基于OpenCL 的驾驶监控系统自调优化研究
2024-04-20刘创李智
刘创,李智
(四川大学 电子信息学院,四川成都,610000)
0 引言
人工智能在视频图像领域已经从理论研究进入了工业和生活,例如自动驾驶、智能视频监控分析等。这项技术的实现与应用就是让计算机系统能快速地读取大量的视频图像信息,并及时做出一系列判断和反馈。因此,如何在有限的时间内分析处理大批量图像数据是实际产业应用系统设计中的难点。为了满足驾驶员监控系统(DMS)的应用需求,各类计算机视觉算法及框架层出不穷,各种异构计算架构及高性能计算平台百花齐放。与此同时,面对特定场景需求的复杂性,学术界和产业界陆续展开了关于如何将算法模型轻松高效部署在特定计算平台的研究与应用工作[1-4]。
OpenCL 是专门为异构计算制定的标准,它可以协调具有不同架构的处理器同时进行工作,这就解决了传统的同构架构下资源利用率低、处理速率慢的问题。同时,OpenCL可以充分发挥不同架构处理器的性能,比如将C 与GPU 和FPGA 强大的并行处理能力相结合,可以完成高性能和低功耗的产品设计以及物联网应用等[5]。
以驾驶员监控系统应用为项目背景,针对深度学习模型计算量大,视频图像识别实时性要求高,应用场景设备资源受限等问题,利用 OpenCL 在基于 CPU+GPU 的异构计算平台上研究实现 YOLOv3 算法的并行化,并且结合最新自动化的端到端的深度学习优化编译器 TVM 解决算法的多平台移植和部署问题[6-7]。
1 背景与相关研究
1.1 车载监控系统
驾驶员监控系统,缩写DMS,主要是实现对驾驶员的身份识别、驾驶员疲劳驾驶以及危险行为的检测功能[8]。在现阶段开始量产的L2-L3 级自动驾驶中,其实都只有在特定条件下才可以实行,很多实际情况需要驾驶员能及时接管车辆进行处置。因此,在驾驶员过于信任自动驾驶而放弃或减弱对驾驶过程的掌控时可能会导致某些事故的发生,而DMS 的引入可以有效减轻这一问题的出现。因此,近年来各国的政策法规等多方面开始推进DMS 的上车:欧盟和中国均出台法律法规。国内已率先对“两客一危”等商用车车型安装DMS 系统作出强制要求,乘用车搭载要求也在推进制定中。而欧盟则将DMS 纳入EuroNCAP 五星安全评级的关键要素,而且是必要条件。几乎是从2020 年开始,DMS系统的装车率快速提升,行业进入发展快车道。
DMS 的核心功能主要是疲劳监测、分心监测、危险行为监测。早期的DMS 方案主要通过非生物特征的技术来实现,比如通过方向盘及转向传感器,监测任何不稳定的方向盘运动、车道偏离或无故改变速度等。但由于系统复杂,非直观感知,整体的搭载率一直很低。现阶段的DMS 则大多是基于摄像头的面部识别和眼球跟踪技术,通过红外光等采集驾驶员面部信息再经过算法分析出人员当下的身体状态,在检测到驾驶员处于不安全状态时,再通过闪烁红光或是方向盘震动等方案对驾驶者进行提醒。整个系统的硬件部分是由摄像头+集成座舱车机/域控制器解决方案组成;软件部分则主要涉及视觉加速算法。
1.2 异构编程模型设计
