FPN算法在视觉感知机器人抓取控制的应用研究
2024-04-27王利祥郭向伟卢明星
王利祥,郭向伟,卢明星
(1.河南护理职业学院公共学科部,河南 安阳 455000;2.河南理工大学电气工程与自动化学院,河南 焦作 454000)
1 引言
智能机器人不仅要能够执行预定义的固定任务,还应该能够基于嵌入式传感器感知环境并与环境交互[1],视觉机器人对于物体的夹持是智能化控制的一大重要标志。成功的抓取主要通过视觉或触觉传感器进行正确的抓取姿势检测,并在此基础上进行精确的夹持控制[2]。为了实现自主抓取,国内外研究人员对视觉机器人的控制开展了大量研究,文献[3]将深度学习方法应用到机器人抓取中,提出了一种用于多步级联抓取的检测系统,该系统通过神经网络提取的特征代替之前算法中手工制作的特征。文献[4]提出了深度强化学习的视觉机器人抓取策略,该策略通过深度网络框架进行学习训练,有效提升了机器人抓取物体成功率。文献[5]研究了RGB颜色空间下的视觉机器人识别方法,提出了视觉逼近的控制算法,该策略应用在视觉机器人上具有一定的识别成功率和抓取成功率。文献[6]结合卷积神经网络和深度学习方法,提出了机器人抓取算法,该算法在Cornell抓取数据集上得到了有效验证,且应用在视觉机器人抓取动作上。文献[7]针对视觉机器人的物体抓取,在图形融合技术的基础上提出了改进的Canny的图形边缘检测算法,该控制算法在抓取物体过程中具有较好的鲁棒性能。文献[8]基于残差BP神经网络研究了视觉机器人对图像识别与机器人关节角之间的关系,神经网络模型的性能得到了有效提升,通过划分区域对数据进行了训练,视觉机器人的网络训练速度得到了提升。
上述所有方法都是基于单尺度特征生成抓取,这些特征提取器具有低分辨率(较高层)或语义信息较少(较低层)的特征,这削弱了抓取检测精度。基于此,使用密集连接的FPN作为特征提取器,将语义更强的高级特征图与分辨率更高的低级特征图融合,将两阶段检测单元附加到每个融合层,根据融合的特征图中生成密集的抓取预测,这种模型结构保证了对各种物体的精确抓取。并在Cornell抓取数据集和Jacquard数据集上训练,并证了所提算法在抓取姿势估计的有效性。设计了两种不同真实场景的物体抓取控制实验,结果表明所提模型能有效提高机器人抓取物体的能力。
2 视觉机器人结构模型
这里研究的视觉感知抓取机器人结构示意图,如图1所示。将深度相机RGBD相机安装在机器人手臂上进行视觉感知,如图1(a)所示。抓取构型的边界框,如图1(b)所示。[x,y]表示图像帧中的位置,[w,h]以像素表示夹持器宽度和开口宽度,θ是图像框中矩形相对于X轴的夹角,即通过5D向量[x,y,w,h,θ]来描述图像帧中的抓取姿势。

图1 视觉感知抓取机器人结构示意图Fig.1 Structure Diagram of Visual Perception Grasping Robot
在检测到图像中的抓取姿态后,首先将图像帧中表示的抓取姿态转换到相机坐标系中,其中可以利用相机固有参数和感知到的原始深度图像计算变换矩阵。抓取估计的最终目标是找到相对于机器人基座的边界框的位置和角度。一旦确定摄像头和抓取姿势之间的齐次变换后,可以根据机器人运动学计算抓取姿势与机器人底座之间的位置和方向位移:
