基于深度学习的行人和车辆检测与跟踪研究
2024-04-14袁旻颉罗荣芳陈静苏成悦
袁旻颉 罗荣芳 陈静 苏成悦

DOI:10.19850/j.cnki.2096-4706.2024.01.025
收稿日期:2023-10-18
摘 要:针对行人及车辆的多目标检测和跟踪中检测精度不足及跟踪目标丢失和身份切换问题,文章提出一种改进YOLOv5与改进Deep SORT相结合的多目标检测跟踪算法。检测阶段使用Varifocal Loss替换二元交叉熵损失函数结合CA注意力机制和DIoU_NMS算法。跟踪阶段将Deep SORT的REID模块特征提取网络替换为EfficientNetV2-S。在COCO数据集检测上,map@0.5达到78%,比原始模型提升4.5%,在MOT16数据集跟踪上,MOTA达到58.1,比原始模型提升5.7,IDswitch减少了516次相当于减少了55.1%,测试结果表明該算法有较好的实际应用价值。
关键词:深度学习;目标检测;目标跟踪;计算机视觉
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2024)01-0121-05
Research on Pedestrian and Vehicle Detection and Tracking Based on Deep Learning
YUAN Minjie1, LUO Rongfang1, CHEN Jing1, SU Chengyue1,2
(1.School of Physics and Optoelectronic Engineering, Guangdong University of Technoology, Guangzhou 510006, China; 2.School of Advanced Manufacturing, Guangdong University of Technoology, Jieyang 515548, China)
Abstract: This paper proposes a multi-objective detection and tracking algorithm combining improved YOLOv5 and improved Deep SORT to address the issues of insufficient detection accuracy, lost tracking targets, and identity switching in pedestrian and vehicle's multi-target detection and tracking. Replacing binary cross entropy loss function with Varifocal Loss in the detection phase, combined with CA attention mechanism and DIoU_NMS algorithm. During the tracking phase, replace the feature extraction network of the REID module of Deep SORT with EfficientNetV2-S. In COCO dataset detection, map@0.5 reaches 78%, an improvement of 4.5% compared to the original model. On the MOT16 dataset tracking, the MOTA reaches 58.1, an improvement of 5.7 compared to the original model. The IDswitch is reduced by 516 times, which is equivalent to a reduction of 55.1%. The test results show that the algorithm has good practical application value.
