基于K近邻算法的主机异常行为检测
2024-04-28黄智睿谢显杰杨晓丹
黄智睿,谢显杰,杨晓丹
(1.昆明冶金高等专科学校,云南 昆明 650033;2.云南师范大学,云南 昆明 650092)
0 引言
网络中高价值的数据不断吸引着黑客,黑客通过利用计算机存在的漏洞攻击计算机系统,以窃取其中有价值的数据[1]。为了防御黑客攻击,入侵检测系统应运而生。入侵检测方法可以分为基于流量的入侵检测方法和基于主机异常的入侵检测方法[2]。市面上的网络安全设备主要采用基于流量的入侵检测方法,目的是防御来自外部的直接攻击。该方法只关注黑客入侵网络时产生的异常流量,而忽视了监测内部人员的异常操作。这可能会产生以下2种安全隐患:(1)黑客绕过网络安全防御设备后可以使用窃取的账户做破坏性的操作[3];(2)如果相关单位的网络安全制度管理缺失或执行不到位,会导致低权限的员工使用高权限的用户账户进行操作造成不可挽回的损失[4]。使用基于主机异常的入侵检测方法可以识别用户操作是否存在异常,进而保证信息的安全。
本文提出了一种基于K近邻算法(K-Nearst Neighbor,KNN)的主机异常检测方法,本方法将系统调用序列看作是有规律的语句,而入侵者系统调用的规律异于正常用户,所以本方法使用自然语言处理(Natural Language Processing, NLP)中的N元语法(N-Gram)算法和词频-逆文本频率指数(Term Frequency-Inverse Document Frequency,TF-IDF)算法对系统调用序列进行特征提取。为了减少计算开销,本方法使用主成分分析(Principal Component Analysis,PCA)算法对特征向量进行降维处理,接着使用K近邻算法学习降维后的特征向量,最终得到一个用于检测主机异常的模型。本文中的实验使用新南威尔士大学公布的澳大利亚国防学院Linux数据集(Australian Defence Force Academy-Linux Dataset,ADFA-LD)对所提方法的效果进行了验证。实验证明使用K近邻算法的主机异常检测方法建立的检测模型有很好的性能。
1 相关工作
由于语义特征是通过分析不连续的系统调用模式得出的,适合神经网络学习。Creech等[5]提出了一种基于完整语义特征作为神经网络学习输入的入侵检测方法。该系统在ADFA-LD 数据集上的使用得到了良好的效果。不过该系统构造词典的过程是基于经验和实验,并不具有普适性,并且与经典的机器学习算法相比,神经网络的运算过程复杂、运行量大,不适合应用于对资源消耗敏感的普通主机。
Geng等[6]提出的使用N-Gram算法构造词典的方法正好可以解决Creech等[5]提出方法中构造词典不具普适性的问题,并且在数据集上测试得到了良好的效果。但它只考虑了词语的频率而忽视了特征向量等其他内在联系。
