基于多尺度特征融合的YOLOv3 行人检测算法∗
2024-04-17黎国斌王等准扈健玮林向会谢本亮
黎国斌 王等准 张 剑 扈健玮 林向会 谢本亮
(贵州大学大数据与信息工程学院半导体功率器件可靠性教育部工程研究中心 贵阳 550025)
1 引言
行人检测技术以往是人工提取特征,例如SIFT[1]、LBP[2]、SURF[3]、HOG[4]以及Haar[5]等特征描述因子,提取行人特征后输入分类器中进行学习,传统的分类器有adboost[6]或者SVM[7],最后输出分类的结果。YOLOv3[8]作为一阶段检测算法,略去区域候选框过程,在保证检测性能的同时提升检测速度,该算法摒弃以往仅仅利用最后检测层进行单尺度输出,而是同时输出三种尺度的目标,更适合本文研究的内容,所以本文使用YOLOv3 作为基准算法。
行人检测是一种特殊的目标检测算法,只是检测目标限定于行人。图1 是Caltech[9]行人检测数据集的统计图。

图1 Caltech数据集行人尺度统计图
由上可知,行人大小尺度分布不均匀,行人尺度主要分布在50 像素以下。在现实生活中,由于道路行人与车载成像设备之间的距离不同,成像后行人尺度差距十分显著,因此,本文在YOLOv3 算法基础上,改进特征提取网络,引入多尺度特征融合模块至残差单元中,替换原来仅仅是两个卷积层堆叠的残差单元。改进后的残差单元,可以将不同尺度的特征进行融合,那么多个残差单元堆叠就可以进一步融合更多不同尺度的行人特征,提高网络对不同尺度特征的提取能力。
2 相关工作
特征融合在目标检测算法中是非常常见的,特征 融 合 有 很 多 种 方 式,例 如ResNet[10]的 跳 连 接(skip connection)、FPN[11]的长连接(long connection)、Inception[12]中同层不同分支间特征拼接或者按像素相加进行特征融合。
针对不同尺度不同语义的特征,Yimian Dai等[13]提出多尺度通道注意力模块(MS-CAM)。多尺度通道注意力模块结构图如图2所示。

图2 多尺度通道注意模块结构图
输入X分别通过全局和局部分支,全局分支依次通过全局平均池化层得到C×1×1 特征,接着输入到深度可分离卷积得到C/r×1×1 特征,随后输入到批量归一化(BN),非线性激活函数(Re-LU),再通过深度可分离卷积得到C×1×1 特征。同理,局部分支除去全局平均池化操作外,其他与全局分支相同。最后将全局的语义信息和局部的特征信息进行相加,通过激活函数(Sigmoid)将特征信息权重限定在[0,1],最后与原特征X相乘得到调整后的特征X′。MS-CAM 仅仅是单输入,难以融合不同层的特征,因此将浅层特征X深层特征Y、多尺度通道注意力模块结合一起,构造成多尺度特征融合模块(AFF),AFF 网络结构图如图3所示。
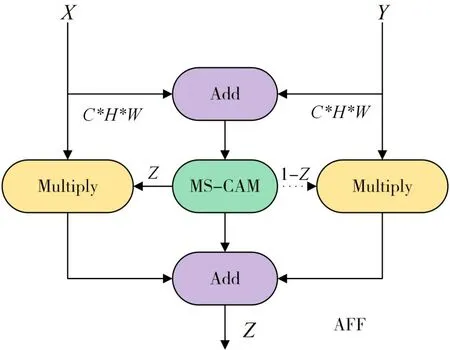
图3 多尺度特征融合模块
X为浅层特征,Y为深层的特征,特征图的宽为W,高为H,通道数为C。X和Y相加得到的特征,继续通过MS-CAM,得到两个分支,左分支是特征融合后的权重,并且局限在0到1之间,而右分支是通过全1 矩阵减左分支的值得到的,右边权重也是限定在[0,1],随后左右分支分别与原特征进行矩阵乘法运算,得到的结果进行相加运算得到最后的输出Z∊RC×H×W,即得到的Z是浅层细粒化特征与深层语义信息融合后的特征。
3 本文算法
本文算法分三个小节进行阐述,首先简述本文改进算法的结构设计、其次阐述改进算法的训练过程、最后针对改进算法的实验环境及结果做进一步的分析。
3.1 本文算法结构设计
为了实现不同尺度行人的检测,本文在YOLOv3 算法的特征提取网络中引入多尺度特征融合模块,改进前的残差单元结构图如图4。
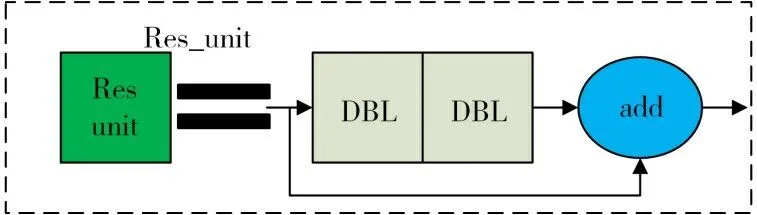
图4 改进前的残差单元结构图
将原输入x、x经过连续两个DBL卷积层得到的特征y、x与y相加得到的特征w,x表示浅层特征,y表示深层特征,改进后的残差单元结构如图5所示。

