基于遗传算法和LightGBM的网络安全态势感知模型
2024-04-10熊郁峰熊洲宇
胡 锐,徐 芳,熊郁峰,熊洲宇,陈 敏
(江西省烟草公司吉安市公司,江西 吉安 343009)
0 引言
网络给诸多行业发展带来了便利,但因网络而导致的问题也日渐显著,相继出现了因网络信息保护不利而导致的信息泄露、网络诈骗、网络监听等事件[1]。人工智能技术是网络安全技术难题的重要解决手段,越来越多的研究着重于基于人工智能构建网络态势感知模型[2]。
应对网络攻击的研究成为热门[3-4],研究人员逐渐使用网络安全态势感知代替原有的被动防御措施,能够提前预测和发现潜藏的网络攻击。原始的网络异常流量检测模型中通常使用统计分析[5]等方法,由于是通过已有信息来进行防范,往往因为预测效果差而达不到防范新型网络攻击的效果。
态势感知是一种基于环境的、动态的、系统的洞悉安全风险的能力,可以全面地发现、识别安全威胁,并能准确分析、及时处理安全威胁的一种方式。最早在军事领域中被提出,分为覆盖感知、理解和预测3个层次[6]。普通的安全管理策略视角单一,不能以全局的视角挖掘出网络空间的内在联系,存在潜在风险,而网络安全态势感知可整合采集的全部数据,以此评价网络运行态势[7]。
基于传统机器学习的网络安全态势感知技术研究中,常用的方法有K邻近算法[8]、支持向量机[9]、朴素贝叶斯[10]、随机森林[11],相较于原始的网络检测模型,在基于传统机器学习的方法中,异常网络模型检测中的准确率被提高了,但是存在复杂函数表达有限、鲁棒性较差的问题。随着网络服务的增加以及网络边界不断往外延伸,网络流量呈现爆炸式增长的趋势,传统的机器学习表现出较大误报率和泛化能力差等现象。
在基于深度学习构建异常网络检测模型的研究中,PEI等人[12]提出了一种基于长短期记忆自编码的异常网络检测模型,有较高的检测精度。YIN等人[13]提出了一种基于循环卷积网络(Recurrent Neural Network,RNN)的异常网络检测模型,在多分类二分类中,相较于传统的机器学习方法性能较好。来杰等人[14]提出将改进的高斯模型和深度AE网络相结合,实现了数据的降维优化,检测异常网络有较好的效果。Hwang等人[15]使用卷积神经网络(Convolutional Neural Networks,CNN)和无监督的模型进行自动的分析流量模式。目前注意力机制也被广泛应用,可以学习特定的特征,而忽略掉不重要的信息,皇甫雨婷等人[16]提出了一种基于注意力机制的模型来学习多个特征之间的相关性,抑制掉干扰信息,提出的模型有较高的准确率,但是在表格文件中,无法学习到位置信息和异常网络信息中的前后信息关系。
综上所述,传统机器学习方法难以处理大量高维实验数据,又因为本文使用的实验数据为表格数据,而深度学习方法在表格数据中表现不如树模型,所以不选择注意力机制和CNN等深度学习方法。基于此,本文提出一种基于遗传算法+LightGBM(Light Gradient Boosting Machine)的网络安全态势感知模型,着重解决实验数据的格式、数量规模和维度带来的问题。在现有针对性的流量攻击中,使用主动防御的网络安全技术,强化的网络模型进行检测,挖掘网络流中的信息,提高网络安全态势预测模型精度与效率。
1 相关技术
1.1 遗传算法
遗传算法(Genetic Algorithm,GA)是一种模拟生物群体演化的计算机方法,它仿照自然界中的环境选择和基因遗传,使适应性高的个体更容易生存和繁衍,而适应性低的个体则被淘汰[17-18]。它不依赖于群体中的梯度信息,而是依靠群体内部的搜索策略,可以求解复杂的非线性问题,具有并行性、鲁棒性、通用性、搜索能力、适用面广等特点[19]。
GA有如下优点:(1)无需求导,仅依据目标函数进行搜索;(2)以决策变量的编码为运算对象,不受函数约束条件的影响;(3)在同一时间内使用了多个查询点的信息,因此它具有平行查询点的特点;(4)在选择、交叉、变异等操作上采用概率的方法,增加了算法的灵活性;(5)具有较强的全局寻优能力,对求解复杂及非线性问题有较好的效果;(6)与其他的启发式算法具有很好的兼容性,能够与诸如各向异性扩散融合(Anisotropic Diffusion Fusion,ADF)等的其他优化算法相结合,提高算法的性能。
1.2 LightGBM
LightGBM是一种梯度提升框架,其作为一个实现梯度下降树(Gradient Boosting Decision Tree,GBDT)算法的框架,支持高效率的并行训练。相较于经典神经网络算法能够以batch的方式训练来保证训练数据的大小不受内存的限制,普通的GBDT算法每次迭代,都需要遍历整个训练数据多次,但由于弱学习器的强依赖性,只能串行训练,从而导致训练耗时较长。LightGBM的单机多线程与多机并行训练特点弥补了这个缺陷。具体算法优化的体现主要在于单边梯度抽样算法(Gradient-based One-Side Sampling,GOSS)与互斥特征绑定算法(Exclusive Feature Bundling,EFB)这两大利器。
GOSS算法能够对梯度小的样本按比例进行采样,对于梯度大的样本点予以保留。而由信息增益公式(如式(1)所示)及定义可知大梯度样本对信息增益有更大作用。所以这样做不仅保证了模型的准确度,而且能够极大减少样本量,从而提高训练效率。
(1)
其中:no=∑I[xi∈O],
njl|O(d)=∑I[xi∈O:xij≤d],
njr|O(d)=∑I[xi∈O:xij>d].
EFB算法专门被用于处理高维特征,能够对互斥特征进行捆绑形成新的特征。其采用一种构图思想,将特征作为图的顶点,对相互之间不互斥的特征进行相连,随后根据顶点的度进行降序排列,度越大,则该特征与其他特征间的冲突越大,设置最大冲突阈值K,将加入到特征簇后冲突数不超过K的特征加入到捆绑簇中,否则建立新的特征簇。
2 本文提出的方法
2.1 数据清洗
读取数据集(CSE-CIC-IDS2018)进行分析,首先要对数据集中的特征进行初步的筛选与清洗,需要删除IP address、Flow ID、Timestamp等多余特征列。为了提高实验结果的准确性,需要对于每个数据集中的样本进行数据清洗,丢弃一些无穷大值、NaN空值和重复行等无效的数据。每个数据集的网络流量类型及样本数量统计如表1所示,包含各个数据集的丢弃样本以及剩余的样本。

