术后风险预测任务的结构化数据生成方法∗
2024-04-17罗晓辉周瑞豪张伟义舒红平王亚强郝学超
罗晓辉 周瑞豪 张伟义 舒红平 王亚强 郝学超
(1.成都信息工程大学软件工程学院 成都 610225)(2.成都信息工程大学数据科学与工程研究所 成都 610225)(3.成都信息工程大学软件自动生成与智能服务实验室 成都 610225)(4.四川大学华西医院麻醉手术中心 成都 610044)
1 引言
在手术前对患者进行系统的、全面的信息收集以及身体检查形成的结构化术前数据十分重要。这份术前数据可以帮助医生了解患者的健康情况,评估手术风险,制定合适的麻醉计划,同时预防术中以及术后可能出现的潜在风险。
近年来,结合结构化的术前数据和机器学习,用于预测术后风险已经成为医学领域的重要趋势。Thottakkara 等[1]使用逻辑回归、朴素贝叶斯和支持向量机用于预测术后脓毒症和急性肾损伤的发病情况。Grsbeck 等[2]使用机器学习预测吸烟者的术后并发症发生率。Yu 等[3]使用逻辑回归识别进行妇科手术后,术后疼痛的高危患者。
为了更好地应对术后风险预测的挑战,专家和研究人员意识到多中心数据共享的重要性。通过采用基于多中心数据的模型训练方法,可以从更广泛和多样化的数据中学习,从而使模型更好地适应不同的患者群体和临床场景,提高模型的泛化能力。Getachew 等[4]使用多中心数据研究术前疼痛与术后疼痛以及手术时间的关系。Peter 等[5]使用多中心数据减少了成人脊柱畸形矫正手术的ICU入院率。
然而,术前检测数据包含大量敏感的个人医疗信息,共享这些原始数据可能会暴露隐私,单纯进行数据匿名化也存在隐私暴露风险[6]。同时,用于预测术后风险的术前结构化数据存在类别不平衡问题[7]。这两个问题限制了术前数据的共享以及术后风险预测模型的效果。
因此,针对以上问题,本文使用CTGAN[8]为基础模型,对其进行改进,添加分类器,使模型更适应于下游任务,本文将提出的模型称为ACCTGAN。我们使用该模型生成与原始数据高度相似的数据,使用生成比原始数据量更大规模的数据,训练下游任务分类器,以达到数据增强的效果,并且达到平衡数据类别的目的,以此方式提升下游模型预测性能。且生成数据可通过生成符合真实数据概率分布并且从未出现在真实数据里的假数据,用于数据共享。为预测术后并发症数据的类别不平衡问题以及数据共享的问题提出解决方案,主要贡献包括以下几个方面:
针对术后风险预测问题,本文使用新的GAN网络,它引入了一个分类器,提供了额外的监督,以提高生成数据在下游任务中的效果。
在不平衡数据集上,使用大量的生成数据增加少数类样本。使用生成数据训练的分类器与基线相比,下游任务分类器效果有显著提高。
使用生成模型生成与真实数据相似的生成数据,使用高质量的生成数据解决数据共享问题。
实验结果表明,在术后并发症预测任务中,通过使用GAN 模型生成的数据,使预测效果有明显提升,且生成数据在特征列的统计分布情况和列与列的相关性上与真实数据高度相似,最后通过隐私暴露风险实验证明这些生成数据可用于学术研究下的数据共享。