Borisaniya等[7]提出了基于修正向量空间表示模型的主机入侵检测框架。与各个系统调用根据它们在系统调用跟踪中的频率分配权重的标准向量空间表示模型不同,修改后的向量空间表示模型将多个连续的系统调用视为一个单词。因此,该框架在跟踪文件中保留了系统调用的相对顺序,这对于正确建模进程行为至关重要。不过,该框架存在着随着N-Gram术语数量的增加,向量空间表示模型呈指数增长的问题。
为了解决基于修正向量空间表示模型的主机入侵检测框架中向量空间表示模型呈指数增长的问题[7],Subba等[8]提出了通过设定阈值来保留频率大于阈值的特征值,实现了降维效果的方法。不过如何设定阈值却成了一个问题。阈值设定过高,会去除许多有作用的特征,阈值设定过低,又达不到降维的效果。
结合相关文献的研究,发现常见的主机异常检测方法存在以下3个问题。
(1)针对系统调用序列提取特征值时,常见的主机异常检测方法没有考虑调用顺序。一般情况下,异常操作和正常操作的调用顺序是有差异的。所以新提出的方法需要考虑操作的调用顺序。
(2)常见的主机异常检测方法只考虑准确性,而忽视了提取特征的高维度导致巨大的运算开销。所以新提出的方法需要对提取出的特征值进行降维处理。
(3)常见的主机异常检测方法即使考虑采取降维措施的异常检测方法,也只通过简单的设定阈值达到降维效果,而没考虑各特征值之间的联系。所以新提出的方法在实现降维时需要考虑特征值之间的关系。
2 基于K近邻算法的主机异常检测方法设计
如图1所示,本文提出的主机异常行为检测方法主要经过以下3个阶段实现对异常操作的检测。
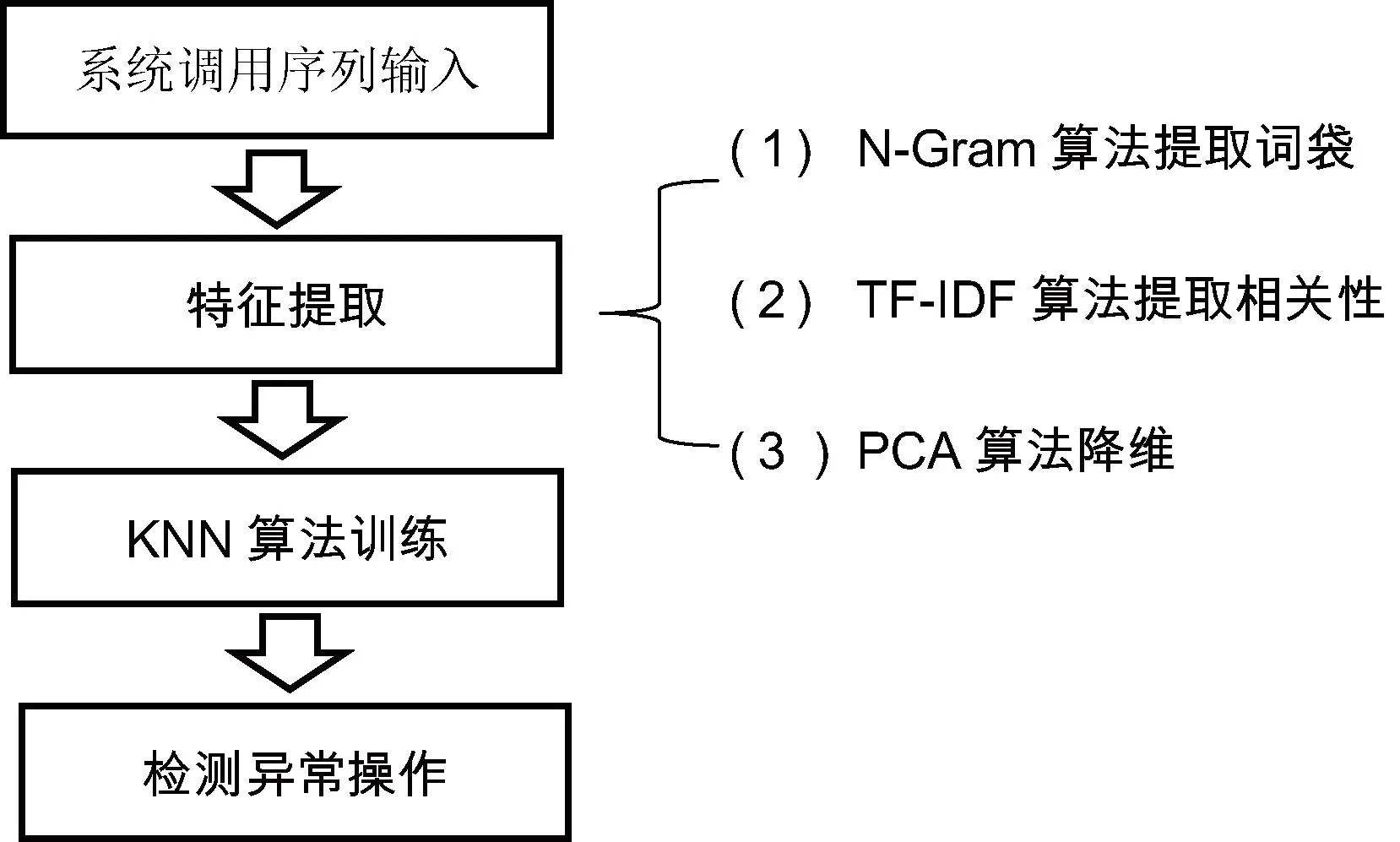
图1 基于K近邻算法的主机异常行为检测方法
第一阶段特征提取阶段。本方法使用N-Gram算法和TF-IDF算法对输入的系统调用序列进行特征提取,并且使用PCA算法对特征值进行降维处理。
第二阶段K近邻算法学习阶段。本方法使用KNN算法对降维后的特征值进行学习。
第三阶段检测异常操作阶段。K近邻算法训练后建立的检测模型可以对新输入的操作数据进行判断,判断是否为异常操作。
2.1 特征提取
在特征提取过程中,本方法将输入的系统调用序列视为文本数据来处理,其中每次系统调用都被视作一个独立字母。本方法采用N-Gram算法来构建词袋模型,从而捕捉系统调用之间的局部依赖关系。随后,本方法应用TF-IDF算法来衡量不同系统调用序列间的相关性,以突出重要特征并抑制噪声。然而,经过N-Gram和TF-IDF处理后得到的特征值维度往往较高,这可能会影响后续分析的效率和准确性。因此,本方法进一步引入了PCA算法,对提取出的高维特征值进行降维处理,以便在保留主要信息的同时降低计算复杂度。
2.1.1 使用N-Gram算法提取词袋
N-Gram算法是自然语言处理中最常用的一种算法,N的数值确定了组成单词的字母数量。对于一列字母,N-Gram算法通过每次向后滑动一位来不断生成N个字母组成新单词,并且统计生成单词出现的次数,最终生成一个由N个字母组成的单词和该单词出现的次数的词袋[9]。此阶段使用N-Gram算法生成了基于词频的词袋,该词袋将为后续的特征提取提供基础。
2.1.2 使用TF-IDF算法统计不同系统调用序列的相关性
