一种基于深度Q网络改进的低轨卫星路由算法
2024-04-14许向阳彭文鑫李京阳
许向阳 彭文鑫 李京阳
DOI:10.19850/j.cnki.2096-4706.2024.01.014
收稿日期:2023-06-05
摘 要:针对卫星节点高速移动,导致节点之间链路状态变化过快的问题,对基于深度强化学习的卫星路由算法进行了研究,由此提出一种基于深度Q网络改进的卫星路由算法。算法采用虚拟节点的思想,以最小跳数为原则,将跳数和距离设置为奖励函数相关参数。同时设置优先经验回放机制,使得算法训练中学习价值最高的样本;最后对网络进行参数的设置并且进行训练。仿真结果表明,从网络传输时延、系统吞吐量、丢包率方面有明显的提升,能有效地适应卫星节点之间链路状态高动态变化。
关键词:卫星路由;虚拟节点;优先经验回放;深度Q网络
中图分类号:TN927+.2 文献标识码:A 文章编号:2096-4706(2024)01-0067-05
An Improved Low-orbit Satellite Routing Algorithm Based on DQN
XU Xiangyang, PENG Wenxin, LI Jingyang
(School of Information Science and Engineering, Hebei University of Science and Technology, Shijiazhuang 050018, China)
Abstract: To deal with the problem of fast-changing link-state between satellite nodes due to high-speed movement of satellite nodes, a satellite routing algorithm based on deep reinforcement learning is studied, and an improved satellite routing algorithm based on DQN is proposed. The algorithm adopts the idea of virtual nodes, and sets the number of hops and distance as the related parameters of reward function based on the principle of minimum hops. Meanwhile, a priority experience replay mechanism is set up to train the