复杂光照条件下基于光流的水运航道流速检测算法
2024-04-23杜田田王晓龙何劲
杜田田,王晓龙,何劲
(1.上海交通大学电子信息与电气工程学院,上海 200240;2.上海华讯网络系统有限公司行业数智事业部,上海 200127)
0 引言
我国地域辽阔,河流众多,但水情不稳定,洪水、断流等极端情况频发,因此能够及时准确地获取河流流速、流量变化等水文信息对智慧水运交通、灾害防治等至关重要。利用螺旋桨测速仪、声学多普勒流速剖面仪(ADCP)[1]等仪器进行实地测量的传统测速方法虽然发展成熟并被广泛使用,但其易受天气、地形、水流条件等因素的制约,且存在需人工涉水、成本高昂、检测范围窄、不能大规模部署等问题,已不能满足我国智慧水运交通发展的要求。
为了应对上述挑战,完成远程监测任务,近年来基于视频图像的河流表面流速(RSV)测量方法被提出,并因其安全性强、测量效率高等优点得到人们的广泛关注。该方法的基本流程如下:首先在河岸一侧架设摄像机获取河流水面视频图像,然后利用图像测速法估算出水流流速的像素级的二维速度场,再通过仿射变换将其转化为真实流速。图像测速法按运动矢量估计方法的不同可分为粒子图像测速法(PIV)、粒子跟踪测速法(PTV)、时空图像测速法(STIV)和光流估计测速法(OFV)。其中,PIV和PTV对示踪物密度和光照变化等很敏感[2-3],不适合应用在有光影或反射的河道场景中,基于STIV[4]的测速方法受限于只能测得部分流场信息,在手动设置测速线的情况下只能获得测速线上的流速分量,无法进一步估算出河流流量。相比之下,OFV方法对示踪物的要求较低[5],并且能够产生像素级流场。在过去的十年中,许多OFV传统方法,如OTV[6]、KLT-IV[7]等已被证明性能优于PIV和STIV。
尽管这些传统的光流方法已经获得了令人满意的结果,但因假设条件的限制,其在有光影干扰或大位移场景中的测量精度较低。近年来,随着深度学习的迅猛发展,许多学者开始尝试利用深度卷积神经网络(DCNN)对传统的图像测速法进行改进。文献[8]采用FlowNet光流估计网络模型处理近距离非接触式水面图像,实验结果表明,与传统的光流测量方法相比,结合DCNN的测速技术具有简单高效、准确度高的特点。文献[9]利用多特征融合的DCNN实现了河流流速分类,并通过引入生成式对抗网络生成河流图像,增强了算法在小差异河流图像上的鲁棒性。
本文提出一种改进的OFV方法,该方法适用于存在光影和反射等复杂光照的河道场景。本文方法基于光流估计中具有较高精度和较强跨数据集泛化性能的循环全对场变换(RAFT)模型[10],通过引入卷积块注意力模块(CBAM)机制,优化其损失函数,降低在复杂光照条件下的误检率。
1 光流估计方法
1.1 传统光流估计方法
传统光流法的提出基于以下3个基本假设:1)亮度恒定,即相邻帧亮度或颜色恒定不变;2)时间连续,即连续的“小运动”;3)空间一致,即相邻像素点间运动一致。根据上述假设,传统的光流估计方法基本方程如式(1)所示:
I(x+dx,y+dy,t+dt)=
I(x,y,t)+Ixdx+Iydy+Itdt
(1)

