图像复原中自注意力和卷积的动态关联学习
2024-04-22江奎贾雪梅黄文心王文兵王正江俊君
江奎,贾雪梅,黄文心,王文兵,王正,江俊君
1.哈尔滨工业大学计算机科学与技术学院,哈尔滨 150000;2.武汉大学计算机学院,武汉 430072;3.湖北大学计算机与信息工程学院,武汉 430062;4.杭州灵伴科技有限公司,杭州 310000
0 引言
复杂的成像条件,如雨雾、低光、水下散射等会对图像质量产生不利影响,并显著降低基于人工智能应用技术的性能,如图像理解(Liao 等,2022;Wang 等,2022a)、目标检测(Zhong 等,2021)和目标识别(Xie 等,2022)。因此,急需研究有效的图像修复方案,消除成像过程中的降质扰动,提升图像的可辨识度和可读性,输出高质量的修复结果。
近十年中,图像修复(马龙 等,2018;Chen 等,2021;Wang 等,2020a;Yang 等,2022)获得了前所未有的发展。在深度神经网络之前,基于模型的图像修复方法(Garg和Nayar,2005)更多地依赖于图像内容的统计分析,并在降质或者背景上引入人为设定的先验知识(例如稀疏性和非局部均值滤波)。尽管如此,这些方法在复杂多变的降质环境中稳定性较差(Bossu 等,2011;Chen 和Hsu,2013;Zhong 等,2022)。
与传统基于模型的方法相比,卷积神经网络(convolutional neural network,CNN)能够从大规模的数据中学习到广义统计知识,无疑是更好的选择。为了进一步提高图像修复的效果,现有网络设计了各种复杂的结构和训练方式(Jiang 等,2021b;杨红菊 等,2022;Yu等,2019)。然而,由于局部感知和平移同变性的固有特征,CNN 至少有两个缺点:1)感受野有限;2)滑动窗口在推理时的静态权重无法应对内容的多样性。具体来讲,前者使网络无法捕捉到长距离的像素依赖性,而后者则牺牲了对输入内容的适应性。因此,它远远不能满足表征全局降质分布的需求。以图像去雨为例,基于CNN 的方法输出结果会有明显的雨水残留(如Ren 等人(2019)方法 和DRDNet(detail-recovery image deraining network)(Deng 等,2020))或细节损失(如MPRNet(multi-stage progressive image restoration network)(Zamir 等,2021)和SWAL(selective wavelet attention learning)(Huang 等,2021)),如图1 中的去雨结果所示。

图1 各种去雨方法的结果比较Fig.1 Comparison of the results of various deraining methods
给定一个像素,自注意力(self-attention,SA)会通过其他位置的加权去获得当前位置的全局响应。在各种自然语言和计算机视觉任务的深度网络中都进行了相关的研究(Vaswani 等,2017;Wang 等,2018;Zhang 等,2019b)。得益于全局处理的优势,SA 在消除图像扰动方面取得了比CNN 更加显著的性能提升(Chen 等,2021;Liang 等,2021;Wang 等,2022b)。然而,由于SA 的计算是全局的,其计算复杂度随空间分辨率呈二次方增长,因此无法应用于高分辨率图像。SA 也可应用于图像修复任务,如图像去雨、去雾、超分等。Restormer(Zamir等,2022)提出了一种多头转置注意(multi-dconv head transposed attention,MDTA)模块来建模全局关联,并取得了令人印象深刻的图像修复效果。尽管MDTA 是在特征维度上而不是在空间维度上应用SA,具有线性的复杂度,但Restormer(Zamir 等,2022)还是需要更多的计算资源才能获得更好的恢复性能。因其具有563.96 Gflops 和 2 610 万个参数,使用一个TITAN X GPU 对512×512 像素的图像进行去雨需要0.568 s,这对于许多资源有限的实际应用来讲,所需的算力或内存都是昂贵的。
除效率低之外,Restormer 至少还有两个缺点。1)将图像修复看做是基于扰动和背景图像的简单叠加,这是有争议的。因为降质扰动层和背景层是交织重叠的,其中降质影响了图像的内容,包括细节、颜色和对比度。2)构建一个完全基于Transformer的框架是次优的。因为SA擅长聚合全局特征图,但缺乏CNN 在学习局部上下文关系方面的能力。这自然引出了两个问题:1)如何将降质扰动去除与背景修复联系起来?2)如何将SA 和CNN 有效地结合起来实现高精度和高效率的图像修复?