机器人抓取姿态的估计,与抓取器和物体之间的最佳接触点有关。这些6D空间接触点可以通过机器人手臂相对于机器人基座的6D位姿进行构型,即[X,Y,Z,yaw,pitch,roll]。
在不丧失普适性的情况下,可以假设机器人手臂沿着实验台法线接近物体,或者对于其他情况,可以用抓取中心在物体上的表面法线作为接近方向,因此抓取姿势的角度可以简单地通过偏航角来确定。
对于平移,图像拍摄点到实验室工作台之间的高度是固定的,或者可以通过原始深度图像像素值计算。通过这些简化的程序,可以发现抓取检测所需的位姿构型由[X,Y,yaw]组成,模型应该根据捕获的RGB或深度图像找到正确的构型。此外,还有两个特征为每一个独特的抓取提供有用的信息,一个是夹持器的开口宽度H,这是由检测出的物体大小和几何细节决定,另一个是抓取区域的宽度W。最后通过5D 向量来描述可能的抓取区域,即[X,Y,yaw,H,W]。所有这些特征都可以通过摄像机的固有特性和机器人的结构构型映射到图像帧。
3 视觉机器人抓取控制策略
3.1 FPN控制结构框图
抓取矩形的大小随物体及其几何细节的变化而变化,为了适应物体,模型应考虑预测不同大小的抓取矩形。对于普通的CNN,卷积层和池化层的组合逐步生成层次特征图。
随着层的深入,特征映射的接受域变大,可以获得分辨率降低、语义信息增加的层。较低层次的特征图有更多的图像细节,并能够预测小的抓取矩形。相比之下,高级特征图包含更多抽象的语义信息,且能够回归大的抓取矩形。仅将抓取检测单元附加到最高或最低(最精细)层,将分别导致抓取区域边界框参数回归不准确或识别失败。
这里提出了一种密集连接的FPN,即下采样部分,上采样部分及其横向连接,作为特征提取器。下采样部分从每个ResNet阶段的最后一层输出中选取,即输出大小相同的图层。
然后将这些来自不同层的特征映射进行密集融合,提取图像的语义信息。这些融合的特征图可以在精确的定位和丰富的语义信息之间实现很好的平衡,并发送给预测单元,整个模型,如图2所示。
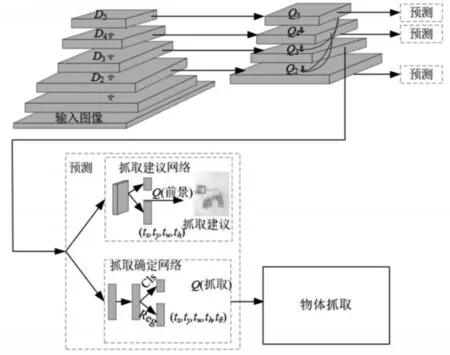
图2 整体模型结构示意图Fig.2 Schematic Diagram of Overall Model Structure
特征提取器的下采样部分由ResNet-50构造[9],得到一系列标度步长为2的标度特征图,每个最后剩余块的激活输出,记为[D2,D3,D4,D5],是系统中的下采样特征图。与输入图像相比,这些特征图的步幅为[4,8,16,32]像素。然后,通过对应的对应特征图Di和所有之前上采样的融合层的横向连接生成融合层,记为[Q5,Q4,Q3,Q2]。最高层Q5是通过对特征图D5上操作的(1×1)核获得,融合层[Q5,Q4,Q3,Q2]计算为:
其中,Ki为从最上层(5)到最后一层(j=i+1)的所有前融合层的连接,即:
融合层Q2的形成过程示意图,如图3所示。Q2是之前所有上采样层(Q3,Q4,Q5)和下采样特征图D2的融合,抓取姿态估计可以通过两阶段抓取检测器从这些融合层中获得。
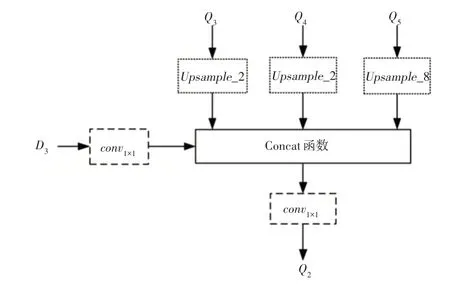
图3 融合层Q2的形成Fig.3 Formation of Fusion Layer Q2
3.2 两阶段抓取
