面向大规模AI 数据流的接入算法和调度机制∗
2024-04-17王季喜陈庆奎
王季喜 陈庆奎
(上海理工大学光电信息与计算机工程学院 上海 200093)
1 引言
物联网作为一种信息技术,其目标就是通过传感设备将现实世界中几乎所有对象进行网络连接,从而实现万物互联互通[1]。随着人们对科学的不断探究,大规模终端设备的感知系统产生规模庞大的数据,物联网进入大数据时代[2~3]。近年来,人工智能[4]技术加速落地,人们开始运用物联网构建新型智能感知系统。在“万物智联”时代,将智能计算任务向边缘部署成为了人们的研究热点。如在智能终端部署老人姿态识别的深度学习模型,对老人姿态进行识别。目前,基于视频、图像的AI 任务不仅需要传输大量的数据,还需要较强的设备计算能力。为降低边缘数据中心带宽压力,充分利用终端设备的计算能力,AI模型分层计算的方法被提出[5~6]。根据终端设备计算能力,将OpenPose 深度学习网络模型[7]拆分为两部分。其中,部署第一部分AI分层模型的智能终端对老人姿态视频流预处理,提取视频帧特征信息称为AI 数据单元,同一前端设备基于时间序列上的AI 数据单元汇集成AI 数据流;GPU服务器利用第二部分AI分层模型对AI数据流进行深入特征提取,从而识别老人姿态变化,对异常姿态进行报警。
在老龄化日益严重的今天,对老人的异常姿态识别成为社会常态,AI 分层模型将被大量部署在智能终端。大规模AI 数据流涌入远端服务器集群将严重影响系统性能。为了充分发挥集群系统性能,提供可靠的并行AI 数据流接入服务,设计高效的AI数据流接入算法和调度机制变得格外重要。
2 相关工作
随着人工智能的边缘化,用于“边缘计算”[8]的智能终端设备规模增加,大规模AI 数据流并发接入系统面临诸多挑战。在分布式“云计算”[9]中,为了实现计算任务的快速可靠完成,往往会涉及到“云计算”服务器负载均衡和计算任务调度问题。而边缘接入服务器集群作为终端数据流向远端“云计算”服务中心汇集的中间通道,对数据流的响应时间和可靠接入有着更高的要求,同样面临着任务迁移调度问题。
在任务迁移调度方面,目前有许多优秀的解决方案。Cloudlet作为向移动边缘计算提供可持续性云服务的重要部分,其内部任务的分配和调度是一项极具挑战性的工作,文献[10]设计一种启发式负载均衡策略,考虑网络带宽和网络延时的动态变化,最小化任务完成时间和最大完工时间,提高云服务效率。Wang等[11]将“云计算”任务总完成时间和惩罚因子量化为适应度函数,提出基于灾难性遗传算法的任务调度算法,在满足延迟的基础上对云计算任务进行调度。文献[12]针对资源需求在时间和长度上的时变特性及云资源的动态性和异构性,提出一种在线强化学习的方法进行前瞻性任务分配,以减少提交任务的响应时间和最大完工时间,提高资源效率。文献[13]将任务调度抽象为虚拟化技术下的虚拟机部署问题,通过三次指数平滑算法计算下一时期任务请求的资源需求,在此基础上提出多目标约束功耗模型和基于概率匹配的低功耗资源分配算法,提高了系统的实时响应效率和稳定性。文献[14]通过度量到达特定机器的数据流包对CPU、内存和网络的利用率,同时考虑组成集群的主机的资源利用率,以降低数据流在线调度对流处理计算性能的影响。