循环神经网络和注意力增强的门控图神经网络会话推荐模型
2024-04-26李伟玥朱志国
李伟玥 朱志国 董 昊 姜 盼 高 明
近几年,电子商务行业的利润现呈现稳步增长的趋势,推荐系统已成为电子商务平台重要的组成部分,在帮助消费者制定购买决策、提高企业营收方面发挥巨大作用[1-2].然而,海量的商品使得信息过载的问题越发严重,因此推荐系统在当今电商平台盛行的背景下,越来越受到平台与企业的重视.
经典的推荐系统往往根据用户的长期历史记录实现个性化推荐,然而,并非在所有情况下用户的长期交互历史都是可获取的.例如:许多小型电商零售平台和新闻门户网站为了降低运营成本,通常仅会记录当前用户在短时间内的浏览历史.此外,也有不少用户经常以未注册、未登录等匿名状态进行访问[3].尽管Cookie技术可临时保存部分用户个人信息,但是此类技术可能存在安全漏洞,存在泄露用户数据的风险.因此,如何根据用户在当前会话中的行为进行精准推荐,成为许多中小型电商平台面临的重要挑战之一.基于会话的推荐旨在根据匿名目标用户在当前会话中的交互记录,学习用户的长短期偏好,为用户提供个性化精准推荐.
基于协同过滤的推荐系统[4]、基于矩阵分解的推荐系统[5]、基于关联规则挖掘的推荐系统[6]大都依赖用户的长期历史交互和用户个人信息,未能明显区分用户在点击序列中表现出的长短期兴趣,因此难以为匿名用户进行精准推荐.马尔科夫链[7]虽然能在一定程度上捕捉用户的动态偏好,但是不具有良好的可扩展性,即随着阶数的提高,计算复杂度也会随之快速增加.
随着深度学习的不断发展,神经网络模型获得越来越强的深层语义特征提取能力,并广泛运用于推荐系统[8].作为会话推荐领域的早期工作之一,Hidasi等[9]提出基于门控循环单元(Gated Recur-rent Unit, GRU)的会话推荐系统,证实循环神经网络(Recurrent Neural Network, RNN)能学习商品间的时序转换关系.此后的大部分学者主要从模型结构[10-12]、数据处理和训练方法[13-14]三方面入手,提出多种基于RNN的会话推荐系统.
随着注意力机制的不断完善,不少学者将注意力机制与RNN结合,或是完全基于注意力机制提出许多会话推荐系统.融合注意力机制的推荐系统可在一定程度上避免将噪声数据引入用户特征提取过程,从而更好地推断用户在当前会话中的主要意图.NARM(Neural Attentive Recommendation Machine)[15]是早期基于GRU使用注意力增强的推荐系统之一,可从较长会话中有效学习用户偏好.STAMP(Short-Term Attention/Memory Priority Model)[16]首次完全基于注意力机制进行会话推荐.相比NARM仅能捕捉用户的一般兴趣,STAMP更重视用户的当前兴趣,因此在处理长会话时性能更强.然而STAMP并未考虑商品间的时序转换关系,限制模型捕捉用户在当前会话中的动态偏好.
近年来,图神经网络(Graph Neural Network, GNN)凭借强大的特征提取能力,在生命科学[17]、情感分析[18]、金融预测[19]、目标识别[20]等领域取得丰富的研究成果,并成为人工智能各应用领域的研究热点之一,不少学者将GNN应用于会话推荐.SR-GNN(Session-Based Recommendation with GNN)[21]开创性地将原始会话序列构造为会话图,再基于GNN进行节点间的消息传递与特征聚合,并从中推断用户意图.GC-SAN(Graph Contextualized Self-Attention Model)[22]使用多个自注意力块增强SR-GNN,在一定程度上去除近邻信息中的噪声.然而,多数相关工作在不同程度上忽略商品间的时序关系.虽然一些工作对此进行一定探索[23-25],但时序信息仍未得到重点关注.
忽略时序特征的会话推荐系统通常会基于用户在当前会话中的所有历史交互行为生成推荐结果,隐含假设认为用户在会话中的长期兴趣非常稳定,并且用户每次交互行为之间相互独立.然而,这种假设过强,脱离现实场景.从用户的角度上看,用户与商品的交互通常是依次发生的,即用户的行为具有一定顺序相关性.从商品的角度上看,商品的流行度会随着时间推移而改变,即商品的特征也具有明显的时序性.从电商平台的角度上看,为了捕捉用户的个性化偏好,平台往往会使用日志记录用户的实时行为,其中包含时间戳信息.因此,时序信息在现实场景下的获取难度较低,应当作为推荐系统重点关注的信息.
然而,大多数基于会话的推荐系统都不同程度上忽略用户交互历史中的时序特征.基于GNN的会话推荐系统在将商品点击序列转换为图的过程中,虽然较好地体现商品间的近邻上下文特征,但是忽略商品间的时序关系.基于RNN的推荐系统虽然能根据用户的点击流数据学习商品的时序特征,但是无法学到商品间的近邻上下文特征.因此,学者们设计不同算法,从用户与商品的当前交互序列中同时学习两种特征,以提升推荐的精确度.部分相关工作采用RNN与GNN堆叠的方式[26],或是受到自然语言处理领域语言模型的启发,基于位置编码学习商品间的时序特征[27-29].然而,基于流式结构的模型会导致先学习到的特征被遗忘,后学习到的特征不够充分,从而限制了模型的推荐性能.例如:在先学习近邻上下文特征,后学习时序特征的会话推荐系统中[28],系统会在学习时序特征的过程中遗忘已学习到的近邻上下文特征.同时,后引入的时序特征难以在接下来的浅层神经网络中得到充分学习,使得系统未能深入挖掘用户点击顺序中表现出的兴趣偏好,导致系统的推荐精准度较低.