抓取姿势检测单元根据融合的特征图中生成密集的抓取预测,检测单元分为两个阶段,包括第一阶段的粗抓取区域检测和第二阶段的抓取姿态细化。在第一阶段中,大部分可能的抓取区域通过锚点策略获得。锚点是一系列预定义的水平边界框,具有不同的大小和纵横比,位于图像中密集平铺的锚点上。锚点的设置应该覆盖大部分的抓取矩形[10],除了旋转角度,旋转角度会在第二阶段回归。将这些锚点作为参考,以预测抓取区域的可能性,并得到粗抓取框参数,包括位置和尺度。抓取建议网络是一个轻量级网络,在整个图像上滑动,以搜索潜在的对跖抓取。
在第二阶段,基于建议裁剪的融合图,并使用感兴趣区域(ROI)池化策略提取固定长度特征,并将其发送到分类头和回归头进行精细化抓取预测。由于抓取检测任务只包含单个类别,即抓取区域与否,第二阶段分类头与第一阶段相同,用于预测正抓取区域的可能性。
与之前固定锚点和建议数量的对象检测方法不同,本研究通过保证正样本和负样本之间的平衡来计算损失和更新模型参数。选取300个得分最高的锚点作为池,随机选取最多128个正锚点和128个负锚点。第二阶段的训练也是类似的过程,选择最多32个正面建议和32个负面建议。使正样本的数量等于每个阶段的负样本的数量,即使没有正面建议,在第二阶段也至少有16个抽样的负面建议,以防模型训练过拟合到第一阶段,即该模型产生零个正面建议以生成第二阶段的零损失(Lg-cls=0,Lg-reg=0)。
3.3 模型损失
抓取姿态检测管道在每个阶段都包含两种损失。在第一阶段为建议分类损失Lp-cls和提议位置和大小回归损失Lp-reg。对于第二阶段,有夹持可能性预测损失Lg-cls和定向抓取姿态和尺寸回归损失Lg-reg。总损失L的计算方法为:
第一阶段和第二阶段损失的计算过程相似,只是在第一阶段使用锚点作为参考,计算地面实况和预测之间的回归损失,而在第二阶段使用第一阶段生成的建议作为参考,在第二阶段中存在角度回归损失。在这两个阶段中,使用平滑L1损失(Ls-L1)来计算锚点(或建议)与地面实况的偏移量,以及锚点(或建议)与预测的偏移量之间的回归损失。
其中,objn=1 表示前景,其中可能存在正抓姿,否则视为背景,不进行下一步的回归处理。由于只计算了第二阶段抓姿预测头中的角度回归损失,因此对于Lp-reg的计算不包括角度,即j∈{x,y,ω,h}。第n个偏移量v=[tx,ty,tw,th,tθ],有:
其中,[x,y,w,h,θ]表示地面实况姿势,[xa,ya,wa,ha,θa]和[x',y',w',h',θ']分别代表锚盒和预测的抓取姿势。抓取的预测损失Lp-cls和Lg-cls为交叉熵损失,λ1,λ2和λ3是这些损失的加权,设置为[1.0,1.0,1.0]。
4 仿真和实验
4.1 数据集的仿真
使用Cornell抓取数据集和Jacquard数据集[11]的抓取数据集来评估所提抓取姿态检测算法的性能,首先,通过Cornell抓取数据集对抓取模型进行评估,通常会通过图像和对象两种不同的策略对数据集进行分割。与图像分割相比,采用对象分割时,训练数据集和测试数据集的对象没有重叠,更接近真实场景。本研究选择了面向对象的分割策略来比较模型性能。然后,使用标准矩形度量来确定抓取预测是否正确。该度量同时考虑了预测边界框的位置和角度。对于正确的预测,Jaccard指数应该大于0.25。Jaccard指数定义为地面实况和预测之间的交集与并集的比率。模型用80%的样本训练,用20%的样本测试。对于对象分割,每个对象的捕获图像数量不同,导致不同数量的测试图像,这增加了检测精度的随机性。