文献[15]讨论了一种具有响应时间约束的大数据流在线调度策略,对系统稳定性、响应时间和资源利用进行建模,有效地权衡了系统接入高稳定性和可接受响应时间之间的矛盾。童钊等[16]提出一种基于Q 学习的多目标任务调度算法,利用Q-learning 自学习算法对任务进行排序,对任务最早完成时间和计算成本进行综合考虑,以产生最小成本为目标函数对任务进行调度。
在前人研究的基础上,本文设计区域动态分组接入算法对AI 数据流进行分组快速接入。同时,针对边缘接入场景中AI 数据单元的动态变化造成部分接入服务器资源“过负载”,进而导致AI 数据单元发生严重丢包现象,本文设计并实现基于资源预测的AI 数据流迁移调度机制,有效解决AI 数据单元动态变化带来的系统问题,提高系统容错能力。
3 AI数据流接入系统设计
3.1 集群通信架构
考虑到规模性数据流通信占用大量网络带宽,引起控制类消息发生严重拥堵,本文采用旁路控制机制,通过专用物理端口将终端设备、接入服务器集群和GPU 计算集群进行旁路连接进行控制类消息通信。如图1所示,针对不同的终端设备(用F1,F2,…,Fn 标识),在接入服务器(用R1,R2,…,Rn标识)使用多端口实现并发数据流接入,并将并发数据流依照轮转周期交给相应的GPU 计算服务器(用G1,G2,…,Gn标识)进行计算。

图1 集群通信架构
3.2 AI数据流通信协议
在边缘接入场景中,AI 计算任务往往需要满足较高的实时性要求,这种高实时性要求的AI 任务处理不仅需要接入服务器物理上靠近智能终端,还需要低延迟的数据通信协议。UDP 传输协议采用无连接的通信方式,在大规模并行接入中显得更加轻量高效,本文设计了基于UDP 消息的AI 数据流轻量化通信协议,以支持大规模AI 数据流并行通信功能。基于UDP消息的AI数据流通信协议包括两种协议类型,一种是进行AI 数据流传输的消息包,用于AI 数据单元的数据封装和传输;另一种是与并行接入系统有关的控制类型数据包,该类数据包用于实现并行接入系统的服务器资源负载信息汇集、服务器数据流接入信息同步和AI 数据流丢包重传等功能。
如图2 为本文设计的消息包格式,该设计对数据包结构进行自定义,保存了数据流的基本信息,便于系统进行丢失数据包的重传,以实现AI 数据流的可靠交付。

图2 数据包协议格式
本文设计的控制类数据包如图3 所示,通过旁路控制机制实现智能终端系统和接入服务器集群之间的控制消息传输。集群内接入服务器定期向集群管理者发送资源负载同步包和数据流接入信息同步包,管理者解析对应控制包,生成资源负载信息表和数据流接入信息表。其中,资源负载同步消息包括对应服务器提供的接入端口地址Ser_Ip,端口带宽负载Net_Load,端口AI 数据流占用内存负载Mem_Load,CPU 利用率CPU_Load。数据流接入同步消息包括接入服务器各端口接收AI 数据流的源地址Src_Ip,以及AI数据流源端控制机制采用控制端口Ctr_Port。对于数据包丢失重传控制包,其DATA 域指明发生丢包AI 数据单元相关信息以及待重传数据包数量Rtr_Pkt_N,对应Data 域中每两个字节标识一个丢失数据包在对应AI 数据单元内的分片编号,以使智能终端对丢失数据包进行选择重传。