此外,仅根据长期行为或短期行为学习用户在当前会话中的兴趣,也会导致推荐准确度降低.一方面,用户在当前会话中的长期兴趣会受到短期兴趣的影响,并随着时间推移而持续变化.如果仅考虑长期兴趣,会导致推荐系统难以捕捉用户活跃的短期兴趣,难以满足用户的即时需求.另一方面,用户在电商场景中的兴趣漂移较严重,如果仅考虑短期兴趣,会导致推荐系统过度依赖用户的当前行为,被噪声交互行为误导.因此,在进行推荐时,需要综合考虑用户的长短期兴趣.
综上所述,本文受到Transformer模型[30]的启发,提出循环神经网络和注意力增强的门控图神经网络会话推荐模型(RNN and Attention Enhanced Gated GNN for Session Based Recommendation, RAGGNN).首先,对匿名目标用户在当前会话中交互的商品进行嵌入式编码,再通过双向长短期记忆网络(Bidi-rectional Long Short-Term Memory, BLSTM)[31]学习商品间的时序依赖关系,以学习用户在当前会话中的短期兴趣.同时,基于门控图神经网络(Gated GNN, GGNN)[32]学习商品间的近邻上下文特征,以学习用户在当前会话中的长期兴趣.考虑到注意力机制可有效缓解会话中噪声交互行为的影响,基于多头自注意力机制过滤商品间的虚假关联关系.最后,基于门控机制,自适应融合商品的时序特征与会话图近邻上下文特征,学习用户在会话中表现的综合兴趣,实现对下一个点击商品的精准预测.在会话推荐领域的电商基准数据集Diginetica、Yoochoose和天猫(Tmall)上的实验表明RAGGNN具有一定的个性化精准推荐能力.
1 循环神经网络和注意力增强的门控图神经网络会话推荐模型
1.1 问题定义
会话推荐旨在根据匿名用户在当前会话中的点击序列,预测用户下一次将要点击的商品.因此,本文的推荐问题可定义如下.定义全局无重复商品集合
V={v1,v2,…,vi,…,v|V|},
匿名用户点击商品的会话集合
S={s1,s2,…,sj,…,s|S|}.
对于任意匿名会话sj,将当前用户已点击的商品按时间顺序排列,有

对于会话序列sj,还可将其建模为有向会话图
Gj=(Vj,εj),

邻接矩阵反映图的结构特征,有助于更好学习各商品节点的特征和捕捉相关关系.
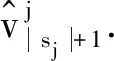
1.2 模型框架
本文提出循环神经网络和注意力增强的门控图神经网络会话推荐模型(RAGGNN),整体框图如图1所示.RAGGNN主要由嵌入编码模块、时序短期特征提取模块、会话图链接长期特征提取模块和特征聚合预测模块构成.
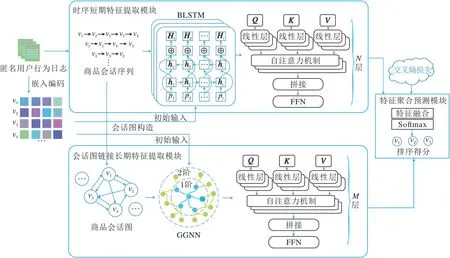
图1 RAGGNN框架图
1.3 嵌入编码模块
嵌入(Embedding)技术可将大规模的稀疏特征投影到相对密集的空间中,有利于模型深入学习商品特征.嵌入编码模块可通过线性变换得到目标商品的嵌入编码向量:

1.4 时序短期特征提取模块
虽然普通RNN难以从较长序列中学习足够的特征,但是LSTM(Long Short-Term Memory)[34]可通过多门控机制捕捉长序列中各商品间的依赖关系.因此,为了更充分学习商品的时序特征,本文在采用LSTM的同时,还引入双向机制,使模型可从正向和反向捕捉商品间的时序关系.在t时刻下,输入门向量
it=σ(Wiixt+Whiht-1+Wcict-1+bi),
遗忘门向量
ft=σ(Wifxt+Whfht-1+Wcfct-1+bf),
LSTM单元状态
ct=ftct-1+ittanh(Wicxt+Whcht-1+bc),
输出门向量
ot=σ(Wioxt+Whoht-1+Wcoct-1+bo),
输出隐状态向量
ht=ottanh(ct).
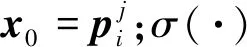
由于单层BLSTM对时序信息的学习能力有限,因此可采用堆叠BLSTM的方式进行时序特征提取,同时使用线性投影将特征维度转换为嵌入编码维度.第m层BLSTM的输出状态矩阵为:
H(m)=WBL(BLSTM(H(m-1)))+bBL.
其中:H(m-1)为第m层BLSTM的输入矩阵,且有
WBL∈R2d×d为可学习的参数矩阵,bBL∈Rd为偏置向量.
对于目标匿名会话sj,可将该部分最终输出记为
由于用户可能受到外界影响的干扰,或无意识地进行误操作,因此交互记录中存在一些噪声信息.如果将噪声信息视为正常的用户交互行为,会导致模型难以学习用户的真正兴趣偏好.受Transformer模型[30]的启发,本文引入堆叠的多头自注意力块,自动调整会话中不同商品间的关联权重,降低噪声信息对模型学习的影响,提升推荐精确度.
自注意力块由多头自注意力层、前馈神经网络(Feed Forward Network, FFN)和残差连接组成,而多头机制使模型可从多个特征子空间分别学习特征,有利于稳固自注意力机制的学习结果,则
其中:

多头机制输出矩阵为:
E=[ATT1‖ATT2‖…‖ATTk]WE,
其中,k为多头数量,WE∈Rd×d为对应可学习权重参数矩阵.
