融合潜在结构与语义信息的多模态推荐方法
2024-04-26张晓明梁正光姚昌瑀李肇星
张晓明 梁正光 姚昌瑀 李肇星
随着互联网的迅速发展,网络信息资源呈现爆炸式增长,庞大的信息量导致用户难以高效发现所需的有用信息.因此,为用户提供个性化推荐功能的推荐系统在当今社会变得愈发重要[1].传统的推荐方法包括基于内容的推荐、基于协同过滤的推荐、混合推荐等.基于协同过滤的推荐是目前主流的推荐方法,其基于用户历史交互信息,能适应用户行为的变化,因此得到广泛的发展和应用.然而真实世界中稀疏的历史交互信息使基于协同过滤模型的推荐在现实中性能受限.因此,如何有效缓解数据稀疏性成为现阶段研究热点之一.
受海量信息中丰富的多媒体资源启发,学者们提出多模态推荐方法.通过提取物品的多模态特征,并将多模态特征引入推荐系统中,可缓解数据稀疏问题.一部分多模态推荐方法利用多模态特征的语义信息丰富物品表示.VBPR(Visual Bayesian Persona-lized Ranking)[2]将物品ID嵌入与视觉特征融合,丰富物品表示.DeepStyle[3]从视觉表示中提取物品类别,用于学习物品的特征和用户偏好.随着图神经网络的广泛应用,NGCF(Neural Graph Collaborative Filtering)[4]和LightGCN(Light Graph Convolution Net-work)[5]基于用户的历史交互信息构建用户-物品二部图,并使用图卷积神经网络学习拓扑结构,提升推荐性能.
同样,一些多模态推荐方法也结合图神经网络学习用户-物品二部图,优化用户和物品表示.MMGCN(Multimodal Graph Convolution Network)[6]构建特定模态的用户物品图,通过图卷积学习用户表示和物品表示,并融合各种模态下的表示.GRCN(Graph-Refined Convolutional Network)[7]利用多模态特征更新用户-物品二部图的边权重,减轻边上的噪音.
上述推荐方法都基于协同过滤范式,聚焦于构建更好的用户-物品图和聚合策略,通过高阶关系发现用户-用户和物品-物品的关联.另一类多模态推荐方法通过挖掘潜在结构以完善拓扑结构信息.DualGNN(Dual Graph Neural Network)[8]显式建模用户对不同模态的注意力,并构建用户-用户图,捕获相似用户的偏好.LATTICE(Latent Structure Mining Method for Multimodal Recommendation)[9]利用物品的多模态特征构建物品-物品图,挖掘物品之间的潜在结构,但物品-物品图的更新需要很大的时间成本.为此,FREEDOM(Freezing and Denoising Multimo-dal Model for Recommendation)[10]使用冻结的物品-物品图,并通过实验验证冻结的物品-物品图能提供更好的潜在结构,同时还设计图剪枝技术,获得较优的推荐性能.
另一种缓解数据稀疏的办法是使用对比学习.SGL(Self-Supervised Graph Learning)[11]对二部图的边、节点进行删除等操作,生成新的视图,以此提升学习质量.SimGCL(Simple Graph Contrastive Lear-ning Method)[12]加入随机噪声以生成视图,探究对比学习起作用的原因.NCL(Neighborhood-Enriched Contrastive Learning)[13]使用邻域丰富的对比学习,将潜在邻居合并到对比对中.KGCL(Knowledge Gra-ph Contrastive Learning Framework)[14]还将对比学习引入知识图谱辅助的推荐系统中,利用对比学习减少知识图谱中的噪声,提高推荐性能.HCCF(Hyper-graph Contrastive Collaborative Filtering)[15]利用超图对推荐数据建模,对比不同的超图结构.SLMRec(Self-Supervised Learning-Guided Multimedia Reco-mmendation)[16]使用3种数据增强方法,揭示数据中的多模态模式,进行对比学习.MGCN(Multiview Graph Convolutional Network)[17]也使用对比学习,最大化多模态特征和行为特征之间的互信息.对比学习通过引入新视图等方式对数据进行增强,提高用户表示和物品表示的质量和推荐系统的性能.