为了解决第1 个问题,本文从降质分布揭示退化位置和程度的观测中得到启示,降质分布反映了图像退化的位置的强度。因此,提出以关联学习的方式,利用预测的退化来优化背景纹理重建,将扰动去除与背景重构相结合,分别设计了图像雨纹移除网络(image deraining network,IDN)和背景重构网络(background recovery network,BRN)来完成图像修复。关联学习的关键部分是一种新的多输入注意模块(multi-input attention module,MAM)。它对输入降质图像中得到的退化分布进行量化表征,生成退化掩码。得益于SA 的全局相关性计算,MAM 可以根据退化掩码从降质输入中提取背景信息,进而有助于网络准确的恢复纹理。
处理第2 个问题的一个直观想法是利用这两种架构的优势构建一个统一的模型。Park 和Kim(2022)已经证明SA 和标准卷积网络有着相反且互补的特性。具体来说,SA 倾向于聚合具有自注意力中重要的特征图,但卷积使其多样化,以专注于局部纹理。与Restormer 中设置的Transformer 不同,本文以并行的方式处理SA和CNN,并提出了一种交叉融合网络。它包括一个残差Transformer 分支(residual Transformer branch,RTB)和一个编码器—解码器(encoder-decoder branch,EDB)。前者通过多头注意力和前馈网络来编码图像的全局特征。相反,后者利用多尺度编码器—解码器来表示上下文知识。并且本文设计了一种轻量级交叉融合块(hybrid fusion block,HFB)来聚合RTB 和EDB 的结果,最终用以处理对应的学习任务。通过这种方式,最终构建一种基于Transformer 的两阶段模型,即ELF(image deeraining meets association learning and Transformer)。在图像去雨任务上,其平均性能优于基于CNN 的SOTA(state-of-the-art)方法MPRNet(Zamir 等,2021)0.25 dB,并且节省了88.3% 和57.9%的计算成本和参数。
本文的主要贡献如下:1)首次考虑到Transformer 和CNN 在图像修复任务中的高效性和兼容性,并将SA 和CNN 的优势整合到一个基于关联学习的网络中,用于扰动消除和背景重构。这是一个针对图像修复任务的局部—整体多层次结构的高效实现。2)设计了一种新的多输入注意力模块(MAM),将扰动去除和背景重构任务巧妙地关联起来。它显著减轻了网络学习负担,同时促进了背景纹理恢复。3)在图像去雨、水下图像增强、低光照增强和检测任务上的综合实验论证了本文提出的ELF方法的有效性和效率。以图像去雨任务为例,ELF平均比MPRNet(Zamir 等,2021)在峰值信噪比(PSNR)上高出0.25 dB,而后者的计算成本为前者的8.5倍,参数量为前者的2.4倍。
1 相关工作
图像去雨的相关工作在架构创新和训练方法方面都取得了重大进展。本节将简要介绍一些典型的且与本文研究相关的图像去雨、图像恢复和视觉Transformer模型。
1.1 单图像去雨
传统的去雨方法(Kang 等,2012;Luo 等,2015)采用图像处理技术和手工制作的先验来解决去雨问题。然而,当预定义的模型不成立时,这些方法会产生较差的结果。基于深度学习的去雨方法(Li 等,2017;Zhang 和Patel,2017;Jiang 等,2023)都表现出令人印象深刻的性能。早期基于深度学习的去雨方法(Fu 等,2017a;Zhang 等,2018a)应用卷积神经网络(CNN)直接减少从输入到输出的映射范围,以此产生无雨结果。为了更好地表示雨水分布,研究人员考虑了雨水特征,如雨密度(Zhang 等,2018b)、大小和遮蔽效应(Li等,2017,2019a),并使用递归神经网络通过多个阶段(Li 等,2018c)或非局部网络(Wang 等,2020b)来利用长距离空间相关性更好地去除雨纹(Li 等,2018b)。在此基础上,SA 利用其强大的全局相关学习消除了雨水退化,取得了优秀的效果。虽然采用精简表示和基于全局不重叠窗口的SA(Wang 等,2022b;Ji 等,2021)来提升全局SA 以减轻计算负担,但这些模型仍然会迅速占用计算资源。除了效率低之外,这些方法(Zamir 等,2022;Ji 等,2021)仅将去雨任务视为雨水扰动的消除,忽略了退化带来的背景细节缺失和对比度偏差。图2 展示了在TEST1200 数据集上比较主流图像去雨方法的效果与性能。
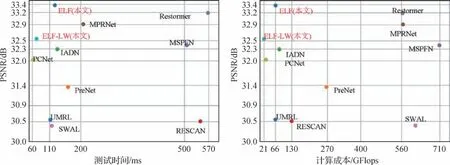
图2 在TEST1200数据集上比较主流图像去雨方法的效果与性能Fig.2 Comparison of mainstream deraining methods in terms of efficiency vs.performance on the TEST1200 dataset
1.2 图像恢复