由于多头自注意力机制仅采用线性投影算法进行计算,因此本文使用两层FFN增强模型的非线性拟合能力.经典的线性修正单元(Rectified Linear Unit, ReLU)激活函数仅根据输入值的正负进行简单门控,当输入值为负时会导致输出为0,从而使神经元难以通过反向传播更新相应参数,即发生神经元坏死问题,所以本文采用高斯偏误线性单元(Gaussian Error Linear Unit, GELU)函数进行非线性变换.同时,考虑到仅使用自注意力机制可能会丢失商品的原始特征,本文还设置残差连接:
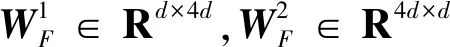
为了简洁起见,将上述多头注意力机制记为
F=SAN(E).
同样,为了增强模型对商品间复杂高阶特征的学习能力,可对其进行堆叠:
F(n)=SAN(F(n-1)),
其中n为当前多头自注意力块堆叠层数,且有
F(0)=SAN(E).
对于目标匿名会话sj,最终输出为:
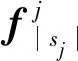
1.5 会话图链接长期特征提取模块
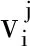
其中,

当前时刻输出状态隐向量
当前时刻候选状态隐向量
更新门向量
用于控制上一时刻状态信息影响当前状态的程度,重置门向量
用于控制上一时刻状态信息影响当前候选状态的程度.其中:Wz,1∈Rd×d,Wz,2∈Rd×d,Wr,1∈Rd×d,Wr,2∈Rd×d,W1∈Rd×d,W2∈Rd×d为可学习参数矩阵,b∈Rd为偏置向量,tanh(·)为双曲正切激活函数.
同理,由于单层GGNN对会话图链接特征的学习能力有限,因此本文也采用堆叠GGNN的方式进行会话图近邻特征提取.第N1层GGNN的输出状态矩阵:
G(e)=GGNN(a(e)),
其中,a(e)为第n层GGNN的输入矩阵,且有
对于目标匿名会话sj,该层最终输出
接下来,同样基于堆叠的多头自注意力机制进行去噪和特征提取,对于目标匿名会话sj,输出结果
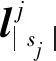
1.6 特征聚合预测模块
为了聚合模型学习的商品间时序特征和近邻上下文特征,采用自适应的门控聚合算法.当前会话sj中用户对商品vi表现出的综合兴趣偏好为:
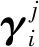
接下来,通过Softmax函数对推荐得分进行归一化处理,得到候选商品vi在会话sj中下一时刻的预测点击概率:
最后,取概率最大的K个商品完成推荐.本文通过最小化如下交叉熵损失函数训练模型:
Loss=
其中,λ为正则项系数,θ={Wembedding}为待正则化的参数集合.
2 实验及结果分析
本文主要基于Pytorch和RecBole[36],在配置英特尔12代i7中央处理器(内存32 GB)和GeForce RTX 3070Ti显卡的计算机上进行实验.
2.1 实验设置
为了保证实验的公平性,选择会话推荐领域的基准公开电商数据集Diginetica、Yoochoose和天猫(Tmall).Diginetica数据集来源于2016年CIKM挑战赛,包含匿名会话商品点击流数据和商品属性数据,实验中仅使用商品点击流数据.Yoochoose数据集来源于2015年RecSys挑战赛,包含商品点击流数据和商品购买记录数据,实验中仅使用商品点击流数据.由于Yoochoose数据集较大,并且过多的数据对模型性能的提升帮助较小[13],因此本文仿照相关工作[37-40],根据时间戳记录截取最近1/64的数据进行实验.Tmall数据集来源于2015年IJCAI挑战赛,包含大量天猫电商平台上的匿名用户购物日志记录.同样地,由于Tmall数据集中的商品数量过多,仿照相关工作[41],根据时间戳记录截取最近1/64的数据进行实验.实验选用数据集的统计指标如表1所示.
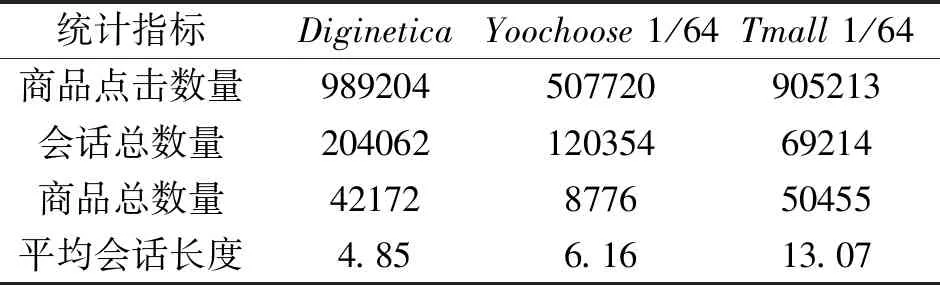
表1 实验数据集部分统计指标
参考相关工作的实验部分[37-40],本文在预处理时过滤2个数据集中出现次数小于5的商品,并过滤仅包含1个商品的会话.对于Diginetica、Yoochoose数据集,先以时间顺序对各会话进行排列,然后按照80%、10%和10%的比例依次划分训练集、验证集和测试集.此外,为了验证RAGGNN能有效缓解推荐的冷启动问题,对于Tmall数据集,先以时间顺序对各会话进行排列,然后按照60%、20%、20%的比例依次划分训练集、验证集和测试集.受相关工作中数据增强技术的启发[13],采用序列增强的方式扩充训练集,增强模型的学习能力.举例来说,对于会话可依次生成一系列子会话及其对应的目标预测商品:
参考会话推荐的相关工作[21,42-43],本文将嵌入编码维度设置为100,使用Adam优化器[44],学习率设定为0.001,最大会话长度设定为20.此外,在{1,2,3}中搜寻最佳堆叠层数,在{1,2,4}中搜寻最佳注意力头数,在
{0.005,0.000 5,0.000 05,0.000 005}
中搜寻最佳正则项系数.