Keywords: Deep Learning; object detection; object tracking; computer vision
0 引 言
传统交通系统需大量人力提取监控信息,效率低,实时性差,资源耗费大,需加入人工智能技术加以改善。目标检测和跟踪技术近年不断取得突破,成为交通系统应用的热点。Girshick等人于2014年发布的RCNN[1]是最早的基于卷积神经网络的两阶段目标检测模型,随后REN的Faster RCNN[2]等改进算法被提出。2016年REDMON等人提出YOLO[3]模型,这类基于卷积神经网络的单阶段目标检测模型效果极佳。随后YOLOX [4],YOLOv6 [5],YOLOv7 [6]等目标检测算法相继被提出,文献[7]基于多尺度注意力网络识别行人,文献[8]提出一种改进YOLOX的车辆检测方法。2016年Bewley提出了基于深度学习的跟踪算法SORT [9],2017年Bewley发布了它的改进版本Deep SORT [10]。文献[11]运用孪生网络进行目标跟踪,文献[12]提出一种自适应特征融合的目标跟踪算法,文献[13]是一种使用YOLOv5和DeepSORT的行人跟踪算法。文献[14]优化DeepSort对车辆实现跟踪。
复杂场景下会出现目标重复检测、遮挡、丢失、特征难以表达导致检测跟踪失败等问题。本文提出将损失函数替换为Varifocal Loss [15],结合CA注意力机制[16]和DIoU_NMS的改进YOLOv5模型,使用EfficientNetV2 [17]作为REID模块的特征提取网络的改进DeepSORT模型,将改进的YOLOv5与改进的DeepSORT结合的一种接缝检测和嵌入(joint detecting and embedding, JDE)跟踪算法[18],能有效提升检测精度和跟踪效果。
1 材料和方法
1.1 数据集处理
将COCO数据集2017版的人和车辆标签数据提取出来进行翻转、裁剪、尺度变换数据增强用于训练检测模型。共67 847张训练集图片和2 869张测试集图片,训练集中行人类标签实例数共262 465个,车辆类标签实例数共43 867个,测试集中行人类标签实例数共11 004个,车辆类标签实例数共1 932个。跟踪阶段reid模块的重识别模型训练使用Market-1501数据集,该数据集包含751类行人。MOT16数据集[19]的2,4,5,9,10,11,13号视频为跟踪数据集,将数据集中分别代表行人、驾驶员、车辆以及静止的人的1,2,3,7号标签提取出来,其他标签信息删除。
1.2 檢测模型改进
1.2.1 Varifocal Loss
本文将Vari focal Loss替换YOLOv5的分类损失和置信度损失使用的二元交叉熵损失。Vari Focal Loss[15]是一种密集目标检测器,作用是预测IACS(IoU-Aware Classification Score),相比二元交叉熵损失能更好地解决密集目标检测器训练中前景和背景不平衡的问题,Vari Focal Loss提出一种变焦思路对正负样本进行不对称处理,其定义如公式为:
(1)
其中p为预测的IACS,q为IoU得分。对前景点即正样本q为预测包围框和它的ground truth(真实包围框)之间的IoU,对背景点即负样本q为0,γ因子能缩放损失。正样本比负样本少应保留它们的学习信息,因此Vari Focal Loss仅减少了负例(q=0)的损失贡献。
1.2.2 注意力机制改进
本文分别选用ECA[20]、CA[16]注意力机制替换YOLOv5骨干网络中的C3层,实验对比各自效果,最终选择效果最优的CA注意力机制。
Coordinate Attention(CA)将横纵向的位置信息都进行编码使网络关注到大范围位置信息的同时计算量不大。流程如图1所示。
改进的YOLOv5网络结构如图2所示。分为输入端、骨干网络(Backbone)、Neck网络和输出端。输入端对输入图像进行归一化、统一尺寸、数据增强等操作;骨干网络为基准网络对输入数据特征提取;Neck网络进一步提升特征的表达能力,输出端即head端以分类回归实现预测检测。其中C3-CA即本文将CA注意力机制替换YOLOv5的C3层。
1.2.3 DIoU_NMS
原始YOLOv5采用NMS算法,预测阶段会预测出多个预测框,需将重复预测及置信度低的框去除,NMS将置信度最高的预测框与其他框进行IoU比对,移除超过预定阈值的框,除该置信度最高的框外,再将其余的框重复操作,直到所有框满足阈值。因为实际场景中会出现大量重叠目标,导致IoU超过阈值而被NMS去除,本文采用DIoU[21]替换掉NMS中的IoU,DIoU更符合目标框回归机制,能一并考虑目标与anchor间距和重叠率及尺度,其定义如式(2):
(2)
其中b,bgt分别为预测框与真实框的中心点,ρ为计算两点间的欧式距离,c为同时包含预测框与真实框的最小闭包区域的对角线距离。
1.3 跟踪模型改进
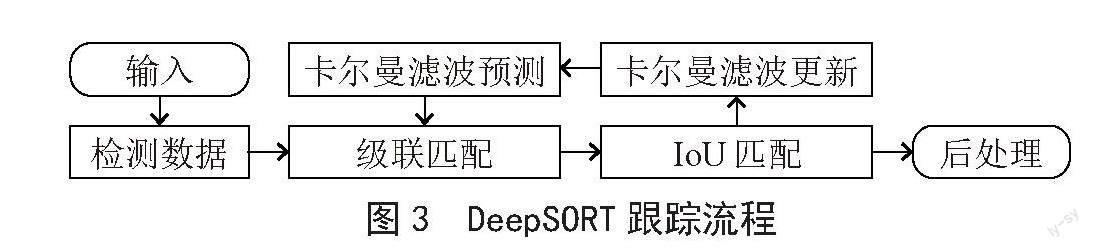
DeepSORT模型采用匀速线性的卡尔曼滤波器预测目标下一帧的运动状态,对预测的位置信息与检测结果进行级联匹配和IoU匹配,更新卡尔曼滤波预测的信息,再重复上述步骤。主要流程如图3所示。
其中级联匹配利用了马氏距离和reid外观特征重识别,本文将reid外观特征重识别模块的特征提取网络替换为EfficientNetV2-S。
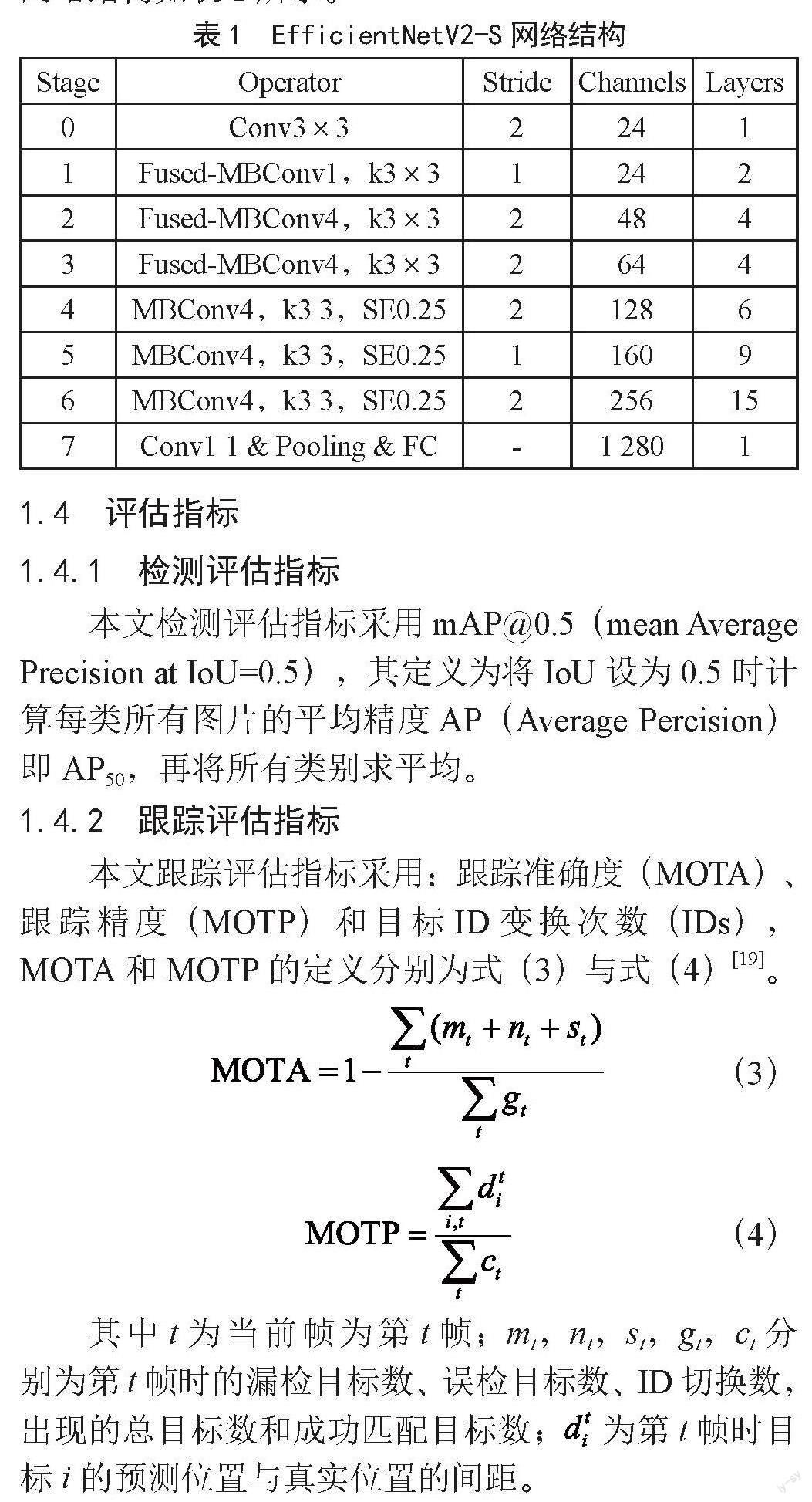
EfficientNetV2比Resnet训练速度更快,采用Fused-MBConv网络模块和渐进式学习策略,EfficientNetV2-S网络结构如表1所示。
1.4 评估指标
1.4.1 检测评估指标
本文检测评估指标采用mAP@0.5(mean Average Precision at IoU=0.5),其定义为将IoU设为0.5时计算每类所有图片的平均精度AP(Average Percision)即AP50,再将所有类别求平均。
1.4.2 跟踪评估指标
本文跟踪评估指标采用:跟踪准确度(MOTA)、跟踪精度(MOTP)和目标ID变换次数(IDs),MOTA和MOTP的定义分别为式(3)与式(4)[19]。
(3)
(4)
其中t为当前帧为第t帧;mt,nt,st,gt,ct分别为第t帧时的漏检目标数、误检目标数、ID切换数,出现的总目标数和成功匹配目标数; 为第t帧时目标i的预测位置与真实位置的间距。
2 实验及结果分析
2.1 环境和参数
表2为实验的硬件环境和使用的深度学习框架。
检测阶段Vari focal Loss损失函数使用的参数是α,γ分别设为0.5和1;batch_size设16,epochs为100,以YOLOv5 m为预训练模型,采用LambdaLR学习率调度器,初始学习率取0.01,循环学习率取0.2,warmup_epoch取3。