尽管多模态推荐现已得到广泛研究,但普遍仅聚焦于多模态特征的语义信息或潜在结构挖掘,缺乏对两者之间关联的充分利用.因此,本文提出融合潜在结构与语义信息的多模态推荐方法(Multimodal Recommendation Method Integrating Latent Structures and Semantic Information, MISS).根据物品的多模态特征、用户历史交互构建物品-物品图、用户-用户图,揭示潜在结构.使用历史交互,生成用户-物品二部图,学习用户行为.之后采用图卷积技术,学习各图的拓扑结构,将用户和物品ID嵌入物品-物品和用户-用户同构图上执行图卷积,挖掘潜在结构.通过潜在结构融合,将得到的表示进一步在用户-物品二部图上执行图卷积,学习用户的历史行为,使物品表示和用户表示能结合潜在结构与二部图结构.为了融合多模态特征提供的潜在结构和语义信息,设计对比学习机制,使学习潜在结构的物品表示与其不同模态下的特征对齐.最后,在3个公开数据集上验证MISS在提高推荐性能上的有效性.
1 融合潜在结构与语义信息的多模态推荐方法
本文提出融合潜在结构与语义信息的多模态推荐方法(MISS),整体结构如图1所示.MISS主要包括如下部分.
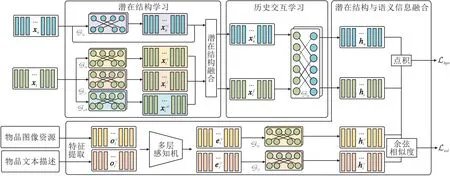
图1 MISS整体框架
1)潜在结构学习.通过数据挖掘,发现并学习其中的潜在结构.
2)历史交互学习.构建用户-物品二部图,学习用户的历史行为.
3)潜在结构与语义信息融合.使用对比学习,融合潜在结构与语义信息.
1.1 问题描述
多模态推荐旨在综合利用文本、视觉等多模态信息,挖掘用户偏好,为其推荐物品.在本文中,设U为用户集合,I为物品集合,M为用户数量,N为物品数量,每位用户u∈U根据用户历史交互矩阵
Y∈RM×N={yui|u∈U,i∈I}
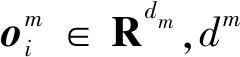
1.2 潜在结构学习
1.2.1 潜在关联挖掘
为了从多模态特征中挖掘物品之间的潜在关联,本文基于物品的多模态特征,计算在不同模态下物品间的相似度,构建模态m下的物品-物品图
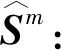
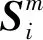
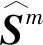
本文使用物品的文本特征和视觉特征,构建文本T和视觉V模态下的物品-物品图GT和GV.之后为了构建多模态物品-物品图
根据不同模态的重要性,加权求和得到图GM的邻接矩阵:
其中,αm为模态m的权重系数,不同模态的权重和为1.
同样,为了探索用户间的潜在关联,根据用户间共同交互的物品数计算用户间的相似度,进而挖掘用户间的潜在关联,并构建用户-用户图
用于显式揭示用户-物品-用户这种高阶关系.

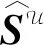
1.2.2 潜在结构学习
通过潜在关联挖掘可发现物品间和用户间的潜在关联.为了进一步利用这些潜在结构信息优化用户表示和物品表示,本文使用图神经网络学习这些潜在结构信息.将物品和用户嵌入基于不同潜在结构进行图卷积,利用挖掘的潜在结构对用户表示和物品表示执行消息的传递与聚合操作,使图中节点能利用不同的潜在关联更新自身的信息,得到信息更全面的用户表示和物品表示.
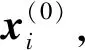
其中,Z∈{T,V,M},NZ(i)为物品i在物品-物品图GZ中的邻居节点.
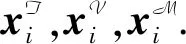
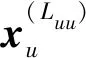
其中Luu为图卷积的层数.
通过图卷积操作,可得到学习潜在结构的用户表示和物品表示.为了更好地融合这些结构信息,设计潜在结构融合机制,聚合这些表示.对于物品表示,根据不同模态的权重系数将物品表示进行加权求和,融合后得到物品表示:
(1)
对于用户表示,考虑用户间的潜在结构学习与之后学习历史交互使用的数据同为用户历史交互记录,为了缓解多轮的消息传递和聚合过程中梯度减小的问题,对用户的潜在结构融合采用残差机制,在传播时更容易保持梯度,有利于提高用户表示的质量.最终得到融合之后的用户表示:
(2)
1.3 历史交互学习
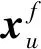
其中ND(u)和ND(i)分别为用户u和物品i在图GD上的邻居节点.