algorithm by learning samples with the highest value. Finally, the network is set in parameters and is trained. The simulation results show that there are significant improvements in network transmission delay, system throughput, and rate of packet loss, effectively adapting to high dynamic changes in link-state between satellite nodes.
Keywords: satellite routing; virtual node; priority experience replay; DQN
0 引 言
近年来,随着无线通信技术的发展与技术的迭代,地面基站受限于地形限制、抗毁性差等因素,无法真正实现全球覆盖。而卫星通信以其覆盖范围广、抗毁性强、不受地理环境约束等优势在移动通信领域得到广泛的应用[1]。相比于中、高轨卫星,低轨卫星具有传输时延更小、链路损耗较低、整体制造成本低等优势[2]。使得构建低轨卫星星座网络成为研究重点。与地面网络相比,低轨卫星网络存在诸多优势,但仍存在网络节点变化过快、节点处理能力不足[3],数据包传输效率较低等问题。网络拓扑结构存在高动态和时变性[4],使得地面网络的路由方法无法有效应用于低轨卫星网络。Taleb等人指出卫星网络内存在当局部节点已经处于高负载状态时,其他节点却一直处于空闲状态的情况,在此基础上提出了一种基于显示负载均衡(Explicitload Balancing, ELB)的算法。BominMao等人提出了一种基于张量的深度学习智能路由(A Tensor Based Deep Learning Technique for Intelligence Packet Routing)策略,根据开放式最短路径优先(Open Shortest Path First, OSPF)协议中的历史提取路由信息,針对每个源节点和目的节点对建立基于张量的深度信念网络(Tensor-based Deep Nelief Architecture, TDBA),利用深度信念网络提取路由信息中的深层维度特征,在应用时,只需要输入当前的路由信息张量即可得到最优的下一跳节点。深度强化学习对复杂问题具有强大的表征能力和解决能力[5],可以为解决问题提供了新的思路。针对低轨卫星的一些问题,本文设计一种基于深度强化学习改进的低轨卫星路由算法,该方法将整个卫星网络作为深度强化学习的环境,将卫星节点作为智能体。基于STK软件建立低轨卫星模型,选用极轨道星座模型中的铱星系统作为研究对象,由NS3平台负责输出结果,设计的算法应具备低时延、低丢包率以及较高系统吞吐量的特点。