2 相关工作
2.1 生成对抗网络
生成对抗网络(GAN)[9]是近年来发展起来的一种生成模型,通常用于生成图像或文本。该模型基于一个生成器和一个判别器,它们的学习过程采用了一种零和极小极大游戏的方式。
在表格类型的生成对抗网络研究中,一些方法基于原始的GAN 模型,并针对特定的应用进行改进。Yahi 等[10]使用GAN 生成连续时间序列病历,他们通过生成对抗网络模拟真实病例数据的分布,从而生成具有连续性的时间序列数据。MedGAN[11]结合了自动编码器和GAN 的思想。它能够生成既包含连续变量又包含离散变量的医疗数据,并且已经在电子病历数据的生成任务中得到应用。Table-GAN[12]也试图解决表格类型数据集的生成问题,它在GAN 框架中引入了信息丢失和分类器,它的生成器、判别器和分类器都是用的卷积神经网络构成。CrGAN-Cnet[13]使用GAN进行航空旅客姓名记录的生成,除了生成连续和离散类型的数据外,CrGAN-Cnet还可以处理表中的缺失值。
由于使用原始的GAN 控制生成数据的局限性,条件GAN 被越来越多地使用,它的条件向量可以用来指定生成某一类数据。当可用数据有限且高度不平衡,并且需要特定类别的合成数据来重新平衡分布时,此功能非常重要。CW-GAN[14]是一种将Wasserstein 距离[15]应用到条件GAN 框架中的模型,它利用条件向量对少数类进行过采样,以解决表格数据生成不平衡的问题。CTGAN[8]在判别器中集成PacGAN[16]结构,使用WGAN 损耗加梯度惩罚[17]训练条件GAN 框架。它还采用了一种采样训练策略,利用条件向量来处理分类变量的不平衡问题。DRL-GAN[18]使用生成对抗网络与强化学习相结合,用于提升检测网络攻击的准确率。Hindistan等[19]使用GAN 与差分隐私来保护工业物联网操作中的敏感数据。这些方法的出现提高了生成数据的质量,丰富了生成对抗网络的应用领域,并针对特定问题提供了更好的解决方案。本文基于生成对抗网络,旨在对术后风险预测的数据进行建模和生成。通过训练模型,可以生成与原始数据具有相似特征和分布的生成数据。生成的数据可以用于改进下游任务的效果,并且可以用于数据共享的目的。
2.2 术后风险预测
术后风险预测是医学领域中的一个重要研究方向,已经吸引了广泛的学术和临床关注。目前主要聚焦于优化机器学习模型,提升在该领域的实际应用效果。Hill 等[20]采用机器学习模型,将美国麻醉医师协会身体状况特征与术前特征结合,提升术后死亡风险的预测性能。Chiew 等[21]使用随机森林、自适应增强、梯度增强和支持向量机对候选模型进行训练,用于预测ICU 入室等风险。Fritz[7]使用了一个多路径卷积神经网络模型,结合多种数据来预测术后死亡风险。这些工作都是在下游任务上训练更好的分类模型,提升术后并发症的预测效果。暂无有人从数据端出发,提升模型的预测效果。
3 任务定义