从低质量图像中恢复高质量图像的任务统称为图像恢复任务,如水下图像增强、低光照图像增强、图像去雾等,具有与图像去雨类似的降质因素。接下来,本小节简要介绍一些典型的水下图像增强和低光照图像增强方法。
1.2.1 水下图像增强
早期的水下图像增强方法通过动态像素范围拉伸(Iqbal 等,2010)、像素分布调整(Ghani 和Isa,2015)和图像融合(Ancuti 等,2012)等方法来调节像素值以实现增强,但这些方法难以应对多样的水下场景。随着深度学习的发展,一些基于深度学习的水下图像增强方法相继提出。其中基于生成对抗网络的方法成为主流,如UCycleGAN(underwater CycleGAN)(Li 等,2018a)采用弱监督的方式将CycleGAN(Zhu 等,2017)的网络结构应用到此任务中,Guo 等人(2020b)提出一个多尺度密集生成对抗网络,都取得了不错的效果。但这些方法都只是简单应用基于生成对抗网络的结构,并没有考虑复杂的退化关系,生成的结果有明显的雨水残留,而且会引入对比度失真。
1.2.2 低光照图像增强
早期的低光照图像增强方法多基于像素灰度值统计分析,如直方图均衡化(Cheng 和Shi,2004;Pisano 等,1998)等。但这些方法只利用了灰度分布,并没有考虑空间信息,增强后的图像可能会过曝光或欠曝光,与真实图像不一致。相比之下,基于视网膜皮层理论(retinal cortex theory)的方法(Jobson等,1997)将输入的低光照图像分解为光照和反射率两部分,通过增强光照部分来增强图像。但这些方法通常缺乏足够的适应性,难以获得稳定的光照分布,且易缺失细节纹理信息。通过学习低光图像到正常光图像的映射,基于深度学习的方法取得了综合的最优效果。例如,Zero-DCE(Guo 等,2020a)通过逐步推导构造出了一种轻量的像素级别的曲线估计网络,来学习像素级高阶曲线参数映射,同时提出无参考损失函数对输出图像的质量进行间接的评估。EnlightenGAN(Jiang等,2021d)提出了一种高效无监督的生成对抗网络,并对全局—局部鉴别器结构,自正规化感知损失融合和注意机制进行了测试,实现了很好的低光照图像增强效果和通用性。LLFlow(Wang 等,2022c)提出以低光图像/特征为条件,学习将正常曝光图像的分布映射到高斯分布中。然后,通过在训练中约束正常图像的光流结构实现图像增强。但是,单一映射的网络结构使得它们在应对复杂输入时可能产生伪影、色差等问题,且难以恢复精细的结构纹理。
1.3 视觉Transformer
基于Transformer的模型首先应用在自然语言任务中的序列处理(Vaswani 等,2017)。由于ViT(visual Transformer)(Dosovitskiy 等,2021)具有很强的长距离依存关系学习能力,因此将Transformer 引入了计算机视觉领域,并将大量基于Transformer 的方法应用于计算机视觉任务,例如图像识别(Dosovitskiy 等,2021;Ijaz 等,2022),分割(Wang 等,2021),目标检测(Carion 等,2020;Liu 等,2021)。对于给定的输入内容(Khan 等,2021),视觉Transformer(Dosovitskiy 等,2021;Touvron 等,2021)将一幅图像分解为一组局部窗口序列,并学习它们之间的相互关系。例如,TTSR(texture Transformer network for image super-resolution)(Yang 等,2020)提出了一种自注意力模块,可以提供准确的纹理特征,用于将参考图像中的纹理信息传输到高分辨率图像进行重建。Chen 等人(2021)在ImageNet 数据集上提出了一个预训练的图像处理Transformer,并使用多头网络架构分别处理不同的任务。然而,SA 的直接应用未能充分利用Transformer 的潜力,这是由于自注意力巨大的计算负载和不同深度(尺度)层之间的低效通信造成的。此外,很少有工作考虑到Transformer与CNN 之间的内在互补特性去构建一个有效统一的模型。自然地,这种设计限制了局部邻域内的上下文融合表达,这违背了使用自注意力而不是卷积的主要动机,因此不适合图像恢复任务。相比之下,本文探索连接两者的桥梁,并为图像去噪任务构建了Transformer和CNN的交叉模型。
2 本文方法
本文的主要目标是利用CNN 和Transformer 构建高效、高精度的图像修复模型。理论上,自注意力将特征映射值与正向的重要权重进行平均,以学习全局表示,而CNN 倾向于聚合局部相关信息。直观上,将它们结合起来以充分利用局部和全局纹理是合理的。一些研究试图将这两种结构结合起来,形成一种用于浅层图像恢复的交叉框架,但是未能充分发挥其作用。
