铁路数据分布式湖仓一体架构分析与设计
2024-04-14李国华邹丹李海军孙思齐王建强
李国华 邹丹 李海军 孙思齐 王建强

DOI:10.19850/j.cnki.2096-4706.2024.01.011
收稿日期:2023-03-27
基金项目:中国国家铁路集团有限公司科技研究开发计划课题(P2021S012)
摘 要:科学合理的数据资源分类方法和行之有效的数据湖架构体系,可以支撑起铁路全业务数据的高效存储、组织和利用,并进一步支持并优化各项运营业务。文章首先对现有数据湖架构进行简要分析,确定选用湖仓一体的概念,将铁路数据以主题进行分类以适应业务处理需求;其次设计了铁路数据分布式湖仓一体架构,阐述了路局级子湖仓一体与国铁集团总湖仓一体的架构与功能,以及两者之间的数据流转过程;最后分析了所设计架构的特性与存在的问题,为进一步构建有效的铁路运营数据湖提供了参考。
关键词:铁路大数据;数据治理;数据湖;湖仓一体;分布式架构
中图分类号:TP302.1 文献标识码:A 文章编号:2096-4706(2024)01-0054-05
Analysis and Design of Railway Data Distributed Lake Warehouse Integrated Architecture
LI Guohua1, ZOU Dan1, LI Haijun2, SUN Siqi1, WANG Jianqiang2
(1.Institute of Computing Technologies, China Academy of Railway Sciences, Beijing 100081, China;
2.School of Traffic and Transportation, Lanzhou Jiaotong University, Lanzhou 730070, China)
Abstract: A scientific and reasonable data resource classification method and an effective data lake architecture system can support the efficient storage, organization, and utilization of railway full business data, and further support and optimize various operational businesses. This paper first provides a brief analysis of the existing data lake architecture, determining the concept of integrated lake and warehouse, and categorizing railway data by theme to