表1 每个数据集的网络流量类型及样本类型
2.2 基于遗传算法改进的LightGBM
为了提高模型的泛化能力和稳定性,本文引入GA对LightGBM进行参数优化。利用GA的随机性、全局性特点,能够使得模型避免陷入局部最优情况。图1是基于遗传算法改进的LightGBM模型的流程图。

图1 模型流程图
为了减少LightGBM全局最优参数组的偏差,提升网络安全态势感知模型的准确性,在对原始数据的处理中,除了正常的数据清洗空值填充以及数值化以外,还需要针对二分类实验进行额外的标签整理工作。将原本多分类的标签整理成有攻击和无攻击两种类型。随后输入到本文的模型中训练,其中利用GA进行参数调优的核心步骤主要分为6步:
(1)求解不同参数组下的LightGBM分类模型的均方根误差(Root Mean Square Error,RMSE)取值大小;
(2)对每个待寻优参数进行编码;
(3)计算种群内各个体的适应度函数值;
(4)找出适应度函数值最大时对应的参数组,并记录结果;
(5)运用轮盘赌算法进行自然选择,保留被选中的参数组;
(6)对剩余参数组按交叉率进行二进制位交换操作以及按变异率进行二进制位变异操作。
2.3 创新点及优势
本文提出的模型相比于传统机器学习和深度学习方法更适用于表格实验数据,传统机器学习方法面对大量高维特征表格实验数据时,常常表现出误报率大和泛化能力差等结果,而深度学习方法在表格数据中表现不如树模型。本文提出的一种基于遗传算法+LightGBM的网络安全态势感知模型,以LightGBM为主模块,使用GA进行参数优化可避免模型过拟合,在两者组合的基础上,使用特定步骤清洗过的数据进行训练能进一步提升模型的态势感知准确率,能够有效解决实验数据的格式、数量规模和维度带来的问题。
3 实验分析
3.1 实验环境
本次实验使用的软硬件环境如表2所示。