跟踪阶段reid模块训练重识别模型epoch为300,采用warm up+CosineAnnealingLR的学习率衰减法,warmup_epoch取5,初始学习率取0.1,循环学习率取0.1,跟踪测试取NMS的IoU阈值为0.5,MAX_AGE取70。
2.2 檢测结果对比
依次在YOLOv5上加入四种注意力机制消融实验与使用Varifocal Loss和DIoU_NMS的YOLOv5实验,同时与Faster R-CNN进行对比,实验结果如表3所示。
结果表示在本文处理的COCO数据集下结合CA注意力机制Varifocal Loss和DIoU_NMS的YOLOv5相比于原始YOLOv5在行人目标上AP50提升了3.3%,在车辆目标上AP50提升了5.7%,mAP@0.5提升了4.5%,验证了改进对检测效果有明显提升。
2.3 跟踪结果对比
分别将YOLOv5与DeepSORT,YOLOv5与改进DeepSORT,改进YOLOv5与DeepSORT,改进YOLOv5与改进DeepSORT结合对比,在MOT16数据集进行跟踪测试对比,实验结果如表4所示。
结果显示本文对YOLOv5和DeepSORT的改进策略对跟踪结果都有提升,MOTA提升了5.7,MOTP提升了0.6,IDswitch即IDs减少了516次相当于减少了55.1%的ID变化率。验证了改进对跟踪效果有提升。
将跟踪结果可视化,如图4分别为YOLOv5结合DeepSORT以及改进YOLOv5结合改进DeepSORT的效果截图,可见本文算法ID为70号、49号、35号的小目标被成功跟踪,被49号目标遮挡的目标和被建筑物遮挡的13号、81号目标也被成功跟踪。
3 结 论
本文针对城市中行人和车辆目标,将YOLOv5结合DeepSORT的多目标检测跟踪算法进行改进,将YOLOv5分类损失和置信度损失的损失函数替换为Varifocal Loss,提升了训练的拟合度,结合CA注意力机制提升检测模型的特征提取能力,使用DIoU_NMS更好地筛选预测框。将DeepSORT的reid模块中的特征提取网络替换为EfficientNetV2-S,通过重新训练目标重识别模型,提升了DeepSORT的重识别能力。由实验结果可知,改进算法在COCO数据集的检测效果以及在MOT-16上的跟踪效果有所提升,在遮挡场景及多目标场景下目标ID变换次数和目标丢失数显著减少。在目标检测算法上加入跟踪技术有较好的实际应用价值。
参考文献:
[1] GIRSHICK R,DONAHUE J,DARRELL T,et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation [C]//2014 IEEE conference on computer vision and pattern recognition.Columbus:IEEE,2014:580-587.
[2] REN S Q,HE K M,GIRSHICK R,et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[3] REDMON J,DIVVALA S,GIRSHICK R,et al. You Only Look Once: Unified, Real-Time Object Detection [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR).Las Vegas:IEEE,2016:779-788.
