基于改进YOLOv7的滑雪摔倒检测
2024-04-14陈园林高兴华吴晗林
陈园林 高兴华 吴晗林
DOI:10.19850/j.cnki.2096-4706.2024.01.017
收稿日期:2023-06-06
基金项目:吉林省科技发展计划项目(20220203179SF)
摘 要:针对目前滑雪场内滑雪人员摔倒检测存在的问题,提出一种基于YOLOv7的目标改进模型。对于检测模型部署在巡逻机器人上致使计算资源受限的问题,在主干网络中引入Ghost模型并在颈部引入GSConv降低模型参数;同时,引入基于并行可变形卷积的注意力机制模块(Parallel Deformable Attention Conv, PDAC)增强模型的精度。改进后的模型相较于原模型在参数上降低了21.6%,GFLOPs降低了27.7%,所需要的计算资源也大大降低。
关键词:目标检测技术;YOLOv7;滑雪摔倒检测;轻量化模型
中图分类号:TP391.4 文献标识码:A 文章編号:2096-4706(2024)01-0084-05
Ski Fall Detection Based on Improved YOLOv7
CHEN Yuanlin, GAO Xinghua, WU Hanlin
(Beihua University, Jilin 132013, China)
Abstract: A target improvement model based on YOLOv7 is proposed to address the current issues in detecting falls among skiers in ski resorts. For the problem of limited computing resources caused by deploying detection models on patrol robots, the Ghost model is introduced into the backbone network and GSConv is introduced in the neck to reduce model parameters; meanwhile, the Parallel Deformable Attention Conv (PDAC) module is introduced to enhance the accuracy of the model. The improved model has reduced parameters by 21.6% and GFLOPs by 27.7% compared to the original model, and the required computational resources have also been greatly reduced.
Keywords: target detection technology; YOLOv7; ski fall detection; lightweight model