1 深度Q网络
传统的强化学习算法在面对一些大状态空间或连续状态空间的学习任务时,通常需要耗费大量时间和计算资源才能学习到一个比较合理的解决方案。这是由于状态空间的维度很高,导致状态-动作空间的规模呈指数级增长,使得传统算法在搜索过程中面临维数灾难问题。
随着深度学习的发展,研究人员在强化学习中引入了神经网络,通过神经网络来估计动作价值,通过强化学习来获取最大化奖励。从而解决了状态空间维度高的问题。这种结合两者优势的方法被称为深度强化学习(Deep Reinforcement Learning, DRL)[6]。
在训练过程中,DQN使用经验回放和固定目标网络来提高学习效率和稳定性。但单一神经网络对状态-动作值进行估计,会高估动作的Q值,从而造成某些状态下次优动作奖励值会优于最优动作,从而找不到最优策略,导致算法训练不稳定。针对此情况,本文引入DQN算法作为路由算法的基础。
Dueling DQN算法通过将网络拆分为两个部分来进一步提高学习效率和稳定性[7,8]。这两个部分分别是状态价值函数和优势函数。价值函数V(s; α, θ)用来估计每个状态的价值,仅与状态有关,与将要执行的动作无关,优势函数A(s, α; β, θ)来估计每个动作的优劣程度,与状态动作都有关,最后的输出则将两者相加,如下所示:
(1)
其中α表示价值函数支路的网络参数,β表示优势函数支路的网络参数,θ表示卷积层公共部分的网络参数。但直接训练会存在将V值训练为固定值时,则算法变为DQN算法,则需要为神经网络增加一个约束条件,则Q值函数计算如下所示:
(2)
2 改进的Dueling DQN算法
2.1 经验回放机制的改进
在原始的RL算法中,每次使用完一个样本(st,at,rt,st+1)就丢弃,造成经验的浪费,并且相关性强,不利于模型的学习。对此情况,Nature DQN算法设置了经验池,为了更新深度神经网络的参数,从经验池中随机选择一小批样本作为训练更新的样本。使用经验回放机制,每次采样时都从经验池中随机选择样本。这种随机选择样本的方式可以有效打破样本之间的相关性,从而更好地训练深度神经网络。
随机采样是在经验池中等概率的随机选择样本,可能会存在信息价值较高的样本在神经网络的训练中使用率比较低甚至没有被使用过的情况,会使得训练次数增加导致训练效率变低。为防止出现此类问题,本章使用优先经验回放[9,10]来进行采样。核心思想是利用经验样本的重要性来加快学习速度和提高学习效果。在这种方法中,智能体会优先选择最有价值的一批样本来训练,提升深度强化学习的效率和性能。为了防止过拟合,低价值的样本也会有一定的概率被选择。优先经验回放样本采样见式(3)与式(4):