以图像去雨为例,与直接将Transformer 块替换卷积的方法不同,本文考虑了这两种结构的高效性和兼容性,并构建了一个称为ELF的交叉框架,能够充分协调它们在图像修复任务上的优势。与现有的图像修复方法相比,所提出的ELF 至少在两个关键的方面与它们不同。
1)设计概念不同。与基于叠加模型的方法不同的是,ELF 将背景图像IB的最优近似值从雨天图像IRain中预测出来,或从雨天图像中残差学习雨水信息IR并生成,ELF 将图像去雨任务转换为雨纹去除和背景重构的组合,并引入Transformer 将这两部分与新设计的多输入注意力模块(MAM)联系起来。
2)成分不同。由于低频信号和高频信号是SA和卷积(Park 和Kim,2022)中十分重要的信息,因此构建了一个用于特定特征表示和融合的双分支框架。具体来说,ELF 的主干是一个双分支交叉的融合网络,包括了一个残差Transformer分支(RTB)和一个编码器—解码器分支(EDB),分别学习全局结构(低频成分)的表征和局部纹理(高频成分)的表征。
图3 概述了提出的ELF 的框架,该框架包含图像去雨网络(IDN)、多输入注意力模块(MAM)和背景重构网络(BRN)。为提高效率,IDN 和BRN 共享相同的双分支交叉融合网络,详见第2.2节。
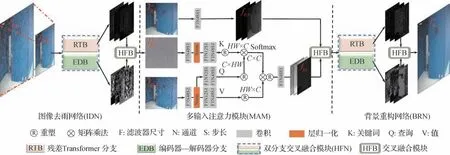
图3 本文提出的图像修复方法ELF的网络结构(以图像去雨任务为例)Fig.3 The architecture of our proposed ELF image restoration method(taking image deraining as an example)
2.1 网络流程及优化
给定一幅雨天图像IRain∈RH×W×3和一幅干净版本的图像IB∈RH×W×3,其中H和W表示映射特征的空间高度和宽度。可以观察到,雨图样本IRain,S∈RH×W×3经过双线性插值重建的雨天图像IRain,SR∈RH×W×3与原始雨天图像有着相似的统计分布,如图4 所示。受到启发,本文在样本空间中去预测雨纹分布,以减轻学习和计算负担。

图4 真实样本与合成样本的“Y”通道直方图拟合结果Fig.4 Fitting results of “Y” channel histogram for real and synthetic samples of true sample and synthetic sample((a)true sample;(b)synthetic sample)
以这种方式,首先对IRain和IB进行双线性操作,生成相应的子样本(IRain,S∈R和IB,S∈R)。如前所述,ELF 包含两个子网络(IDN 和BRN),通过关联学习来完成图像去雨。因此,IRain,S被输入到IDN中,生成相应的雨水分布和去雨结果,具体为
式中,FBS(·)表示双线性下采样,以生成雨天图像样本IRain,S,ϑIDN(·)表示IDN中的雨水评估函数。
雨水分布展示了退化的位置和程度,将其转化为退化自然是合理的,有助于准确地恢复背景。在将传入BRN 进行背景重构之前,设计了一个多输入注意力模块(MAM),如图3 所示,该模块通过Transformer 层能够充分利用来自雨天图像IRain的背景信息进行互补,并将其合并为嵌入表征。MAM的流程表示为
式中,FSA(·)表示自注意力函数,包含了嵌入函数和点乘交互。FB(·)是生成初始表征的嵌入函数。FHBF(·)是指HFB 中的融合功能。之后,BRN 将fMAM作为背景的重构,即
式中,ϑBRN(·)表示BRN 的超分辨率重建函数,FUP(·)表示双线性上采样。
与单独训练雨纹消除和背景重构不同,本文引入了联合约束来增强去雨模型与背景重构的兼容性,且能够从训练数据中自动进行学习。然后使用图像损失(Charbonnier 损失函数(Hu 等,2022;Jiang等,2020b;Lai 等,2017))和结构相似性(structural similarity,SSIM)(Wang 等,2004)损失对网络进行监督学习,同时实现图像和结构保真度的恢复。损失函数表示为
式中,α和λ用于平衡损失成分,分别设置为-0.15和1。惩罚系数ε设置为0.001。
2.2 交叉融合网络
自注意力机制是Transformer 的核心部分,它擅长学习长距离的语义依存关系和捕捉图像中的全局表示。与之相反,由于固有的局部连通性,CNN 更加擅长对局部关系进行建模。为此,本文结合Transformer 和CNN 的优势,将IDN 和BRN 的构建成深度双分支交叉融合网络。如图3 所示,主干包括残差Transformer 分支(RTB)和编码器—解码器分支(EDB)。RTB 以一些可学习的内容(特征通道)作为输入,叠加多头注意力和前馈网络来编码全局结构。然而,获取长距离像素的相互关系是造成Transformer 计算量巨大的罪魁祸首,使其无法应用于高分辨率图像,尤其是图像重构任务。受El-Nouby 等人(2021)启发,除了在样本空间上处理表征外,本文没有学习全局的空间相似性,而是应用SA计算跨通道的互协方差,以生成隐式编码全局上下文的注意力图,它具有线性复杂度而不是二次复杂度。