0 引 言
随着冬奥会的举办,滑雪运动逐渐变得火热。近年来,我国滑雪场数量不断增加,滑雪人数年均超2 000万人次[1-3]。滑雪人数增长的同时,滑雪事故也在不断增加,每年都有因滑雪而造成的伤亡[4]。目前针对摔倒检测的方法主要有传感器检测和利用视觉算法的检测。由于滑雪运动速度较快,对传感器检测影响很大,传感器不能准确的判断是否为正常运动中的加速状态,还是摔倒状态。而基于视觉方法的检测可以提高检测的精度。
基于计算机视觉的目标检测,主要是对图片或视频帧中所要识别的物体进行定位并分类。在深度学习没有普及之前,传统的目标检测需要手工提取目标特征[5],而基于深度学习的目标检测算法解决了此问题。根据算法特性基于深度学习的目标检测算法分为一阶段检测算法和二阶段检测算法,一阶段检测算法主要以YOLO系列、SSD等为代表[6,7],二阶段检测算法主要以R-CNN、FasterR-CNN为代表[8,9]。
在使用目标检测算法对雪场摔倒人员进行检测时,由于雪场滑雪人员较多,容易对待检测目标造成遮挡。并且雪场范围很大,在远处的待检测目标在检测场景中占比很小,以至于很难准确地进行检测。其次,在同一场景中可能存在大尺度或小尺度的待检测目标,尺度不同也很容易造成检测器的漏检。最终,滑雪场摔倒人员检测技术的部署不仅需要高精度,还需要较高的检测速度,以满足在复杂情况下的实时检测,并且因为模型是部署在移动机器人上,计算资源受限,不能承载参数量很大的模型。
为了解决上述问题,构建了一种基于改进YOLOv7的滑雪摔倒目标检测算法。引入Ghost模块降低模型的参数,并引入并行可变形卷积注意力机制模块,减少特征提取过程中骨干网络造成的空间信息损失[10]。同时在颈部引入GSConv,进一步降低参数的同时,增强其非线性表达能力[11]。
1 YOLOv7概述
YOLOv7[12]是YOLO系列中最新推出的模型,根据部署对象的不同,分别为YOLOv7-Tiny、YOLOv7和YOLOv7-W6。YOLOv7的识别精度和识别速度已经超过了目前大部分检测器,结构和前几代YOLO模型类似。
YOLOv7算法框架主要由主干网络(Backbone)、颈部(Neck)、预测头(Head)三部分组成,其算法会对输入的图片做一系列的数据增强操作,目的是提高检测的精确度。经过数据增强后的图片被送进主干网络中,主干网络对图片进行特征提取,然后将其以三个不同尺度的输出送入颈部当中。三个不同尺度的特征会在颈部进行信息流动并融合,融合后的特征被送入头部,检测后输出结果。
YOLOv7模型的主干网络主要采用ELAN模块,该模块是一种高效的网络结构,它通过控制最短梯度路径实现更多的堆叠,获得更强的学习能力和更多的学习信息,增加模型的预测精度。为了增大感受野,使得算法对不同尺度的图像具有良好的适用性,还采用了SPPCSPC模块,模块通过三个不同尺度的Maxpool操作来区分大小不同的物体,提高了网络的适用性。
2 网络模型改进