(3)
(4)
其中,P(t)表示第t个经验被采样的概率,pt表示样本优先级,α表示一个超参数,用于控制优先级的衰减速度。δt表示时间差分误差,又称为时序误差,通常用于衡量代理在执行动作后,对于预期奖励的估计值与实际奖励之间的差异。时序误差一般是用来更新行为值函数,时序误差绝对值越大,说明其学习价值越高。优先经验回放采用时序误差,可以使得增加价值高的样本的重要性和减少错误行为发生的概率。而ε的设置则是为了保证时序误差为零时采样概率不为零,时序误差计算公式由式(5)可得:
(5)
其中,Rt表示当前的奖励,γ表示衰减因子,Q′(St, At, θ′)是目标网络。在训练过程中,当从回放缓冲区中按照优先级采样一批经验样本进行训练时,优先级高的样本会被更频繁地选择进行训练,以提高重要经验样本的学习效率。优先经验回放步骤如下:
1)对于每个样本(st,at,rt,st+1),计算时序误差δt。
2)根据时序误差得出优先级高低,时序误差越大,优先级越高,将样本添加到经验回放缓冲区。
3)根据优先级高低对样本排序。
4)在每次训练时,从经验回放缓冲区按照优先级采样一批样本进行训练。
2.2 奖励函数
在使用DQN算法进行训练时,将奖励函数作为目标Q值的计算基础。在每个时间步,计算出当前状态下所有可能的行动的Q值,并根据当前的行动选择一个最优的行动,用于下一个时间步的状态转移。然后,我们可以计算当前状态下选择的行动的Q值和目标Q值之间的差异,将其作为样本的时序误差,用于训练DQN的神经网络。本节设置的路由算法的目标是在已知源节点和目的节点的情况下,选择合适的链路来进行数据传输。因此设定的奖励函数以最小跳数链路为优先选择。奖励函数R由跳数评价函数Hc、源节点与目的节点距离Di, j (t)构成。具体设置如式(6)所示:
(6)
其中μ,η表示权重参数,令其μ + η = 1,将最大奖励设置为Ra,Ra表示绝对值较大的正奖励,当下一跳为目的节点时,奖励最大,其他情况奖励均为负值。在奖励函数设置时,卫星执行当前动作后,下一跳节点距离和目的节点相对距离越近,奖励值越大。节点距离Di, j (t)可由升交点赤經的差值Δλ和真近地点角差值Δω来表示,见式(7):
(7)
(8)
在路由算法中,为了避免追求最大奖励值从而产生路由跳数过多的问题,设置路由最大跳数N,令当前跳数为n,可设置跳数评价函数Hc,见公式(8)。当跳数越来越大时,Hc趋向于1。
2.3 模型训练