这种种原因标明,利用Fizpatrick-Pathak皮肤分型来预测MED值是不可靠的,缺乏客观依据。

图3 控制包协议格式
3.3 数据流接入算法与调度机制
3.3.1 AI数据流资源模型

3.3.2 接入服务器资源负载模型
根据服务器接入信息,可获得接入服务器Ri接收端口Pj理论最大接收速率为Vmax_Pj_Ri,接入服务器最大接收端口数量为num_port_Ri,接入服务器Ri接收端口Pj接入AI 数据流数目为Nreceived_Pj_Ri,接入服务器Ri最大内存容量Mmax_Ri,在t时刻,接入服务器Ri的CPU资源利用率φC_Ri(t)由系统得出。通过式(3)可以计算出接入服务器Ri端口Pj网络带宽占用量,考虑通信干扰因素,由式(4)对端口带宽占用量进行平滑修正,修正因子δ为0.8。式(5)可以计算出接入服务器Ri全部接收端口总带宽利用率。接入服务器Ri接收端口Pj接入AI 数据流内存使用量由式(6)计算得出,由式(7)进行平滑修正,修正因子ϵ取0.8,最后由式(8)计算出AI 数据流对接入服务器Ri总内存占用率。
3.3.3 区域动态分组接入算法ADGA及其改进
在大规模AI 数据流接入工作中,采用轮询方式将AI 数据流接入边缘服务器集群,服务器资源的动态变化导致传统轮询方式较高延迟响应问题。本文针对大规模AI 数据流接入请求,通过对接入服务器资源进行分析,建立AI 数据流资源需求与接入服务器可用资源二分图,寻找增广路径,设计区域分组动态接入策略,将AI 数据流进行分组接入。
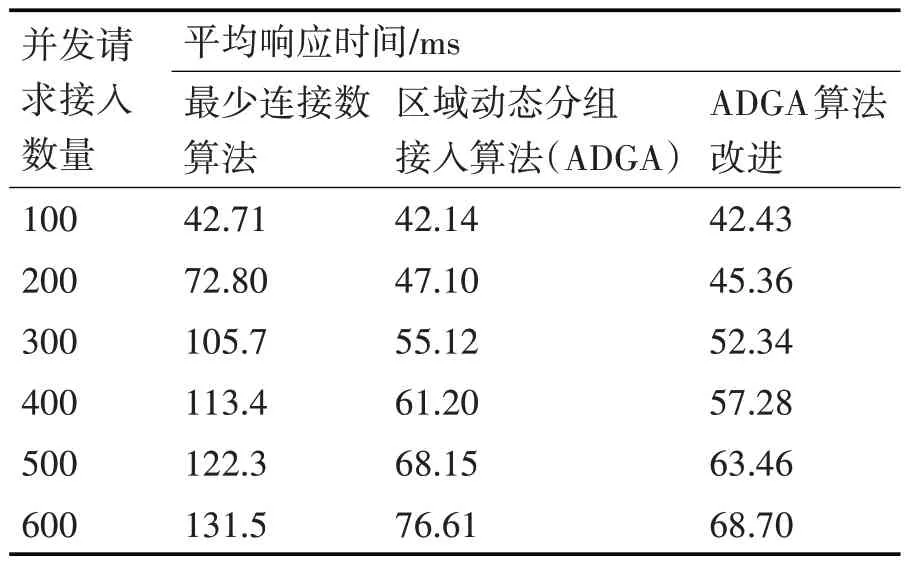
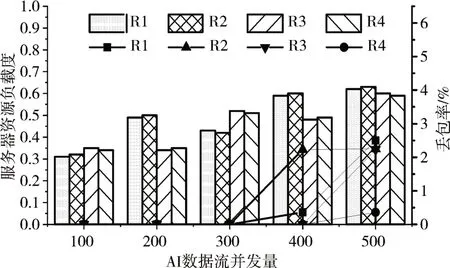
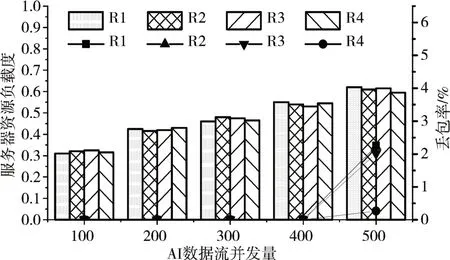
采用常用图表示方法表示二分图为G={ }V1,V2,E,其中V1为集群接入服务器节点集,V2为请求进行AI 数据流接入的智能终端节点集,E为两个节点集内节点之间的边集,最初E=∅。当大量智能终端发送接入请求时,区域管理者解析接入请求包,获得待接入AI 数据流数据单元Fk对接入服务器Ri端口带宽占用量Buse_Fk_Ri及内存占用量Muse_Fk_Ri。管理者查看集群资源负载信息表,获得接入服务器Ri剩余端口带宽Bleave_P_Ri和 内 存 资 源Mleave_P_Ri。 若Buse_Fk_Ri 区域动态分组接入算法核心在于二分图的构建和最大匹配的求解。假设集群接入服务器节点共n 台,请求接入的智能终端共有m 个。构建二分图时,需要将所有请求接入的AI 数据流占用资源与所有服务器节点剩余资源进行比较,建立终端与服务器之间的连接线,此过程时间复杂度最大为O(mn)。求解最大匹配过程中,对于每个接入服务器节点,都要查找其匹配边,对于具有n 个接入节点的集群,匹配边最坏查找情况即每次匹配都会查找一条增广路径,由二分图构建过程可知增广路径最大边数为mn,则完成最大匹配求解最差时间复杂度为O(mn2)。