TF-IDF算法即词频-逆文档频率算法,是基于统计的经典算法。TF-IDF算法的主要思想是单词的重要性随着它在文档中出现次数的增加而上升,并随着它在词袋中出现频率的升高而下降。TF-IDF算法由词频(Term Frequency, TF)、逆文档频率(Inverse Document Frequency, IDF)2部分组成[10]。TF只注重词在文档中出现的频次,没有考虑词在其他文档下出现的频次,缺乏对文档的区分能力。IDF则更注重词对文档的区分能力,2种算法各有不足之处。综合权衡词频、逆文档频率2个方面衡量词的重要程度,TF-IDF算法的计算公式如式1所示。
(1)
其中,ni,j为词ti在文档j中出现的频次;∑knk,j为文档j的总词数;|D|为文档集中的总文档数;|{j:ti∈di}|为文档集中文档di出现词ti的文档个数,分母加1是为了避免文档集中没有出现词ti导致分母为零的情况。
前一阶段通过N-Gram算法生成的词袋经过TF-IDF算法的特征提取,可以得到系统调用序列之间的相关性特征。
2.1.3 对特征值进行降维处理
PCA算法是一种使用最广泛的数据降维算法。PCA算法的主要思想是将n维特征映射到k维上,实现对数据特征的降维处理[11]。由于调用序列的数据经过N-Gram算法和TF-IDF算法提取出的特征值维度较高,使用PCA算法对特征值降维,既进行了降维处理又保留了特征值之间的关联。
2.2 K近邻算法
K近邻算法又称KNN算法,是常用的机器学习算法之一。KNN算法的基本思想为:KNN算法训练样本集中的训练样本;KNN算法对需要判断的新样本和训练样本集的训练样本进行比较;KNN算法选取和新样本特征值距离最近的K个邻居;KNN算法根据距离最近K个邻居的标签来判断新样本的标签[12]。
使用KNN算法对提取到的降维特征值进行训练,并使用训练好的模型对新产生的系统调用序列进行检测是否为异常操作。
3 实验
本文使用新南威尔士大学澳大利亚国防学院公布的ADFA-LD数据集对提出的基于K近邻算法的主机异常行为检测方法进行如下2方面的实验:验证提出方法的降维效果;验证提出方法在检测异常操作的效果。
3.1 ADFA-LD数据集
本实验数据集为ADFA-LD数据集,该数据集是新南威尔士大学澳大利亚国防学院公布的一套基于Linux系统的主机级入侵检测系统数据集合,通常被广泛用于各种入侵检测产品的测试。ADFA-LD数据集中的每个文件独立记录了一段时间内的系统调用顺序,每个调用都用数字标号。并且标注了该文件记录的系统调用是否为异常操作[13]。
3.2 实验方法
实验流程如图2所示,首先实验采用N-Gram算法和TF-IDF算法提取ADFA-LD数据集中各系统调用序列的特征值;接着采用PCA算法对得到的特征矩阵进行降维处理;然后实验随机划分60%的样本作为训练集,40%的样本作为测试集[14],并且在划分出来的训练集上使用KNN算法训练检测模型;最后,实验使用训练好的检测模型对测试集中的数据进行异常操作检测,验证检测效果。

图2 实验流程