在算法中,需要对模型的状态S、动作A、奖励函数R、状态转移概率P、折扣率γ进行设置。其中,状态S设置为链路状态,动作A设置为下一跳卫星节点,状态转移概率P为选择下一跳节点的概率,奖励函数R设置为当前路由到下一跳卫星节点的奖励,折扣率γ为未来期望奖励权重。模型训练是输入链路状态和目的节点,来选择到目的节点的最优下一跳节点。
在算法中,由于使用了优先经验回放,使得样本的分布发生改变,产生重要性采样权重,如式(9)所示:
(9)
其中,N表示样本容量,β为超参数,代表优先经验回放对收敛结果的影响程度,由此可得,采用优先经验回放的DQN算法的Loss函数如式(10)所示:
(10)
基于DQN改进的算法完整流程:
输入:网络拓扑G(V,E)、状态空间S、学习率λ、动作空间A、折扣率γ、目标网络更新参数频率F、回合M、迭代次数T。
输出:训练完成的DQN模型。
1)初始化经验池D、Q网络参数θ、目标Q网络θ′、α,β超参数;
2)for episode =1 to M do:
3) 初始化环境,得到初始状态St;
4) for iteration t =1 to T do:
5) 采用ε贪婪策略选择动作,随机选择一个动作;
6) 执行动作At,观察奖励Rt和下一个状态St+1;
7) 計算时序误差,存储经验到经验池D;
8) 将样本(st,at,rt,st+1)添加到经验池D中,更新优先级并从高到低进行排序;
9) 当经验池D中的样本大于某个阈值,从中删除优先级最低的样本;
10) 从经验池D中随机采样N个样本进行训练;
11) 对于每个(St,At,Rt,St+1)执行以下步骤;
12) if St+1是终止状态,则Q_target=Rt;
13) else 用目标Q网络计算Q_target = Rt + γ max Q′(St, At, θ′ );
14) 使用反向传播算法更新神经网络参数θ;
15) 计算当前状态下执行At的Q值Q(St,At),以及当前状态下所有行动的Q值;
16) 计算Q_target和Q(St,At)之间的时序误差δt;
17) 计算Loss函数;
18) 使用梯度下降算法更新Q值网络:θ = θ - λ*θ ? Loss;
19) 每隔F步更新目标Q网络:θ′←θ;
20) 更新状态S = St+1;
21) end for
22)end for
3 仿真
3.1 仿真参数设置
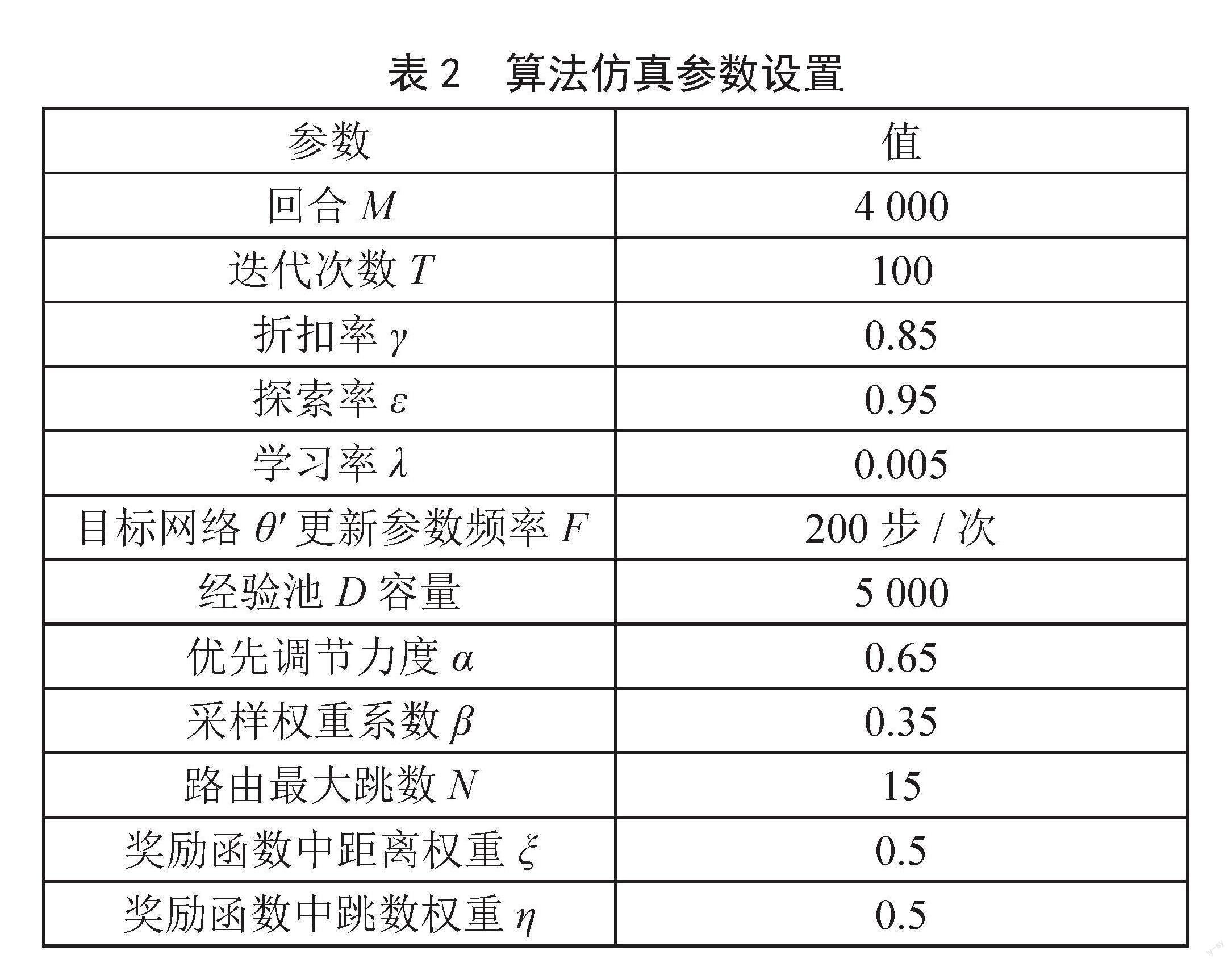
为了评估算法性能,利用NS3仿真软件,在一个类似铱星卫星网络中构建仿真。其中,66颗卫星分布在六个平面上。每颗卫星有两个层内链路和两个层间链路,层内链路一直连接,层间链路在反向缝区域断开。设置同层卫星链路带宽为25 Mbit/s,层间链路带宽为1.5 Mbit/s,队列缓冲大小为50 kB。数据包大小设置为1 kB,Hello包发送周期仿真时间设置为90 s。仿真参数和算法训练参数分别如表1和表2所示。