OpenCL 在高性能计算领域具有许多优势,而最重要的优势之一就是可移植性,允许使用多种加速器,包括多核CPU,GPU,DSP,FPGA 和专用硬件[9]。OpenCL 由三个模块构成:实现执行在OpenCL 设备上的内核程序的编程语言,定义和控制平台的应用编程接口和运行时系统。OpenCL 支持任务与数据两种并行化计算模式,很大程度上增强了GPU 的计算性能,其整体核心架构包括:平台模型,执行模型,存储模型,编程模型四种模型。基于OpenCL的异构编程模型设计如图1 所示。
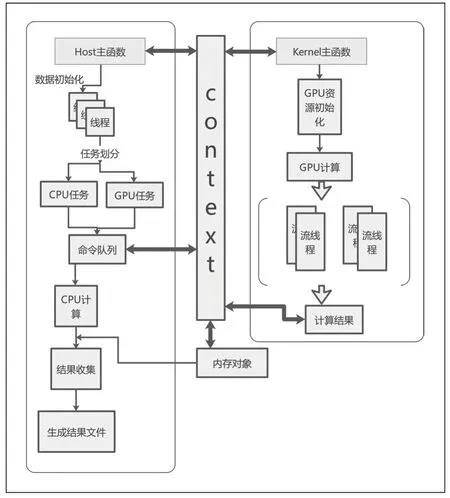
图1 基于OpenCL 的异构编程模型设计
在CPU+GPU 异构硬件平台上,通过OpenCL API 调用查询平台和设备属性,选择合适的平台和设备进行初始化。主机端创建上下文、命令队列,分配内存,并在主机与设备之间进行数据传输和计算。异构平台上,主机封装设备内存为内存对象以实现数据管理,通过命令队列向设备发送命令,使用上下文与设备进行信息交互。设备端实现并行算法核函数,创建程序对象执行内核,最后将设备执行的数据结果映射到主机内存,以生成最终的结果文件。
基于CPU+GPU 异构架构,将计算任务划分为块。CPU 负责任务调配、复杂逻辑处理和事务管理,GPU 处理简单逻辑、计算密集、大规模并行的任务。通过并发执行映射到CPU+GPU 多个计算单元的子任务,进一步细粒度划分模块以提高CPU 和GPU 的协同计算效率。
1.3 TVM 深度学习自动化端到端优化编译器
TVM 是一种编译器,支持计算图级和运算符级优化,能将深度学习任务映射到各种硬件原语,实现性能在不同硬件设备上的可移植性。通过机器学习方法解决高级算子融合和内存延迟等优化问题,并提出了基于成本建模的高效搜索方法,自动优化生成满足底层硬件特性的程序。
TVM 系统框架与执行流程如下:导入现有框架中的网络模型,转换为计算图,利用高级数据流对计算图进行优化。运算符级优化生成高效可执行代码,其中运算符的定义简化为使用张量描述语言宏观指定。TVM 结合用户设定的硬件目标将运算符映射到可能的代码优化集合,通过基于机器学习的成本模型在优化空间中搜索运算符的优化。最终,系统将训练得到的优化代码整合为可部署的编译运行时模块,包括优化处理的计算图、映射及搜索生成的运算符库和目标设备的运行参数。
2 实现与优化
2.1 性能模型的设计与实现
设计一种基于GPU 架构的自调优性能模型[10~11]。参数化影响GPU 程序性能的因素并确定取值范围,构建参数集合空间。通过在GPU 平台上配置所有可能的参数并测量实际的kernel 执行时间,从测试结果中选取最小值,对应于最优配置。首先,向Host 端主机内存输入并初始化数据。利用搜索空间优化算法选择一组最优参数配置。然后,将输入数据和kernel 函数的参数配置传输到Device 端显存内,初始化设备平台,并在GPU 上执行kernel 函数进行自调优。最后,将最优配置和实际执行时间返回到Host 端并输出结果。
基于GPU 架构的OpenCL 性能模型实现如图2 所示,分为两方面:一是从并行粒度出发,包括设置OpenCL 核函数中work-group 大小和每个线程处理任务量,workgroup 的维度根据具体应用确定。二是布尔型变量,评估GPU 平台的优化方法,如局部内存使用、循环展开、避免bank conflict 等,以确定这些优化方法对特定算法应用的有效性。