EDB 旨在推理局部中丰富的纹理,受U-Net(Ronneberger 等,2015)的启发,还使用U 形框架构建了EDB。将前3个阶段构成编码器,其余3个阶段作为解码器。每个阶段采用类似的架构,包括采样层、残差通道注意块(residual channel attention block,RCAB)(Zhang 等,2018c)和交叉融合块。使用双线性采样和1×1 卷积层来减少棋盘伪影和模型参数,而不是使用跨步或转置卷积来重新缩放特征的空间分辨率。为了促进不同阶段或尺度下的残差特征融合,设计了HFB 以在空间和通道维度上聚合不同阶段的多个输入。HFB可以在重构过程中充分利用更多不同的功能。此外,为了进一步减少参数量,RTB 和EDB 设置了深度可分离卷积(depthwise separable convolutions,DSC)。对 于RTB,将DSC 集成到多头注意力中,以在计算特征协方差之前强调局部上下文,从而生成全局注意图。此外,将EDB 构造成非对称U 形结构,其中编码器设计了便携式的DSC,但解码器使用标准卷积。该方案可以节省整个网络约8%的参数。实验证明,在编码器中使用DSC的编码器优于在解码器使用。
2.3 多输入注意力模块
如图3 所示,为将雨纹去除和背景重构联系起来,本文构建了一个带有Transformer 的多输入注意力模块MAM,充分利用背景信息进行互补增强。不同于将系列图像块作为Transformer 的输入,MAM 将预测的雨水分布,子空间的去雨图像和雨天图像IRain作为输入,首先学习嵌入表征去丰富局部语义内容,和fRain分别表示查询(query,Q),键(key,K)和值(value,V)的映射关系。这里不对大小为RHW×HW的空间注意图进行学习,而是重新定义Q和K的映射大小,并通过和fRain之间的点乘,生成交叉的协方差转置注意力图M∈RC×C。
如图5,注意力图引导网络从IRain的嵌入表征fRain中挖掘背景纹理信息fBT。SA的处理流程为

图5 MAM的可视化Fig.5 Visualization of MAM
式中,FK(·)、FQ(·)和FV(·)是进行映射的嵌入函数,◦是点乘操作。之后在交叉混合模块中,将提取的互补信息和的嵌入表征结合去丰富背景表征。
2.4 交叉融合模块
考虑到残差块和编码阶段之间的特征冗余和知识差异,本文引入了一种新的交叉融合块HFB,其中早期阶段的低层次背景特征有助于巩固后期阶段的高层次特征。具体来说,将深度可分离的卷积和通道注意层纳入HFB,以便在空间和通道维度上辨别性地聚合多尺度特征。与基于像素级叠加或卷积融合相比,提出的HFB更加灵活和有效。
3 实验结果
为了验证本文提出的ELF,在合成的和真实的雨天数据集上进行了广泛的实验,并将ELF 与几种主流的图像去雨方法进行比较。这些方法主要包含MPRNet(Zamir 等,2021)、SWAL(Huang 等,2021)、RCDNet(rain convolutional dictionary network)(Wang等,2020b)、DRDNet(detail-recovery image deraining network)(Deng 等,2020)、MSPFN(multi-scale progressive fusion network)(Jiang 等,2020a)、IADN(improved attention-guided deraining network)(Jiang等,2021a)、PreNet(progressive recurrent network)(Ren 等,2019)、UMRL(uncertainty guided multiscale residual learning)(Yasarla 和Patel,2019)、DIDMDN(density-aware multi-stream densely connected convolutional neural network)(Zhang 等,2018c)、RESCAN(recurrent se context aggregation net)(Li 等,2018c)和DDC(deep decomposition composition network)(Li 等,2019b)。使用5 种常用的评估指标进行评测,例如峰值信噪比(peak signal-tonoise ratio,PSNR)、结构相似性(SSIM)、特征相似性(feature similarity,FSIM)、自然度图像质量评估器(naturalness image quality evaluator,NIQE)(Mittal等,2013)和基于空间熵的质量(spatial-spectral entropy-based quality,SSEQ)(Liu等,2014)。