表2 软硬件环境
3.2 数据集
为验证模型的效果,本实验使用的数据集是CSE-CIC-IDS2018 on AWS,来自通信安全机构(CSE)与加拿大网络安全研究所(CIC)之间的协作项目。CSE-CIC-IDS2018 on AWS是基于创建用户概要文件生成的用于入侵检测的多样且全面的基准数据集。受攻击的攻击基础设施包括50台计算机,以及5个受害组织部门的420台计算机和30台服务器。捕获每台计算机的网络流量和系统日志,使用CICFlowMeter-V3从捕获的流量中提取的80个特征。包括七种不同的攻击场景的14种攻击类型:Heartbleed、Botnet、DoS等。
在数据预处理部分对数据进行初步筛选和汇总,从汇总后的数据中提取出正常的标签和每种攻击类型的数据,正常标签数据为Benign,剩下的标签数据为各种攻击类型。正常的网络流量类型与各个攻击类型的比例为7:3左右,统计如表3所示。本实验将所有的攻击类型统一划分,分为正常类型与受攻击类型,使用模型进行异常识别分类,验证模型效果。
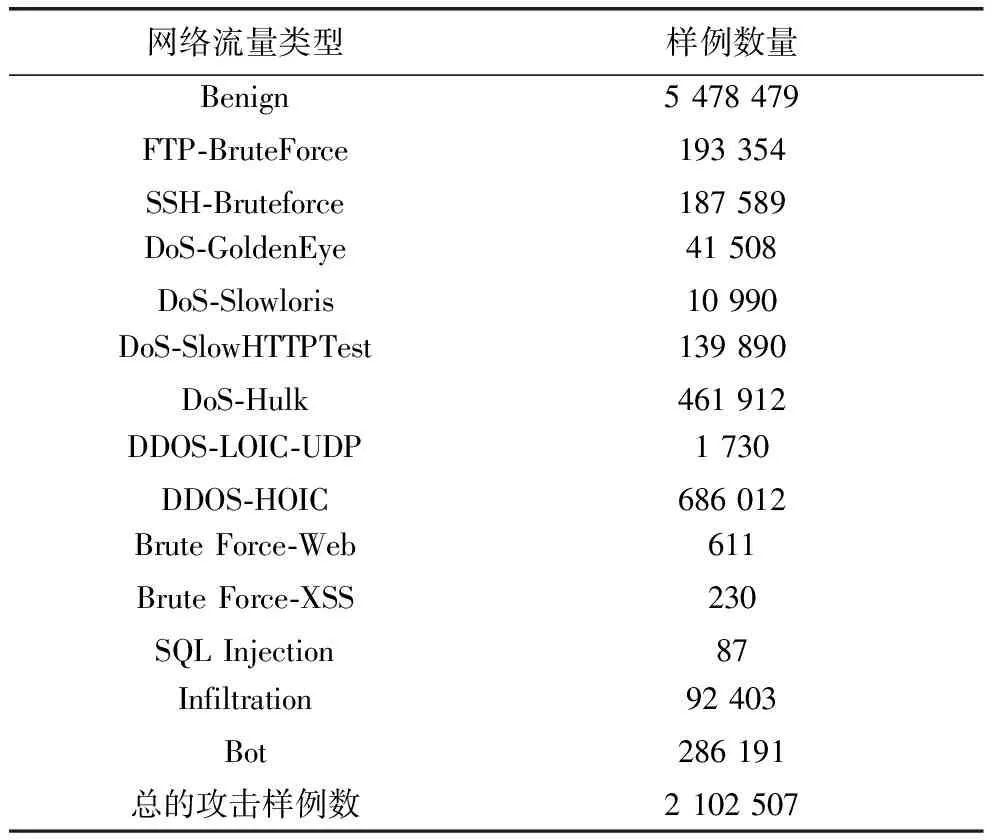
表3 网络流量类型数量统计
3.3 实验分析与评价
为了更好地验证本文提出的模型在进行网络安全态势感知的效果,根据所使用的数据集划分了四个对照组:80个特征多分类对照组(IDS-2018-mul-80future)、80个特征二分类对照组(IDS-2018-bin-80future)、18个特征多分类对照组(IDS-2018-mul-18future)以及18个特征二分类对照组(IDS-2018-bin-18future)。在每个对照组中,选取了几个其他应用在网络安全态势感知方面的深度学习网络模型,并使用相同数据集进行对比实验。若本文提出的模型能够根据输入数据正确预测网络攻击类型,则判定为感知成功。
首先是80特征下的网络安全态势感知效果,根据表4可以看出不同模型在80特征下的多分类、二分类准确率,本文所提出的模型在80特征的情况下的态势感知准确度要明显优于其他深度学习神经网络模型,其中多分类的感知准确率达到了99.43%,二分类的感知准确率达到了99.87%。

