融合密度和划分的文本聚类算法∗
2024-04-17蔡林杰
刘 龙 刘 新 蔡林杰 唐 朝
(湘潭大学计算机学院·网络空间安全学院 湘潭 411105)
1 引言
近几十年来,随着计算机技术的快速发展,人们获取的信息和采集的数据越来越多,但是海量的数据缺乏有效的处理,人们就很难得到有效且有用的信息。基于此种情况,作为数据挖掘的一种有效工具,聚类算法[1]可以帮助人们高效分析数据之间的关系。
本文研究文档聚类[2],文档聚类的首要任务是文本向量化,将文档转换为高维向量再进行聚类。2013 年,谷歌推出了基于神经网络训练的Word2vec[3]词向量模型,极大地促进了自然语言处理的发展;谷歌在2018 年再次发布了基于深度学习的BERT[4]模型,该模型刷新了自然语言处理领域中多个方向的记录。
文档聚类的核心任务是研究聚类算法,但是密度聚类算法[5]在高维数据集上的表现非常差。划分算法中的K-均值算法[6]效果一般,主要原因是算法的初始化[7]是随机生成的。近年来,为了克服选取中心点为离群点,李武等[8]提出一种启发式算法来逐步选取初始类中心点,选取的原则是初始类中心点差异度高且与其他初始类中心点差异度高,实验表明该算法聚类效果正确率高,收敛速度快。贾瑞玉等[9]提出利用局部密度和决策树来确定K-均值算法的类簇中心点的数量和位置,该方法可以有效地排除特殊点,在低维上有着不错的效果。王思杰等[10]提出基于距离的离群点检测技术,对中心点进行筛选,避免离群点成为中心点。张国峰等[11]提出逐步选取类簇中心点,在更新中心点的同时判断簇点的合理性并及时做出修改,这种方法确保了不会出现空簇。Rodriguez等[12]在Science上提出了一种新的密度聚类算法,该算法的思想是聚类中心的密度高于其邻近的中心且距其他高密度点相对较远。
本文使用BERT 模型来处理文本向量化,并且与其他方法进行实验比较,BERT 模型的确具有出色的性能。本文还提出了一种结合密度和划分的文本聚类算法,与其他几种聚类算法相比,该算法对高维数据集具有更好的聚类效果。
2 相关工作
2.1 文本向量化表示
文本聚类一个重要过程就是文本的向量化。文本向量方法有传统的向量空间模型[13](VSM)和Word2vec 方法,两者需要结合文本特征提取TF-IDF[14]方法来进行文本聚类。Word2vec 方法优点是简单、快捷、易懂,但也存在着比较严重的问题,它非常依赖语料库,需要选取质量较高且和所处理文本相符的语料库进行训练。
本文使用BERT 模型来处理文本的向量化,BERT 模型作为Word2vec 的替代者,它的网络架构使 用 了 多 层 带 有Attention[15]的Transformer[16]结构。本文使用的是BERT-Base 中文模型,模型有12 层Transformer 编码器,隐藏层的维度是768,自注意头的个数为12,其中BERT 模型中一个Transformer编码器的计算过程如下:
1)文本向量:通过词向量化将单词变成向量x1、x2…xm,文本向量X的维度是m×768,m为句子的最大分词数;
2)计算Q、K、V:这里我们通过模型的参数WO、WK、WV结合输入向量X来计算出来向量Q、K、V:
3)单头自注意力层的输出矩阵Z:这里首先计算词在上下文中的意义以及词之间的影响QK,得到之后进行归一化处理,最后加权平均得到单头注意力层输出矩阵Z:
4)融合所有注意力头信息的矩阵Zsum:BERT模型使用了12个注意力头,经过步骤3)后,我们可以得到12 个不同的Z 矩阵,乘上附加的权重矩阵WO可得到Zsum,Zsum的维度为m×768,最后经过残差连接和求和归一化即为下一层下面Transformer 编码器的输入。公式中concat(Zi)表示为12 个注意力头输出矩阵的拼接:
2.2 文本距离计算
文本聚类过程中需要计算文本间的差异,本文使用欧氏距离来计算文本距离,欧氏距离可以有效防止过拟合,还可以让距离优化求解快速和稳定。文本距离计算公式如下:
注:D(X,Y)表示文本X与文本Y的欧氏距离。该值越小代表着两个文本属于同一类别的可能性越高。反之,该值越大则说明文本相似度越小。xi与yi分别表示文本X、Y的某一向量维度值。
3 文本聚类算法
3.1 K-means算法
K-means算法属于划分聚类算法,该算法是将数据集n个数据对象划分成K类,其具体步骤是:
1)任意选择K 个样本点当做初始类中心点,每个初始类中心点作为一个聚类中心;
2)对于数据集中的所有样本点,计算其与每个聚类中心的距离,将其归为距离最近的聚类中心类簇;
3)将各个类簇样本点的均值作为该类簇新的聚类中心,得到新的K个聚类中心;
4)重复步骤2)~3),并在每次迭代后计算是否满足停止条件,若达到条件之一,则输出结果。
K-means算法的停止条件一般为以下三种:聚类中心与前一次聚类中心相差极小;重新划分给其他类簇的样本点极少;目标函数极小,即数据集的误差平方和(SSE)局部最小。误差平方和计算如式(7)至式(8)所示:
注:SSE 参数计算表示当前的聚类情况的所有样本点到各自划分类的聚类中心的距离总和,这个值越小表示当前的聚类效果越好。K表示聚类类别。Ci表示单个类簇,共K 个类簇。p 表示样本点向量。mi表示类中心点向量,是类Ci的均值向量,也称质心。x表示类簇Ci中的向量。
3.2 K-means++算法
K-means++算法[17]主要解决K-means 算法受初始化影响大的问题,在选择初始类中心点方面做了改进,保证初始点足够离散。算法初始化类中心点的具体步骤如下:
1)任选某一样本点当做初始类中心点;
2)计算其余样本点与最近初始类中心点的距离,用D(x)表示;
3)通过样本点的D(x)来表示其成为初始类中心点的概率P;
4)最后轮盘法选择出下一个初始类中心点;
5)重复步骤2)~4)直至得到K 个初始类中心点。
关于K-means++算法的初始化过程中参数D(x)和P,D(x)为文本向量的欧氏距离,具体计算见式(6),概率P计算如式(9)所示:
K-means++算法的初始化有效地改善了随机初始化的不稳定性,选取下一个聚类中心点的概率与距离挂钩,使得初始类中心点离散。
3.3 最大距离法
2014 年,翟海东等[18]提出使用最大距离法来选取初始类中心点。采用最远距离的逐步选取类中心点,最大距离法选取类中心点流程如下:
1)计算n 个样本点两两之间的距离,找到满足D(c1,c2)≥D(ci,cj)(i,j=1,2,…,n)的两个样本点c1和c2,并将它们作为两个初始类中心点;
2)在剩余的(n-2)个样本点中,选取满足D(c1,c3)×D(c2,c3)≥D(c1,ci)×D(c2,ci)的样本点c3,将c3 作为第三个初始簇中心,ci 是除c3 外的任一样本点;
3)依此类推,直至选取K个中心点。
最大距离法属于K-means++算法的优化,聚类的初始化簇中心点确实有效地囊括所有数据,促使所选中心点的分布离散且合理。但是该方法极易选中离群点,导致聚类效果不理想。关于此类方法,还有基于子空间的K-means++优化算法[19]和K-meansⅡ算法[20]。
3.4 融合密度和划分的聚类算法
本文提出了一种结合密度和划分的文本聚类算法(CDP 算法)。首先通过距离计算来定义样本点的密度,然后通过密度来选择适合作为中心点的样本,然后通过最远距离方法逐渐选择初始聚类中心点,最后根据距离对整个数据集进行划分。算法具体步骤如下:
1)使用文档距离计算模型计算n 个样本集两两之间的距离dij;并计算所有样本之间的平均距离dc,给出dc计算如式(10)所示:
2)根据样本之间距离与样本平均距离大小计算出每个样本的密度ñi,并计算所有样本的密度ρi,给出ρi和ρc计算如式(11)~(13)所示:
3)将所有满足ρi>ρc的样本点归入适合作为初始类中心点集合M,核心点集M 的个数m 必须满足n>m>K;
4)在M 集合中随机选取一点c1 作为初始类中心点;
5)在(m-1)个点中,选择满足D(c1,c2)≥D(c1,ci)的样本点c2,ci是M集合中除c2的任一点;
6)在(m-2)个点中,选择满足D(c1,c3)×D(c2,c3)≥D(c1,ci)×D(c2,ci)的样本点c3,ci 是M 集合中c3的任一点;
7)依此类推,直至得到K个初始类中心点;
8)根据距离计算将所有样本点分配至与其相距最小类簇里;
9)重新计算中心点,类簇中全部样本的均值就是新中心点;
10)重复步骤8)~9),直至数据集的SSE目标函数不变或者变化极小。注:dc表示截断距离,即文档数据集的样本平均距离,计算数值是每一个文档与其他文档之间的文本距离总和平均化后得到的数值,当数据集确定后,该值为常数。ρi表示为单个文档Xi的密度,若两个文本的文本距离若小于样本平均距离dc,说明两个文本距离较近,即文本相似度较高,文档Xj在文档Xi的密度领域内,该值越大说明文档Xi的附近点越多。ρc表示截断密度,计算数值是所有文档的密度平均值,当文本集确定后,该值也为常数。
4 实验
4.1 数据集
本文实验使用的数据集来自清华大学的的THUCNews 新闻文本分类数据集,THUCNews 数据集是根据新浪新闻2005~2011 年间的历史数据筛选过滤生成,包含74 万篇新闻文档,均为UTF-8 纯文本格式。此数据集在原始新浪新闻分类体系的基础上,重新整合划分出14 个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐。该数据集的每篇文档所包含的字数在300~5000之间。
4.2 评估标准
此次实验使用的评判标准主要是F1 值,其次还有文本聚类耗时T。F1 值由精确率P(precision)和召回率R(recall)的计算得到,精确率P 值为所有“正类判定为正类”占所有“检测是正类”的比例,召回率R值是所有“正类判定为正类”占所有“样本是正类”的比例。P、R、F1 值的计算如式(14)~式(16),其中,TP表示“正类判定为正类”,FP表示“负类判定为正类”,FN表示为“正类判定为负类”。
4.3 实验对比
4.3.1 文本向量化实验
本次实验目的是测试不同的方法处理文档向量化的效果。实验数据集是5 类文档集,每一类文档集有300 篇文档。实验首先使用不同方法将文档转为向量,然后使用传统的K-means算法对文档向量集进行聚类,将聚类的结果作为评判标准,实验仅文档向量化处理过程不一样,其他均一致。实验的两种文档向量化处理方法分别是BERT 模型、Word2vec。实验结果如图1所示。
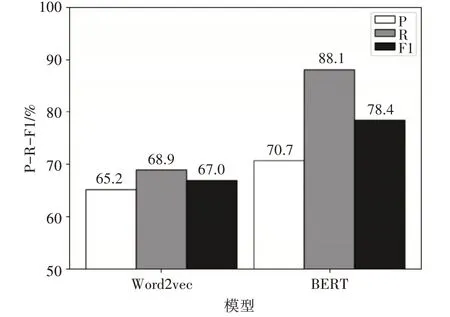
图1 Word2vec与BERT关于文本向量化处理对比图
从实验结果可以看到在P、R、F1 值上,BERT均领先Word2vec,在F1 值上提高超过10%。在文档向量化处理效果上,BERT 模型要优于Word2vec方法。
4.3.2 文档关于类别数量变化实验
本次实验目的是测试聚类效果关于文档类别数量的变化。对比实验分成两类:K-means 算法、本文提出的CDP算法。每一类分成七组试验:第一组实验的数据集包含3 类,每一类100 篇共300 篇文档;第二组实验的数据集包含4类,每一类100篇共400篇文档;以此类推,第七组实验的数据集是9类共900篇文档。每一组实验均采用BERT模型处理文档向量化,每组实验过程一致,仅实验数据集不一样。聚类指标随类别数量变化如图2所示。