基于亮度恒定假设,对式(1)按照泰勒公式展开可以获得:
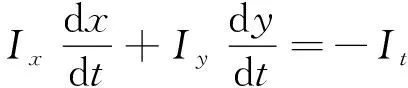
(2)
时间连续假设增加了运动物体内部为平滑光流场的约束,通过光流场梯度计算全局平滑度然后不断迭代,当平滑度达到最高时,可视为估算出真实光流场。然而,在很多实际场景中,这些假设是不成立的。具体而言,当光照剧烈变化或相邻帧之间物体发生巨大位移时,传统的光流估计方法就会表现出较差的检测精度,但在河道场景中,倒影、阳光反射等现象是不可避免的。因此,传统的光流估计方法在RSV检测任务中适用场景比较受限。
1.2 基于深度学习的光流估计方法
近年来,深度学习在计算机视觉领域广泛应用,取得了显著效果[11]。为解决传统光流估计方法存在的问题,文献[12]设计了基于深度学习的光流估计(DLOF)架构,并提出FlowNetS和FlowNetC两种编码器-解码器结构的网络模型,其中,FlowNetS是一种相对简单的光流网络,首先对输入的相邻两帧图像使用卷积神经网络下采样获取图像的特征,然后通过反卷积方法获得逐像素的光流结果,另一种相关性光流网络FlowNetC,受传统方法中加入匹配项的启发,首先计算两帧图像的相关性,再通过特征空间求解光流。文献[13]提出了基于空间金字塔的光流模型Spatial Pyramid Network(SpyNet),与FlowNet 1.0相比,SpyNet的参数量减少了96%,但其精度较差,且每一层网络都需要单独训练。德国弗莱堡大学团队在2017年提出了FlowNet 2.0[14],相较于FlowNet 1.0,其精度得到了大幅提高,但该架构是通过堆叠子网络来获得的,因而模型的训练参数量巨大,难以训练。2018年,学者们在SpyNet的基础上,提出了两种具有代表性的金字塔结构光流网络PWCNet[15]和LiteFlowNet[16],其采用特征扭曲操作,而非在不同尺度下进行图像扭曲,同时使用了成本体积层计算金字塔各层的匹配代价,进一步处理大位移并降低了模型参数量,在不同的光流数据集上都取得了较好的效果。文献[17]考虑到算法空间复杂度太高,降采样又会导致精度受限的问题,引入高效的体积网络来进行密集的二维对应匹配,极大地减少了空间的占用量。
2020年,文献[11]针对之前的DLOF模型过多依赖于训练数据、泛化性能不强的问题,提出了RAFT网络模型。该模型的独特之处在于:使用改进的门控循环单元(GRU)迭代更新预测光流,在运行时间、训练速度和模型大小等方面都表现出色,达到了最佳估计性能,吸引了许多研究人员对其进行改进和增强[18]。
2 改进的RAFT光流网络
考虑到DLOF模型在许多基准测试中都优于传统模型,并且端点误差(EPE)更小,本文采用RAFT光流估计为基准网络架构。
改进的RAFT光流网络模型如图1所示(彩色效果见《计算机工程》官网HTML版,下同),其中改进部分即引入的CBAM注意力模块,使用虚线框做了标注。RAFT模型主要分为3个部分:首先是像素级特征向量的运动特征提取部分;其次是计算所有像素对之间全局相关量的视觉相似度模块;最后是基于GRU的光流迭代更新器。针对存在光反射和闪烁的河面场景,本文在运动特征提取部分引入了注意力机制。由于不同迭代轮次的中间值对于光流估计结果的贡献度不同,本文提出一种具有不同权重的复合损失函数方法,通过增加体现流体物理特性的角误差和旋度平滑损失,提高光流估计网络在流体运动估计中的泛化性能。
2.1 引入CBAM注意力的特征编码器
RAFT的运动特征提取网络由上下文编码器和特征编码器两部分组成,这2个编码器结构相同,均由6个残差块组成,两两一组,分别具有1/2、1/4和1/8的分辨率,通过这种下采样可得到密集的特征映射。两者的不同在于,上下文编码器只接受I1,并使用批处理规范化而不是实例规范化。
RAFT的运动特征提取网络专注于捕获大型、刚性运动物体,然而在RSV估算问题中,波纹或示踪物的尺寸较小、形状不规则、分布密集且运动模式复杂,因此,需要对网络进行修改,以更好地适应流体运动估计。
受人类生物系统的启发,注意力机制在深度学习领域得到广泛应用,在处理大量信息时,注意力能够引导模型关注重要的部分。在RSV估计中,有反射或阴影的水域背景常被误检为示踪物,这在很大程度上影响了光流估计的性能。为此,本文引入了注意力机制,自适应调整权重,可更加准确地提取到所需特征。CBAM[19]是通道注意力和空间注意力并重的注意力机制网络,原理如图2所示,通道注意力分支是将输入特征在通道维度上进行最大池化和平均池化,再将得到的向量输入共享权重的多层感知机(MLP),最后逐位相加,得到通道注意力,如式(3)所示:
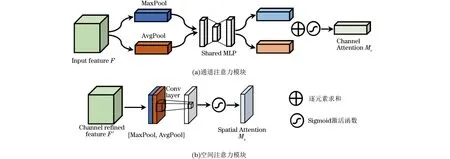
图2 通道注意力模块和空间注意力模块Fig.2 Channel attention module and spatial attention module
Ac(F)=σ(MLP(AvgPool(F))+
MLP(MaxPool(F)))
(3)
空间注意力分支是将输入特征的最大池化和平均池化连接起来,再经过卷积层和激活函数得到空间注意力,如式(4)所示:
As(F)=σ(Conv(Cat(AvgPool(F),
MaxPool(F))))
(4)
改进的RAFT光流估计网络模型如图1所示,加入CBAM的特征编码器可以使运动特征提取网络聚焦于信息丰富的区域,如带粒子或波纹的像素,减少无关区域诸如反射、阴影、背景等像素点的影响。
2.2 结合流体物理特性的光流估计损失函数
损失函数是深度学习的关键部分,主要调节样本和预测之间的误差,其实际意义通常是真实值与预测结果之间的差距。研究表明,损失函数与神经网络的泛化能力和训练效率密切相关[20],然而RAFT是基于刚体运动的基本特性展开的,其关键损失函数部分仍普遍采用L1范数或L2范数,缺乏对流体运动特性的考虑。因此,将流体运动特性的物理知识与深度学习方法相结合的方法为研究者提供了一种新的研究思路[21]。
文献[22]为解决图像序列中光照漂移问题,提出基于亮度梯度和一阶旋度散度平滑项的损失函数来优化针对PIV数据集的LiteflowNet网络,并将复合损失函数添加到U-Net中,取得了较好的效果,这说明引入基于流体物理先验知识的损失函数能更好地指导网络训练。受其启发,本文提出一种结合基于LI范数距离平均绝对误差(MAE)、平均角误差(AAE)和旋度散度平滑损失的复合损失函数,对流体运动的局部和全局特征进行多维度优化。基于流体物理知识的复合损失网络结构如图3所示。复合损失函数表达式如式(5)所示:

图3 基于流体物理损失的CBAM-RAFT网络结构Fig.3 CBAM-RAFT network structure based on fluid physical loss
Lfinal=λ1LMAE+λ2LAAE+λ3LS
(5)
其中:λ1、λ2、λ3为权重系数,用于平衡训练过程中各损失项的相对重要性。
2.2.1 改进的MAE损失函数
RAFT采用预测值与真实值之间的L1范数距离误差监督网络进行训练,由于RAFT架构存在光流迭代模块,根据迭代得到的流场具有由粗糙到精细的特点,本文引入按照迭代次数呈指数增长的权重来调整不同迭代轮次的重要性,改进的MAE表达式如式(6)所示:
LMAE=

(6)
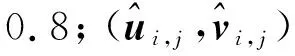
2.2.2 AAE损失函数
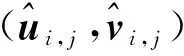
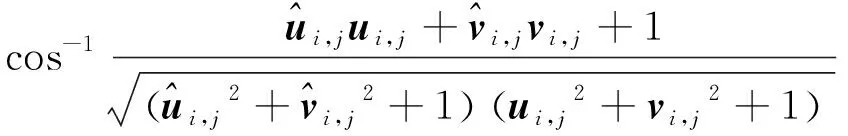
(7)
2.2.3 旋度散度平滑损失函数
旋度和散度是描述空间矢量场特征的二阶物理量。在流场估计中,它们建立了单个矢量与全局矢量流场之间的联系。本文采取流场真实值旋度和散度以及模型预测值旋度和散度的L2范数加权作为二阶流场平滑损失函数,计算公式如式(8)所示:

(8)

流场散度和旋度计算如式(9)和式(10)所示:

(9)
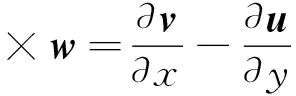
(10)
对于复合损失函数,往往需要一个超参数尺度因子调节各损失函数模块参与比例。为了在确保模型训练稳定和收敛的同时,又能使每个损失函数模块都能够发挥其应有的作用,各部分损失的数量级应该保持一致。通过测试,发现模型的AAE通常在15°左右,而均方根误差(RMSE)在1个像素以下,旋度和散度的平均值在0.1以下。因此,本文研究采用RMSE作为基本损失函数,将超参数λ1、λ2、λ3的值分别设为1、0.05、和10。
3 实验与结果分析
3.1 模型训练
由于RAFT是一种密集光流监督模型,很难获得有大量像素位移标记的真实河流场景数据集,因此使用开源光流数据Sintel[24]预训练,并采用PIV数据集[25]作为验证集。对于模型训练性能评价,本文采用EPE损失,即预测光流与地面真实光流之间欧氏距离平均值。GRU更新器的迭代次数设置为12,优化器选用Adam优化器,批量大小设置为4,并将初始学习率设置为0.000 125。为了充分验证所提方法的有效性,采用文献[26]构造出的虚拟河流数据集和现场采集的河流数据集[27-28]进行实验。
3.2 真实河流数据集实验结果分析
为了评估在自然场景中基于DLOF的表面速度测量方法表现效果,本文采用收集到的12段Brenta River河流视频[28]、Hurunui River和Stanton River河流视频进行验证。为评估提出的模型对光影的抗干扰能力,在12段Brenta River河流视频中添加光照噪声来模拟光照场景。所有Brenta River视频帧率为25 Hz,时长为20 s,其他视频信息以及不同模型对Brenta River的RSV估计结果的平均相对误差如表1所示。

表1 不同光流方法的平均相对误差估计结果Table1 Result of average relative error estimated by different optical flow methods
Stanton River河流视频数据集是通过架设在河岸的摄像机以30 Hz帧率和分辨率为1 920×1 080像素录制的,时长为31 s,同时利用ADCP采样获取真实流速。表2列出了在Stanton River河流沿岸采集到的流速和水深数据。从图4和表2可以看出,Stanton River较浅,水流缓慢,河流清澈,表面漂浮着一些落叶可作光流估计跟踪的示踪物。此外,图像左下角有一片明显的光影闪烁水域,为验证本文提出的方法对倒影、光影闪烁噪声的鲁棒性,沿图4中标注的刻度线测量流速,得到的流速分布如图5所示,从图5椭圆圈出部分可以看出,引入CBAM和基于流体物理损失函数的RAFT模型在光照场景下鲁棒性更好。至于速度分布曲线波动,较大可能是河流表面示踪物较少,捕捉到的特征权重分布不均所致。
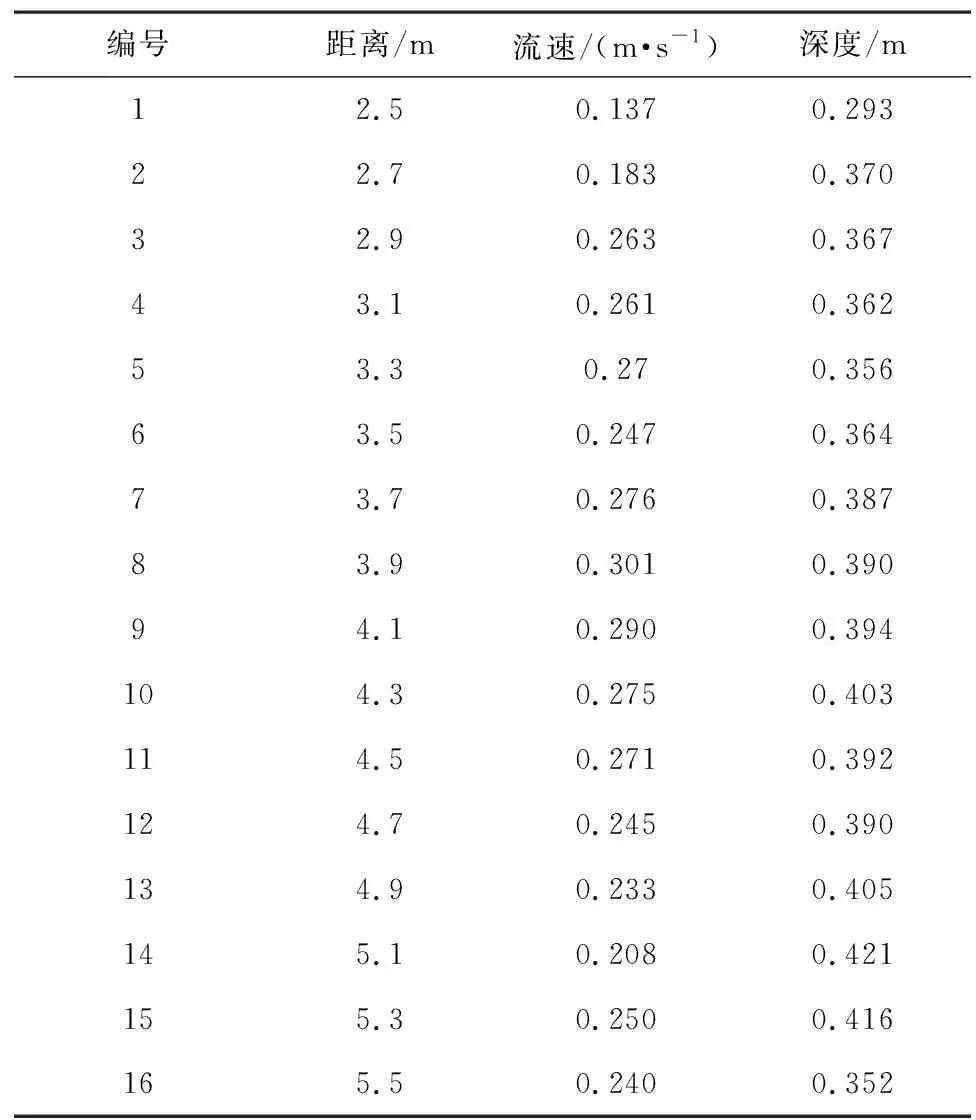
表2 Stanton River河流流速数据Table 2 Stanton River stream flow data