最后通过READOUT函数,得到最终的用户表示和物品表示:
其中Lui为在用户-物品图上执行图卷积的层数.READOUT函数可采用加和、拼接和平均等函数,本文使用平均函数.
1.4 潜在结构与语义信息融合
多模态特征中的语义信息是指物品从不同感官(如文本、视觉等)提取的能表达语义含义的特征,这些特征有助于丰富用户和物品的向量表示.融合不同模态下表现的语义信息,可使推荐系统进一步理解物品的各种属性.本文使用物品的文本特征和视觉特征,包含物品在不同模态下获得的关于物品的高层次语义内容,每个模态的特征都提供独特的信息视角.例如:文本特征提供关于物品的文本描述,而视觉模态提供有关物品外观、形状、颜色等方面的视觉信息.
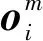
(3)
其中,Wm∈Rdm×d为多层感知机中的线性变换矩阵,bm∈Rd为偏置项.

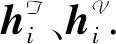

其中,s(·,·)表示计算两个向量之间的相似度,本文使用余弦相似度,τ为对比损失的温度系数.
最后将不同模态的对比损失根据权重加和,得到总的对比损失:
(4)
1.5 模型预测和优化
本文通过用户表示和物品表示计算内积,得到用户u对物品i的偏好分数:
采用BPR(Bayesian Personalized Ranking)损失函数[19],该函数鼓励正对的用户-物品对的偏好得分高于其负对的得分,并构建三元组集合T,每个三元组(u,i,j)满足yui=1并且yuj=0.BPR具体定义如下:
(5)
其中σ(·)为Sigmoid激活函数.结合对比损失和BPR损失,得到最终的损失函数:
L=Lbpr+λLssl,
(6)
其中λ为对比损失的权重系数.
1.6 算法步骤
算法1MISS训练过程
输入多模态数据,用户行为数据
输出MISS
预处理构建用户-用户图、物品-物品图、
用户-物品图
初始化随机初始化用户和物品嵌入等模型参数
Forepoch= 1 toN
在用户-物品二部图执行图卷积操作,得到hi
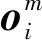
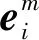
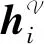
由式(4)计算对比损失Lssl
由式(5)计算BPR损失Lbpr
由式(6)计算总损失L
应用梯度下降更新模型参数
End for
2 实验及结果分析
2.1 实验环境
本文在Amazon的Baby;Sports and Outdoors(简记为Sports);Clothing, Shoes, and Jewelry(简记为Clothing)这3个公开数据集[20]上进行实验.历史交互数据通过筛选过滤,确保每位用户至少有5条交互记录.3个数据集的统计情况如表1所示.对于多模态数据,文本和视觉的多模态特征使用公开并广泛使用的版本[9],均通过预训练模型提取得到,文本特征为384维,视觉特征为4 096维.
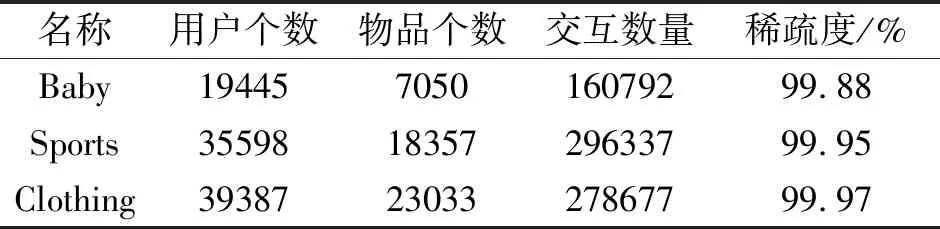
表1 实验数据集统计
为了便于算法性能对比分析,本文将数据集按照8∶1∶1的比例划分为训练集、验证集和测试集,并使用广泛采用的评价指标——召回率(Recall)和NDCG(Normalized Discounted Cumulative Gain)评价推荐性能,简记为R@K和N@K.嵌入维度d设为64维,使用文献[21]中方法初始化用户和物品的ID嵌入.在模型优化上,设置批次大小为2 048,并使用Adam(Adaptive Moment Estimation)优化器[22]优化模型参数,最大迭代次数设为1 000,在连续20次无性能提升时提前停止.为了保证公平性,所有模型在MMRec(Simplifying Multimodal Recommenda-tion)框架[23]上实现,并在NVIDIA RTX A5000显卡上进行实验.