根据算法最差时间复杂度可知,在大规模AI 数据流接入工作中,这种分配模式仍存在较大弊端。本文对请求AI 数据流接入的智能终端进行分组,分组大小为K(K 为单个分组内AI数据流数目),通过如下公式计算K值。 经过改进的区域动态分组接入算法,当接入服务器拥有较多可用资源时,将大规模AI 数据流接入请求进行分组,每个分组用二分图中V2的一个顶点表示,每个匹配边表示将一组数据流接入请求分配给一台接入服务器节点。 3.3.4 基于资源预测的AI数据流迁移调度 前文已对接入服务器CPU利用率、内存利用率和端口带宽利用率进行分析建模,设φ_Rj(t)=(φC_Ri(t),φM_Ri(t),φN_Ri(t) )表示t时刻接入服务器Ri各资源利用率,定义接入服务器Ri资源总负载度为 在大规模AI 数据流并发接入模型中,当智能终端设备进行时间序列AI 数据流接入时,接入服务器的资源随着数据流的接入发生波动,可能导致服务器“过负载”现象,大大降低集群接入性能。针对接入服务器资源负载变化问题,防止资源负载突变产生负载误差,本文基于加权平均的思想,采用二阶差分指数平滑法对接入服务器资源负载情况进行预测。使用二阶差分指数平滑法进行预测的计算过程如下:当t 时刻资源负载标准差LSDt超过负载平衡阈值θ(θ取值0.1),触发管理者数据流调度机制。由于对AI 数据流进行接入时,区域动态分组接入算法已经基于服务器资源对数据流进行了初分配,此处管理者选择“过负载”接入服务器中资源占用较少的数据流迁移至“欠负载”接入服务器。可以通过式(20)~(24)计算迁入节点的可接受迁入数据流数量。其中,式(20)可以计算出接入服务器Ri单端口剩余带宽,通过式(21)进行平滑调整,调整因子u=0.8。式(22)可以计算出接入服务器Ri接收端口总剩余带宽。式(23)计算出接入服务器Ri剩余内存总量。最后,通过式(24)可以计算接入服务器Ri能接受迁移的AI数据流数目。 为验证本文接入算法和流调度机制性能,我们使用4 台不同主机搭建边缘接入服务器集群,其中1台兼备协调者功能,详细配置如表1所示。 表1 接入服务器配置信息 针对本文研究环境,经过Nano 开发板预先进行姿态行为视频采集和预处理生成AI 数据流,每台模拟机存储300路不同的AI数据流,多线程进行不同AI 数据流发送任务。每台模拟机详细配置信息如表2所示。 表2 模拟机配置信息 经前期实验第一部分AI 分层模型采用27 层时,Nano 开发板可在轮转周期为1s 内完成图像采集、AI 预处理和周期性发送任务。经过分层模型预处理的AI 数据单元大小约为672KB,采用设计的AI 数据包大小,单个AI 数据单元将被封装成945 个AI 数据包。假定发送数据单元周期数为T,单个周期数据单元并发量为N,通过对丢包率和各服务器资源负载度的分析,对本系统的调度机制性能进行评估。 丢包率DPR 指连续发送周期T 内AI 数据流丢包总量占数据流包总数的比例;接入服务器资源负载度Li由式(13)计算得出。对比管理者被触发数据流迁移调度前后各服务器资源总负载度和AI 数据流丢包率,可以反映系统数据流迁移调度算法性能。 