基于人工智能的SDN 网络中流量优化与拥塞控制方法
2024-04-16欧阳炜昊
欧阳炜昊,王 晶
(湖南大众传媒职业技术学院,湖南 长沙 410100)
0 引 言
随着信息技术的迅猛发展,网络通信在当今社会中扮演着不可或缺的角色[1-3]。软件定义网络(Software Defined Network,SDN)作为一种创新性的网络架构,将网络控制平面与数据平面分离,为网络管理提供了灵活性和可编程性的新范式[4-5]。然而SDN 网络的高度灵活性也带来了一系列挑战,其中流量优化与拥塞控制问题是急需解决的关键问题之一[6-7]。
文章深入探讨SDN 网络的架构与原理,并在此基础上提出一种创新的流量优化与拥塞控制方法,以应对SDN 网络中由于流量波动和拓扑变化引发的性能问题。文章采用基于强化学习的方法来提高网络的自适应性和性能优化能力。强化学习是一种具备学习和适应能力的人工智能技术,能实现对网络动态环境的实时感知和智能决策,从而应对网络流量的动态变化和拥塞状况。同时,使用Mininet 平台进行测试与评估,以验证所提方法的有效性。
本研究旨在为SDN 网络中的流量优化与拥塞控制问题提供一种创新的解决思路,为未来智能化网络的设计和应用提供有益的参考,以期为网络技术领域的研究与应用提供新的理论支撑和实用经验。
1 SDN 网络架构与原理
SDN 网络架构的核心理念是将网络控制平面与数据平面分离,由控制平面、数据平面、控制器、北向接口以及南向接口等组成,具体如图1 所示。

图1 SDN 基本架构
第一,控制平面。控制平面是网络的大脑,负责制定和管理网络策略、路由、流量工程等。在SDN 中,控制平面是通过1 个单独的控制器来实现的。该控制器使用开放接口与网络设备进行通信。
第二,数据平面。数据平面负责实际的数据传输,即网络中的数据包在设备之间的流动。在SDN中,数据平面的任务是根据控制平面的指令,进行流表项的匹配和数据包的转发。
第三,控制器。控制器是SDN 架构的关键组件,提供1 个中央控制点,通过与网络设备之间的通信向数据平面传递指令。常见的SDN 控制器包括OpenDaylight、ONOS 和Floodlight 等。
第四,北向接口。北向接口是控制器与应用程序进行通信的接口,允许应用程序通过控制器来管理和配置网络。
第五,南向接口。南向接口是控制器与网络设备进行通信的接口,允许控制器向设备下发指令。常见的南向接口协议包括OpenFlow、NETCONF 等。
2 基于强化学习的流量优化与拥塞控制
SDN 网络的灵活性和可编程性为网络管理提供了新的范式。然而,由于网络环境复杂多变,传统的静态流量管理方法已无法满足实时性和效率性的要求。因此,引入强化学习技术成为解决SDN 网络中流量优化与拥塞控制问题的一种前瞻性途径。文章将深入探讨基于强化学习的方法,力求通过智能决策和实时调整来优化网络流量分配。
2.1 强化学习的基本原理
强化学习是一种通过智能体与环境的交互学习,以最大化累积奖励的机器学习范式[8-9]。其核心思想是智能体在不断与环境进行交互的过程中,通过学习合适的决策策略,以获得最大的长期回报。强化学习由状态、动作、奖励、智能体以及环境组成,基本原理如图2所示。
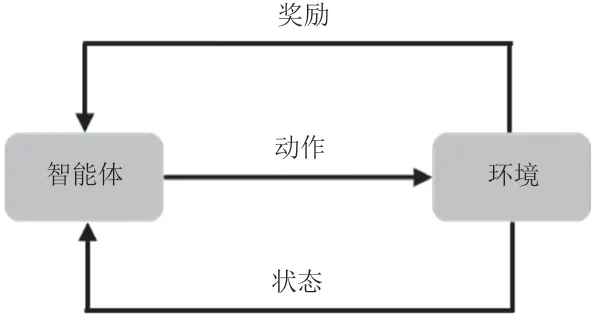
图2 强化学习的基本原理
第一,状态。状态用于描述环境特定时间的信息,用于定义问题,记状态集合为S。
第二,动作。动作是智能体在特定状态下采取的决策或行为,记动作集合为A。
第三,奖励。奖励是环境根据智能体的动作和状态给予的反馈信号,用于评估动作的好坏。奖励通常用函数R(s,a)表示,其中s为状态,a为动作。
第四,智能体。智能体是执行动作并与环境交互的决策实体,其目标是通过学习获得最大累积奖励。智能体的策略决定了在特定状态下选择哪个动作。
第五,环境。环境是智能体所处的外部系统,用于接收智能体的动作,并根据这些动作改变其状态,从而产生相应的奖励。
强化学习的基本目标是找到1 个最优的策略,使智能体在特定状态下采取特定动作,从而最大化长期累积奖励,用价值函数表示为
式中:V(s)表示状态s的状态值函数;Q(s,a)表示状态s采取动作a的预期累积奖励;Rt表示t时刻的即时奖励;γ表示用于平衡当前奖励和未来奖励权重的折扣因子;E(·)表示数学期望;St=s表示状态St取值为s的情况;At=a表示动作At取值为a的情况。
通过调整智能体的策略以最大化状态值函数或动作值函数,强化学习算法能够实现智能体在复杂环境中的优化决策学习。
2.2 流量优化与拥塞控制
在流量优化与拥塞控制的研究中,采用强化学习的方法来调整网络中的流量分配,以达到优化网络性能的目的,采用的强化学习框架由4 部分组成。
第一,状态表示与特征提取。网络状态St通过包括网络拓扑和流量信息等多方面特征的函数f进行建模,从而全面地反映当前网络环境。
第二,动作空间与策略,用公式表示为
式中:{a1,a2,…,am}表示智能体可选的执行动作的集合;策略函数π(·)表示在给定状态St下选择动作At的概率分布。
第三,奖励函数。奖励函数通过网络性能指标等因素,量化智能体在状态St下选择动作At后所获得的即时奖励。
第四,价值函数。通过计算状态价值函数来表示在状态St下的预期累积奖励,并通过式(1)和式(2)进行计算。
强化学习方法会根据网络状态St的特征采取相应的动作At,当网络拓扑结构存在问题时,智能体会根据当前状态下各路径的动作值,选择具有最大值的动作,即调整流量分配,以实现网络中路径的动态调整,公式为
式中:arg max 表示某个函数取得最大值时的参数值。式(5)表示在给定状态St下,选择使动作值函数Q(St,a)达到最大的动作a,即智能体在某个状态下采取的最优动作。当状态特征为流量信息时,智能体通过激活函数Soft(·)调整策略,根据动作值的概率分布选择适应当前拥塞情况的动作,实现流量在网络中的灵活调整,公式为
当状态特征表现为网络性能指标时,基于网络性能指标等因素计算即时奖励,以量化智能体在当前状态下选择动作后的效果。
3 实验与分析
3.1 仿真环境
为验证所提方法的有效性,文章采用Mininet 仿真工具构建仿真环境[10]。网络拓扑参数如表1 所示。