2.2 对比实验
为了验证MISS的有效性,本文选择如下推荐方法进行对比.
1)协同过滤模型.
(1)LightGCN[5].去除图卷积中的特征变换和非线性激活,提高计算效率和性能.
(2)BPR[19].设计BPR损失,优化矩阵分解模式下的用户表示和物品表示.
2)多模态推荐模型.
(1)VBPR[2].在BPR的基础上,融合视觉特征与物品嵌入,丰富物品特征语义.
(2)MMGCN[6].利用图卷积得到不同模态的用户表示和物品表示,融合后得到最终的表示.
(3)GRCN[7].利用多模态特征对用户-物品二部图进行剪枝,减少二部图中的噪声.
(4)DualGNN[8].从用户-物品图中提取用户-用户图,增强用户表示.
(5)LATTICE[9].从多模态特征中学习物品之间的潜在结构,挖掘物品之间的关联.
(6)FREEDOM[10].冻结来自多模态特征的物品-物品图,并采用图剪枝实现最佳性能.
(7)SLMRec[16].在多模态推荐中使用自监督学习方式,并提出3种数据增强的方式.
各对比方法在K=10,20时的性能如表2所示,表中黑体数字表示最优值,斜体数字表示次优值.
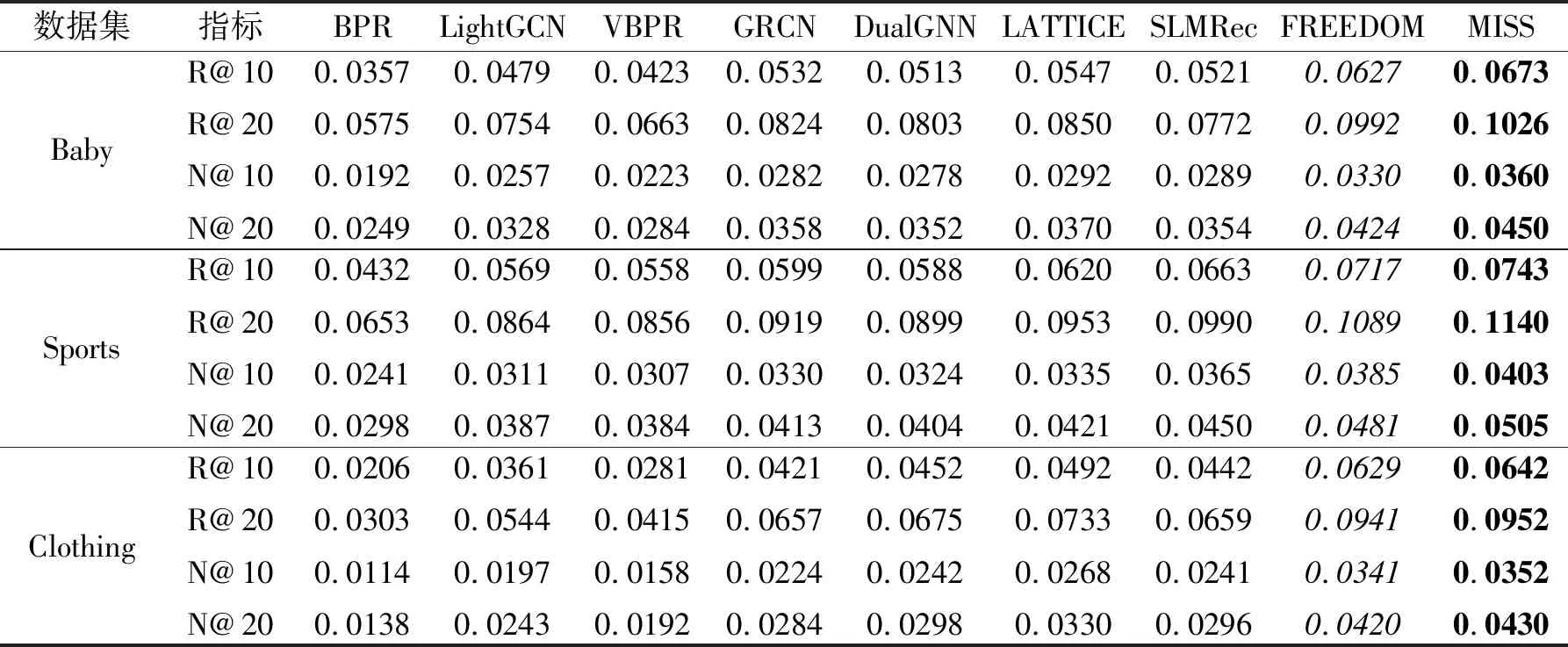
表2 各方法在3个数据集上的性能对比
由表2可见,MISS的性能优于对比方法.与现有模型相比,MISS学习潜在结构和二部图结构,有效融合各图的结构信息,并利用对比学习机制,将物品表示与其多模态特征对齐,从而融合多模态中的潜在结构和原始语义,进一步提高推荐性能.