我们将真实的结构化术前数据定义为Ddata={(X,Y)},其中X={X1,X2,…,Xm}为表格类型数据,其中Xm∊Rn,即总共有m 个样本,每个样本有n 个特征,在标签上,Y={Y1,Y2,…,Ym},其中Ym∊R2,它们构成标签集,在本文中标签为术后风险的发生情况,用1 和0 来标识术后并发症的发生与未发生。这些变量遵循一个未知的联合分布,每一行都是联合分布的一个样本,每一行都是独立采样的,即我们不需要考虑每一行的顺序。我们的目标是得到一个生成模型,该模型有三部分,生成器、判别器和分类器,我们将生成器表示为G,判别器表示为D,分类器表示为C。通过训练使该生成模型生成的表格T 达到以下标准,首先,把T 用于训练分类模型,并在真实的测试集上达到与真实训练集类似甚至更好的效果,其次,生成表格T 与原始数据集拥有类似的统计分布。
4 模型定义
GAN 模型由两个神经网络组成:生成器和判别器。我们的基础模型CTGAN[8]也是如此。我们的模型ACCTGAN 采用了CTGAN[8]原始的架构,但有一个额外的神经网络,称为分类器,每个结构的功能介绍如下:
1)生成器产生与真实记录具有相同分布的生成数据样本,且生成样本要足够真实能够欺骗判别器。
2)判别器用于区分真实的数据和生成样本。
3)分类器用于预测生成记录的标签。在训练生成器的过程中,添加一个分类器可以维护生成记录中值的一致性,这个在本节的后文中有详细介绍。
ACCTGAN的生成器和判别器的结构以及条件向量的生成方式都与CTGAN[8]中一致。
ACCTGAN 中的分类器的隐藏层使用了3 层全连接网络,每层有256 个神经元,每层的激活函数都用的是Leaky ReLU,并且使用了dropout 防止分类器过拟合。这个分类器是根据原始表中的真实标签来训练的,可以学习标签和特征之间的关系。当给定一条生成的记录时,分类器可以判断该记录在特征与标签上的关系是否正确。若分类器检测错误,可为生成器提供反馈,可以帮助生成器生成更准确、更真实的生成数据,这样可以提高生成数据的质量和可信度。
事实上,判别器本身也可以在某种程度上学习特征与标签之间的关系。关系不正确的生成样本可能不会被判别器分类为真实的。然而,判别器的主要任务并非考虑特征与标签之间的关系,因此我们在基础的GAN 模型中添加分类器,使生成器能更好的学习特征与标签之间的关系。本文模型的整体结构如图1所示,其中FCN表示全连接层(Fully connected network,FCN),BN 表 示 批 标 准 化(Batch Normalization,BN)。
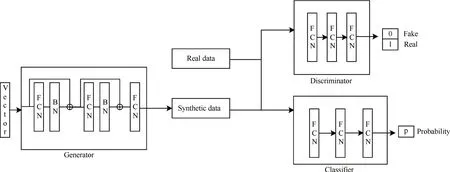
图1 ACCTGAN模型基础架构
在判别器和生成器部分,我们使用原始CTGAN 的损失函数,并将它们表示为它们分别用来衡量判别器和生成器的性能和指导它们参数的更新。在分类器上,它的损失函数如式(1)所示:
ACCTGAN的分类器使用二分类交叉熵损失函数,其中k是每轮训练的样本数,yi是第i个样本的所属类别,pi是分类器对每个标签的预测概率,取值范围为0~1。在训练过程中,分类器有两次输入,分别输入真实数据和生成数据,先输入真实数据,学习真实数据中特征与类别之间的关系,再将学习到的关系应用在生成数据中,分析生成数据是否有不合理的关系,之后再更新生成器的参数,因此,分类器损失函数在输入真实数据时定义为,这表示使用该损失函数评估分类器,优化分类器模型,在输入生成数据时为,这表示使用它更新生成器参数,优化生成器。
我们通过一个例子来详细的解释分类器如何帮助生成器学习特征与标签之间的关系。如图2所示,在一次训练中,先将条件向量与噪声向量输入生成器,让生成器生成样本,然后通过条件向量选出对应的真实数据,之后先将真实数据的特征输入分类器,使用损失函数对分类器预测的结果进行评估,使用Adam 更新分类器参数。然后将生成器生成样本的特征输入分类器,可以注意到图2中,生成器生成的样本中手术部位为皮肤,ICU 入室标签为真,但真实数据集中没有这样的数据,这就与分类器从真实数据中学到的特征与标签之间的关系不符,这样损失函数L的值就会比较大,较大的损失函数值通常会导致更大的梯度,这将影响模型参数的更新幅度,以帮助模型更快地向着更优的参数方向移动。这样使用Adam 优化器根据更新生成器参数时,可使生成器更快地学习特征与标签之间的关系。
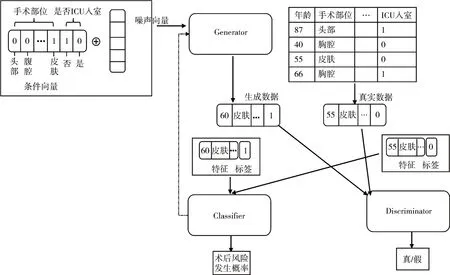
图2 ACCTGAN模型部分训练过程
5 实验
5.1 实验数据
建立术后并发症数据的生成模型,需要使用大量的数据来训练模型。我们使用的是某三甲医院手术麻醉管理系统中的数据来构建模型。该数据集包含患者的基本身体状况信息和实验室检查数据,并且对这份原数据本文采取以下处理。
1)删除了病人的身份信息、手术开始日期和手术编号等信息,以保护患者隐私。
2)选择了与术后并发症相关的特征,并且仅保留这些特征用于建立生成模型。这些特征的选择是基于医学先验知识和经验进行的,以确保训练下游分类任务时分类模型具有较高的预测性能和准确性。
最后得到两个术后并发症预测任务数据集,包含了三种术后并发症的标签。第一个数据集有17356 个样本,两种标签,分别是肺部并发症和心血管不良,第二个数据集有12240 个样本,1 种标签,标签为ICU 入室风险,这些标签的阳性率分别是14.05%、6.16%和2.74%,如图3所示。
5.2 实验方法
本次研究的主要目的是验证ACCTGAN 是否能够有效捕获数据集中的特征分布,并且生成的数据是否能够直接用于训练模型,训练模型的实验在Ubuntu 18.04 系统上运行,机器的CPU 为Intel(R)Xeon(R)Silver 4210R CPU @ 2.40GHz,显 卡 为RTX 3090。此外,我们希望通过增加生成数据的数量来增强下游任务中的分类模型的性能,以此达到数据增强的效果。
为了达成目标,我们使用了以下几种方式分别验证生成数据集在下游任务中的有效性,生成数据与真实数据的统计相似性,以及生成数据的隐私暴露风险。