为了探索模型参数量对于推荐性能的影响,在{128,256,512}中对嵌入编码维度进行实验.为了缓解模型训练过程中的过拟合问题,使用神经元失活率为20%的暂退法(Dropout)和提前停止策略(Early Stop):当平均倒数排序(Mean Reciprocal Rank, MRR),即MRR@20在连续五轮训练中没有提升的情况下提前停止训练.
为了保证实验的公平性,参照各基线模型的实验结果设置相应的最佳参数.
实验选取精准度(Precision)、命中率(Hit Rate, HR)、MRR和归一化折损累计增益(Normalized Discounted Cumulative Gain, NDCG)这4个指标评估模型性能.
Precision指标表示预测为用户感兴趣的商品中,有多少是用户真正感兴趣的商品,公式如下:
其中,M表示测试集中的商品数量,hit_num(i)表示正确为用户i推荐的商品数量,rec(i)表示向用户i推荐的商品总数量.
HR指标表示在推荐列表中的商品包含多少用户感兴趣的商品,公式如下:
其中,hit(i)表示是否成功为用户推荐符合个性化兴趣的商品,若为用户进行准确的推荐,hit(i)=1,否则hit(i)=0.
考虑到用户可能对推荐列表的前几个商品更感兴趣,因此,引入MRR和NDCG.MRR指标反映目标用户感兴趣的商品是否排在更靠前的位置,公式如下:
其中,N表示测试集上的商品数量,rank(i)表示商品i在Top-K推荐列表中的位次.
NDCG指标也是考虑推荐列表中的商品排序是否更符合用户偏好,公式如下:
其中,rel(i)表示第i个位次上的推荐商品是否出现在候选商品集合中,若是,rel(i)=1,否则,rel(i)=0.
4个性能评估指标均在[0,1]上取值,数值越大,表示推荐系统的推荐精准度越高.考虑到大多数情况下,用户仅会浏览首页的推荐结果,因此参照相关工作[15,16,21,42-43,45],设置K=20.
2.2 基准模型对比实验
受到会话推荐领域相关工作的启发,选择14种基准模型进行性能对比.按照基准模型使用的核心算法,可划分为如下3类.
1)传统机器学习算法.
(1)基于商品流行度的启发式算法(本文简记为POP).向用户推荐流行度最高的商品,简单易行,广泛应用于实际业务场景,并在某些场景下具有一定竞争力.
(2)文献[46]模型.向用户推荐与当前点击商品最相似的K个商品,使用余弦相似度进行度量.
2)基于RNN或注意力机制的模型.
(1)文献[9]模型.基于GRU进行会话推荐的模型,采用基于排序的损失函数.
(2)NARM[15].分别基于GRU和加性注意力机制捕捉商品间的全局特征与局部特征,拼接后通过双线性相似度函数推断用户偏好.
(3)STAMP[16].完全基于注意力的会话推荐模型,通过加性注意力机制学习各商品特征.
(4)CL4SRec(Contrastive Learning for Sequential Recommendation)[47].使用多种数据增强技术构建自监督信号,设计基于对比学习的多任务学习框架进行序列推荐.
(5)DuoRec[48].采用对比正则化技术,缓解序列推荐系统中的商品嵌入编码退化问题.
(6)CORE(Consistent Representation Space)[49].基于独特的编码器和具有鲁棒性的距离测度方法,将会话与商品嵌入表征统一到相同特征隐空间中.
3)基于图神经网络机制.
(1)SR-GNN[21].先将原始会话序列转换为会话图,再通过GGNN根据商品节点的出度和入度矩阵学习商品特征.
(2)GC-SAN[22].先基于GGNN捕捉商品间的局部近邻关系,再基于自注意力块捕捉商品间的全局依赖关系.
(3)TAGNN(Target Attentive GNN)[42].自适应激活不同用户对不同目标商品的兴趣.
(4)LESSR(Lossless Edge-Order Preserving Aggre-gation and Shortcut Graph Attention for Session-Based Recommendation )[45].保留时序信息的会话图,结合快捷图注意力网络学习商品特征.
(5)NISER(Normalized Item and Session Representations Model)[50].对商品编码进行正则化,提升模型的长尾推荐能力,还基于位置编码学习商品的时序特征.
(6)SGNN-HN(Star GNN with Highway Net-works)[51].提出星型会话图,设计高效读出函数,应对图神经网络的过拟合问题,还考虑商品的位置编码.
SR-GNN、GC-SAN和TAGNN忽略商品的时序特征,NISER和SGNN-HN采用简单的位置编码学习商品的时序特征,LESSR基于保留时序信息的会话图学习商品的时序特征.
各模型对比实验结果如表2所示,表中黑体数字表示最优值,斜体数字表示次优值.由表可见,基于传统机器学习的POP和文献[46]模型性能较差,这是因为两种模型仅根据商品流行度和商品间的相似度为用户生成推荐结果,未考虑商品间深层、复杂的关联关系.