为了评估入侵检测模型并比较其性能,通常使用召回率、精度、综合评价指标和准确性等指标[15]。本次实验使用了召回率、精度、综合评价指标和准确性4个指标来评估提出的异常行为检测方法的性能。召回率衡量的是异常操作检测系统的查全率,是检测系统检测出真正存在的异常操作数与真实异常操作数的比率。精度衡量的是检索系统的查准率,是检测系统检测出真正存在的异常操作数与检测出所有异常操作数的比率。综合评价指标可以更综合地评估检测系统,是精度和召回率加权调和平均。准确率是衡量在所有的检测样本中,有多少行为被准确评估了,包括正常行为和异常行为。
3.3 实验结果
3.3.1 降维效果
本文所提出的方法,在特征提取阶段采用了PCA算法进行降维处理。实验的核心比较点在于,对比了采用此方法降维后的样本空间与未进行降维处理的样本空间的维度差异。如表1所示,当N-Gram的取值在2~6的整数范围内变动时,原本高达1000维的样本列数分别被有效降低至128维、177维、191维、191维和176维。这一结果显示,本方法在降维方面展现出了显著效果。

表1 PCA降维前后对比 单位:维
3.3.2 性能比较
如图3所示,分别从召回率、精度、综合评价指标和准确性4个指标展示了基于K近邻算法与基于决策树算法和朴素贝叶斯算法对于主机异常检测的性能,其中N-Gram取值为2~6的整数。通过实验可以得出以下结论。
(1)除了N-Gram取值为4时,K近邻算法的召回率都高于另外2种算法;当N-Gram取值为4时,K近邻算法的召回率和决策树算法一致为86.2745098%;决策树算法的召回率高于朴素贝叶斯算法。
(2)K近邻算法的精度都高于另外2种算法;当N-Gram取值为6时,K近邻算法的精度略高于决策树算法,分别为83.6363636%和83.5403727%;决策树算法的精度都高于朴素贝叶斯算法。
(3)K近邻算法的综合评价指标都高于另外2种算法;决策树算法的精度都高于朴素贝叶斯算法。
(4)K近邻算法的准确性都高于另外2种算法;
决策树算法的准确性都高于朴素贝叶斯算法。
(5)通过4个指标的综合评估,K近邻算法优于决策树算法,决策树算法优于朴素贝叶斯算法。
4 结语
在深入研究相关文献的基础上,本文提出了一种基于K近邻算法的主机异常检测方法。在采用了ADFA-LD数据集的实验中,证明了该方法构建的模型在性能上优于使用决策树算法和贝叶斯算法构建的模型。与现有的主机异常检测方法相比,本文提出的方法具有以下优势:首先,它使用N-Gram算法和TF-IDF算法提取特征,这充分考虑了系统调用序列的顺序。其次,它通过采用PCA算法对特征向量进行了有效地降维处理,从而降低了计算复杂性。此外,K近邻算法的运用考虑了特征值之间的关系,增强了检测模型的准确性。最后,实验建立了高效的主机异常检测模型,能够准确判断主机是否存在异常操作。综上所述,本文提出的基于K近邻算法的主机异常检测方法在特征提取、降维处理、算法选择和模型构建等多个方面均展现出显著优势。这一创新性的解决方案,将为主机安全领域提供有力支持,有助于更准确、高效地检测主机异常操作。
