execution Model
In MEC execution model,APs are the offloading target for UD’s tasks.We assume that UDminitially offloads its taskLmto APkfor execution,where UDmfrist sends the dataBmto APkvia the uplink.Then APksends the execution results back to UDmvia the downlink after processing.The uplink transmission rate between UDmand APkcan be formulated as:
whereWrepresents the channel bandwidth,Pmis the transmission power of UDm,denotes the channel gain between UDmand APk.In the uplink transmission process,the data transmitted by UDmincludes its own data and also the forward-associated task input data,hence,the uplink transmission delay can be calculated as:
whereBmrepresents the taskLmown data,p(m)deno∑tes the set of forward-associated tasks ofLm,anddenotes the sum of the forward task input data.The corresponding uplink transmission energy consumption of UDmis expressed as:
After receiving the data transmitted by UDm,APkstarts processing the task.We setas the computational power of APk,the processing delay can be calculated as:
since our ultimate goal is to minimize the delay and energy consumption of all UDs,the energy consumption of APs is not discussed in this paper.
Generally,since the data size of the returned execution result is much smaller compared with the input data and considering the high data transmission rate of the cellular link,the transmission delay is neglected in the downlink.Finally,the AP task completion delay of taskLmcan be formulated as:
3.4 D2D Execution Model
D2D execution model stands for UDs offload tasks to UEs for processing.When UDmchooses UEito offload its taskLm,UDmfrist sends the dataBmto UEivia the D2D link.Then UEisends the execution results back to UDmafter processing.The D2D link transmission rate between UDmand UEican be expressed as:
the corresponding D2D link transmission energy consumption of UDmcan be given as:
After receiving the data transmitted by UDm,UEistarts processing the task.We setas the computational power of UEi,the processing delay can be calculated as:
Similarly,the transmission delay is also neglected in the D2D backhaul link considering the small amount of data returned from UE.The UE task completion delay of taskLmis expressed as:
3.5 Associated Tasks Data Exchange Model
We assume that taskLnis a forward-related task ofLm.After the execution of taskLn,it needs to send its result back to UDmas the input.Since there are still three possible execution modes,the following analysis will be provided separately.
When taskLnis executed locally by UDn,it need to send results data to UDmafter processing.LetPnbe the transmitting power of UDn,its transmission rate can be given as:
whereWrepresents the channel bandwidth,andN0denote the channel gain between UDnand UDmand the noise power separately.Then the transmission delay is:
whereBn,mis the size of the associated data between taskLnand taskLm.The energy consumed by UDnduring the transmission can be expressed as:
When UDnchooses MEC or D2D execution model,taskLnis offloaded to APkor UEifor execution respectively,the corresponding results need to be sent back from APkor UEito UDm.Then UDmdecides to executeLmlocally or remotely through offloading.It is worth noting that the execution of taskLmmust wait for all tasks inp(m)to execute priorly and then transfer their results to UDm.We defnie the queuing time at which taskLmreceives data from all its forward-associated tasks asTready,m,i.e.the time at which taskLmis ready for the next stage processing.For different tasks inp(m),the data exchange process to UDmcan be carried out simultaneously,so the queuing delay of taskLmcan be formulated as:
3.6 Problem Formulation
In summary,the total latency is equivalent to the sum of the completion latency ofMtasks,which is formulated as:
The total energy is the sum of all energy consumption ofMUDs,including local processing,data exchange,data offloaded to AP and UE:
Our ultimate goal is to minimize the weighted sum of total latency and total energy consumption,which is defnied as:
wherewis the weight factor andw ∈(0,1).Finally,the study of multi-device associative task offloading strategies in this paper can be formulated as:
Eq.(21a)indicates that all tasks should be executed eventually,whether through local execution,MEC execution,or D2D execution mode.Eq.(21b) ensures that tasks generated by data collection equipment must be executed locally so that patient information can be obtained immediately.Eq.(21c),(21d) and (21e) describe the total computation resources limitation of UD,UE and AP,respectively.Obviously,the proposed objective function is non-convex and an NP-hard problem,which it is challenging to obtain the optimal solution directly by mathematical methods.