meet business processing needs; secondly, a railway data distributed lake warehouse integrated architecture is designed, elaborating on the architecture and functions of the sub lake warehouses at the railway bureau level and the overall lake warehouses of China Railway Group, as well as the data flow process between the two; finally, the characteristics and existing problems of the designed architecture are analyzed, providing a reference for further constructing an effective railway operation data lake.
Keywords: railway big data; data governance; data lake; integrated lake and warehouse; distributed architecture
0 引 言
铁路数据服务平台是铁路大数据应用的基础支撑,是铁路行业的基础性数据平台,用于整合全路的数据资源,实现数据的规范存储、管理和高效应用。数据湖的概念诞生于2010年,是由James Dixon提出的一种大数据基础设施架构,通过引入自然生态中湖的概念来描述一种数据从源头流入,用户或程序可以从中查询和抽取所需数据的“数据湖”[1]。然而数据湖这一概念自诞生之初时至今日仍未在业界形成严格界定标准,Gartner[2]认为数据湖是一种以低成本进行数据存储的方法。
许多学者在特定领域的数据管理中都引入了数据湖概念。梁怿[3]等对于西气东输领域多源数据汇总过程中的安全性问题设计了基于绝对单向技术的数据湖架构并实现了安全性与功能性之间的平衡;谭景信[4]等针对工商联业务的特性构建了虚拟化模型驱动的分布式数据湖架构,并通过测算验证了模型在满足业务需求的同时有效降低了数据传输的成本;对于电网业务数据的管理,曾飞[5]等针对数据存储与共享设计了基于数据湖的邊缘层分布式电力数据存储架构并通过实验表明了其具有应用的潜力,谢裕清[6]等将原始数据加密存储在数据湖中并以提出的数据访问与共享优化模型来实现数据的跨业务连通,兼顾数据流转的安全性与高效性。我国铁路实行模块化管理,主要包括机务、车务、工务、电务和车辆等模块,具有跨区域网络、技术构成复杂、部门繁多、业务应用广泛等特点[7],因此,构建铁路数据湖必须要考虑铁路数据的特点与铁路系统的结构。