为了满足滑雪摔倒检测的实时性和精确性目标,提出了一种基于YOLOv7算法改进的目标检测模型,结构如图1所示。改进算法的主要目标是降低模型的参数量,降低模型运算需要的计算资源,在此基础上获得良好的检测精度。
2.1 PDAC注意力机制模块
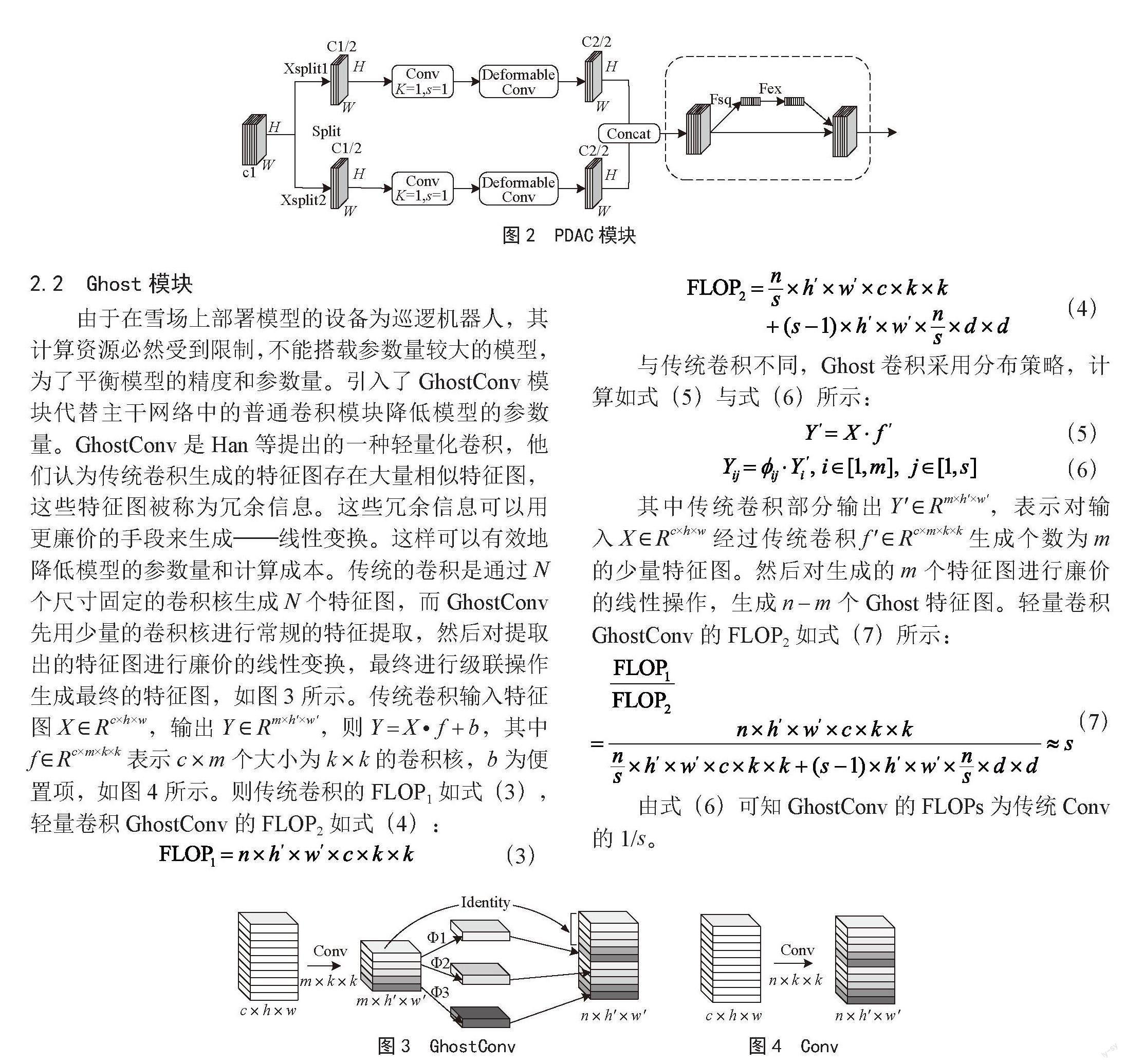
注意力机制是机器学习中一种特殊的模块,一张图片中包含着丰富的语义信息,但不是所有的信息都是重要的。注意力机制分为空间注意力机制、通道注意力机制和混合注意力机制,还有最近兴起的可变形注意力机制DETR等[13]。
基于前人提出的注意力机制的启发,提出了一种可变形注意力机制,在注意力机制中引入可变形卷
积[14],即PADC,如图2所示。PADC可以自适应地改变感受野的大小,减少特征图语义的损失。在PADC模块中,我们首先将特征图在通道上进行等分,通过两个分支对其进行可变形卷积改变其感受野的大小,并将两个分支做通道上的连接。其次将每个通道的二维特征通过全局平均池化压缩为一个实数,将特征图从[h,w,c]变换为[1,1,c],再给每个特征通道生成一个权重值,最后将得到的归一化权重加权到每个通道的特征上,可变形注意力机制输出如式(2)所示。图2中,Conv表示卷积核大小为1、步长为1的标准卷积,对输入的特征图进行尺度的调整,受到可变形卷积网络的启发,其感受野不受限于原来的正方形状,而可以是任意的形状,能够自适应尺寸和姿态的变化。在雪场中,滑雪人员所处的远近及姿态不同,可变形卷积可以更好地适应这种尺度和姿态的变化。
(1)
(2)
2.2 Ghost模块
由于在雪场上部署模型的设备为巡逻机器人,其计算资源必然受到限制,不能搭载参数量较大的模型,为了平衡模型的精度和参数量。引入了GhostConv模块代替主干网络中的普通卷积模块降低模型的参数量。GhostConv是Han等提出的一种轻量化卷积,他们认为传统卷积生成的特征图存在大量相似特征图,这些特征图被称为冗余信息。这些冗余信息可以用更廉价的手段来生成——线性变换。这样可以有效地降低模型的参数量和计算成本。传统的卷积是通过N个尺寸固定的卷积核生成N个特征图,而GhostConv先用少量的卷积核进行常规的特征提取,然后对提取出的特征图进行廉价的线性变换,最终进行级联操作生成最终的特征图,如图3所示。传统卷积输入特征图X ∈ Rc×h×w,输出Y ∈ Rm×h'×w',则Y = X · f + b,其中f ∈ Rc×m×k×k表示c×m个大小为k×k的卷积核,b为便置项,如图4所示。则传统卷积的FLOP1如式(3),轻量卷积GhostConv的FLOP2如式(4):
(3)
(4)
與传统卷积不同,Ghost卷积采用分布策略,计算如式(5)与式(6)所示:
(5)
(6)
其中传统卷积部分输出Y' ∈ Rm×h'×w',表示对输入X ∈ Rc×h×w经过传统卷积f ' ∈ Rc×m×k×k生成个数为m的少量特征图。然后对生成的m个特征图进行廉价的线性操作,生成n - m个Ghost特征图。轻量卷积GhostConv的FLOP2如式(7)所示:
(7)