3.1 实验细节
3.1.1 数据收集
由于所有比较方法的训练样本存在差异,根据Jiang 等人(2020a)的方法,使用Fu 等人(2017b)、Zhang 等人(2020)方法中的13 700 个干净的背景/雨天图像对,用其公开发布的代码训练所有比较方法,并通过调整优化参数以进行公平比较。在测试阶段,选取了4 个合成基准Test100(Zhang 等,2020)、Test1200(Zhang 等,2018a)、R100H 和R100L(Yang等,2017)和3 个真实数据集RID(rain in driving)、RIS(rain in surveillance)(Li 等,2019a)和Real127(Zhang等,2018a)进行评估。
3.1.2 实验设置
在本文的基线中,RTB 的Transformer 模块数量设为10,根据经验,对于EDB 中的每个阶段,RCAB设置为1,滤波器数量为48。为了方便训练,将训练图像裁剪为固定尺寸为256×256 像素的块,以获得训练样本。使用学习率为2E-4 的Adam 优化器,每65 个训练轮数的衰减率为0.8,直到600 轮。批量大小为12,在单个Titan Xp GPU 上训练ELF 模型500 轮次。
3.2 消融研究
为了验证网络中各个组件对最终去雨性能的贡献,本节进行了相应的消融研究,包括自注意力(SA)、深度可分离卷积(DSC)、超分辨率重构(super resolution,SR)、交叉融合模块(HFB)和多输入注意力模块(MAM)。为简单起见,将最终模型表示为ELF,并通过删除上述所有组件来表示基线模型(用w/o 表示)。在Test1200 数据集上的去雨性能和推理效率方面的定量结果如表1 所示,实验表明完整的去雨模型ELF 比其不完整的版本有着显著的改进。与w/o MAM(从ELF 中删除MAM 模块)模型相比,ELF 实现了1.92 dB 的性能增幅,主要是因为MAM 中的关联学习可以帮助网络充分利用雨天输入的背景信息和预先预测的雨水分布。此外,将图像去雨任务分解为低维空间的雨纹去除和纹理重建在效率(推理时间和计算成本分别上升了19.8%和67.6%)和重构质量(参考ELF 和ELF*的结果,ELF*在原始分辨率空间上完成去雨和纹理重构)上具有相当大的优势。使用深度可分离卷积可以在参数大致相同的情况下增加通道深度,从而提高表示能力(参考ELF 和w/o DSC 模型的结果)。与用标准RCABs 替换RTB 中的Transformer 块的w/o SA 模型相比,ELF在可接受的计算成本下提升了0.45 dB。

表1 在Test1200数据集上消融实验Table 1 Ablation study on Test1200 dataset
本节进行了双分支交叉融合框架的消融实验,其中涉及一个残差Transformer 分支(RTB)和一个U 型编码器—解码器分支(EDB)。基于ELF,依次去除这两个分支,设计两个对比模型(w/o RTB和w/o EDB),定量结果如表1 所示。去除RTB 可能会大大削弱对空间结构的表示能力,导致性能大幅下降(参考ELF和w/o RTB模型的结果,PSNR下降2.09 dB)。此外,EDB允许网络聚合多尺度的纹理特征,这对于丰富局部纹理的表征至关重要。
3.3 与SOTA的比较
3.3.1 合成数据
表2 提供了在Test1200、Test100、100H 和R100L数据集的定量结果,以及推理时间、模型参数和计算成本。据观察,大多数模型在小雨的情况下一致地获得了优异性能,而ELF 和MPRNet 在大雨条件下仍然表现良好,特别在PSNR 上显示出更大的优势。ELF 模型在所有指标上都取得最优,平均超过了基于CNN 的SOTA(MPRNet)0.25 dB,且仅占其计算成本和参数的11.7%和42.1%。同时,轻量模型ELF-LW 仍然具有竞争力,在4 个数据集上的PSNR分数排名第3,平均比实时图像去雨的方法PCNet(Jiang 等,2021c)高出1.08 dB,并具有更少的参数(节省13.6%)和计算成本(节省23.7%)。
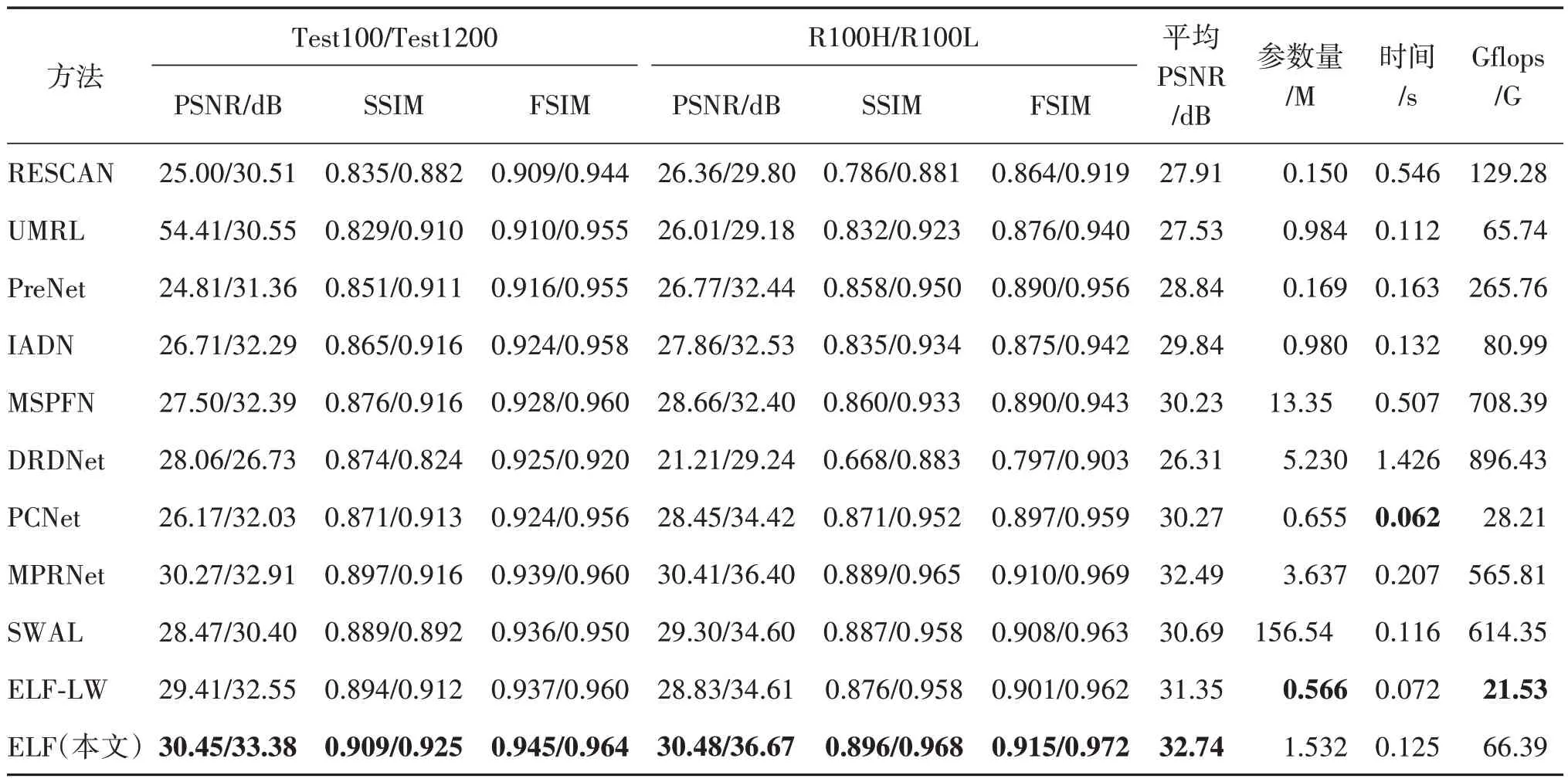
表2 在4个数据集上PSNR、SSIM和FSIM 的比较结果Table 2 Comparison results of average PSNR,SSIM,and FSIM on four datasets