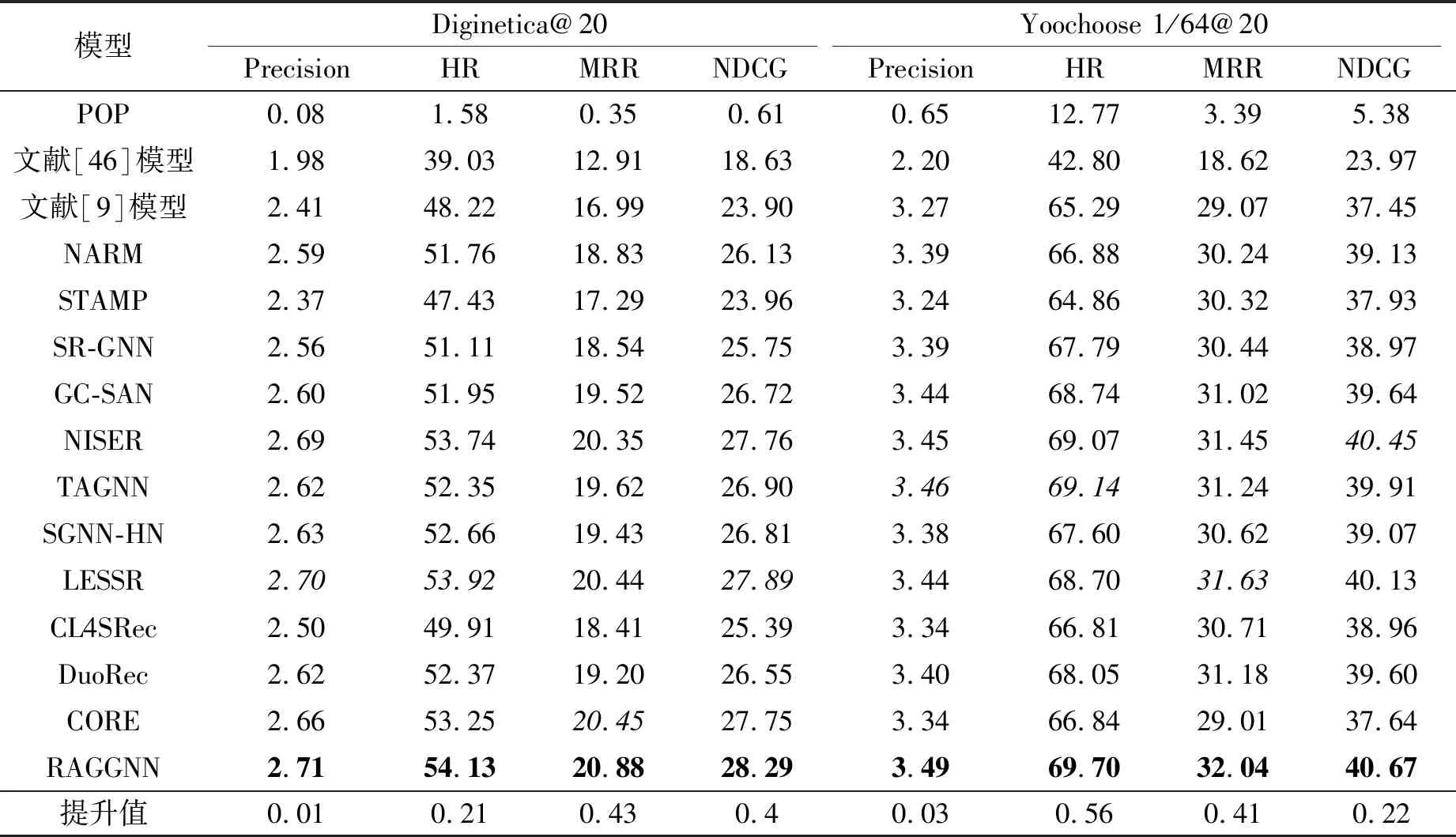
表2 各模型在3个数据集上的对比实验结果
所有基于神经网络模型的性能都超越传统机器学习算法,从而验证深度学习技术在会话推荐中的有效性.文献[9]模型通过学习商品间的时序关联关系,相比传统机器学习算法,性能有大幅提升.NARM进一步采用加性注意力机制,有效过滤会话中存在的噪声信息,获得更高的推荐精准度.CORE统一编码和解码特征表示空间的策略,增强模型对商品特征的学习能力.CL4SRec采用掩码、裁剪、重排等多种数据增强方法扩充训练数据,并通过捕捉会话级的对比信号实现精准推荐.DuoRec基于对比正则化策略,更好地保留会话中的语义特征,实现对商品特征表征分布的优化.
GNN的优势在于突破序列数据结构的局限,并且因为在模型训练时需要按照批次进行处理,所以同个批次中的会话序列通常会被构建为一个局部会话图,使模型在推荐时可从邻域范围中学习来自其它会话或是当前会话中商品间的非时序近邻上下文关系.因此,在大多数情况下,SR-GNN和GC-SAN性能高于基于RNN或注意力机制的模型,这得益于自适应地激活用户对不同商品的独特兴趣,TAGNN进一步获得更强的精准推荐能力.
然而,SR-GNN、GC-SAN和TAGNN都忽略商品间的时序信息,推荐精准度还存在较大的提升空间.NISER、SGNN-HN和LESSR通过多种策略挖掘隐藏在商品时序转换间的用户兴趣,具备较强的竞争力.