中国国家铁路集团有限公司自2019年成立后积累了体量接近10 PB规模的各个生产运营领域的海量数据,其中蕴含着巨大的分析和应用价值,对于如何有效地管理这些数据许多学者开展了各自的研究。王喆[8]等在铁路数据服务平台的存储架构设计中引入了数据湖的概念;刘彦军[9]等以整合成熟的开源技术与产品为主设计了铁路大数据资产管理平台;海洋[10]等所设计的铁路大数据存储管理系统可实现数据来源管理,存储系统资源可视化管理,数据预测和存储规划以及数据的统一管理;王沛然[11]等针对“数据沼泽”现象从铁路数据服务平台存储架构层面提出了一种新的顶层设计,通过丰富的存储组件满足各种存储需求并划分数据存储的冷热分区。
想要将数据湖概念合理地融入铁路数据的治理中就需要构建适合铁路领域的数据湖架构。目前数据湖架构主要以下几种。最初的数据湖架构由两层组成:临时数据的着陆区层级和永久存储原始数据的层级。尽管各个学者与厂商在后来的发展中构建了更为复杂的数据湖架构,但大多架构都遵从了最初架构的定义:数据在数据湖中的存储形式应是其原始的,不变的形式[12]。最初的两层架构经过一些调整演变成了Lambda架构,Lambda架构更多地关注数据处理和消费而非存储,适用于主要通过特别查询访问的大量数据[13]。数据池架构由五个在逻辑上相互分离的组件组成,最大缺点是缺乏原始形式的持久数据存储,这可能最终导致分析数据时缺乏信息并失去数据再处理的可能性[14]。多层架构中每一层都与相邻的层通信,数据必须在所有四层上进行管道传输[15]。Zaloni分区架构包括四个常规区域和一个沙箱区域,沙箱不受访问限制,提供对全体数据的分析和探索[16]。另一种部分基于Zaloni分区架构的方法包含更多分区,每个分区都以特定用途建模的形式保存数据。该架构中提出的所有区域都在存储的数据上创建了组织层,并向数据湖范围之外的用户和系统提供数据湖接口[17]。
从数据仓库到数据湖,数据治理的要求标准日渐完善,在顺应实际需求的趋势下,湖仓一体概念诞生于2020年,实现了数据仓库与数据湖的有机融合。湖仓一体融合了两层架构和区域架构,通过虚拟化层提供了对数据仓库和数据湖的数据访问[18,19]。
本文通过对湖仓一体概念的理解与对铁路大数据特点的把握,构建了铁路数据分布式湖仓一体架构,详细阐述了路局级子湖仓一体与国铁集团总湖仓一体的架构与功能以及两者之间的数据流转过程,分析此架构理论上可支持海量多源异构数据的处理,保证数据的原始格式储存,具有一套完善健全的数据流转过程,实现数据的冷热分离与存算分离。
1 铁路数据分类
铁路数据按照主题域分为16类,按照数据性质划分为主数据、事务数据和基础数据[20]。按照数据生产过程和加工深度,铁路数据可分为一、二、三次数据;按照效用范围可分为共享数据和专有数据;按照稳定性及时效性可分为静态数据和动态数据[21]。铁路主数据作为铁路系统最基本的数据支撑有必要依据主题进一步往下细分到具体条目[22,23]。