[4] GE Z,LIU S T,WANG F,et al. Yolox: Exceeding Yolo Series in 2021 [J/OL].arXiv:2107.08430 [cs.CV].[2023-09-27].https://arxiv.org/abs/2107.08430.
[5] LI C Y,LI L L,JIANG H L,et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications [J/OL].arXiv:2209.02976 [cs.CV].[2023-09-28].https://arxiv.org/abs/2209.02976.
[6] WANG C Y,BOCHKOVSKIY A,LIAO H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors [C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition.Vancouver:IEEE,2023:7464-7475.
[7] 武鑫森.基于深度学习的行人属性识别及应用 [J].现代信息科技,2023,7(17):61-65+70.
[8] 徐慧智,蒋时森,王秀青,等.基于深度学习的车载图像车辆目标检测和测距 [J].吉林大学学报:工学版,2023:1-13.
[9] BEWLEY A,GE Z Y,OTT L,et al. Simple online and realtime tracking [C]//2016 IEEE international conference on image processing (ICIP).Phoenix:IEEE,2016:3464-3468.
[10] WOJKE N,BEWLEY A,PAULUS D. Simple online and realtime tracking with a deep association metric [C]//2017 IEEE international conference on image processing (ICIP).Beijing:IEEE,2017:3645-3649.
[11] 苗宗成,高世严,贺泽民,等.基于孪生网络的目标跟踪算法 [J].液晶与显示,2023,38(2):256-266.
[12] 朱冰,刘琦,余瑞星.复杂场景下自适应特征融合的图像运动目标跟踪算法研究[J].航空兵器,2023,30(2):125-130.
[13] 张梦华.基于Yolov5和DeepSort的视频行人识别与跟踪探究 [J].现代信息科技,2022,6(1):89-92.
[14] 金立生,华强,郭柏苍,等.基于优化DeepSort的前方车辆多目标跟踪 [J].浙江大学学报:工学版,2021,55(6):1056-1064.
[15] ZHANG H Y,WANG Y,DAYOUB F,et al. VarifocalNet:An IoU-aware Dense Object Detector [C]//2021 IEEE/CVF conference on computer vision and pattern recognition.Nashville:IEEE,2021:8510-8519.
[16] HOU Q B,ZHOU D Q,FENG J S. Coordinate Attention for Efficient Mobile Network Design [C]//2021 IEEE/CVF conference on computer vision and pattern recognition. 2021:Nashville:IEEE,2021:13708-13717.
[17] TAN M X,LE Q V. EfficientNetV2:Smaller Models and Faster Training [J/OL].arXiv:2104.00298 [cs.CV].[2023-09-28]. https://arxiv.org/abs/2104.00298.
[18] WANG Z D,ZHENG L,LIU Y X,et al. Towards real-time multi-object tracking[J/OL].arXiv:1909.12605[cs.CV].[2023-09-28].https://arxiv.org/abs/1909.12605v2.
[19] MILAN A,LEAL-TAIX? L,REID I,et al. MOT16:A benchmark for multi-object tracking [J/OL].arXiv:1603.00831 [cs.CV].[2023-09-28].https://arxiv.org/abs/1603.00831v2.
[20] WANG Q L,WU B G,ZHU P F,et al. ECA-Net:Efficient channel attention for deep convolutional neural networks [J/OL].arXiv:1910.03151 [cs.CV].[2023-09-28].https://arxiv.org/abs/1910.03151v1.
[21] ZHENG Z H,WANG P,LIU W,et al. Distance-IoU loss:Faster and better learning for bounding box regression[J/OL].arXiv:1911.08287 [cs.CV].[2023-09-28].https://arxiv.org/abs/1911.08287v1.
作者简介:袁旻颉(1999—),男,汉族,广东东莞人,工程师,硕士,主要研究方向:计算机视觉、机器学习、图像处理;罗荣芳(1965—),男,汉族,江西吉水人,副教授,博士,主要研究方向:信息处理、人工智能技术、生物特征识别技术等;陈静(1980—),女,汉族,广东广州人,副教授,博士,主要研究方向:机器學习、图像处理等;苏成悦(1961—),男,汉族,湖南长沙人,教授,博士,主要研究方向:应用物理。