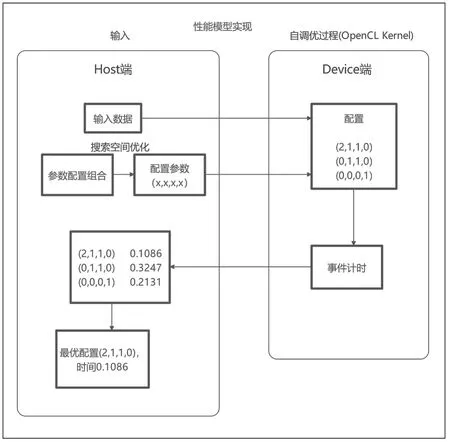
图2 基于 GPU 架构的自调优性能模型实现
步骤1:读取输入数据,对平台配置参数化;
步骤2:将输入数据从host 内存拷贝到device 的全局内存中;
步骤3:通过搜索空间优化算法选取参数配置,所选取的参数配置用来初始化OpenCL 核函数;
步骤4:在device 端执行kernel 函数,得出测试时间并将结果返回host 中;
步骤5:重复步骤3、4,直至遍历完全部的搜索空间;
步骤6:对所有测试时间进行排序,即可得出最小时间与最优配置。
2.2 YOLOv3 算法在异构计算的实现
在上文模型搭建完成的基础上,设计实现基于 OpenCL的 YOLOv3 视频图像识别算法的并行加速[12~13],根据用 C语言和 CUDA 编写的开源神经网络框架 DarkNet 项目,然后结合视频图像识别任务需求、硬件平台特征和 OpenCL编程模型,利用OpenCL 的可移植性,在异构系统上实现基于OpenCL 的YOLOv3 卷积神经网络算法模型。
使用并行编程模型OpenCL 设计规范实现算法,主机应完成OpenCL 平台设备选择,内存声明,建立上下文并创建命令执行队列等工作,为设备创建缓冲内存及内存对象,将数据从主机端缓存区发送到目标设备的缓存区。设备端应编写算法中需要并行化设计的内核代码,然后创建对应的程序对象并在设备上执行内核,在主机代码中,需要使用clSetKernelArg()设置内核参数,然后调用clEnqueueNDRangeKernel()划分安排NDRange 工作项和工作组的大小,调用OpenCL 内核函数启动内核。内核运行后得到的结果数据仍然存储在设备内存空间,主机需要将数据映射主机内存空间中,最后在设备任务执行完成后,由主机清理工作期间创建的内存缓冲区并关闭OpenCL 对象等。主机函数设计流程图如图3 所示。
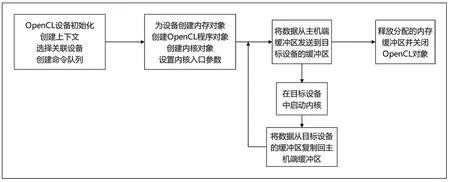
图3 主机函数设计流程图
本文基于clBLAS 库(OpenCLBLAS,基于OpenCL 内核的基础线性代数操作数值库),采用im2col 法将整个卷积过程转换为GEMM(通用矩阵乘法)过程实现卷积层内核函数。采用NDRange模式实现数据并行,利用系统的多级存储结构和程序执行的局部性来充分加速运算。
传统卷积计算的复杂度很高,需要7 层循环遍历图像batch 数、batch 大小、图像通道、图像尺寸、卷积尺寸。采用矩阵乘法的方式将卷积计算转化,将图像通道和卷积核按矩阵拼接,减少循环层数。通过OpenCL 执行模型中的单指令多线程(SIMT)特性,利用多个工作项同时计算,实现并行加速。
在二维卷积运算中,每个输出点的计算是独立且不依赖的,因此,通过将OpenCL 工作项一对一映射到输出点,可以轻松实现多输出点的并行计算。在卷积神经网络中,卷积层、批量归一化和激活函数层通常形成一个固定的结构。为了进一步优化数据流,采用算子融合,将固定结构的计算集中处理,减少数据移动和内核启动关闭带来的额外性能开销。下面为卷积计算convolutional_kernels_cl.cpp 函数设计:

2.3 基于TVM 的加速优化设计实现
为了描述算法模型中计算操作指定的张量输出大小以及每个元素的计算表达式,TVM 采用一种张量描述语言来描述张量在索引空间中的每个操作,张量描述语言不仅支持常见的数学运算表示,而且实现了常见的深度学习运算符的表示。借用Halide 将计算算法和调度逻辑进行抽象并分离的思想优化神经网络算子,然后采用一些搜索算法来找到较优的调度方案,从而自动生成最终的执行代码。其中Halide 是C++实现的图像处理领域的领域专用语言(DomainSpecifiedLanguage,DSL)。它的特点是实现了图像算法的运算(包含函数及表达式),这些运算在计算硬件单元上以函数为单位进行可分离性的调度。
2.3.1 TVM 运行环境搭建
在异构平台上构建TVM 运行环境,运行系统为Windows10 x64,由于TVM 需要将张量表达式映射到特定的低级代码以便部署在异构平台上,因此需要采用低级编译器中间表示(IR),准备visualstudio2017,CMake。由于TVM 在CPU 平台的编译会依赖LLVM,下载LLVM source code 和Clang source code 并使用CMake 编译,再添加到系统路径下配置系统环境变量,配置CUDA 及OpenCL。
接下来安装TVM,从GitHub 上下载整个安装包,修改tvm 源码下面的CMakeLists.txt,把USE_LLVM、USE_OPENCL、USE_CUDA 等设置修改为ON。使用CMake 编译生成tvm.sln,打开tvm.sln,确认编译的平台和版本release x64,编译成功后,获取Windows 动态库libtvm.dll,libtvm_topi.dll, 进 入tvm/python,tvm/topi/python,运行pythonsetup.pyinstall,安装成功便可以导入tvm 包文件。
2.3.2 YOLOv3 模型优化部署
使用TVM 进行模型部署的完整流程:
(1)导入DarkNet 深度学习框架的YOLOv3 模型,以实现计算图 iR(中间表示)的转换。
(2)对原始计算图中间表示(IR)进行计算图优化,得到优化的计算图。
(3)对计算图中的每个计算操作用张量表示描述语言描述的张量计算表达式,并针对异构硬件平台,选择最小计算原语生成具体的调度。
(4)使用基于成本模型的机器学习自动优化器生成经过优化的特定的低级代码。
(5)生成特定于硬件设备的二进制程序。
(6)构建异构平台可部署的模型。
训练好的模型编译为TVM 模型,TVM 模型由deploy.dll、deploy.json、deploy.params 三个文件组成。将生成的TVM 部署库文件deploy.dll 添加到动态链接库,deploy.json、deploy.params 作为资源文件加入工程项目中。部分核心代码代码如下:

3 实验结果与分析