图5 改进后的残差单元结构图
浅层特征x与左分支权重z相乘得到浅层调整后的特征,深层特征y与右分支相乘得到深层调整后的特征,然后将调整后的特征相加得到最后输出。将改进Res_unit 替换YOLOv3 中的Res_unit,其他网络结构不变。
3.2 网络模型训练设计
由于两个阶段的学习率不一样,模型更新步伐不同,第一阶段将学习率调大,可以加快模型训练,第二阶段调小学习率,可以更好地找到全局最优解,所以模型训练过程分为两个阶段,第一阶段实验超参数设计如表1所示。
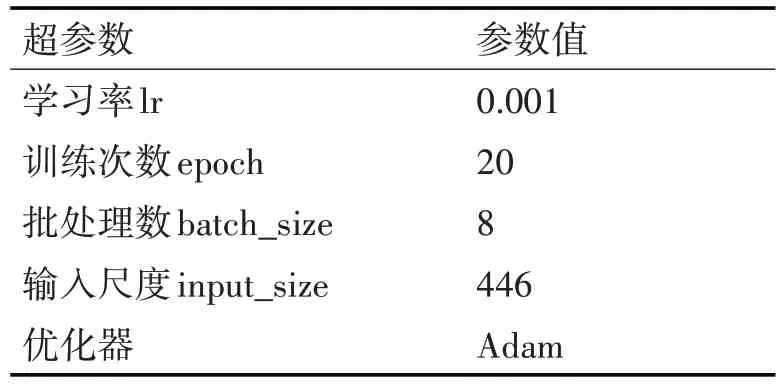
表1 第一阶段实验超参数表
第二阶段学习率调整为0.0001,训练次数epoch设置为10,其他参数与上相同。
模型训练,训练与验证集比例为7∶3,并随机打乱训练集。网络训练的最终目的是保存最佳的权重参数,而权重更新的方法很多,本文使用学习率自适应二阶优化方法Adam(Daptive Moment Estimate)。该优化方法可以自适应地调整学习率,并且适合处理不平稳的目标函数,计算效率高且内存需求小,正好适用于行人检测数据集。
3.3 本文实验结果与分析
3.3.1 实验配置与数据集
本文实验环境分为两部分,其一是本地调试程序使用的个人计算机运行平台,其二是实验室搭建的英伟达(NVIDIA)GPU 服务器。个人计算机运行平台软硬件环境配置如表2所示。
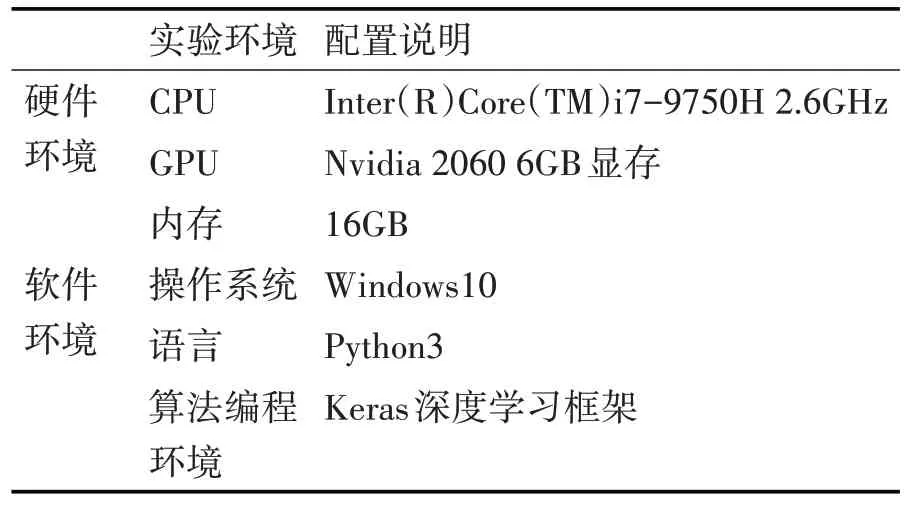
表2 本地调试程序个人计算机软硬件环境
服务器软硬件配置如表3所示。