从噪声过滤的角度上分析,由于用户的误操作或一些特殊的行为习惯,历史行为记录中往往存在噪声信息.噪声信息会误导模型学习到虚假的用户兴趣,导致推荐精确度的降低.注意力机制可使模型更关注对推荐结果有重要影响的部分,从而减少对噪声敏感的用户行为产生的负面影响.通过动态调整注意力权重,模型可更聚焦于反映用户兴趣偏好的商品交互行为,同时减少对噪声记录的过度关注.对比文献[9]模型、NARM、SR-GNN和GC-SAN的结果,无论是加性注意力还是自注意力机制,都能有效过滤用户行为记录中的噪声.然而,加性注意力作为一种浅层模型,仅能过滤部分噪声信息.自注意力机制可帮助模型进行全局的特征交互,更好地理解不同特征之间的关系.同时,自注意力机制可结合残差连接、暂退法等策略进行堆叠,进一步提升去噪能力,增强模型的鲁棒性.此外,无论是商品间的时序特征关联关系,还是近邻上下文特征关联关系,都充斥大量噪声.受此启发, RAGGNN引入自注意力机制,并且双侧的自注意力提供更强的噪声过滤能力,使学习的用户兴趣更具有表现力.
然而,完全基于注意力机制的STAMP将会话视为不具有顺序关系的交互集合,难以充分学习商品间的时序关联关系和上下文关联关系,导致推荐精准度甚至低于文献[9]模型和SR-GNN.
总之,RAGGNN基于集成学习思想,分别基于RNN和GNN捕捉商品间的时序关系与近邻上下文特征,充分考虑商品间不同的关联关系中隐藏的不同用户兴趣,因此获得强大的精准推荐能力.
2.3 冷启动实验
冷启动问题为推荐系统在实际业务场景中的应用带来重大挑战.因此,本节基于Tmall数据集进行实验,并使用更少的训练集模拟冷启动场景,探索各对比模型的推荐精准度变化.在基准模型的选取上,基于对比实验结果,选择3个具有竞争力的模型:LESSR、CL4SRec和DuoRec.
各模型冷启动实验结果如表3所示,表中黑体数字表示最优值,斜体数字表示次优值.由表可见,RAGGNN获得具有竞争力的结果,相比其它基准模型,在4个度量指标上均获得较大提升.这是因为RAGGNN在学习用户的个性化兴趣时,既考虑动态多变的时序短期兴趣,也考虑稳定多元的近邻上下文长期兴趣.LESSR虽然也考虑两种用户兴趣,但是采用迭代优化的方式会造成不同类型兴趣的纠缠,导致模型难以学习到真正的综合兴趣.CL4SRec和DuoRec均采用对比学习的方式,从会话序列中捕捉用户兴趣,这会导致模型过度依赖行为顺序信息,从而被商品间的虚假依赖关系误导,导致推荐结果的准确度较低.

表3 各模型冷启动实验结果对比
从数据集的特征上分析,相比其它两个国外电商数据集,Tmall数据集虽然用户数量最少,但是具有更长的平均会话长度.这说明中国在线用户更活跃,能为平台提供更多的用户反馈信息,使推荐系统更容易推断用户的兴趣偏好.此外,可观测到Tmall数据集具有最多的商品数量,在为用户提供广泛选择范围的同时,也为精准推荐带来更大挑战.出于用户隐私政策的限制,所有的信息均以匿名化形式呈现,无法获得较多的用户侧信息.因此,在会话推荐场景下,对推荐系统的学习能力提出更高的要求.
总之,冷启动实验结果表明RAGGNN具有较好的鲁棒性.即使在用户历史记录较少时,仍能学习具有表现力的兴趣特征,并将挖掘的知识运用于推断未出现在训练集上的用户兴趣,具有较好的泛化能力.
2.4 消融实验
为了验证RAGGNN各模块的有效性,进行如下两组对照实验,第1组实验可检验时序信息和注意力机制去噪的有效性,第2组实验可检验门控聚合机制的有效性.
由于SR-GNN和GC-SAN已分别证实自注意力机制可增强GGNN的有效性,因此对于第1组消融实验,设置如下两种变体.
1)RAGGNN-RNN:移除RNN后的自注意力层.
2)RAGGNN-noise:移除GNN和RNN之后的自注意力层.
第1组消融实验结果如图2(a)所示,在该组实验中,仅对各变体模型结构进行相应调整,并使用与RAGGNN一致的参数.
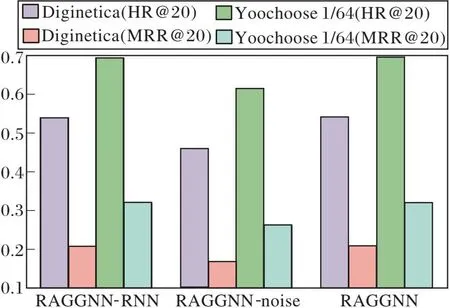
(a)第1组
结合基准模型对比实验结果和本组消融实验结果可发现,RAGGNN性能表现最佳.正如2.3节中分析,SR-GNN和GC-SAN的对比体现注意力机制对GNN学习结果的明显提升作用.同时还观察到,RAGGNN-RNN的性能优于GC-SAN,这说明在会话推荐中,商品间的时序关系也是重要的信息源之一,仅考虑商品间的会话图近邻信息难以精确捕捉用户兴趣.
此外,对比RAGGNN-noise和RAGGNN的结果可发现,当RAGGNN使用去除RNN和GNN后的注意力机制时,模型性能下滑较严重,这表明会话中存在的噪声信息会使模型错误学习商品间的虚假关联关系,导致推荐的精准度较低.
综上所述,在进行会话推荐时不仅需要考虑到多种特征,还有必要对其进行噪声过滤,才能精准学习真实的用户兴趣.
为了研究不同聚合模型对模型性能的影响,在第2组消融实验中,提出如下两种变体.
1)RAGGNN-avg:采用均值算法融合商品间的时序特征和会话图近邻特征.
2)RAGGNN-FFN:采用单层前馈神经网络融合商品间的时序特征和会话图近邻特征.