3.2 仿真结果分析
与本文算法进行对比的路由算法为SPF路由算法和ELB路由算法,将通过网络平均传输时延和丢包率以及系统吞吐量三个方面进行对比。
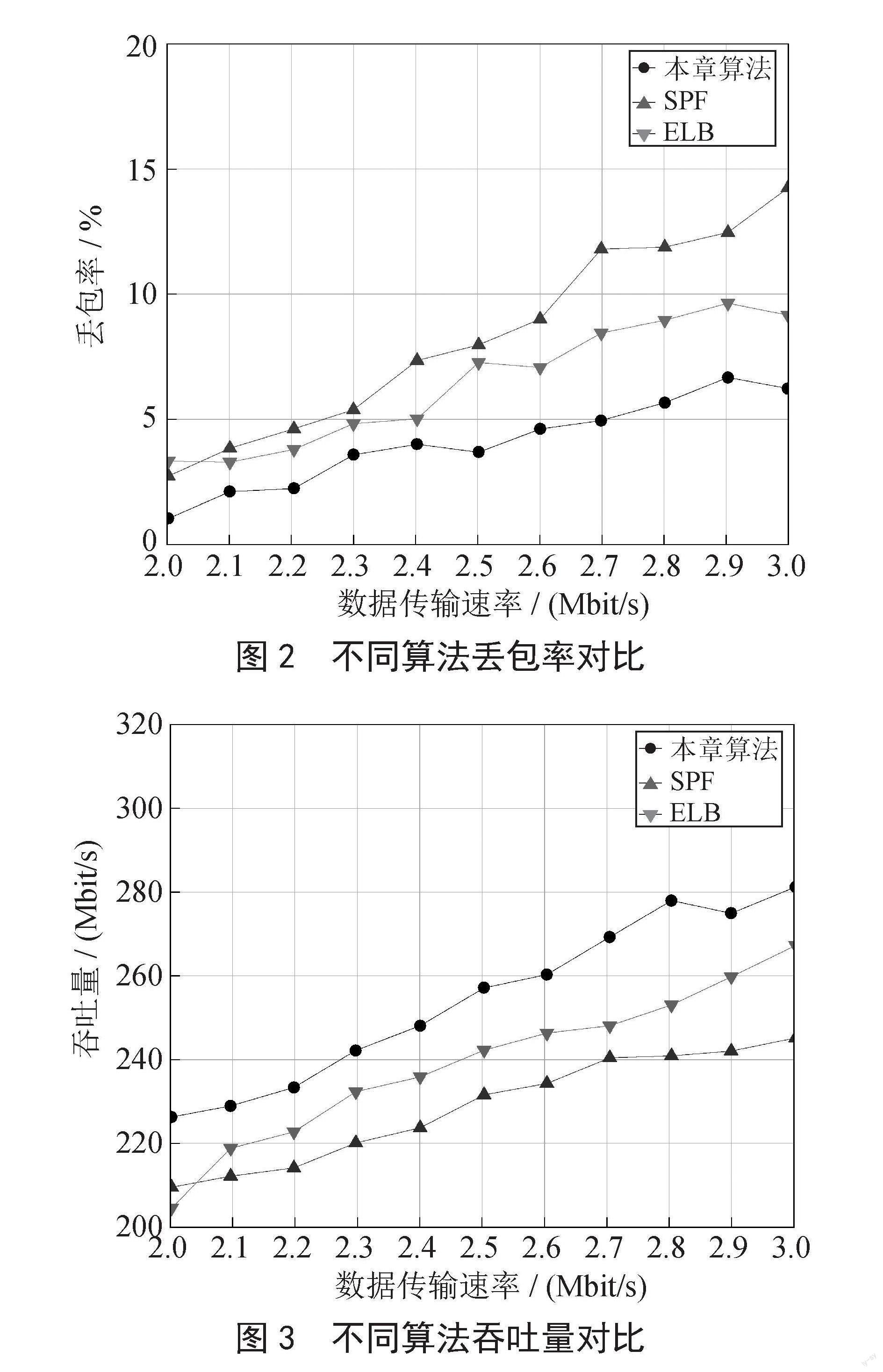
3.2.1 网络平均传输时延
如图1所示,随着数据传输速率不断增大,网内传输数据包数量增加,逐渐达到链路带宽上限,所以网络中数据包的传输平均时延上升。通过仿真结果可以看出,本文路由算法在网络传输时延上略优于SPF算法和ELB算法。由于采用了DQN模型进行路由计算,训练后的模型遵循最短路径的原则去选择路径,并在链路状态变化时,对链路进行切换从而减少节点拥塞问题。
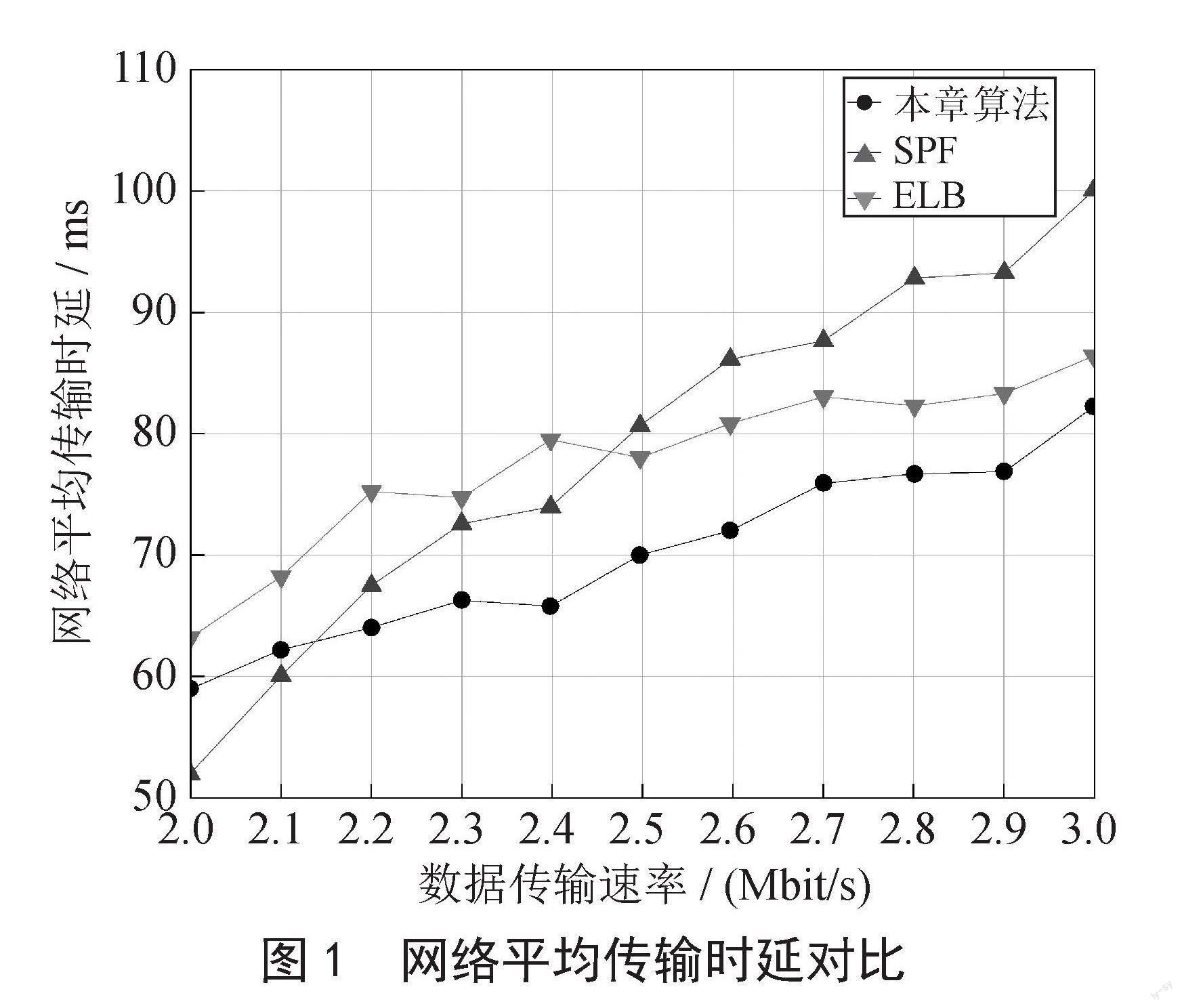
3.2.2 丢包率
如图2所示的仿真结果表明,本文算法在丢包率上当链路状态到达拥塞时,将会将数据转发到次优链路,有效地降低了丢包率。
3.2.3 吞吐量
吞吐量是对卫星网络中路由算法在一定时间内的数据传输总容量的衡量标准。系统仿真结果如图3所示。
由仿真结果可知,随着数据传输的速率的增大,系统吞吐量也在提升。由于奖励函数的设置,使得数据包会往距离最近,时延最短的方向进行转发,算法可以快速为卫星提供下一跳节点的选择,从而使得同样的时间内,卫星节点可以处理更多的任务,提升系统的吞吐量。
4 结 论
本文针对低轨卫星网络存在的高动态性的问题,提出了一种基于深度强化学习的卫星路由算法,并通过设置相应的参数以及改进的采样机制来实现更好的效果。仿真结果表明,基于优先经验采样机制的深度强化学习算法有效降低了数据发送时延,降低了丢包率,提高了系统吞吐量。
参考文献:
[1] IZZAT G,MOHAMMED H.Optimised routing algorithm in low Earth orbit satellite network [J].International journal of ad hoc and ubiquitous computing,2021,36(4):230-237.
[2] 吴署光,王宏艳,王宇,等.低轨卫星网络路由技术研究分析 [J].卫星与网络,2021(9):66-74.
[3] KUANG Y,YI X,HOU Z. Congestion avoidance routing algorithm for topology-inhomogeneous low earth orbit satellite navigation augmentation network [J].International Journal of Satellite Communications and Networking,2021,39(2):221-235.