表3 服务器软硬件环境配置
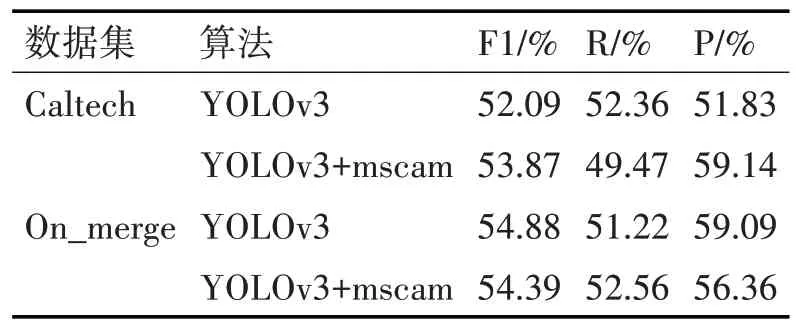
表4 改进算法在Caltech、On_merge数据集训练的测试结果
本文实验使用的数据集共2 个,分别为Caltech和On_merge数据集。选择set00-set05 作为Caltech训练集,共有67020张训练图片。On_merge数据集包含Caltech 训练集、Cityperson[14]训练集、验证集,共有69663 张训练图片。由于Caltech 数据集中存在部分错标漏标的情况,本次实验的测试集选用set06 中部分数据集,测试集经过调整后,测试图片数量为2059张。
3.3.2 实验结果与分析
替换Darknet53为引入多尺度特征融合模块的特征提取网络,其他网络结构与YOLOv3 一样。经过实验,得到如图6~7所示PR曲线图。

图6 Caltech数据集精准率-召回率曲线图

图7 On_merge数据集精准率-召回率曲线图
从图6、7 知,改进算法(YOLOv3+mscam)的平均精准率比基准算法高,并且在On_merge 数据集的平均精准率都比基准算法高,进一步说明改进算法的有效性。On_merge 数据集包含Caltech 和Cityperson数据集,模型泛化能力更强。
YOLOv3+mscam 表示引入多尺度特征融合模块的YOLOv3 算法,分别在Caltech、On_merge 数据集进行训练,测试得到的结果;R 表示召回率,P 表示精准率。从表5、6 可知,对于Caltech 数据集,YOLOv3+mscam、YOLOv3 在置信度分别等于30.79%,26.4%取得上述F1系数、召回率、精准率以及平均精准率。YOLOv3+mscam 的平均精准率比基准算法高出其5.49%,F1调和系数比基准算法高出其3.42%,精准率比基准算法高出其14.1%。
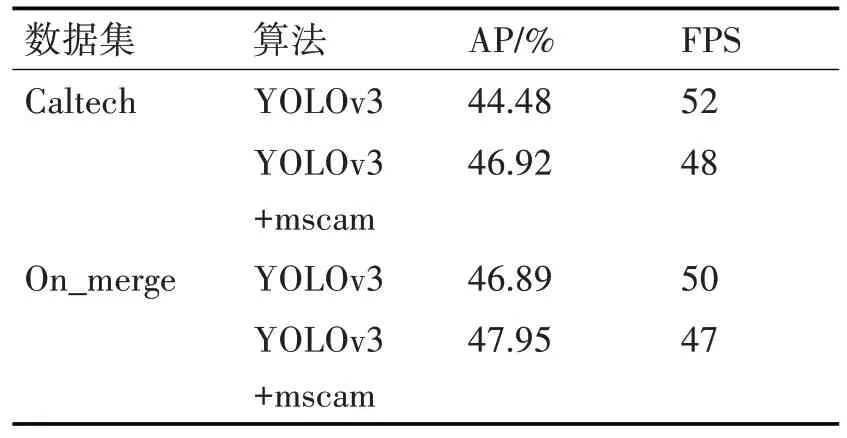
表5 改进算法在Caltech、On_merge数据集训练的测试结果
取得上述性能提升的主要原因是引入了多尺度特征融合模块,并且是引入到残差单元(ResNet)内部,依然保持残差连接特性,即增加网络深度的同时不会引起梯度消失的问题。增加特征提取网络的深度,进一步提升特征提取网络的非线性表达能力,增强网络对行人特征的提取能力。
此外,多尺度特征融合模块内部融合通道域注意力机制,融合全局与局部的信息,可以更好判别行人特征信息,降低假阳性率,在通道域注意力机制的引导下,网络增加行人特征对应通道的响应权重,降低背景等无关信息对应通道的响应比例,因此网络可以更加倾向行人可见特征信息,降低行人特征信息以外等无关信息的干扰,更多有用行人特征信息参与网络训练,网络对行人的识别能力也进一步加强。
由图3 可知,多尺度特征融合模块外部改变为双输入,一输入为浅层的特征、另外一输入为残差学习后的特征,两输入相加后的特征信息输入至多尺度通道注意力模块,得到两个特征比例权重,浅层特征、残差学习后特征分别与各自比例权重相乘得到各自调整后的特征,最后将调整后的特征相加输出,经过多级特征融合的残差单元级联,可以更好地融合不同尺度行人的特征信息,从而提高行人检测的性能。
为了更直观理解改进算法的模型参数,基准算法与改进算法的模型参数如表6。
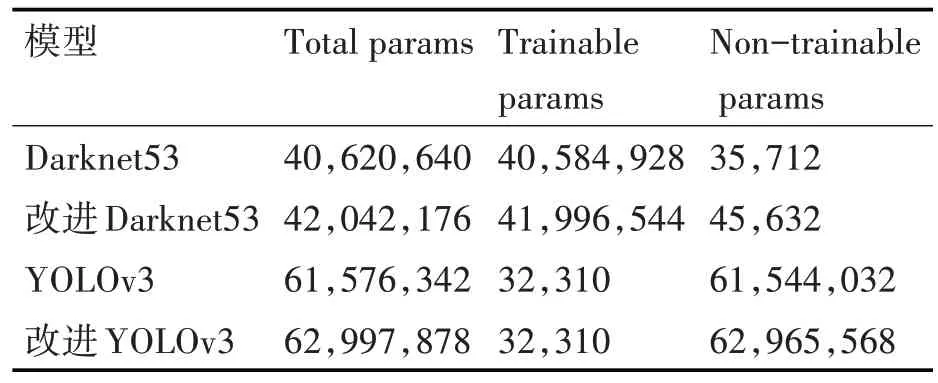
表6 模型参数对比表
虽然改进算法在特征提取网络引入别的网络层,但总体的计算量增加不大,改进算法在Tesla V100 的FPS 为48,基准算法的FPS 为52,都能满足检测实时性要求。
为了更直观地理解改进算法的有效性,改进算法与基准算法的检测效果图如图8~9所示。