第2组消融实验结果如图2(b)所示,在该组实验中,未改动模型的框架结构和参数配置,仅采用不同的特征聚合方式.
由图2(b)可见,使用均值聚合算法的RAGGNN-avg性能最优,其次是使用门控机制的RAGGNN,表明简单的融合算法已足够学习用户在会话中表现出的综合兴趣.由于已进行充分的噪声过滤,再增加模型深度会导致严重的过拟合问题,因此RAGGNN-FFN的推荐精确度较低.RAGGNN之所以未采用均值聚合算法融合模型学习的去噪时序特征和近邻上下文特征,是考虑到简单均值的泛化能力可能较弱,很可能在不同的数据集上性能波动较大,此时很可能会仿照GC-SAN的实验部分,引入额外的权重参数进行调整.而门控机制的聚合权重完全由模型根据当前数据自主学习得到,具有较强的自适应能力,同时避免引入更多的超参数.此外,门控机制可增强推荐结果的可解释性,帮助判断用户在会话中的兴趣受到何种特征的影响较大.
2.5 超参数分析
本节分别探索RNN和GNN的堆叠层数、RNN侧和GNN侧自注意力机制的堆叠层数和头数、正则项系数和嵌入编码维度对推荐精准度的影响,具体实验结果如表4所示.

表4 超参数对模型性能的影响
在RNN和GNN的堆叠层数实验中可发现,随着堆叠层数的增加,HR@20和MRR@20指标出现小范围波动,意味着较多层数的RNN和GNN不一定有助于提升模型性能,反而可能会带来更严重的过拟合问题.在实验中还观察到,堆叠RNN虽然可能会提升模型的推荐准确度,如在Yoochoose数据集上堆叠两层RNN会带来更高的推荐精准度,但是待训练参数量也会随之快速增加.因此,如何权衡计算复杂度和推荐性能之间的关系,仍值得进一步研究.
在注意力机制的头数实验中可发现,适当增加注意力机制的头数有助于提升模型性能,但是头数并非越多越好.例如:在Diginetica数据集上的实验中,相比未使用多头机制(头数为1),头数为2的多头注意力机制可在一定程度上提升模型性能.但是,当头数增至4时,模型性能并没有随之继续提升.根据多头机制的原理,不同的注意力头可从不同的特征子空间学习商品间潜在的隐性关系,因此适当增加注意力头数时,性能会有所提升.但是模型在学习的过程中可能会出现偏差,而过多的注意力头可能会导致偏误量增加,并在接下来的聚合过程中积累更多的偏误,导致模型性能降低.
在注意力机制的堆叠层数实验中,在2个数据集上均可观察到如下现象.综合来看,一层多头注意力机制的性能最佳,堆叠三层的性能次之,堆叠两层的性能相对较差.经分析,这可能是由于模型在相对浅层的结构下即可拥有较强的特征学习能力,过深的结构会带来更严重的过拟合问题,导致推荐精准度的降低.
在正则项系数的实验中,当正则化系数从0.000 005提至0.00 005时,推荐精确度有所提升.然而,随着正则化系数的进一步增加,推荐的精确度有所降低.恰当的正则项系数可有效缓解过拟合问题,提升模型的鲁棒性.然而,过大的正则项系数会导致模型在学习过程中忽略一些重要的特征,无法充分从行为记录中学习稳定的兴趣偏好表示,限制模型的泛化能力.因此,有必要根据用户行为记录数据分布的特点,调整正则项系数.
在嵌入编码维度的实验中,当维度从64提升到100时,推荐精确度有所提高.然而,当维度继续增加时,推荐精确度反而持续降低.上述结果表明,在一定范围内,增加嵌入编码维度有助于提升模型的表征学习能力.对于本文而言,适当增加嵌入维度可使模型从更多方面学习用户兴趣,提升推荐精准度.然而,过多的嵌入维度不仅会带来更大的计算开销,显著提升模型的复杂度,还会带来严重的过拟合问题,限制模型对用户兴趣的学习能力.因此,需要找到合适的嵌入编码维度,权衡推荐精确度和模型复杂度.
总之,RAGGNN具有较强的稳健性,性能不会因为部分参数的改动而产生较大波动.
2.6 实例分析
为了更直观了解商品间的时序特征和会话图近邻特征,本文随机选取数据集上5个匿名会话,根据不同模型的学习结果进行点击率预测,并进行热力图可视化展示,具体如图3所示.图中每个方格表示当前所属会话中的一个商品,颜色越深的方格表示该商品在会话中的目标特征越显著,方格下面的坐标表示对应商品在相应会话中的ID,越左侧的方格表示越早被用户点击的商品.对图中使用的模型说明如下.

(a)会话ID:17427 (b)会话ID:104669 (c)会话ID:63336
1)未过滤噪声的时序特征:仅基于BLSTM的学习结果进行点击率预测,即仅根据未过滤噪声的时序特征进行推荐.
2)未过滤噪声的上下文近邻特征:仅基于GG-NN的学习结果进行点击率预测,即仅根据未过滤噪声的会话图近邻特征进行推荐.
3)过滤噪声后的时序特征:基于BLSTM和对应自注意力块进行点击率预测,即根据过滤噪声后的时序特征进行推荐.
4)过滤噪声后的上下文近邻特征:基于GGNN和对应自注意力块进行点击率预测,即根据过滤噪声后的会话图近邻特征进行推荐.
5)过滤噪声后的融合特征:基于RAGGNN进行点击率预测,即根据过滤噪声后的融合特征进行推荐.
结合图3的可视化结果分析后,可得到如下结论.
1)注意力机制可有效去除数据中的噪声,提高模型的特征学习能力.