考虑到数据湖与数据仓库之间的数据流转效率与面向业务分析的数据主题域划分原则,数据湖中的数据应按照主题分区存储。本文将铁路数据主要分为运输对象、运输产品、市场营销、调度指挥、运输生产、设备设施、物资管理、人员及机构、建设管理、综合协同规划、财务管理11大类,如图1所示。
具体介绍如下:
1)运输对象分为客运部分与货运部分。客运数据包含铁路客运相关的旅客信息及其服务记录等数据;货运数据包含铁路货运相关的托运人信息及其服务记录等数据。
2)运输产品分为客运部分和货运部分,分别都包含其产品信息与相关服务。
3)市场营销分为客运部分和货运部分,分别都包含其营销计划与市场调研。
4)调度指挥包含运输调度中的各项计划和实绩信息,如轮廓计划、日(班)计划、车站作业计划、调度命令信息等。
5)运输生产包含了运输生产作业过程中列车、车辆、机车、集装箱及客货运输中的事件、状态信息,列车编组信息等。
6)设备设施分为固定设施数据和移动设备数据,分别包含各自设施设备的基本信息与作业记录,作业记录包含使用、维修及保养记录。
7)物资管理分为物料清单数据与管理记录数据,管理记录包含物资的供应、使用以及库存记录。
8)人员及机构分为组织机构数据与人员信息數据。所涉及的人员与组织不仅限于铁路系统内部而是所有与铁路有关的人员与组织。
9)建设管理分为设计管理数据、建设管理数据、项目管理数据、工程监督数据等。
10)综合协同规划分为综合管理数据与战略决策数据。综合管理包含规章政策与组织协同信息等;战略决策包含关键绩效指标和战略管理信息等。
11)财务管理包含财务科目、资产信息、会计核算、清算信息等。
2 分布式湖仓一体架构
2.1 分布式架构
与日俱增的铁路数据庞大的体量会使传统集中式架构会产生以下问题:
1)数据量的持续增长会使数据管理难度增加,而管理不善的数据湖有变为“数据沼泽”的风险。
2)全量的原始数据搬运至数据湖中会占用大量带宽资源且无法保证时效性。
3)集中式数据湖只管存储日益增长的原始数据而忽略了数据的使用价值大小,存储成本和管理成本会不断攀升直至难以承受。
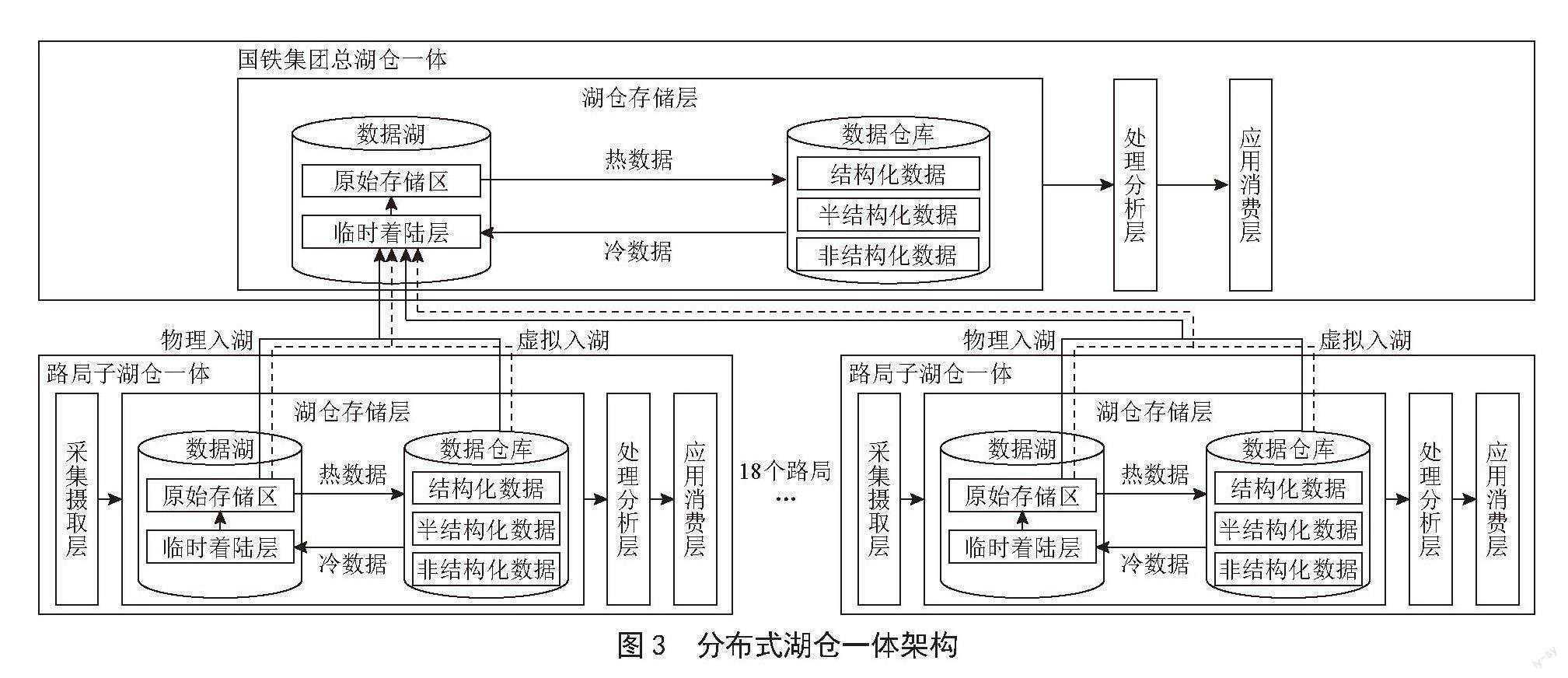
本文针对铁路大数据系统需求的特点构建了以国铁集团的总湖仓一体为原点向外辐射型地连接18个路局的子湖仓一体的分布式架构。
2.2 子湖仓一体架构
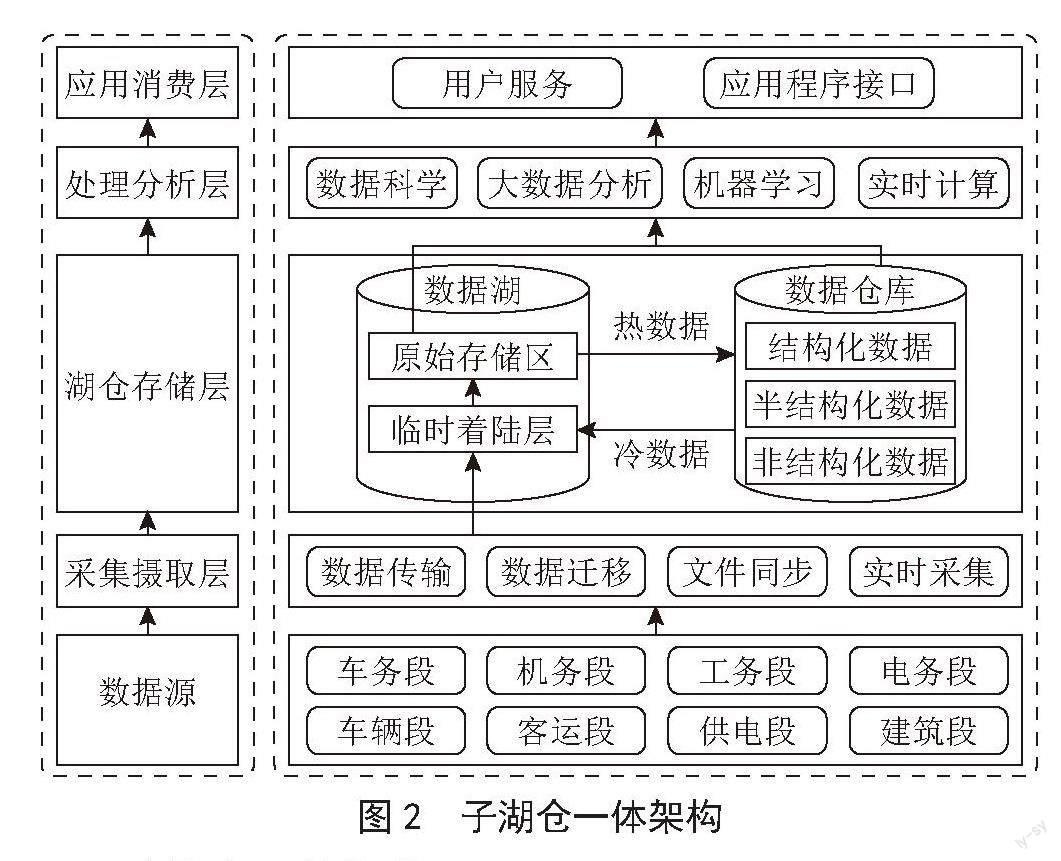
路局的子湖仓一体架构分为4层:采集摄取层、湖仓存储层、处理转换层及应用消费层,如图2所示。
1)采集摄取层,其任务是通过数据传输、数据迁移、文件同步以及实时采集等途径采集摄取来自不同数据源节点即路局管辖内各个站段和系统的海量异构数据,包括结构化数据、半结构化数据以及非结构化数据等。
2)湖仓存储层包含数据湖与数据仓库,数据湖包含临时着陆层与原始存储层。数据最初到达的区域是临时着陆层。临时着陆层中的数据包含原始格式的临时存储数据。该区域会进行初步数据分析以及潜在的业务和技术合规性缺失。原始存储层包含从临时着陆区获得的原始数据。在原始存储层中,原始数据以其原始形式永久存储,而一旦数据在原始存储层中被确认存储就会从临时着陆区删除,如此原始存储层成为分析和进一步处理的唯一可信数据源。此外,初始数据处理是在原始区域中完成的,从而使用适当的元数据建立数据索引和完善记录。