图8 改进算法检测效果全图

图9 改进算法检测局部放大图
红色框代表基准算法的检测结果,绿色框代表改进算法的检测结果,从图8、9 知,基准算法对于距离较远的小尺度行人存在漏检,而改进算法可以完全框出图像中的行人。
为了验证改进算法的有效性,将改进的算法在On_merge 训练集进行训练,经测试得到表4 与表5结果。YOLOv3+mscam、YOLOv3 在置信度分别等于33.81%,34.28%取得上述F1 系数、召回率、精准率以及平均精准率。YOLOv3+mscam 的平均精准率比基准算法高出其2.26%。进一步说明改变原来特征提取方式,替换为带多尺度特征融合模块的特征提取网络,可以提升不同尺度行人的检测性能。
红色框是基准算法,绿色框是改进算法,从图10、11 得知,改进算法的检测效果更佳。基准算法对较小尺度行人存在漏检,改进算法可以很好地拟合小尺度行人。

图10 改进算法检测效果全图

图11 改进算法检测局部放大图
4 结语
在行人检测技术中,行人大小尺度问题比较常见,一直也是行人检测的难点。由于行人与成像设备间的距离不同,导致行人大小尺度不一问题尤为显著,本文针对行人大小尺度问题,提出基于多尺度特征融合的YOLOv3 行人检测算法。由于YOLOv3 的特征提取网络Darknet53 引入了残差连接,那么在残差单元里引入多尺度特征融合模块,改变特征的提取方式,将浅层特征和经过残差学习的深层特征进行融合,融合后输入多尺度通道注意力模块,可以同时关注行人的全局信息和局部信息,并更加关注行人的有用信息,降低无用信息对网络的干扰。最后在Caltech 数据集和Cityperson 数据集上进行消融实验,上文也统计Caltech 数据集中的行人尺度,行人尺度分布广泛,小尺度行人尤为显著,提高不同尺度行人检测性能,为后续行人重识别[15]、行人跟踪等领域的研究奠定坚实的基础。