5.2.1 机器学习效用
机器学习效用(ML utility)是指将原始数据分为7∶3 的训练集与测试集,使用训练集训练一个GAN 模型和训练下游任务分类器,将GAN 用于生成数据,再用GAN 模型生成的数据训练另一组分类器,之后用真实的测试集数据分别对这两组分类器做评估,对比它们的效果。
在训练的分类器上我们使用精确率(Precision)、召回率(Recall)和F1值评估模型的效果。下面是评估指标的计算公式:
在本文中,我们选择了三个医学上常用的机器学习模型,逻辑回归(Logistic Regression,LR)[22]、随机森林(Random Forests,RF)[23]和CatBoost 以及两种最新针对表格类型数据的深度学习模型Tabnet 和TabResnet 来构建分类器模型。LR 和RF 采用scikit-learn 框架[24]实现,CatBoost,Tabnet 和TabResnet 我们使用它们的开源代码库[25~26]和原始参数设置进行实现。
5.2.2 统计相似性
本文使用三个度量指标来度量真实数据和生成数据之间的统计相似性。
Jensen-Shannon divergence(JSD),它的取值范围在0 和1 之间,其中0 表示两个数据概率分布完全相同,1 表示两个数据概率分布完全不同。它在机器学习中经常用于衡量概率分布之间的差异。在本文中,该值越小则证明生成数据集与真实数据的差异越小,生成的效果越好。JSD 的计算公式如式(5)所示,P、Q 分别为真实数据集与生成数据集的概率分布。
Wasserstein distance(WD),它的值越小,表示两个概率分布越相似。与其他距离度量不同,Wasserstein 距离可以处理具有不同质量的概率分布,而不仅仅是在集合上测量距离。在本文中,该值越小则证明生成数据集与真实数据的差异越小,生成的效果越好。WD 的计算公式如式(6)所示。其中,P、Q分别为真实数据集与生成数据集的概率分布,Π(P,Q)表示分布P 与Q 组合起来的所有可能的联合分布的集合。
关系系数比较,我们使用皮尔逊相关系数比较两组数据之间关系的差异。相关系数的取值范围在-1~1 之间,越接近1 或-1,则说明特征列之间的关系越强。使用相关系数生成热力图,通过比较热力图的差异来衡量生成模型是否捕获到数据之间相关性。
5.2.3 隐私暴露风险分析
Distance to Closest Record(DCR)是指在两个数据集之间,数据集A 中数据点到数据集B 中数据点的最近距离,也就是说该值越大,隐私暴露的风险就越小。我们对每条生成数据选取与其最近的s条真实数据,对它们的距离求平均值,然后对生成数据集的DCR 求平均,得出一个数据集的平均DCR。本文在两个数据集上分别做了3 次DCR 实验,s取值分别为1、5、10,以分析隐私暴露的风险及可能性。
5.3 实验分析
5.3.1 机器学习效用