本文分为三组实验组进行对比实验,实验组一从MagicData 发布的开源DMS 驾驶员行为数据集中随机抽5000 张图,划分为5 个图片集,将准备好的每组测试集图片的路径全部存放在一个txt 文件里建立测试文件,修改detector.c 文件,在异构平台上用GPU+CUDA cuDNN 库执行批量测试,重新make Darknet 框架,进行五次重复测试,并记录图片识别推理时间,得到原模型在 GPU 并行运行的性能数据,该实验为基准实验组。
实验组二将YOLOv3 算法移植到基于 OpenCL 的异构平台上实现优化卷积计算过程,融合卷积层+批量归一化+激活函数层固定的组成结构,在主机函数和内核函数设计实现过程中运用循环展开、向量化、数据重排、多线程并行和内存访问优化等运算并行化策略,同时将计算负载合理分配给 CPU 和 GPU,通过 OpenCL 实现异构并行计算并解决移植性问题。基于 OpenCL 的异构并行编程模型,在CPU+GPU 异构计算平台上运行 YOLOv3 算法模型,得到手动优化算法模型运行性能数据。
手动凭借经验在异构平台对算法模型优化设计,存在局限性,无法实现全局最优以及负载均衡,对于算法的优化,涉及高性能张量分解,数据布局,低开销负载平衡调度,内存分配、通信、同步等多重优化方案。引入TVM 自动优化算法模型,并面向目标平台编译生成部署代码。以实验组一和实验组二为参考,在实验组二算法实现的基础上植入TVM 的 CPU/GPU 自动编译优化部署运行测试,得到测试结果。对比结果如表1,图4 所示。
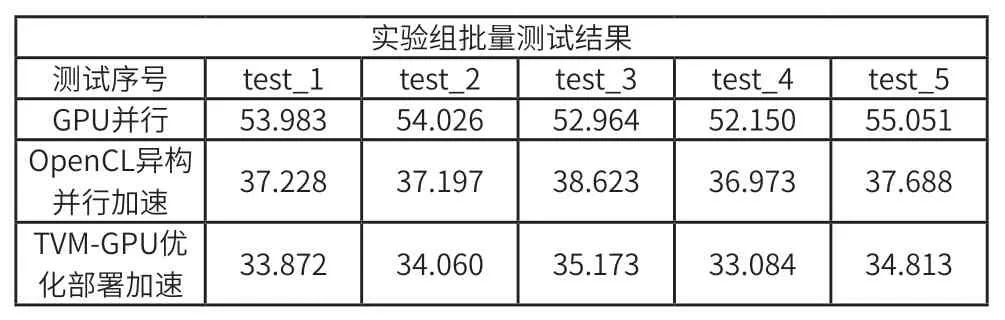
表1 优化对比实验
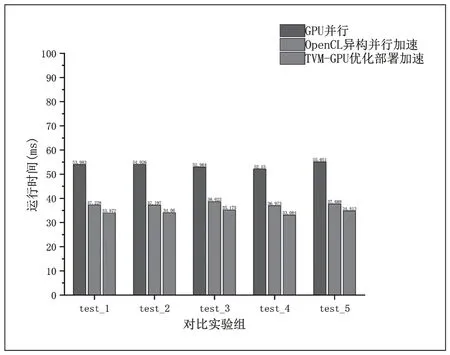
图4 优化对比实验结果
通过实验数据结果,计算三个实验组的平均时间分别53.635(ms)、37.542(ms)、34.200(ms),实验表明 YOLOv3 算法在基于OpenCL 的 CPU+GPU 异构计算平台上相对于GPU 加速比达到 1.42。TVM 优化部署在GPU加速比达到 1.56,并且相对于手动优化也能达到1.10 的加速比。结果表明,本文提出的基于OpenCL 异构平台的视频监控图像处理加速方案和自调优化编译方法具有可行性和有效性,突破了原算法的应用平台局限性,有利于与其他设备扩展结合及移植且自动编译优化方案可快速部署在各种设备端。

4 结束语
本文主要从汽车智能化的驾驶员监控系统实际应用出发,构建了OpenCL 框架下的自调编程模型和TVM 优化编译器以及算法研究,利用 OpenCL 在基于GPU 的异构计算平台上实现视频图像识别 YOLO 算法的并行化加速,并进一步结合TVM 进行自动编译优化部署,完成了三个对照组实验,结果表明相较于基准对照实验,植入YOLOv3 算法的OpenCL 异构并行编程模型的加速比能达到1.42,基于TVM 优化部署后加速比能达到1.56。表明本文提出的基于异构平台的图像识别加速方案和基于 TVM 的端到端自动优化编译方法具有可行性和有效性,且OpenCL 框架突破了原始基于 CUDA 的应用平台局限性,利于与其他设备扩展结合及移植且自动编译优化方案可快速部署在各种设备端。