采集摄取层收集的数据先到达数据湖进行初步分析与验证后再依据热数据的定义标准流转到数据仓库里,热数据的定义标准由数据实时性,数据价值以及数据使用频率等因素决定。而当数据仓库内的热数据不再满足热数据的定义标准后就会变成冷数据流转回到数据湖内,出于技术合规性考虑冷数据同样要先到达临时着陆区再前往原始存储区。考虑到数据流转效率与数据存储成本,将热数据存储到数据仓库里方便提取,而冷数据存储到数据湖中可以有效降低存储成本,同时这些移到湖里的数据,仍然可以被数据仓库查询使用。湖仓存储层有机融合了数据仓库与数据湖的优点,实现了数据的冷热分离。为了使数据湖与数据仓库之间的数据流转更加顺畅,数据湖的原始存储层按照数据主题分为11个区域,数据仓库也按照同样的原则进行主题划分。
3)处理转换层提供了一个可挖掘铁路海量数据价值的潜力,通过数据科学、大数据分析、机器学习以及实时计算等功能对铁路大数据进行分析和处理,分析结果可为铁路系统高层决策提供参考。
4)应用消费层为最终用户或应用程序提供了所需数据的访问入口。用户或应用程序可以访问这些数据,以便执行数据探索、创建和应用分析查询,并使用各种可视化工具可视化存储的数据。
2.3 总湖仓一体架构
国铁集团的总湖仓一体架构分为三层,与路局的子湖仓一体相比没有采集摄取层,这是因为国铁集团总湖仓一体的数据来源就是下属的18个路局子湖仓一体的湖仓存储层级,数据来源安全且稳定,因此无须设置采集存储层。总湖仓一体的数据湖可分别与子湖仓一体的数据湖和数据仓库之间进行数据传输。总湖仓一体与子湖仓一体组成的分布式架构如图3所示。
国铁集团的总湖仓一体架构的三层在功能属性方面与路局的子湖仓一体一致,而在能力强弱方面前者强于后者,除了在硬件设施方面国铁集团所部署的设备能力强于路局所部署的设备能力外,总湖仓一体还有进行数据逻辑入湖和云计算的特权。
在路局级子湖仓一体中,此路局所管辖的所有数据都需要在物理层面上进行存储以确保成为大数据分析应用的可靠数据源,而在国铁集团总湖仓一体中只需物理存储少量所需数据,再逻辑存储所有子湖仓一体的所有数据即可,这样可以有效降低数据存储与传输成本,如果总湖仓一体需要未在本地物理存储的数据只需按照逻辑地址到物理存储了该数据的子湖仓一体中提取即可。
如果某一子湖仓一体需要其他子湖仓一体的数据则需要向总湖仓一体申请,由总湖仓一体作为中转实现子湖仓一体之间的数据流转,如此就不必在18个子湖仓一体之间两两建立数据传输通道。云计算同理,总湖仓一体可以调动子湖仓一体闲置的算力完成数据处理的任务,子湖仓一体也可向总湖仓一体申请使用云计算来处理超过自身硬件能力的计算需求。
3 架构分析
3.1 湖仓一体的特性
经综合分析,本文所提出的湖仓一体架构在铁路全业务数据治理上具备以下特点:
1)支持海量多源异构数据的处理,包括结构化与非结构化类型,如文本、图像、视频、音频,以及半结构化数据,如JSON等。
2)保证数据“原汁原味”的原始性与完整性,兼容各类数据模型的建立,具有一套完善健全的数据流转过程。
3)实现数据的冷热分离,使得数据的流动效率更高,存储成本更低。
4)实现存算分离,给予了整个系统扩展能力与容量的潜力,符合未来对于分布式数据架构的发展要求。
湖仓一体仍处于发展探索阶段,业界尚未就定义标准与技术路线达成共识,仍需一定时间的完善才能成为成熟的大数据处理方案,但完善时间的不确定使得湖仓一体可能会被其他新诞生的大数据处理方案所替代。其次湖仓一体实际应用案例较少,缺乏可靠的参考对照,具体工具产品的使用与实施部署的方案仍有待考虑,因此无法确定湖仓一体能否会实现预期的效果。
3.2 未来展望
铁路数据在湖仓一体的架构中的流动有以下情况:从各类数据源头流入架构,从架构流出到用户或应用程序以及在整体架構中层级与区域之间的流动。数据的数量与质量关系着管理数据的难度,从而产生“数据重力”现象,处理不善可能导致“数据沼泽”现象的产生,因此湖仓一体架构要有机结合数据湖与数据仓库,克服“数据重力”现象,使数据在各个层级与区域之间的流动更有效率。
湖仓一体的实现需要多个产品与工具的配合与部属,此架构以结构简单的数据湖为核心,建立一套完整的数据处理系统,铁路全业务数据湖需要具备的功能是,从铁路数据的采集与摄取到数据的入湖入仓,到湖仓之间冷热数据的流转与存储,再到数据出湖从而进行转换处理以供消费与应用,多个层级与区域的相辅相成与紧密缝合使得铁路数据有一个完整的流入—存储—流出—处理—消费过程。
4 结 论
从数据仓库的成熟应用到数据湖的初步探索再到湖仓一体概念的诞生,说明现代社会对于日益增长的海量数据的存储与处理的要求也随之上升。铁路行业作为国家基础设施的支柱性行业必须迎合数据信息时代的发展趋势,建立能够涵盖海量多源异构数据全生命周期的大数据处理系统符合铁路行业对于未来的期望。本文所构建的铁路数据分布式湖仓一体架构分为国铁集团总湖仓一体和路局级子湖仓一体上下两级,理论上可支持海量多源异构数据的处理、保证数据的原始格式储存、具有一套完善健全的数据流转过程,实现数据的冷热分离与存算分离、可通过物理入湖与虚拟入湖进行数据分布式存储、可通过分散的算力设备进行云计算。未来计划研究该架构的具体部署方案以及软件硬件选取,以供相关研究与实践参考。
参考文献:
[1] DIXON J. Pentaho, Hadoop, and Data Lakes [EB/OL].[2023-05-06].https://jamesdixon.wordpress.com/2010/10/14/pentaho-hadoop-and-data-lakes/.
[2] GARTNER. Gartner says beware of the data lake fallacy [EB/OL].[2023-05-06].http://www.gartner.com/newsroom/id/2809117.