图6提供了结果可视化,PreNet、MSPFN和RCDNet 等高精度的方法,可以有效消除雨水层,从而提高可见度。但由于大量的伪影和不自然的颜色外观,尤其是在大雨条件下,它们未能在视觉上产生好的效果。DRDNet专注于细节的重构,但推理过程耗时长、内存大。MPRNet 往往会产生过度平滑的结果。ELF 除了重构出更干净和更可靠的图像纹理外,产生的结果也具有更好的对比度以及更少的颜色失真(参考“老虎”和“马”的场景)。此外,可以推出重构质量的改善可能得益于提出的Transformer和CNN 的混合表示框架以及用于雨纹去除和背景重构的关联学习方案。这些策略方法被集成到一个统一的框架中,使得网络能够充分利用各自的学习优点进行图像去雨,同时保证模型的推理效率。

图6 7种图像去雨方法的可视化结果对比Fig.6 Visualization comparison of the results of seven image deraining methods
3.3.2 真实场景数据
进一步在3 个真实场景的数据集Real127、RID和RIS 上进行实验。表3 列出了NIQE 和SSEQ 的定量结果,其中NIQE 和SSEQ 分数越小,表示感知的质量越好,内容越清晰。ELF 同样具有很强的竞争力,在RID 数据集上的平均分数值最低,NIQE 和SSEQ 的平均分数在Real127 和RIS 数据集上是最好的。图7 直观展示了8 种方法在5 个真实场景(包括雨雾效应、大雨和小雨)中去雨的结果。可以看出,ELF 产生的无雨图像中内容更干净、更可信,而其他的方法未能很好地去除雨痕。这些实验表明了ELF模型不仅能够很好地消除雨水扰动,同时还能保留纹理细节和图像自然度。
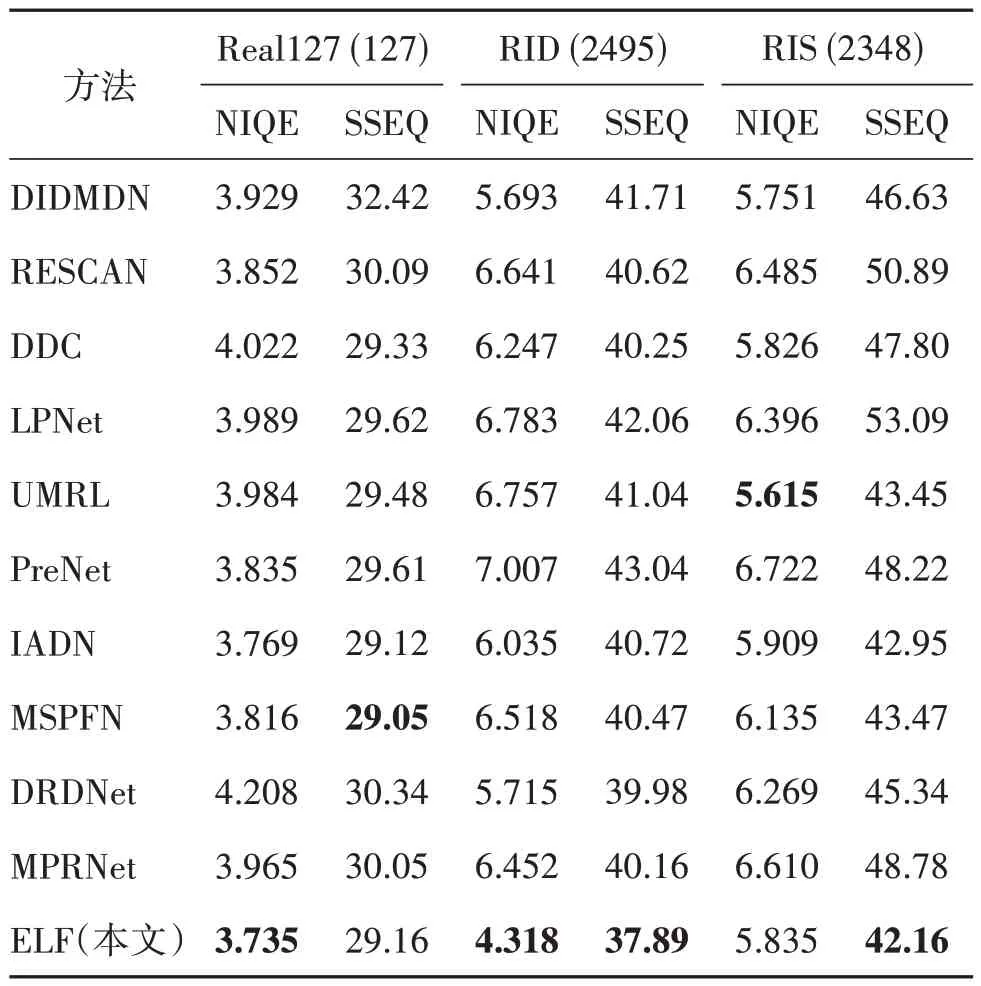
表3 3个真实数据集上10种图像去雨方法的NIQE/SSEQ 平均分数对比Table 3 Comparison of average NIQE/SSEQ scores with ten deraining methods on three real-world datasets

图7 8种方法在5个真实场景中去雨的结果对比Fig.7 Visual comparison of derained images obtained by eight methods on five real-world scenarios
3.4 对下游视觉任务的影响
在雨天条件下消除雨纹的退化影响,同时保留可靠的纹理细节对于目标检测来说至关重要。这就促使本文研究去雨对目标检测算法中检测精度的影响。为此,将ELF 和几个有代表性的去雨方法直接应用在一些雨天图像并生成对应的无雨图像,然后使用公开的YOLOv3(Redmon 和Farhadi,2018)预训练模型进行检测。
表4 展示了不同方法在COCO350 和BDD350 数据集上联合图像去雨和目标检测的结果比较。其中,COCO350 数据集的图像尺寸为640×480 像素,BDD350 数据集的图像尺寸为1 280×720 像素,目标检测算法为YOLOv3(you only look once v3)阈值为0.6。从表4 可以看出,ELF 在COCO350 和BDD350 数据集(Jiang 等,2020a)上的PSNR 分数最高,与其他去雨方法相比,ELF 生成的无雨结果具有更好的目标检测性能。
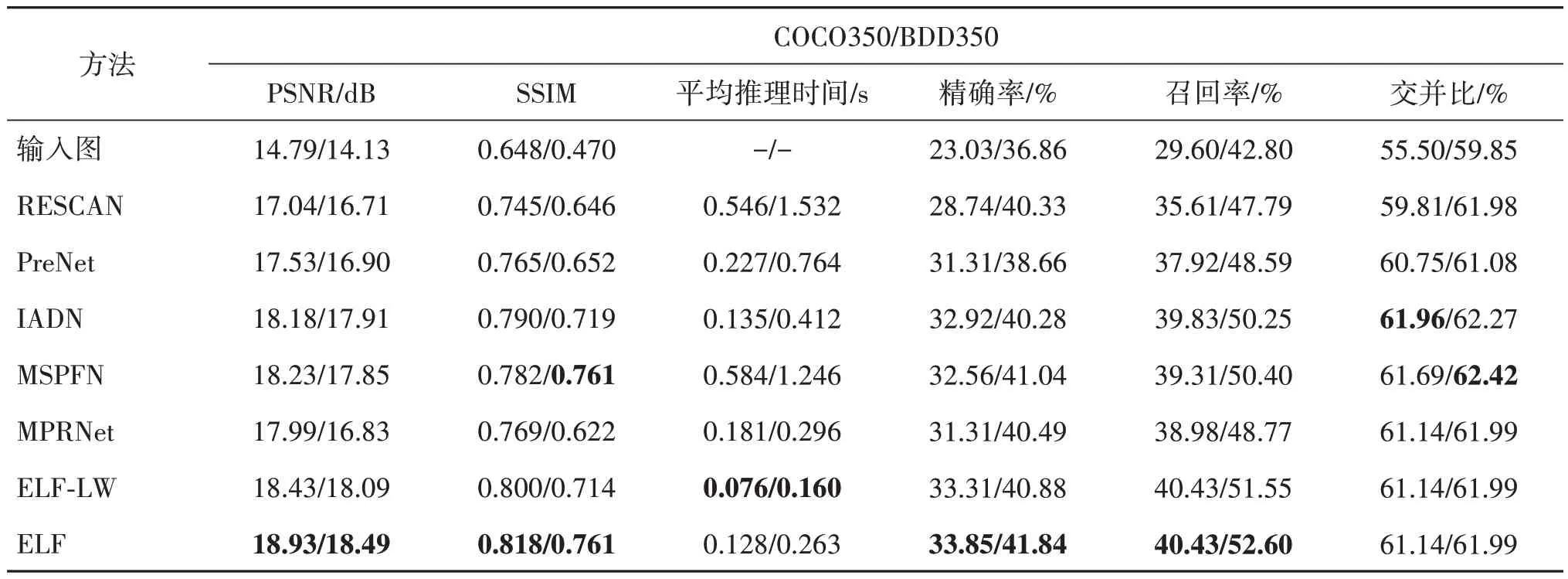
表4 不同方法在COCO350/BDD350数据集上联合图像去雨和目标检测的结果比较Table 4 Comparison results of joint image deraining and object detection on COCO350/BDD350
图8 为不同方法在BDD350 数据集上联合图像去雨和目标检测的可视化比较。图8 中两个样本的比较表明,ELF去雨图像在图像质量和检测精度方面有着显著的优势。去雨和下游检测任务的显著性能归因于雨纹消除和细节重构任务之间的关联学习。

图8 不同方法在BDD350数据集上联合图像去雨和目标检测的可视化比较Fig.8 Visual comparison of joint image deraining and object detection on BDD350 dataset
3.5 对其他图像恢复任务的通用性
一些图像恢复任务如水下图像增强,低光照图像增强等,具有和图像去雨相似的退化干扰因素,因此,为进一步探索提出的ELF的通用性与稳定性,本节在水下图像增强和低光照图像增强任务上开展了简单的研究。
3.5.1 水下图像增强
根据Li 等人(2021),使用2 050 对生成的水下图像来训练ELF。其中,800 对图像选自UIEB(Li等,2020a)数据集,1 250 对图像选自Li等人(2020a)提出的数据集S1000。分别在真实场景数据集R90(Li 等,2019b)和合成数据集S1000 上进行实验,并与7个主流的水下图像增强方法进行了对比。
表5列出了PSNR和均方误差(mean squared error,MSE)的定量结果,PSNR 分数越大、MSE 分数越小表明图像的质量越好。可以看到,ELF 在R90和S1000数据集上都取得了最好的结果,且平均PSNR分数比Ucolor(Li等,2021)方法分别高出4.15 dB和3.94 dB。