机器学习效用的研究结果见表1。数据源分别为真实数据集,使用CTGAN 和ACCTGAN 生成的数据集,将这三个数据源分别称为“Origin”,“CTGAN”和“ACCTGAN”。表1 中首先是用“Origin”训练的下游任务分类器在真实测试集上的性能,然后展示了使用“CTGAN”和“ACCTGAN”训练的分类器在真实测试集上的表现,这些生成数据规模分别是原始训练集的1、2、4、8倍。
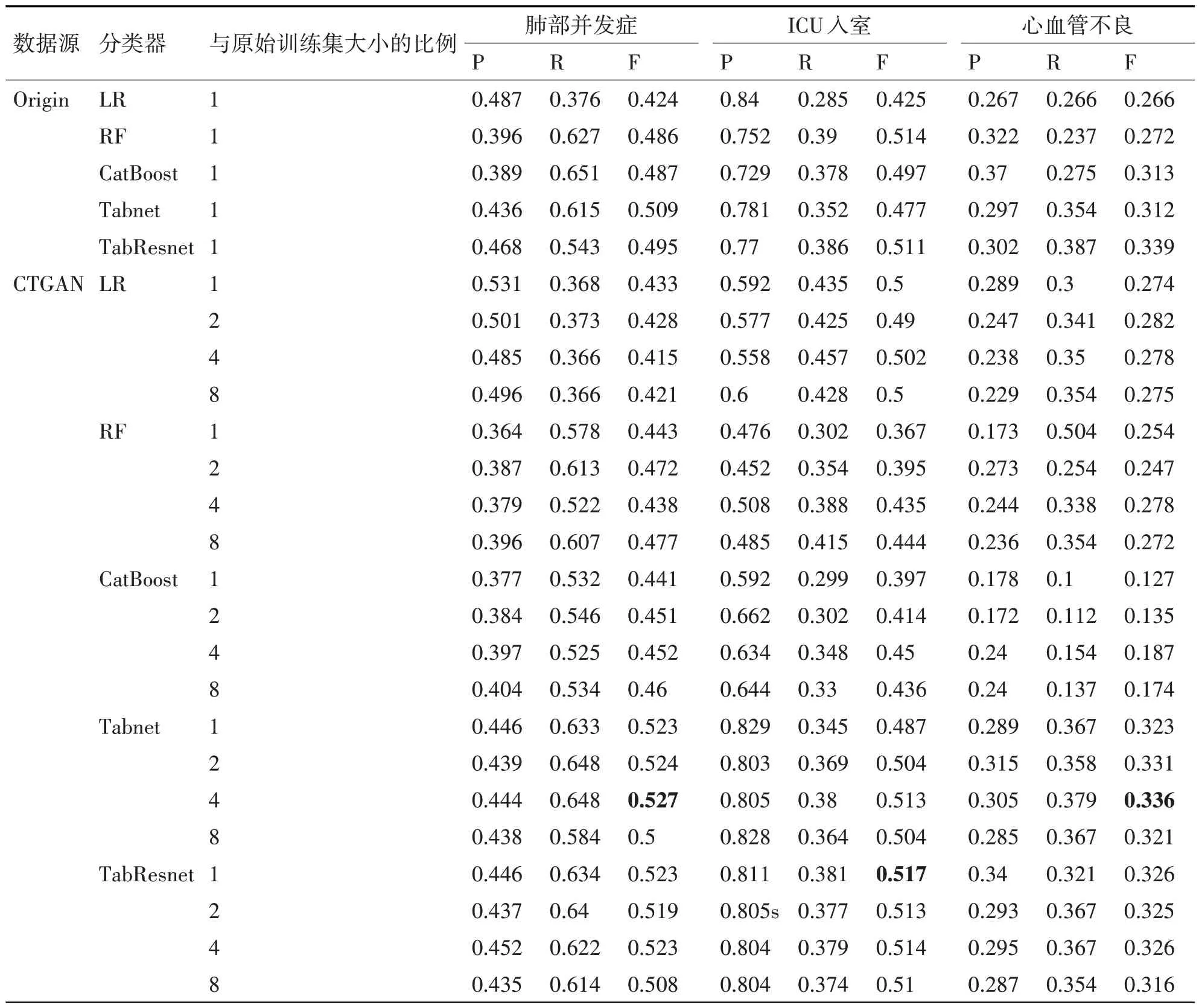
表1 机器学习效用结果
实验结果表明,使用ACCTGAN,可以有效提升下游分类任务模型的性能。实验中发现,生成适量的数据可以达到最佳的结果,具体而言,在本文进行实验时,生成4 倍于原始训练集数量的数据可以取得最佳效果。在肺部并发症、ICU 入室和心血管不良这三个任务中,使用ACCTGAN 生成的数据训练的下游分类器的F1 值分别为0.531、0.547 和0.343,相比与只使用原始数据集训练的分类器,效果有所提升,同时,使用CTGAN模型数据的分类器F1 值也分别为0.527、0.517 和0.336,其评价指标同样高于只使用原始训练集训练的分类器。这证明了使用GAN 模型生成的数据可以扩展原始数据集少数类的规模,有助于缓解数据不平衡的问题,并改善分类模型的训练效果。可以达到数据增强的作用,提升下游分类模型。表格1 中的P、R 和F 分别代表评价指标Precision,Recall和F1值。
实验结果进一步验证了ACCTGAN 作为一种辅助任务增强的生成器,能够更好地利用现有数据,生成高质量的生成数据。通过生成大量的高质量生成数据,用于训练下游分类器,从而增强了下游分类模型的泛化能力和性能。
5.3.2 统计相似性
在统计相似性和隐私暴露风险分析这两个实验中,我们都使用与原始训练集同规模的生成数据集进行比较。因为我们的模型是通过分类器考虑标签与特征之间的关系,以下游任务为导向生成的数据,在第一个数据集上有肺部并发症和心血管不良这两种标签,因此我们的模型根据这两种标签生成了两个数据集,在实验中我们以标签的名称命名数据集。
表2 展示了统计相似性分析的结果,图中颜色越浅变量之间正相关性越强,颜色越深则变量之间负相关性越强。ACCTGAN在肺部并发症和心血管不良数据集上的JSD 和WD 指标均优于CTGAN,在ICU 入室数据集上的JSD 值也优于CTGAN,但WD指标上CTGAN的结果略优于ACCTGAN,这证明了在肺部并发症和心血管不良这两个数据集上ACCTGAN生成的数据集更接近于原始数据集的分布。JSD和WD指标主要用于验证生成的数据集是否符合原始数据集的分布,结果表明这两个GAN模型均符合原始数据集的分布。

表2 统计相似性结果对比