图4 Stanton River原图Fig.4 Original image of the Stanton River

图5 不同方法估算的Stanton River表面速度Fig.5 Stanton River surface velocities estimated by different methods
Hurunui River河流视频数据集是使用大疆 M210无人机以24 Hz帧率和分辨率为3 840×2 160像素录制的,时长为59 s,并使用ADCP采样获得真实流速。图6和图7展示了拍摄画面以及本文提出的改进RAFT流速估计箭头矢量图。由于Hurunui River水质清晰度较低,流速较高,河流表面平坦,波纹均匀密集,RAFT和本文方法测得流速均接近于真实流速,此外,从图8折线图可以看出,相较于RAFT,本文的改进方法流速曲线更平滑,误差更小,这表明提出的改进方案在普通环境高流速场景下依然有效。

图6 Hurunui River原图Fig.6 Original image of the Hurunui River

图7 改进RAFT估算的Hurunui River流速分布Fig.7 Hurunui River streamflow distribution estimated by the improved RAFT

图8 不同方法估算的Hurunui River表面速度Fig.8 Hurunui River surface velocities estimated by different methods
3.3 虚拟河流数据集实验可视化分析
为了更直观地体现模型改进的有效性和泛化能力,选取晴天、多云、森林以及无人机高空拍摄等多场景虚拟河流视频进行流场颜色编码可视化,图9展示了两个场景的RSV估计结果,场景1(见图9 第1行)为有光照反射的晴天(河水朝左下方流动),场景2(见图9第2行)为无人机拍摄场景(河水朝右流动)。可以看到,在场景1中,初始RAFT模型估计的流场可视化图[图9(b)]左下方有较大空腔,主要是因为该区域河流表面受到光影干扰,导致基于光流的模型难以跟踪粒子运动,而图9(c)和图9(d)的空腔明显变小,这说明本文改进模型对于光影干扰有更好的鲁棒性。此外,从场景2的图 9(c)也可以看出,引入CBAM机制后模型微小特征学习能力增强,因而图 9(c)颜色略深于图 9(b),场景2图 9(d)明显更平滑一些,这是结合旋度散度平滑损失函数的结果。其中,场景1的图 9(d)图右上角为流场颜色编码,颜色类型表示流场方向,深浅表示流场大小。

图9 虚拟河流视频可视化图Fig.9 Visualization of synthetic river flow videos
4 结束语
本文提出一种改进的OFV方法,提高在有反射和光影噪声的河道场景下RSV估计的精度和鲁棒性。该方法在深度学习监督模型RAFT基础上,引入注意力机制增强在相似性高的河道表面特征识别能力,同时在光流迭代过程中采用基于流体物理运动特性的复合损失函数,提高模型在流体运动估计上的泛化性能,降低其在光影干扰等复杂环境中的误检率。实验结果表明,该方法具有较好的鲁棒性,能够生成更加精准的表面速度空间分布图。本文采用的将流体物理特征知识融合到DLOF损失函数的方法,结合了传统光流估计和深度学习两者的优点,为后继RSV测量提供了一种新的研究思路。下一步研究方向是构建具有真实稠密流速的河道数据集,提高光流估计网络在RSV估计上的泛化能力。