由式(6)可知GhostConv的FLOPs为传统Conv的1/s。
2.3 GSConv模块
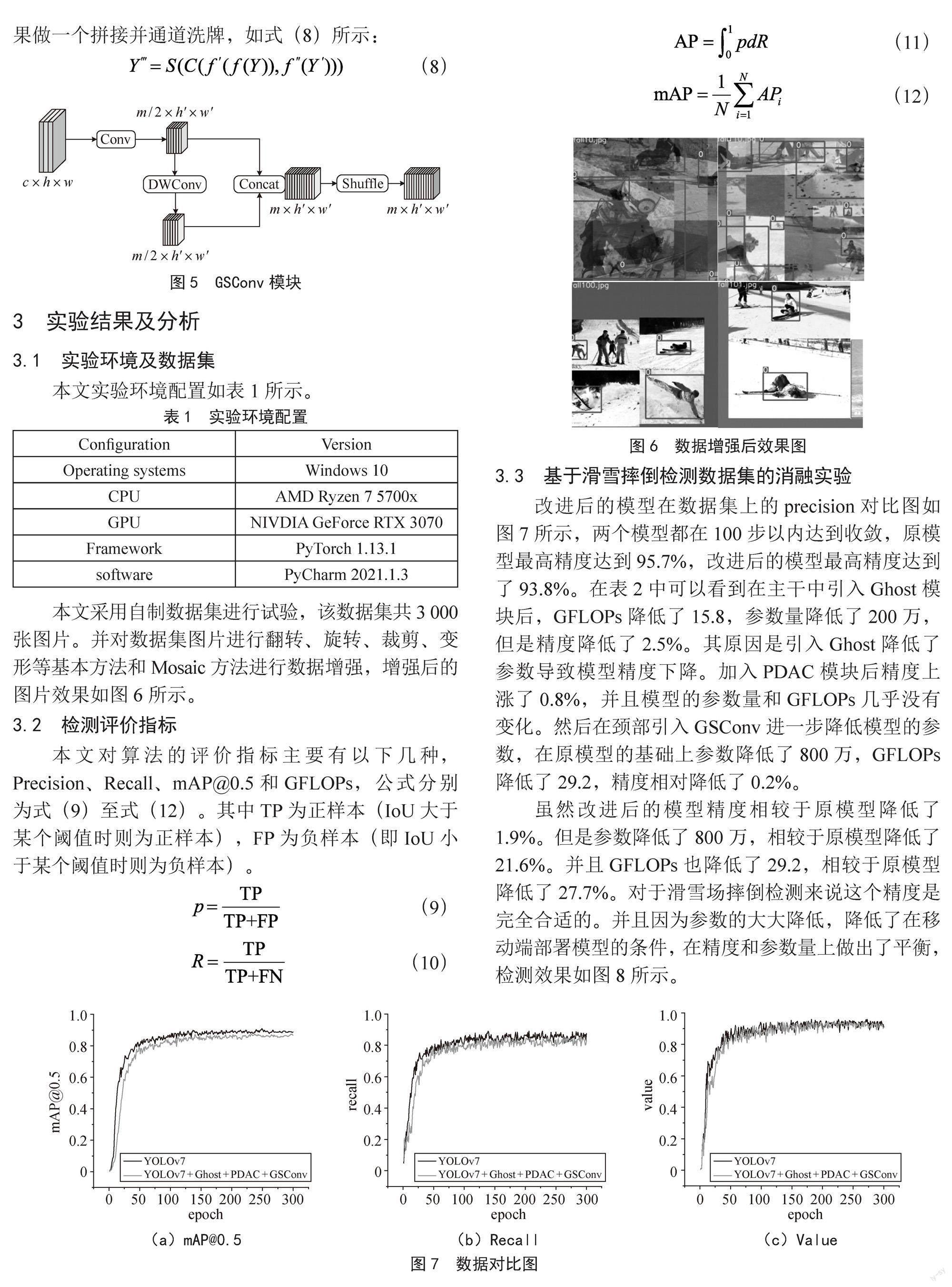
在进行目标检测任务中,参数越多检测精度相对来说也越高,但是推理速度会因为参数的增多而减慢,并且因为参数的增多很难部署到一些计算资源少的设备上,为此我们在特征融合阶段引入了GSConv模块,如图5所示。传统的卷积随着网络深度的增加,特征图的尺寸会被压缩,并且通道会进行扩张,这会造成浅层语义的丢失,通道之间的隐藏联系也会减少。GSConv可以用较低的时间复杂度尽可能地保留这些联系。GSConv对轻量型检测模型的影响非常明显,它增加了深度可分离卷积层[15]和通道洗牌,增加模型的非线性表达能力。但是我们并没有选择在骨干网络中采用GSConv模块。虽然GSConv模快能大幅度地降低模型的参数量,但同时也带来网络层数的加深,伴随网络层数的加深,数据流的阻力也相应增加,这会造成模型推理速度变慢。但若将其部署在颈部则完全克服了这个问题,当特征图输入到颈部时特征图的尺寸已经变得很小了,这时采用GSConv来处理串联特征图是最好的选择,冗余信息大大减少。所以在颈部引入GSConv模型可降低模型的参数量,并增强其非线性表达能力,能够更好地进行特征融合使深层的语义信息和浅层的语义信息得到更加充分补充,以此来增强模型的精度。输入X ∈ Rc×h×w,经过f ∈ Rc×m/2×k×k变换后输出Y ∈ Rm/2×h'×w',输出Y再经过f ' ∈ Rm/2×k×k得到Y' ∈ Rm/2×h'×w'。再将输出经由大小为1×1、个数为m/2×m/2的卷积核得到Y' ∈ Rm/2×h'×w'。再将两部分结果做一个拼接并通道洗牌,如式(8)所示:
(8)
3 实验结果及分析
3.1 实验环境及数据集
本文实验环境配置如表1所示。
本文采用自制数据集进行试验,该数据集共3 000张图片。并对数据集图片进行翻转、旋转、裁剪、变形等基本方法和Mosaic方法进行数据增强,增强后的图片效果如图6所示。
3.2 检测评价指标
本文对算法的评价指标主要有以下几种,Precision、Recall、mAP@0.5和GFLOPs,公式分别为式(9)至式(12)。其中TP为正样本(IoU大于某个阈值时则为正样本),FP为负样本(即IoU小于某个阈值时则为负样本)。
(9)
(10)
(11)
(12)
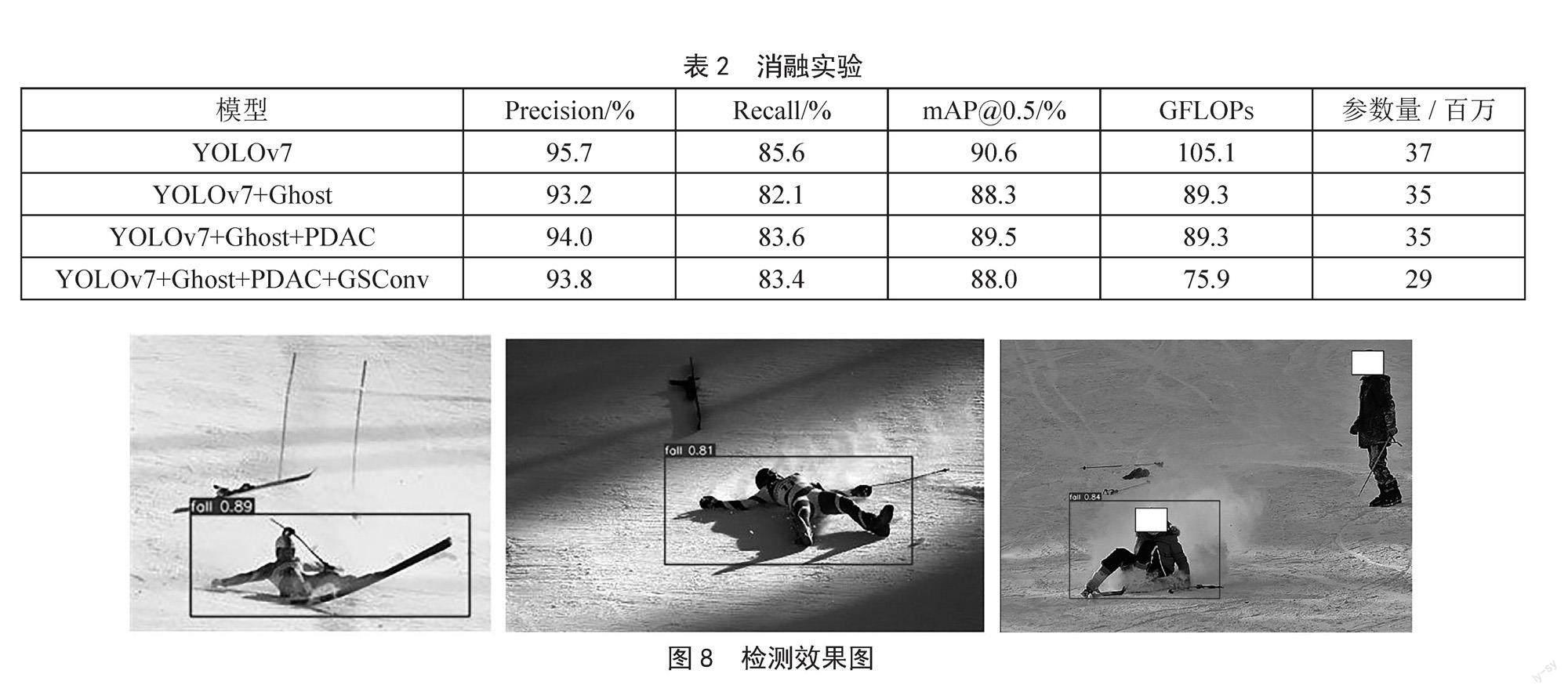
3.3 基于滑雪摔倒检测数据集的消融实验
改进后的模型在数据集上的precision对比图如图7所示,两个模型都在100步以内达到收敛,原模型最高精度达到95.7%,改进后的模型最高精度达到了93.8%。在表2中可以看到在主干中引入Ghost模块后,GFLOPs降低了15.8,参数量降低了200万,但是精度降低了2.5%。其原因是引入Ghost降低了参数导致模型精度下降。加入PDAC模块后精度上涨了0.8%,并且模型的参数量和GFLOPs几乎没有变化。然后在颈部引入GSConv进一步降低模型的参数,在原模型的基础上参数降低了800万,GFLOPs降低了29.2,精度相对降低了0.2%。