Particularly,many scholars propose applying multistage methods to divide the NP-hard problems into multiple subproblems and then solve them step by step,ultimately obtaining suboptimal solutions [26].For instance,[27] propose a lightweight yet effciient offloading scheme and a distributed consensus algorithm to investigate the problem of fnie-grained task offloading in edge computing for low-power IoT systems.A sub-optimal solution based on the alternating optimization technique is proposed in [28].Specif-i cally,the offloading decision is solved through a customized matching game algorithm,and then the intelligent reflective surfaces (IRS) phase shifts and resource allocation are optimized through in alternating fashion using the Difference of Convex approach.However,those mentioned solutions can only fnid suboptimal instead of the optimal solution.Furthermore,the NP-hard problem is proved to have a better solution until the emergence of AI[29].Among currently researched learning-based algorithms,Double DQN is a typical deep reinforcement learning algorithm algorithm with strong stability,which results in good performance for correlated tasks with different coupling relationships.Hence,in order to solve this NP-hard problem,we propose a Double DQN based associative task offloading algorithm to fnid the optimal offloading solution.
IV.DOUBLE DQN BASED ASSOCIATIVE TASKS OFFLOADING ALGORITHM
In this section,we propose a Double DQN based associative tasks offloading (DDATO) algorithm which includes a cache-aided procedure to solve the above problem.In the following subsection,we frist defnie the essential elements of DRL,then introduce the cache-aided strategy.Finally,Double DQN and our proposed algorithm are described in detail.
4.1 Deep Reinforcement Learning Settings
For each UD,the offloading decisionαm ∈A,andαm=0 stands for local execution,αm=krepresents offloading the task to APk,αm=k+istands for offloading the task to UEifor processing.
State: The correlation of the tasks leads to a specifci order of execution,hence the offloading decision of each UD will have an impact inverse on the state. We set the state space asS=(α1,α2,···,αm,···,αM,n),whereα1,α2,···,αm,···,αMdenote the offloading decision of each UD,αmof UDmfor which no offloading decision has been made is represented by NAN,and the last itemnrecords the number of devices that have completed offloading.
Reward: After UD executes the action,it will get the corresponding rewardRt(st,at).Since our algorithm always takes the reward as the evaluation index of the action,where higher rewards are associated with a larger action Q-value.But the optimization problem is to minimizeCtotal,so we defnie the reward to be negatively related to theCtotal.In summary,we defnie the reward of each step as the difference between local execution cost and actual cost,i.e.,Rt=Clocal-Ct,whereClocalis the cost consumed when tasks are executed locally andCtrepresents the cost in the actual offloading case.
4.2 Cache-Aided Procedure
From the above DRL settings,we can see that the action and state spaces are huge,which results in an extended training time and higher algorithm complexity.Considering that in real applications,MEC include content caching and task offloading,which are inextricably reacted with each other.So in this part,we propose a cache-aided task offloading procedure.
In the content caching procedure,APs and UEs are assumed to have more computing power than UDs,and UD can cache part of tasks to APs and UEs in advance according to the content popularity distribution [30].Here,we defnie a cache matrixHto store the already cached tasks.Specifcially,it is utilized to record the size of cached data of all offloaded objects(APs and UEs)for all UDs,andHis:
wherehu,vrepresents the caching factor,which is the ratio of the amount of task data has been cached,and it is sethu,v ∈[0,1].More specifcially,hu,v=0 stands for no cached data for the taskLuon the devicev.Andhu,v ≠0 represents that part of the taskLuhas been already cached to a specifci AP or UE,when the value ofvis not bigger thanK,it means that the taskLuhas been cached to APv,otherwise,it indicates that the taskLuhas been cached to UEv-K,and the size of already cached task ishu,v×Lu.When executing tasks,BS will identify the already cached data in advance according toH,and then select the action to execute only the uncached task data,which signifciantly reduces the repetitive task offloading and also improves computational effciiency.Algorithm 1 shows the specifci cache-aided procedure:

4.3 Introduction of DDQN
After the setting of DRL and cache-aided Procedure,we can use the corresponding algorithm to obtain the optimal offloading strategy.In Ref.[31],a DQN based frame aggregation and task offloading approach is employed,but it only uses the same target network for both the action selection and Q-value prediction sessions,which leads to excessive Q-value valuation.To solve above issue,the Double DQN algorithm uses the current network and the target network concurrently,thus improving the stability of the algorithm.The target Q-value of Double DQN algorithm is defnied as:
whereγis the decay coeffciient,θtandθ′are the parameter of the current network and the target network,respectively.The loss function is given by:
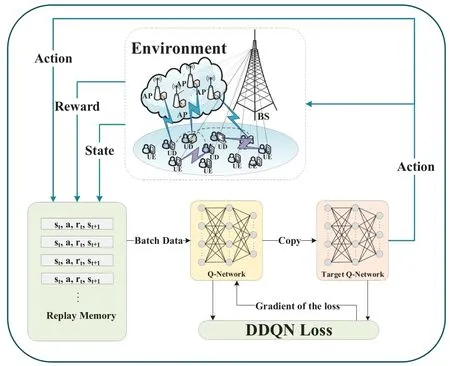
Figure 3.Flowchart of double DQN.