[4] 頓聪颖,金凤林,谭诗翰,等.卫星网络负载均衡路由技术研究综述 [J].信息技术与网络安全,2021,40(4):46-55+63.
[5] WEI D,ZHANG J,ZHANG X,et al. Plume:Lightweight and Generalized Congestion Control with Deep Reinforcement Learning [J].China Communications,2022,19(12):101-117.
[6] LIU W,CAI J,CHEN Q,et al. DRL-R:Deep reinforcement learning approach for intelligent routing in software-defined data-center networks [J/OL].Journal of network and computer applications,2021,177(Mara):102865[2023-02-24].https://doi.org/10.1016/j.jnca.2020.102865.
[7] 杨思明,单征,丁煜,等.深度强化学习研究综述 [J].计算机工程,2021,47(12):19-29.
[8] 赵星宇,丁世飞.深度强化学习研究综述 [J].计算机科学,2018,45(7):1-6.
[9] LI Z,XIE Z,LIANG X. Dynamic Channel Reservation Strategy Based on DQN Algorithm for Multi-Service LEO Satellite Communication System [J].IEEE Wireless Communications Letters,2021,10(4):770-774.
[10] GUAN Y,LIU B,ZHOU J,et al. A New Subsampling Deep Q Network Method [C]//2020 International Conference on Computer Network,Electronic and Automation(ICCNEA).Xi'an:IEEE,2020:26-31.
作者简介:许向阳(1967—),男,汉族,河北石家庄人,副教授,硕士导师,硕士,主要研究方向:无线自组网、卫星通信;彭文鑫(1999—),男,汉族,河北唐山人,硕士在读,主要研究方向:卫星路由;李京阳(1997—),男,汉族,河北沧州人,硕士在读,主要研究方向:卫星路由。