图2 聚类指标随类别数量变化图
实验结果中,红色线数据为K-means 算法,采用随机化初始化,蓝色线数据为CDP算法。从实验结果可以知道文档聚类的F1 值会随着文本类别的增加而降低,当K值较小时,F1值很高,当K值增加时,F1 值逐渐降低。使用CDP 算法后,聚类效果更好且稳定,在聚类类别小于10时,文档聚类的F1值一直超80个百分点。
4.3.3 文档关于文档集数量变化实验
实验三:本次实验目的是测试聚类效果关于文档数据集数量的变化。对比实验分成两类:K-means 算法、CDP 算法。每一类分成六组对比实验,每组实验都是5 类文档,只有文档数量不一致,实验分别对每组进行聚类取平均值:第一组实验包含5 类,每一类100 篇共500 篇;第二组实验包含5类,每一类200 篇共1000 篇;以此类推,第六组是5类共3000 篇文档。每一组实验均使用BERT 模型处理文档向量化,实验过程一致,仅实验数据集不一样。聚类指标随文档数量变化如图3所示。
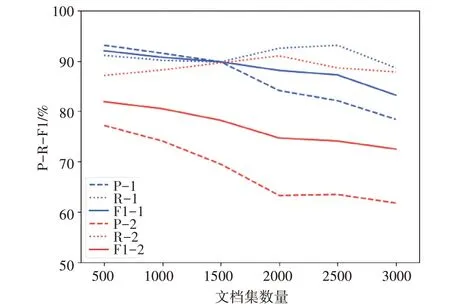
图3 聚类指标随文档数量变化图
实验结果中,红色线数据为K-means 算法,采用随机化初始化,蓝色线数据为CDP算法。实验表明在文本类别不变的情况下,文档的数量增加也会导致聚类的F1 值下降。数据显示在K 值不变的情况下,两类对比实验的召回率R 值都在90%左右变动,精确率P 随着文档数量的增加而逐渐下降,从而导致F1 值的下降。说明文档聚类会随着文档集数量增加而降低,两类对比实验的F1 值下降程度都较为稳定。
4.3.4 综合对比实验
实验四:本实验选择两组数据,第一组为5 个类别,每个类别100 篇共500 篇文章;第二类是5 个类别,每个类别有400篇共2000篇文章。测试算法有5种组合:算法1是一种传统的K-means算法,使用Word2vec 做向量化处理;算法2 是K-means 加BERT 来处理文本向量化;算法3 是K-means++算法加BERT 来处理文本到向量的算法;算法4 是最大距离法(MDM)加BERT 处理向量化;算法5 是本文提出的CDP 算法,并结合BERT 处理文本向量化。每组实验数据集均一致,采用5 种算法,最后多次实验取均值作为实验结果。第一组实验结果如表1,第二组结果如表2。
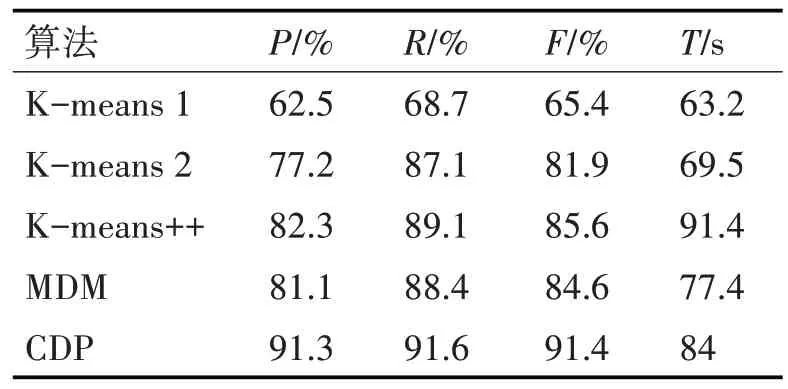
表1 综合实验一
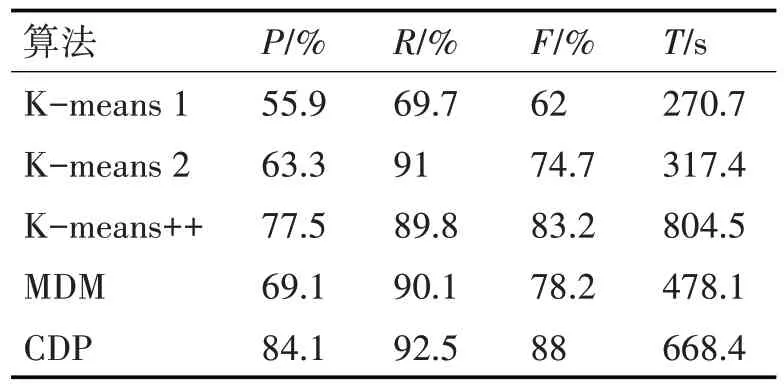
表2 综合实验二
根据表1 和表2 的数据,比较算法2、3、4 和算法5,可以判断CDP 算法在准确率P 和召回率R 方面均有提升,其F1 值高于其他三种算法;但是该算法耗时较多,原因是需要计算文档数据集的密度。由算法1、2 可知,BERT 模型在处理文本转向量方面更加优秀。算法1 和算法5 的比较表明,与传统的K均值文本聚类相比,本文提出的CDP聚类算法有很大的进步。
4.4 实验结论
结合以上实验,在文档数据集上,使用BERT模型对文本进行向量化转换,极大地提高了文本聚类效果。在此基础上,本文提出的融合密度和划分的聚类算法进一步提升了文本聚类效果。实验表明,本文提出的融合密度和划分的文本聚类算法与传统的K 均值文本聚类算法相比,将F1 值提高超10%,效果显著且稳定。
5 结语
本文使用BERT 中文模型处理文档向量化,并使用新提出的融合密度和划分的聚类算法进行文本聚类。与传统的文本向量化处理相比,BERT 模型在处理文档向量化方面更为出色;提出融合密度和划分的文本聚类算法在文档聚类问题上有着优秀的表现;但该算法也有一些缺点,聚类类别的增加或文档数量的增加将导致文本聚类的效果略有下降,并且文本聚类将花费较多时间。