2.3 消融实验
为了验证MISS中各组件的有效性,单独移除各组件以评估不同组件的贡献,从而得到MISS的3种变体.
1)MISSii.移除物品-物品图潜在结构学习的MISS.
2)MISSuu.移除用户-用户图潜在结构学习的MISS.
3)MISScl.移除对比学习机制的MISS.
3种变体和MISS在3个数据集上的性能对比如图2所示.
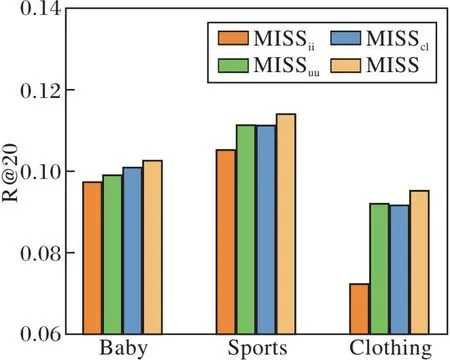
(a)R@20
由图2可看出,物品-物品图的潜在结构学习在3个数据集上均为贡献度最大的组件,在用户和物品数量更多的数据集Sports、Clothing上,用户-用户图的潜在结构学习和对比学习贡献度相似.在不同数据集和指标下,MISS始终优于其它变体,这表明每个组件对于性能的提升都是有益的,也表明融合潜在结构和语义信息的有效性.
为了探究不同模态的贡献,本文对比使用多模态时和使用单一模态时性能,并将仅使用文本特征的MISS称为MISST,仅使用视觉特征的MISS称为MISSV.使用多模态的MISS与使用单一模态的MISST和MISSV的性能对比如图3所示.由图可看出,使用多模态的MISS在性能上始终优于使用单模态的MISST和MISSV,这表明结合多种模态更有利于推荐性能的提升.此外,文本之间相似的置信度往往高于视觉之间相似的置信度,正如图中观察到的,仅使用文本特征时比仅使用视觉特征时具有更优的推荐性能.
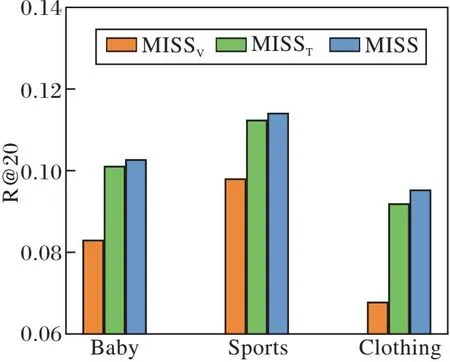
(a)R@20
2.4 超参数敏感度实验
本文中不同模态的权重和为1,为了研究不同视觉权重对模型性能的影响,将视觉权重αv的取值范围设为0至1,并以0.1作为步长,此时文本权重为1-αv.MISS在3个数据集上不同视觉权重αv下的推荐性能对比如图4所示.
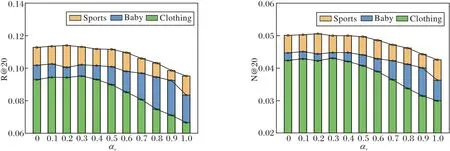
(a)R@20 (b)N@20
从图4可看出,在αv≤0.3时,MISS在数据集上取得最佳性能,之后随着αv取值增大,模型性能呈下降趋势.
此外,本文还研究模型在学习率和对比损失权重上的敏感性,设置学习率
lr=1e-1,1e-2,1e-3,1e-4,
对比学习损失权重系数
λ=0.1,0.2,0.3,0.4,0.5.
在Baby、Sports数据集上,不同学习率和对比损失权重组合下的MISS性能对比如表3和表4所示.由表可发现:MISS对lr的变化更敏感,并且在lr=1e-3时性能最佳;MISS对λ不太敏感,但选取恰当的λ对模型性能仍是有益的.