虽然改进后的模型精度相较于原模型降低了1.9%。但是参数降低了800万,相较于原模型降低了21.6%。并且GFLOPs也降低了29.2,相较于原模型降低了27.7%。对于滑雪场摔倒检测来说这个精度是完全合适的。并且因为参数的大大降低,降低了在移动端部署模型的条件,在精度和参数量上做出了平衡,检测效果如图8所示。
4 结 论
本文在YOLOv7原有算法框架上进行了改进。在主干采用GhostConv代替了一部分传统卷积对模型进行轻量化处理,并在颈部采用GSConv对深层和浅层的语义进行融合,进一步降低模型的复杂度,模型参数相较于原模型降低了21.6%。并引入注意力机制模块改善因参数量的降低对网络精度造成的损失,在降低原有模型参数的基础上获得了较好的精度,实现了计算资源受限的移动端设备的目标检测。下一步将根据现有的研究结果对跌倒检测进行目标跟踪研究。
参考文献:
[1] 赵建滕.我国滑雪产业发展困境及对策 [J].合作经济与科技,2022(16):27-29.
[2] DISHMAN R K,HEATH G W,SCHMIDT M D,et al. Physical Activity Epidemiology:Third edition [M].Champaign:Human Kinetics Publishers,2021.
[3] 王琳.运动医学 [M].北京:北京体育大学出版社,2016:113.
[4] 林俐,张晓军,王举翠.滑雪场安全风险及防范措施研究 [J].中国应急管理,2021(11):63-65.
[5] ZOU Z X,CHEN K Y,SHI Z W,et al. Object Detection in 20 Years: A Survey [J].Proceedings of the IEEE,2023,11(3):257-276.
[6] REDMON J,DIVVALA S,GIRSHICK R,et al. You Only Look Once: Unified, Real-Time Object Detection [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:779-788.
[7] LIU W,ANGUELOV D,ERHAN D,et al. SSD: Single Shot MultiBox Detector [C]//Computer Vision–ECCV 2016.The Netherlands:Springer,2016:21-37.
[8] GIRSHICK R,DONAHUE J,DARRELL T,et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation [C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus:IEEE,2014:580-587.