4.3.1 数据流接入响应时间测试 在该实验中,本文选择传统最少连接数法、本文的区域动态接入算法及其改进算法,对比各算法对不同规模请求接入的平均响应时间。如表3 为不同数据流接入请求时各算法平均响应时间对比。 表3 不同接入请求量下各算法响应时间对比 对比可以看出,在不同数量数据流并发请求接入时,采用最少连接数算法对数据流进行接入,数据流接入请求平均响应时间都远远大于本文的区域动态分组接入算法及其改进算法。在数据流接入请求数量为100 时,集群各接入服务器仍处于“欠负载”状态。对于大量“欠负载”服务器,管理服务器执行动态分组算法效果并不明显,由于在分配数据流接入请求时需要先对数据流进行分组划分,然后按分组进行动态接入,导致ADGA 改进算法平均响应时间略大于区域动态分组接入算法。在数据流接入请求数量大于200 时,ADGA 改进算法接入请求平均响应时间明显小于算法改进前平均响应时间,这是因为ADGA 改进算法不仅考虑服务器负载情况,并将流平均分配思想用于分组大小的计算,提高了服务器负载均衡程度,从而降低集群对规模性数据流接入请求的平均响应时间。 4.3.2 数据流迁移调度实验 本文利用服务器集群单端口进行数据流迁移调度实验,发送周期T 选取100。模拟机向集群管理者发送不同规模AI 数据流接入请求,计算采用资源预测的数据流调度前后各服务器资源负载信息,将数据流调度前后各服务器丢包率进行对比。 如图4和图5所示,未采用数据流调度时,集群各服务器资源负载度存在明显差异,特别是当集群数据流并发量达到400 时,部分服务器资源负载度达到0.6,开始出现“过负载”现象,丢包现象明显;采用基于资源预测的数据流调度算法之后,各服务器相互分担数据流接入工作,集群各服务器资源负载度相对均衡,并未出现个别服务器“过负载”现象,丢包率明显下降。当集群数据流并发量达到500 时,基于资源预测的流调度方案可以使各服务器资源负载相对均衡,但AI 数据流总并发量超出了集群处理能力,部分服务器仍存在“过负载”现象。通过图4 和图5 可以看出,当AI 数据流总并发量在集群可处理能力范围内时,基于资源预测的流调度方案可以更好地对集群服务器资源进行均衡利用,避免单个服务器由于“过负载”出现集群性能瓶颈,从而提高系统AI数据流接入可靠性。 图4 调度前各服务器资源负载度和数据流丢包率 图5 调度后各服务器资源负载度和数据流丢包率 在大规模AI 数据流接入过程中,进行不同数量的数据流并发接入时,本文设计并实现的区域动态分组接入算法对数据流接入请求平均响应时间均低于传统最少连接法。针对AI 数据单元动态变化,设计并实现基于动态资源预测的AI 数据流调度。在流动态变化过程中,采用动态资源预测的数据流调度机制可以有效解决接入服务器预期“过负载”现象,保证系统总并发量不变情况下,降低边缘接入集群AI 数据单元丢包率,使系统资源得到高效利用。这对未来大规模智能终端数据进行汇集接入具有重大实际意义。未来本文将对接入服务器集群动态扩展进行研究,以使得集群规模自适应AI数据流并发接入总量。
4 实验测试
4.1 实验环境


4.2 评估指标
4.3 实验结果及分析
5 结语