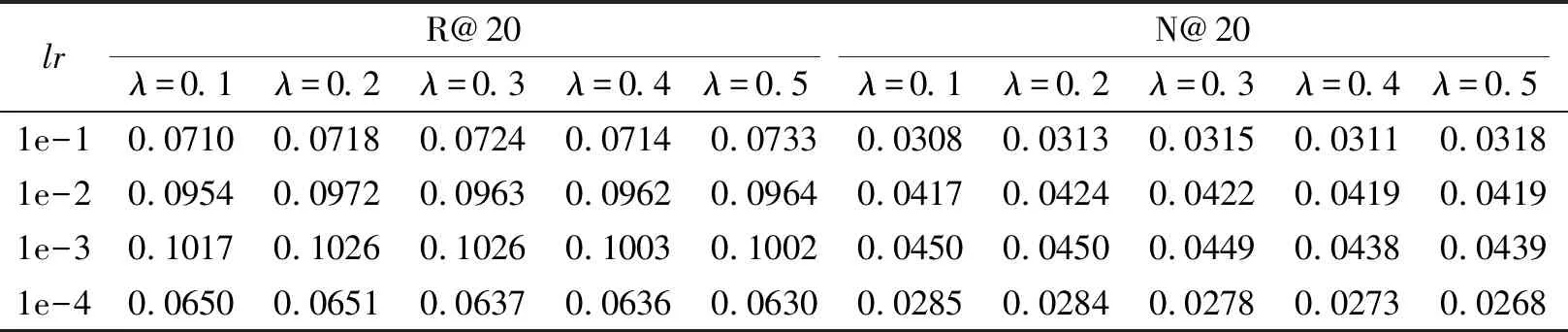
表3 Baby数据集上不同学习率和对比损失权重组合下的MISS性能对比

表4 Sports数据集上不同学习率和对比损失权重组合下的MISS性能对比
2.5 案例分析
为了进一步探究MISS性能提高的原因,本文分别将LightGCN和MISS生成的用户最佳表示和物品最佳表示进行可视化(随机抽样2 000位用户和2 000个物品).
采用单位圆可视化方法[24],首先使用t-SNE(t-Distributed Stochastic Neighbor Embedding)[25]将用户表示和物品表示分别映射为二维空间中的单位向量,再使用高斯核密度估计计算用户特征和物品特征的分布情况,并可视化不同角度的密度.LightGCN和MISS的用户表示和物品表示在单位圆上的分布情况如图5和图6所示.
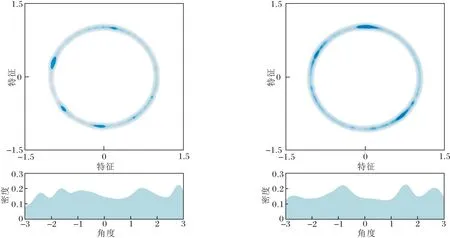
(a)用户特征分布 (b)物品特征分布

(a)用户特征分布 (b)物品特征分布
对比图5和图6可看出,LightGCN学到的表示呈现局部的高度聚集,而MISS学到的特征分布更均匀,可更全面考虑各种用户兴趣和物品特征,提高推荐准确率.同时均匀的用户表示和物品表示分布可促使模型考虑更广泛的用户兴趣和物品特征,从而提高推荐系统的多样性.实验表明融合多模态结构和语义信息对于提高模特推荐性能是有效的.
3 结 束 语
本文提出融合潜在结构与语义信息的多模态推荐方法(MISS),融合多模态特征提供的潜在结构和语义信息,有效增强用户表示和物品表示.MISS通过图卷积方法学习多模态特征的潜在结构和用户-物品二部图结构,使用户表示和物品表示能互补捕捉不同图上的结构信息.设计对比学习,将多模式语义信息与学习结构信息的物品表示进行对齐,确保物品表示能对齐来自多模式特征的原始语义,从而有效实现多模态中潜在结构与语义信息的融合.最后,在3个数据集上进行的广泛实验验证MISS的有效性.此外,MISS组件可方便替换,并且可方便地将其它模态特征引入模型中,具有较强的拓展性.今后将继续探索潜在关联挖掘方法,以及语义信息和潜在结构的融合方法,提高对多模态信息的挖掘能力,增强对推荐场景中模态多样化的适应能力.