[9] REN S Q,HE K M,GIRSHICK R,et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[10] HAN K,WANG Y H,TIAN Q,et al. GhostNet: More Features From Cheap Operations [C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR).Seattle:IEEE,2020:1577-1586.
[11] LI H L,LI J,WEI H B,et al. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles [J/OL].arXiv:2206.02424 [cs.CV].(2022-08-17)[2023-05-06].https://arxiv.org/abs/2206.02424.
[12] WANG C Y,BOCHKOVSKIY A,LIAO H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors [J/OL].arXiv:2207.02696 [cs.CV].(2022-07-06)[2023-05-06].https://arxiv.org/abs/2207.02696.
[13] ZHU X Z,SU W J,LU L W,et al. Deformable DETR: Deformable Transformers for End-to-End Object Detection [J/OL].arXiv:2010.04159 [cs.CV].(2020-08-08)[2023-05-06].https://arxiv.org/abs/2010.04159.
[14] DAI J F,QI H Z,XIONG Y W,et al. Deformable Convolutional Networks [J/OL].arXiv:1703.06211 [cs.CV].(2017-06-05)[2023-05-06].https://arxiv.org/abs/1703.06211v2.
[15] CHOLLET F. Xception: Deep Learning with Depthwise Separable Convolutions [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Columbus:IEEE,2017:1251-1258.
作者簡介:陈园林(1996—),男,汉族,黑龙江鹤岗人,硕士研究生在读,主要研究方向:计算机视觉;通讯作者:高兴华(1966—),女,汉族,吉林吉林人,硕士生导师,教授,硕士,主要研究方向:特种机器人;吴晗林(1996—),男,汉族,山东青岛人,硕士研究生在读,主要研究方向:自主导航。