对于Cornell抓取数据集,由于训练图像的数量有限,检测精度随每个训练时期而变化。通过同时考虑角度误差和Jaccard指数,研究了Cornell 抓取数据集和Jacquard数据集上的检测精度,如表1、表2所示。可以看出,本研究所提模型在两个数据集上都比其他方法获得了更高的检测精度。RGB-d模态策略是将RGB和深度模态结合起来,用对应的深度图像替换蓝色通道。仅采用深度模态训练的模型准确率达到91.6%,而采用RGB-d 模态和RGB模态训练的模型准确率更高。对于Cornell 抓取数据集,真实捕获的深度图像是有噪声的,尤其是在图像边界和物体边缘处,因此引入相应的RGB模态可以提高抓取检测精度。在尺寸为(420×420)的输入图像下,本研究所提模型的检测率约为35Hz,可以满足大多数实时机器人应用的要求。对于Jacquard数据集上的检测精度,由于模拟的深度图像清晰准确,使用RGB模态时并没有太大的提高。基于对象分割的检测精度,所提模型显示了精确抓取姿势的能力。
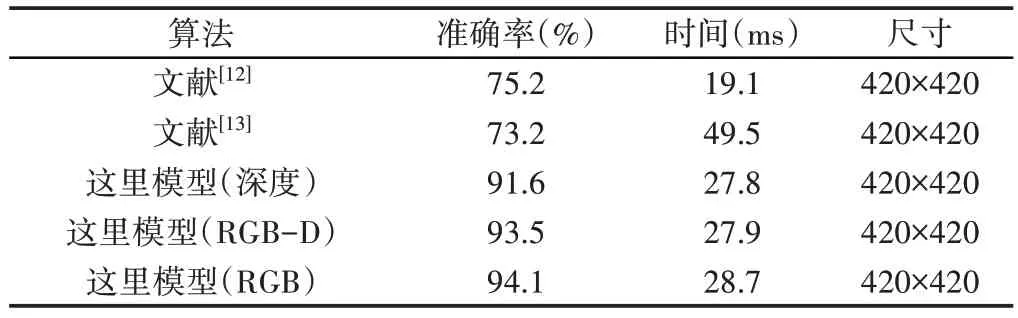
表1 Cornell Grasp数据集的性能比较Tab.1 Performance Comparison of Cornell Grass Datasets

表2 Jacquard数据集上的检测精度Tab.2 Detection Accuracy on Jacquard Data Set
从Cornell 抓取数据集中选取的全尺寸RGB图像评估示例,如图4所示。

图4 这里模型在Cornell 抓取数据集上的检测Fig.4 Detection of Our Model on Cornell Grab Dataset
从上到下,每一行分别代表输入的RGB图像、第一阶段的抓取建议和第二阶段的抓取检测结果。粗略的抓取建议在模型的第一阶段生成,抓取姿态预测则在第二阶段提供。与Jacquard数据集相比,Cornell 抓取数据集中的真实捕获图像在背景中的噪声更大,导致第一阶段产生假阳性建议,可通过第二阶段的细化过程进行过滤。密集连接的特征图和两阶段的抓取检测器确保了对多种尺寸和复杂形状的对象成功的抓取检测。
所提模型从Jacquard 数据集训练集的抓取检测,如图5 所示。可以看出Jacquard 数据集训练模型的输入、中间阶段和输出的实例,使用锚点作为参考有助于生成高质量的建议。

图5 所提模型在Jacquard数据集训练集的抓取检测Fig.5 Grab Detection of the Proposed Model in Jacquard Dataset Training Set
4.2 实验验证
基于上述模型,本节通过实验对模型的合理性进行验证,设计了两个实验来检验模型检测精度,其中模型由Cornell抓取数据集进行训练。首先以不同的姿势多次抓取单个物体,然后抓取堆叠在一起的各个物体,以验证抓取检测器在现实世界中的有效性。在实验中,可以使用RGB或深度图像生成抓取姿势预测,然后使用深度图像计算相应的抓取高度。与深度图像相比,RGB图像的噪声更小,但容易受到光照条件的影响。因此,在实验中使用深度图像作为模型输入来消除这些误差。