此外,我们还进行了一组实验,记录原始数据集每列的最大和最小值,并计算生成数据集出现在该区间内的频次。该频次的结果值范围为0~1,如果结果为1,则表示所有生成数据都在该区间内。结果如表3 所示,从结果可以看出,这两个GAN 模型都没有生成原始数据集最大最小值区间外的异常值,这说明了生成的数据集与原始数据集在最大最小值区间保持了高度的相似。这个结果表明这两个生成模型在生成数据时能够有效地控制数据的范围,避免生成异常值。这对于保持生成数据的可信度和质量至关重要,使得生成数据能够更好地与原始数据集相匹配,并在下游任务中具有可用性。

表3 非异常数据分布检测结果
相关性的热力图如图4、5、6 所示,比较了原始数据集和通过CTGAN 模型生成的数据集以及通过ACCTGAN模型生成的数据集这三者之间的相关性差异。我们首先观察三个数据集的整体情况,CTGAN 模型生成数据集的热力图比原始数据的热力图颜色要整体偏深,这代表CTGAN 生成数据集的相关性与原始数据有一定差异,而ACCTGAN 生成数据的热力图与原始数据的热力图颜色分布基本类似,这证明ACCTGAN 更好的学习到了原始数据之间的相关性,且在几个强相关的点,ACCTGAN都有学习到。这证明了ACCTGAN 生成的数据更贴近于原始数据的相关性。
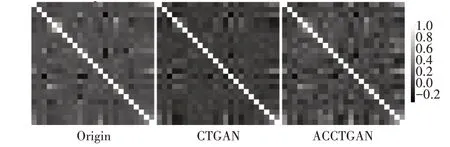
图4 肺部并发症数据集热力图

图5 ICU入室数据集热力图

图6 心血管不良数据集热力图
综上所述,实验结果表明ACCTGAN 在统计相似性方面的表现优于CTGAN,这些优势可归功于在模型中添加了分类器,使模型更好地保持了原始数据的关联关系。
5.3.3 隐私暴露风险分析
表4 展示了我们对原始数据集和生成数据集进行的DCR 计算结果。首先可以看出,两个GAN模型生成数据的DCR 都比原始数据集高,这说明本文所采用的GAN 模型不是简单地记忆原始数据并生成相同的数据,而是学习了数据之间的模式,生成了与原始数据集不同的新样本作为生成数据集。其中可以注意到的是,随着s取值的减少,DCR的结果在真实数据上减少的幅度要大于ACCTGAN。这暗示着生成数据与真实数据之间,最近的s 条数据的距离要大于原数据的距离,这种结果的产生可以被视为对真实数据隐私的一种保护。这两点表明ACCTGAN 可以有效地生成隐私保护数据,用于数据共享。
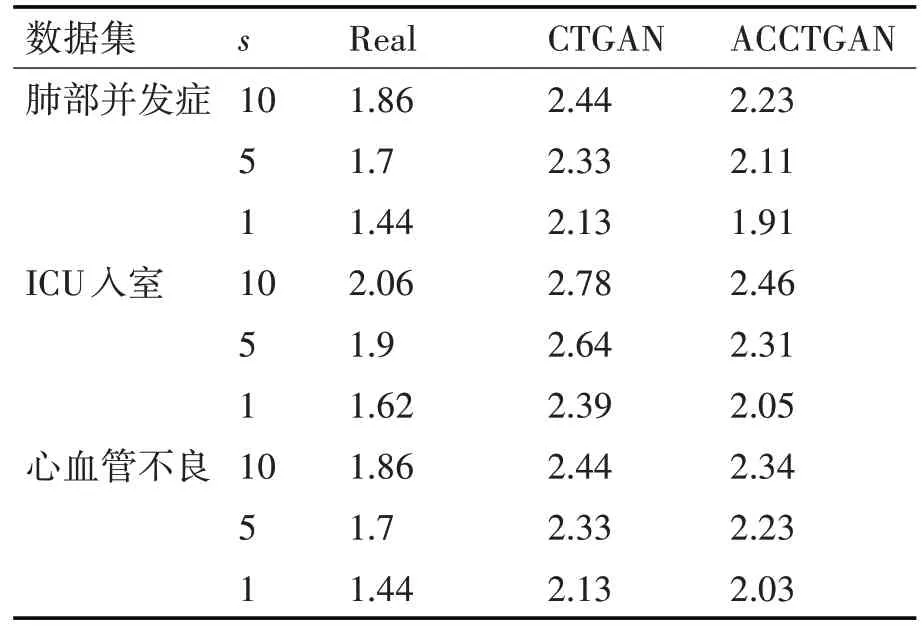
表4 DCR结果对比
6 结语
表格数据作为患者病历的载体,使用表格数据对患者病情进行分析和使用机器学习模型辅助医生预测术后并发症是一种常见的方式。但是由于数据的隐私性,这些数据不能被共享,这使得可供训练模型的数据有限,并且数据阳性样本很低,导致训练出来的模型效果一般。为此,本文提出一种以下游任务为导向的生成模型,使用该模型学习原始数据集的信息,生成更多高质量的生成数据用于训练分类器,提升下游任务模型的效果,为预测术后并发症任务提出一种新的解决方案。实验证明,使用ACCTGAN 可以提高下游分类器的预测性能,通过统计相似性和隐私暴露分析证明了GAN 模型有学到原始数据中的相关信息,而不仅仅是记忆原始数据。因此,我们的方法可以作为医学数据隐私共享问题和不平衡数据对分类器性能的影响的一种新的解决方案。