4.4 The Proposed DDATO Algorithm

Algorithm 2 depicts the detailed procedure of the proposed DDATO algorithm.Firstly,the experience replay pool,current network,and target network parameters are initialized.In each roundt,the agent selects and executes actionataccording to the dynamicε-greedypolicy.Then,the agent gets the rewardrtgiven by the environment and the environment goes to the next statest+1.Meanwhile,parameters of current step(st,a,rt,st+1)are stored in the experience replay pool.When the experience replay pool has enough data,the agent randomly takes out small batches of data from it for training to update the Q-value.Then,the current network parameters are updated using gradient descent according to the loss function.Finally,the current network parameters are assigned to the target network andεis updated everyξsteps,the update strategy is:
whereεrepresents a random probability generated for current step andεmindenotes the minimum probability threshold.In the early stage of training,due to the limited number of training,the Q value is not accurate,and the value ofεis large in the early stage of training under this strategy,thus preventing the training procedure from falling into the locally optimal solution.After the whole training process has been completed,the algorithm arrives at the convergence and the best offloading strategy for each UD can be obtained.
V.SIMULATION RESULTS
In this section,we evaluate the performance of the proposed algorithm and further analyze the experimental results.First,the considered associative tasks include three hybrid types: which are represented by mesh,tree,and general tasks,respectively [15].Here we adopt the above mentioned three task models for the experiment evaluation.As shown in Figure 4,each circle represents a task numbered fromL1toL10.In particular,L1andL2represent data collection nodes whose tasks must be executed locally.Each edge of Figure 4 indicates an associated data exchange between connected tasks.Considering the practical application scenario of IoMT,where delay and energy consumption are usually regarded as important indicators [32],so we adopt a compromise solution for the weight coeffciient.Finally,the weight factor of each UD is set to 0.5.Other simulation factors are listed in Table 1 The simulation is carried out in Python 3.8 platform.

Table 1.Simulation parameters.

Figure 4.The considered task models in the simulation.
To demonstrate the performance of the proposed algorithm,we compared it with four algorithms,namely,the random offloading strategy(Random),the DDQN algorithm without considering relevance of tasks(NR DDQN),the DDQN algorithm without considering cache-aided (NC DDQN) and the DDQN algorithm without considering D2D technology(ND DDQN).
Figure 5 demonstrates the convergence performance of the proposed algorithm for the tree,mesh and general task models in the simulation.It is evident that as the number of training rounds increases,the rewards acquired by the agent steadily rise and reach the peak around after 1500 episodes for the three task models.This phenomenon proves the convergence performance of the proposed method.Furthermore,it should be noticed that the difference between the reward values of the three convergence curves is not large.This is because we set the same size of tasks and computational power for these task models.The fnial convergence results prove that our algorithm is applicable to tasks with different structures.
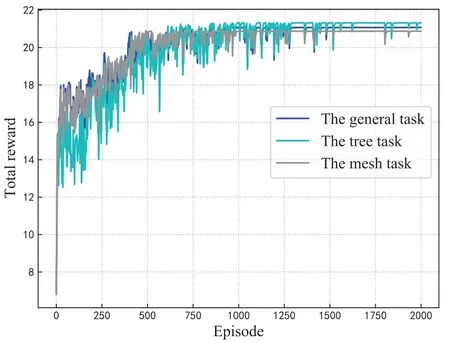
Figure 5.Convergence of the proposed DDATO algorithm for the tree,mesh and general task models.
Figure 6 displays the total cost of the proposed algorithm compared with the other four comparison algorithms.The results demonstrate that our proposed algorithm has the best performance for all task models.Moreover,the performance of NR DDQN is worse than the other DRL algorithms because it ignores the relevance of tasks before training,which further confrims the importance of considering task relevance in our experiment.In comparison,the total cost of ND DDQN is slightly smaller than that of NC DDQN,which indicates that cache-aided procedure is better than D2D technique in terms of performance improvement for associative task processing.Finally,the Random method has the worst performance in terms of total cost than the DRL based algorithms,because it adopts a random offloading policy.