本研究开展了两个抓取实验,包括一个单物体抓取实验和一个多物体抓取实验。在实验中使用的对象均没有出现在训练数据中。得出实验结果如下:
(1)实验1:收集了42个物体,覆盖了机器人在现实世界中可能具有的大部分抓取姿态。这些被选中的物体在形状、颜色、大小和材质上都有所不同,以挑战抓取姿势检测模型。在实验过程中,每个物体都被以“扔”的方式随机放在实验台上三次,因此总共进行了126次抓取试验,实验1的抓取试验,如图6所示。

图6 抓取机器人实验1示意图Fig.6 Schematic Diagram of Grasping Robot Experiment 1
第一行中,机器人手首先移动到预定义的初始位置,以便安装在腕部的深度相机拍摄对象的照片。第二行中,基于捕获的深度图像,模型试图找到最佳抓取区域。第三行中,将夹持边界框转换为相对于机器人基座的空间姿势。第四行中,机器人手移动到与生成的夹持姿势对齐的位置,并闭合手指。第五行中,机器人夹持物体以提起。可以看出所提模型成功地生成了准确的抓取姿势。失败的原因主要是高度执行误差造成,高度执行误差主要来自于深度相机的传感噪声,而这种误差会导致夹持器无法接触到物体。
(2)实验2:提出多物体抓取实验,其中物体之间密集重叠。这个实验更具挑战性与前两者相比,因为背景并不干净,预测抓取应该更准确,以避免夹持器和“背景”对象之间的碰撞。此外,不仅对象没有出现在训练数据中,而且训练后的模型在训练过程中从未遇到过杂乱的场景。
收集了36个形状、大小和颜色各异的物体,并将它们随机分成4个不同的组,每组包含9个物体。对于每组物体,都将其放入不透明的盒子中,并用力摇晃以确保其随机性和无序性,然后再将其放入工作空间中。机器人系统从这些物体中检测抓取姿势,然后选择得分最高的一个由执行单元去实现。系统逐个抓取物体,直到清理工作空间,如图7所示。

图7 抓取机器人实验3示意图Fig.7 Schematic Diagram of Grasping Robot Experiment 3
抓取实验在不同的相机初始位置下重复三次,失败案例的原因分类为位置误差(P)、尺寸误差(S)、角度误差(A)、高度误差(H)和不稳定(NS)。其中P、S和A与抓取预测有关,H和NS主要是由于深度感知不确定性和夹持器闭合力不足造成。由[P,S]引起的失败尝试次数从(5,8)减少到(2,1),这表明所提方法在解决复杂场景下的抓取检测时是有效的。
5 结论
针对视觉机器人的物体抓取控制,与之前的抓取检测相比,结合了特征金字塔网络(FPN)算法实现机器人对物体抓取的精确控制,得出的主要结论有:
(1)使用密集连接的FPN作为特征提取器,将语义更强的高级特征图与分辨率更高的低级特征图融合,将两阶段检测单元附加到每个融合层,根据融合的特征图中生成密集的抓取预测,这种模型结构保证了对各种物体的精确抓取。
(2)FPN利用CNN固有的多尺度层次结构,为检测头部提供多个具有更丰富语义信息的特征映射。该模型在Cornell抓取数据集和Jacquard 数据集上训练,检测准确率分别为94.1%和89.6%。验证了所提模型在抓取姿势估计的有效性。
(3)在理论分析的基础上,设计了两种不同真实场景的物体抓取控制实验,结果表明视觉机器人具有抓取各种日常物体的潜力,进一步验证了所提模型的合理性。