表1 网络拓扑参数
表1 列出了Mininet 仿真环境中的网络拓扑参数值,其中节点数表示网络中的交换机和主机连接点的数量;连接数表示网络中的链路数量;带宽表示链路的带宽容量;拓扑类型选用树状拓扑,以模拟实际网络环境;控制器数表示SDN 网络中的控制器数量;SDN 应用数表示网络中应用的SDN 网络架构数量。
3.2 实验与结果讨论
实验过程包括以下几个步骤。
第一步,环境搭建。使用Mininet 工具构建网络仿真环境,设定节点数、连接数、带宽以及延迟等参数。
第二步,数据采集。在仿真环境中运行基于强化学习的流量优化与拥塞控制方法,通过监测网络状态、动作选择、奖励等信息,采集实验数据。
第三步,性能评估。通过对比实验前后网络的性能指标,如吞吐量、延迟、拥塞情况等,评估强化学习方法对网络性能的影响。其中,吞吐量表示网络的数据传输能力,平均延迟表示数据传输的延时,拥塞情况用于反映网络中是否存在拥塞现象。实验结果如表2 所示。

表2 实验结果
通过实验结果对比可知,基于强化学习的流量优化与拥塞控制方法能够有效提升网络性能。利用该方法后,网络吞吐量提升至95 Mb/s,平均延迟降低至10 ms,拥塞情况显著减少。由此可知,文章所提方法在实验环境中取得了显著的性能优化效果。
4 结 论
文章提出一种基于强化学习的流量优化与拥塞控制方法,并通过实验证实了该方法的有效性,为SDN 网络中的性能提升提供了一种新的解决思路。在网络拓扑参数固定的情况下,实验结果表明,所提方法在吞吐量、延迟等方面均取得了显著改善。通过动态调整流量分配和拥塞感知调整策略,强化学习方法成功地提高了SDN 网络的自适应性和智能化水平。该研究为SDN 网络中流量优化与拥塞控制问题的解决提供了新的理论支持和实用经验,具有一定的理论和应用价值。未来的研究方向可在进一步优化强化学习算法、扩展网络拓扑结构等方面展开,以更好地适应不同场景下的网络环境。