表4 80特征训练准确率对比
对比分析网络安全态势感知效果较好的TabNet网络模型。在80特征条件下,模型训练过程的损失变化和准确率变化结果如图2、图3所示,测试准确率如图4所示,图示中的横坐标为epoch,纵坐标为loss值和准确率。

图2 TabNet 80特征训练损失变化曲线

图3 TabNet 80特征训练准确率变化曲线

图4 TabNet 80特征测试准确率曲线
由以上训练损失、训练准确率和测试准确率曲线变化图可得出结论:虽然TabNet网络模型的感知效果在训练时呈现出较高的感知准确率,但是其在测试集上呈现出震荡的趋势,根据其曲线变化可以推断出这是由于训练特征过多而导致的过拟合现象。
为验证因特征过多导致的模型过拟合猜想,设置18特征对照组实验,根据构建树模型时各个特征所做出的贡献的重要程度进行排序,排序结果如图5所示,提取重要度排名前18的特征用于训练,图示中的横坐标为前18个特征名,纵坐标为特征重要度评分。

图5 特征重要度评分
将80特征降维为18特征后,训练过程的损失变化和测试准确率如图6和图7所示。

图6 TabNet-18训练损失曲线
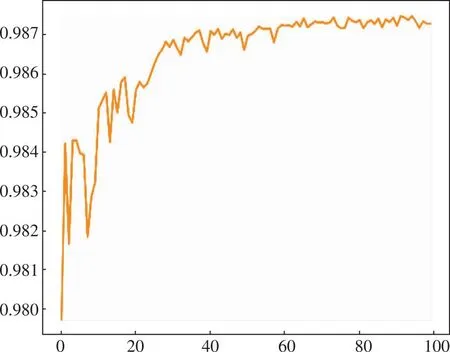
图7 TabNet-18测试准确率曲线
选取18特征用于训练大大降低了训练难度,削减了大部分无用特征之后训练时所需要消耗的时间和硬件资源也会大大减少,训练出的模型大小相较于80特征也会有明显降低。
通过图6和图7可以看出通过特征降维,剔除掉对于网络安全态势感知帮助不大的特征,能够极大地缓解深度神经网络训练时所出现的过拟合现象,增强深度神经网络的鲁棒性。除此之外,降低训练特征之后所训练出的模型明显更加符合日常使用场景。
使用18特征数据集进行模型对比实验,结果如表5所示。根据表5中的实验结果对比可以看出,本文提出的机器学习模型在少特征的情况下仍然具有较好的网络安全态势感知效果,相较于其他模型具有较为明显的优势,且本文模型相较于其他深度学习模型还有以下几个优点:
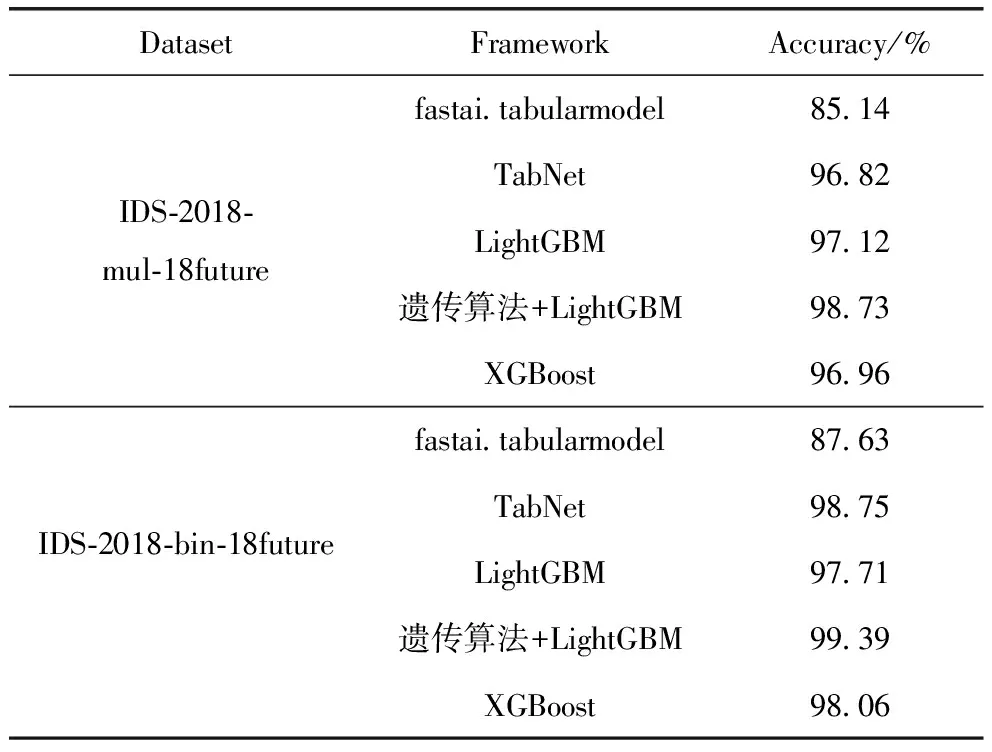
表5 18特征训练准确度对比
(1)训练速度快,模型准确率高。
(2)训练出来的树模型具有良好的可解释性。
(3)对于硬件要求不高,鲁棒性强。
结合fastai.tabularmodel、TabNet、LightGBM、XGBoost四个对照组所产生的对比实验结果,可以证明本文所提出的模型具有良好的鲁棒性和准确率,无论是面对多分类的网络安全态势感知问题,还是面对二分类的网络安全态势感知问题,本文提出的模型相较于其他模型而言都具有更高的感知准确率,在数据集仅有少量训练特征,如18个特征时,仍能表现出很好的感知效果。
4 结论
针对目前网络异常流量检测中存在的网络环境复杂、数据集特征多、模型检测效率低且容易过拟合等现象,提出了一种基于遗传算法改进的LightGBM模型,利用遗传算法的随机性、全局性特点能够使其避免陷入局部最优情况。本文提出的网络模型在CIC-IDS-2018数据集上进行实验分析,在80特征的网络安全态势感知下,二分类的感知准确率达到了99.87%。为了防止出现过拟合现象,通过构建树模型减少训练特征,能够从高维数据中挖掘出对于检测效果影响重要的关键特征信息,并对这些关键特征信息进行分析。实验证明,在低特征二分类的情况下仍然能够达到99.39%的准确率,与其他网络检测模型相比有更高的准确率,检测效率高且具有很好的灵活性和鲁棒性,在智能烟草工业数字化建设中具有实际的应用价值。
除此之外,本文提出的模型还存在着一些问题:本文使用的CIC-IDS-2018数据集包含了79个流量特征信息,在实际工业应用中可能难以提取。下一步将根据提取的特征对模型进行微调,从而使其更加适用于实际场景。