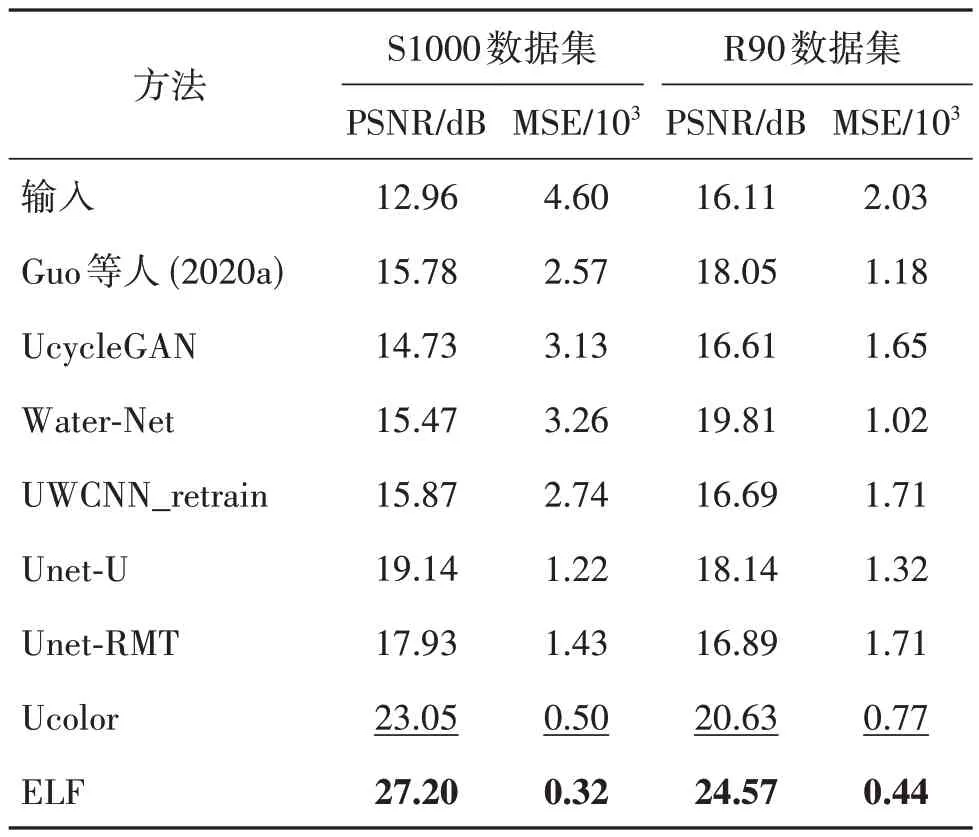
表5 在S1000和R90数据集上7种水下图像增强方法的PSNR 和 MSE平均分数比较Table 5 Comparison of average PSNR and MSE scores with seven underwater image enhancement methods on S1000 and R90 datasets
图9 直观地展示了得出的结果,可以看到,提出的方法在有效矫正水下图像的对比度和光照失真的同时,可以恢复出了更真实的细节结构,而其他对比方法,要么没有消除水下异常色调,要么恢复出的图像模糊、缺少细节信息。这些实验表明了ELF 模型在水下图像增强任务上的有效性和优势。

图9 5种方法在S1000和R90数据集上增强后的结果比较Fig.9 Visual comparison of enhanced images obtained by five methods on S1000 and R90
3.5.2 低光照图像增强
在低光照图像增强领域最常用的基准数据集之一LOL(Li 等,2019a)数据集上进行实验,评估ELF在该任务上的性能。使用LOL 训练集中485 对低光—正常光的图像对训练ELF,并在测试集上进行测试。除了PSNR 和SSIM 评估指标外,还使用了LPIPS(learned perceptual image patch similarity)(Li等,2020a)指标,越低的LPIPS 分数表示感知质量越好。
表6 给出了与9 个主流的低光照增强方法的定量对比结果,ELF 取得了最高的PSNR 分数,在SSIM和LPIPS 指标上也十分接近当下的最优方法。其中,LLFolw 采用额外的条件编码器提取光照不变的颜色图作为先验分布的均值,并利用基于低光照图像/特征为条件的负对数似然损失,这有助于表征图像结构和上下文内容,保证在图像流形中具有和真值相近的颜色分布。因此,LLFolw 可以获得更好的MAE 和LPIPS 分数。相比之下,本文提出的ELF 不需要任何颜色先验,但因具有精细的关联学习方案,和逐像素、结构一致性约束,这对本文方法获得更高的PSNR得分贡献更大。
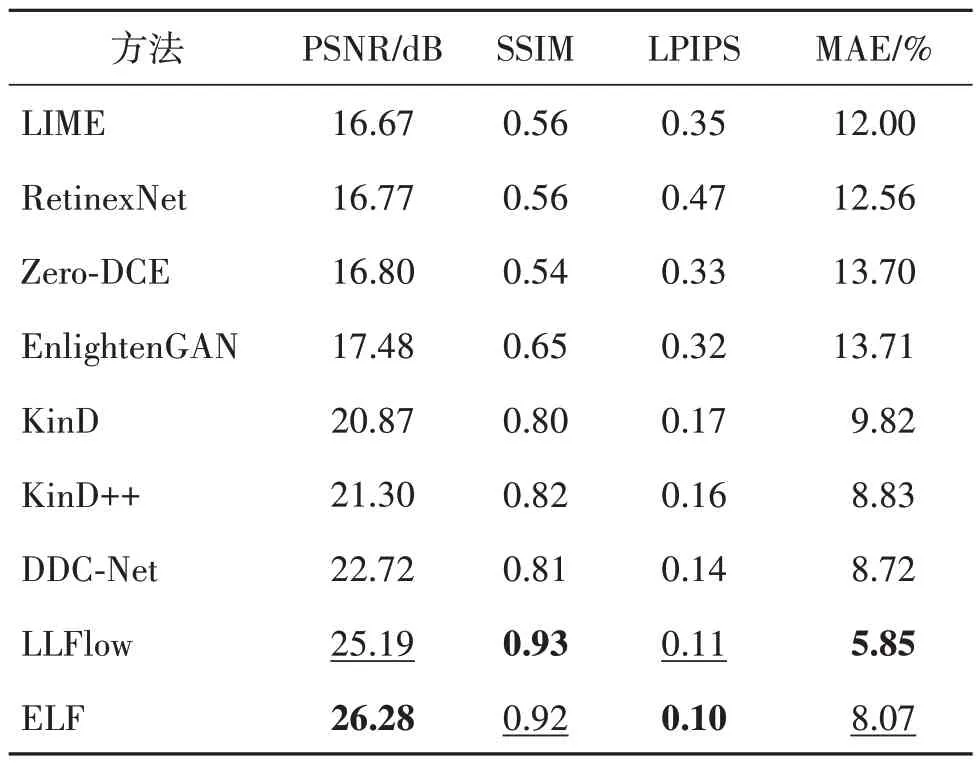
表6 在LOL数据集上比较9种低光照图像增强方法的PSNR、SSIM、LPIPS和MAETable 6 Comparison of average PSNR,SSIM,LPIPS and MAE scores with nine low light image enhancement methods on LOL datasets
为了进一步显示ELF 的有效性,图10 展示了直观的视觉结果。可以看到,部分方法恢复出的图像存在较大的噪声和伪影,如EnlightenGAN(Jiang 等,2021d)和KinD++(Zhang 等,2021);一些方法要么增强后的亮度不足,要么出现了过曝光的情况;相比之下,ELF 在合理增强图像亮度的同时,受噪声和色偏的影响较小,且恢复出了更接近原图的结构信息。这些实验表明了ELF模型在低光图像增强任务上的鲁棒性,也验证了提出的退化消除和背景恢复关联学习方案的有效性。

图10 7种方法在LOL数据集上增强后的结果比较Fig.10 Visual comparison of enhanced images obtained by seven methods on LOL dataset
4 结论
基于降质分布揭示了图像退化位置和程度的观察,本文引入退化先验来帮助精确的背景恢复,并据此提出了高效高质的部分—整体图像扰动去除和背景修复方案,即ELF。为了在提高模型紧凑型的同时实现关联学习,提出同时利用Transformer 和CNN的优势,构建一个精心设计的多输入注意力模块(MAM)来实现扰动去除和背景修复的关联学习。在图像去雨、水下图像增强、低光图像增强和联合目标检测任务上的大量实验结果表明,本文提出的ELF模型远优于现有的主流图像增强模型。
尽管本文方法在图像去雨、水下图像增强、低光图像增强,以及联合目标检测任务上展示了令人印象深刻的效果,但因缺少对不同降质的特性和共性特征的特定表达,在应对具有多种复杂天气条件的真实场景时可能失效。同时,该方法仍然需求大量的高质量成对训练数据,极大地限制了在新场景和新任务上的推广,并且和真实环境降质存在极大的域差异。为了解决上述问题,未来作者团队拟引入视觉大模型作为特征、语义表达先验,在隐式空间实现不同降质环境下场景本质信息的表征,消除场景和降质差异;进一步引入基于提示的文本语言大模型,实现实时可交互的场景内容修复、理解和分析。