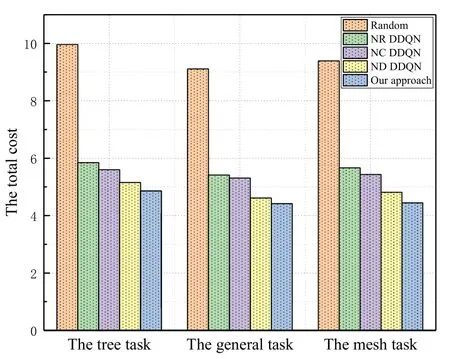
Figure 6.Comparison between different algorithms for the tree,mesh and general task models.
The effect of variations in the computing power of APs on the total cost for the general task model is illustrated in Figure 7.The results show that as the capacity of AP increases,the total cost displays a decreasing trend for all the algorithms,this is because the increase in computing power leads to a reduction in processing latency.Meanwhile,it is observed that our algorithm has the optimal performance under different computing power of APs.This phenomenon is explained as not only do we utilize cache-aided procedure and D2D technique,but also our algorithm ftis well with the relevant task model.Furthermore,the total cost curves of the four reinforcement learning algorithms gradually flatten out,which indicates that the effect of AP’s computing power on the overall performance improvement becomes weaker as AP’s computing power increases gradually.The reason behind this phenomenon is that the growth of AP’s computing power only reduces the processing delay and does not play a role in other factors affects the total cost,such as transmission delay and energy consumption of UD.Moreover,when the computing power of APs change from 1 to 2Gigacycles/s,only the total cost of ND DDQN decreases in the DRL algorithm,which is because it does not use D2D technique.In this stage,the computing power of AP is even smaller than UEs,so UDs choose local or D2D execution,and the change in AP’s computing power has no effect on the total cost.
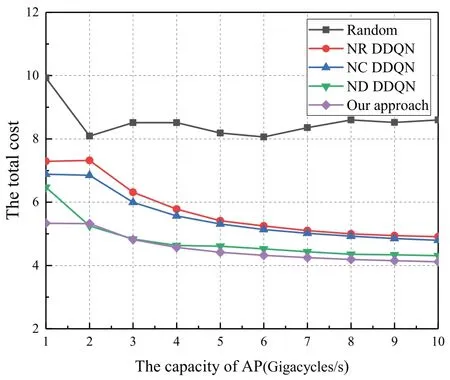
Figure 7.The computing power of APs versus the sum cost of system for the general task model.
Figure 8 presents the effect of variation in workloads of UDs on the total cost for the general task model.The results show that the total cost displays an increasing trend.This is because the growth in workloads consequently leads to an increase in computational cost.More importantly,as the workloads of UDs increase,the advantage of our algorithm become apparent compared with others.This phenomenon indicates that our algorithm behaves better when the task size grows larger.In addition,it can be seen from Figure 8,the algorithm performance of ND DDQN is the closest to that of our proposed algorithm,but the gap gradually becomes obvious as the workloads of UDs continues to increase.This phenomenon is attributed to the fact that the size of caching tasks in ND DDQN does not vary with the workloads of UDs,which leads to a diminishing effect of the cache-aided strategy.And at the same time,our proposed algorithm can strike a balance for the mentioned problem effciiently combining the D2D technique.
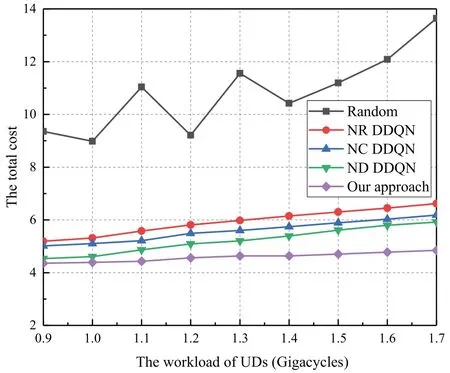
Figure 8.The workloads of UDs versus the sum cost of system for the general task model.
In Figure 9,we explore the convergence performance of our algorithm with different weights for the tree and general task models.Firstly,the convergence curves eventually reach smoothness in all these cases after 1500 episodes.The results indicate that our algorithm is convergent and applicable for associative tasks combined with different requirements of delay and energy consumption.In addition,whenw=0.8,the highest reward is obtained by the agent,and the algorithm has the fewest rewards under the condition ofw=0.2.This phenomenon indicates that our proposed algorithm has better performance for processing delay-sensitive associativity tasks.