[3] 梁怿,李佳鹏,王洪钧,等.一种基于绝对单向技术的数据湖设计方法 [J].西安石油大學学报:自然科学版,2022,37(2):138-142.
[4] 谭景信,刘玉龙,李慧娟.虚拟化模型驱动的分布式数据湖构建方法研究 [J].计算机科学与探索,2019,13(9):1493-1503.
[5] 曾飞,杨雄,苏伟,等.基于区块链与数据湖的电力数据存储与共享方法 [J].电力工程技术,2022,41(3):48-54.
[6] 谢裕清,王渊,江樱,等.便于数据共享的电网数据湖隐私保护方法 [J].计算机工程与应用,2021,57(2):113-118.
[7] 马丽梅,史丹,高志远,等.大数据技术及其行业应用:基于铁路领域的概念框架研究 [J].北京交通大学学报:社会科学版,2019,18(3):58-67.
[8] 王喆,马小宁,邹丹,等.基于铁路数据服务平台的铁路数据资产管理研究 [J].铁路计算机应用,2021,30(3):23-26.
[9] 刘彦军,李平,马小宁,等.铁路大数据资产管理平台的研究与设计 [C]//第十二届中国智能交通年会大会论文集.常熟:电子工业出版社,2017:351-356.
[10] 海洋,李浩鹏,刘忏,等.铁路大数据存储管理系统设计方案 [J].铁路计算机应用,2021,30(8):34-37.
[11] 王沛然,马小宁,王喆,等.铁路数据服务平台存储架构设计与应用 [J].铁路计算机应用,2021,30(5):48-52.
[12] FANG H. Managing data lakes in big data era: What's a data lake and why has it became popular in data management ecosystem [C]//2015 IEEE International Conference on Cyber Technology in Automation, Control, and Intelligent Systems (CYBER). Shenyang:IEEE,2015:820-824.
[13] MUNSHI A A, Mohamed Y A R I. Data Lake Lambda Architecture for Smart Grids Big Data Analytics [J].IEEE Access,2018,6:40463-40471.
[14] INMON W H. Data Lake Architecture:Designing the Data Lake and Avoiding the Garbage Dump [J].Technics Publications.2016
[15] SAKR S,ZOMAYA A Y. Encyclopedia of Big Data Technologies [M].Springer International Publishing,2019:552-559.
[16] LAPLANTE A,SHARMA B. Architecting Data Lakes:2nd Edition [M].[S.I.]:O'Reilly Media,2018.
[17] GIEBLER C,GR?GER C,HOOS E. The Data Lake Architecture Framework: A Foundation for Building a Comprehensive Data Lake Architecture [EB/OL].[2023-04-20].https://www.researchgate.net/publication/354661265_The_Data_Lake_Architecture_Framework.
[18] ARMBRUST M,GHODSI A,XIN R. Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics [EB/OL].[2023-04-20].https://www.cidrdb.org/cidr2021/papers/cidr2021_paper17.pdf.
[19] ORESCANIN D,HLUPIC T. Data Lakehouse - a Novel Step in Analytics Architecture. 2021 44th International Convention on Information, Communication and Electronic Technology (MIPRO).Opatija:IEEE,2021:1242–1246.
[20] 马小宁,李平,杨连报,等.铁路信息化数据架构研究与设计 [C]//2014第九届中国智能交通年会大会论文集.广州:电子工业出版社,2014:25-32.
[21] 马小宁,史天运,邹丹.铁路公用基础信息的特征、范畴及概念分析 [J].中国铁路,2012(11):44-47.
[22] 杨连报,李平,马小宁,等.铁路主数据全生命周期管理研究 [C]//第十二届中国智能交通年会大会论文集.常熟:电子工业出版社,2017:365-369.
[23] 马小宁,邹丹,吴艳华.铁路主数据管理平台解决方案及应用实践 [J].中国铁路,2017(1):17-23.
作者简介:李国华(1978—),男,汉族,内蒙古突泉人,正高级工程师,硕士,研究方向:铁路运输、计算机软件及计算机应用、电信技术。