对比各会话中过滤噪声前后的推荐结果可知,推荐系统学习的用户兴趣发生明显变化.例如,对于时序特征:在图3(a)中,推荐系统认为用户会对商品15602感兴趣;而在过滤噪声后,推荐系统认为商品15600比商品15602更能吸引用户的注意力.
从近邻上下文特征角度也可观察到相似现象.例如:在图3(e)中,近邻上下文特征分布的峰值出现在会话中后期,然而在过滤噪声之后,(e)中会话106714的可视化结果显示,近邻上下文特征主要分布区域偏移至会话中前期.
类似的现象表明,无论是原始的时序特征还是近邻上下文特征,都存在不同程度的噪声,这些无关信息可能会使模型难以学习真实的用户兴趣.尤其是在去噪前后具有较大幅度变化的会话,变动幅度越大,说明会话中的噪声信息越多.因此,在实际业务场景下设计会话推荐系统时,应当重点关注去噪算法,提高推荐结果的精准度.
2)在大多数情况下,相比会话中部和头部商品,会话尾部商品的时序特征更重要.
除了会话17427之外,最后一两个方格的颜色都较深,这说明相应会话的最后一两个商品表示的时序特征较明显,尤其在过滤噪声后,携带重要时序特征的商品发生明显后移.
类似现象表明简单地将当前会话中用户交互的最后一个商品视为用户的短期兴趣在一定程度上是合理的.从普通序列推荐与会话推荐差异的角度上看,目标用户过于久远的商品交互历史对于精准推荐的效用可能较低,在电商推荐的场景下尤为明显.相关平台企业应当更关注用户的当前兴趣,并适当考虑短期内用户浏览过的商品.
3)具有明显近邻上下文特征的商品具有多变性.
首先,近邻上下文特征更明显的商品不一定固定出现在会话的某个部分.例如:在图3(b)的会话104669中,颜色较深的方格出现在会话前期,这说明用户在会话刚开始时,就发现很感兴趣的商品,并且用户对相关商品的兴趣保持较长时间;在(c)的会话63336中,颜色较深的方格出现在会话中后期,这表明用户在经历一段时间的浏览后,发现很感兴趣的商品,但用户对相关商品的兴趣衰减较快;在(e)的会话106714中,颜色较深的方格分别出现在会话的前中期和末期,这表明用户在经历一段时间的浏览后,找到感兴趣的商品,但是该商品并未表现足够的吸引力,于是用户对此类商品的兴趣发生快速衰减,又经过一段时间的浏览之后,用户对其它商品产生兴趣.
其次,具有吸引力的商品很可能会连续出现.例如:在图3(b)的会话104669中,用户很可能在浏览完商品16071后发现非常感兴趣的商品16064,并在此之后查看与此前商品弱相关的商品15928.
从商品相关性的角度分析,在捕捉到用户兴趣时为其推荐与当前商品高相似度的商品在一定程度上是合理的,因为用户可能在浏览惯性的作用下持续点击此类商品.这从一定程度上解释文献[46]模型虽然基于朴素的相似度度量和聚类算法,但具有相当强的竞争力的原因.
同时也应当注意到,电商平台不能仅推荐与用户当前交互商品高度相似的商品,否则可能会引起用户对此类商品兴趣的快速衰减.例如:在图3(e)的匿名会话106714中,用户可能在连续点击较相似的3个商品后,出现审美疲劳,并转而浏览其它商品.
4)时序特征与近邻上下文特征是不同角度下的特征,需要注意辨识.
从特征区分的可视化结果上看,时序特征与近邻上下文特征显然是两种不同角度下的特征,该现象在图3(a)、(b)、(e)中表现得尤为明显.因此,在设计会话推荐系统时,应当对不同特征加以区分,而不能简单地一概而论.
从特征融合的可视化结果上看,RAGGNN可自动调整时序特征和近邻上下文特征的权重占比,有效实现不同角度下特征间的自适应融合.例如:在图3(a)的会话17427中,商品15600表现更强的近邻上下文特征,而商品15602则表现更强的时序特征.然而,RAGGNN认为商品15600确实表现更强的近邻上下文特征,但是商品15602并不具有很强的时序特征.
类似的现象可以说明,RAGGNN可精准识别不同商品在会话序列中表现的不同特征,并据此推断用户真正的兴趣偏好,推荐更具有吸引力的商品.
3 结 束 语
本文在电商场景下,提出循环神经网络和注意力增强的门控图神经网络会话推荐模型(RAGG-NN).考虑融合会话中商品间的时序特征和会话间的会话图近邻特征,基于集成学习的思想,分别基于BLSTM和GGNN学习商品间时序与近邻上下文特征,并通过门控机制实现不同特征的自适应聚合.这样使模型能全面推断用户的长短期偏好,进而为用户生成更精准的推荐结果.本文实验在一定程度上说明捕捉商品间两种特征的重要性和必要性,同时验证RAGGNN的优越性.
然而,本文还存在以下局限之处:1)由于在会话推荐问题下,难以有效利用用户的个人信息,当匿名用户无任何交互历史时,可能无法生成较精准的推荐结果.因此,对于用户冷启动问题,RAGGNN还有改进空间.一种可能的解决方式是先基于商品流行度为匿名用户推荐热门商品,同时根据用户初始的几次交互推断用户偏好,再使用基于深度学习的推荐系统进行后续推荐.2)本文模型仅从用户-商品交互中学习包含丰富时序信息和会话图近邻信息的商品特征向量,并未从商品本身的角度出发,没有根据商品的价格、分类、流行度等属性进行深入研究.今后将尝试解决上述问题,进一步完善模型.