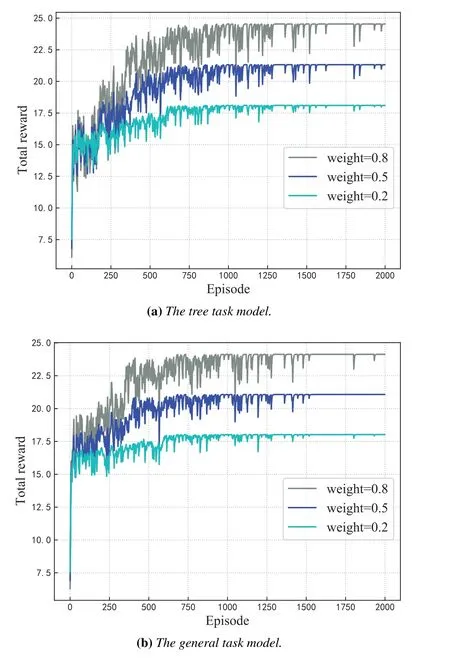
Figure 9.Convergence of the proposed DDATO algorithm for our considered task models when the weight factor equals 0.8,0.5 and 0.2 respectively.
Furthermore,we compare the total cost between different algorithms under different weightswfor the tree and general task models as depicted in Figure 10.Firstly,no matter whetherw=0.8 orw=0.2,comparing the total cost between the tree and the general task models,we can obtain the same insights as can be observed in Figure 6.This phenomenon indicates that our proposed algorithm can maintain feasible and stable performance as the weight parameters change.Then,we can notice that the total cost is always higher whenw=0.8 than that of the cost whenw=0.2 for different task models.This is explained as in the considered model,the impact of delay on the overall system performance is higher than that of the energy consumption of UDs.Finally,since our proposed algorithm provides UDs with a wider array of offloading choices,thereby mitigating the delays and energy consumption associated with redundant calculations.Consequently,our algorithm demonstrates the lowest total cost among all scenarios,reaffriming its optimal performance in addressing the offloading challenges related to coupled tasks.
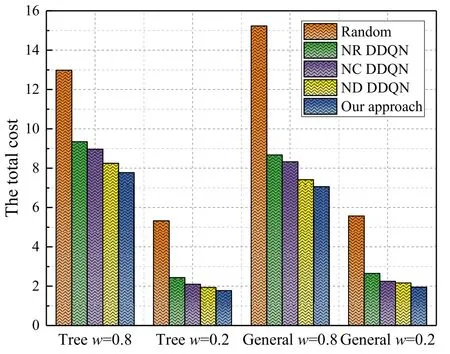
Figure 10.Comparison between different algorithms under different weights w for the tree and general task models.
VI.CONCLUSION
The Internet of Medical Things (IoMT) is referred to as an amalgamation of medical devices and also their applications that can connect to intelligent healthcare systems using advanced networking technologies,which can be regarded as an extension of the IoT technology.In this paper,a computing offloading policy in IoMT considering task relevance has been studied,and a multi-user Double DQN based associative task offloading algorithm is proposed.Then,considering D2D communication and MEC architecture,we formulate the offloading scheme as a mixed-integer non-convex optimization problem.Before the training of model,we adopt a cache-aided strategy to reduce the data dimensions of tasks,which reduce workload without impacting fnial results.Moreover,a better computing offloading scheme for IoMT can be obtained by integrating task coupling into Double DQN,and the proposed algorithm can instruct agents to reduce the delay and energy consumption of UDs significantly,which facilitates the development of the IoMT.Finally,our experiments incorporated three prevalent task models,and the simulation results unequivocally demonstrate that our algorithm outperforms existing solutions in terms of cost when applied to scenarios involving associated tasks.Moreover,our algorithm proves adaptable to a variety of associative task models with different structures.
ACKNOWLEDGMENT
This research was supported by National Natural Science Foundation of China (Grant No.62071377,62101442,62201456);Natural Science Foundation of Shaanxi Province (Grant No.2023-YBGY-036,2022JQ-687);The Graduate Student Innovation Foundation Project of Xi’an University of Posts and Telecommunications under Grant CXJJDL2022003.
杂志排行

China Communications的其它文章
- Distributed Application Addressing in 6G Network
- A Support Data-Based Core-Set Selection Method for Signal Recognition
- Actor-Critic-Based UAV-Assisted Data Collection in the Wireless Sensor Network
- Integrated Clustering and Routing Design and Triangle Path Optimization for UAV-Assisted Wireless Sensor Networks
- Joint Task Allocation and Resource Optimization for Blockchain Enabled Collaborative Edge Computing
- Stochastic Gradient Compression for Federated Learning over Wireless Network