热损伤玉米种子的高光谱无损检测
2024-04-08张方圆王新月吕庆丰武一戈张亚坤付三玲
张 伏, 禹 煌, 熊 瑛, 张方圆, 王新月, 吕庆丰, 武一戈, 张亚坤, 付三玲
1. 河南科技大学农业装备工程学院, 河南 洛阳 471003
2. 机械装备先进制造河南省协同创新中心, 河南 洛阳 471003
3. 河南科技大学农学院/牡丹学院, 河南 洛阳 471023
4. 河南平安种业有限公司, 河南 焦作 454881
5. 河南科技大学物理工程学院, 河南 洛阳 471023
引 言
玉米是世界三大粮食作物之一, 同时也是我国重要的粮食作物[1]。 玉米种子质量直接影响作物产量, 特别是劣质种子在外形、 颜色等方面与正常种子难以分辨, 但其种子发芽率, 含水率均不符合国家标准, 严重损害了种植户的经济效益[2]。 因此, 对玉米种子准确高效、 快速鉴别具有重要研究意义和应用价值。
除掺杂不同品种种子肉眼可区分外, 劣质玉米种子难以用肉眼区分, 传统方法是将玉米种子送至专门鉴定机构, 通过现代生物技术手段鉴别, 但鉴别成本较高, 鉴定过程费时费力[3]。 高光谱图像技术是将光谱与图像相结合, 常被用于农产品种子品种分类、 内部物质识别、 活性检测等研究[4-6]。 Xia等[7]利用高光谱对17个玉米品种鉴别, 其中MLDA-(LS-SVM)模型的准确率最高为99.13%。 Zhou等[8]基于高光谱图像技术鉴别玉米品种, 其中最佳模型是结合次区域投票算法的CNN模型, 其胚状形态和非胚状形态的准确率为97.78%和98.15%。 Chivasa等[9]利用多时相高光谱对25个玉米品种鉴别, 采用不同的预处理方法处理数据, 与未预处理模型对比, 采用自标度法使花期和衰老期的PLS-DA模型准确率分别提升52%和63%, 采用广义最小二乘加权使花期和衰老期的PLS-DA模型分别提高55%和62%。 杨欣等[10]基于高光谱成像技术结合MSC预处理方法和CARS、 IRIV特征波段选取方法建立支持向量机和线性判别分析模型, MSC-IRIV-LDA模型的训练集和测试集识别率分别为0.960和0.933。 田喜等[11]建立PLSR模型预测玉米种子的水分含量, 预测最高效模型为SPA-PLS模型, 其相关系数(Rp)为0.922 7, 预测均方根误差为0.336 6。 吴静珠等[12]基于高光谱技术结合改进RF算法建立玉米种子胚面朝上和胚面朝下两种水分检测模型, 胚面朝上模型精度较高, 训练集和测试集相关系数R分别为0.969和0.881, 均方根误差分别为0.094%和0.404%。 Ashabahebwa等[13]基于高光谱成像技术结合PLS-DA算法建模, 模型训练集和预测集的准确率分别为97.6%和95.6%。 Cui等[14]采用高光谱成像技术采集甜玉米种子光谱, 采用PLS、 PCR和KPCR建立回归模型, 应用特征选择算法后以KPCR建立的根长和苗长预测模型结果为0.780 5和0.607 4。 Feng等[15]采用高光谱成像技术鉴定人工老化玉米种子活力, 采用PCA定性分析不同老化时间条件下的玉米籽粒, 通过二阶导数选择特征波长, 分别建立基于全光谱和最佳波长的SVM分类模型。 孙俊等[16]基于高光谱图像技术与深度学习建立检测水稻种子活力等级的SAE-SVM模型, 其准确率达到96.47%, GWO算法优化后准确率提升至98.75%。 彭彦昆等[17]提出一种基于高光谱的番茄种子分级算法, 其模型校正集和验证集的正确率分别为93.75%和90.48%。
国内外学者对玉米种子的品种、 物质含量、 活力已有大量相关研究, 但对玉米种子受热损伤和劣质种子的研究较少。 本研究利用高光谱成像技术, 快速获取玉米种子的光谱信息, 通过多元散射校正(multiplicative scatter correction, MSC)、 标准正态变换(standard normal variation, SNV)对光谱预处理, 与连续投影算法(successive projections algorithm, SPA)和竞争性自适应重加权算法(competitive adaptive reweighted sampling, CARS)两种特征波段提取, 以发芽试验结果评价种子生活力建立支持向量机(support vector machine, SVM)模型, 以此实现劣质种子的快速无损识别, 为无损快速检测热损伤玉米种子提供新方法。
1 实验部分
1.1 材料
试验材料选取900粒“豫安三号”玉米种子并分别编号, 样品来自于河南平安种业有限公司, 选取样品时应尽量保证样品种子表面平整、 无霉变、 无损伤, 将样品放置在恒温恒湿环境下, 后续用于种子热损伤试验、 光谱采集和种子发芽试验。
1.2 仪器与设备
采用的高光谱图像采集系统包括高光谱成像仪(SPECIM FX17e, Specim, 芬兰)、 自稳定扫描平台(SPECIM LabScanner 40×20 cm)、 2组150 W的卤素灯阵列光源、 光纤、 暗箱和计算机等, 如图1所示。 高光谱成像仪范围为900~1 700 nm, 共224个光谱波段, 视场角为38°, 采样间隔为3.5 nm, 光学分辨率为8 nm, 利用高光谱图像系统配套的Lumo Scanner软件获取玉米种子高光谱图像。 研究中数据处理软件为ENVI 5.3、 Excel 2021、 Origin 2022、 Matlab 2021a。
1.3 热损伤样品制备
“豫安三号”玉米种子均分为9份, 每份100粒, 共9组样品, 其中一组为对照组, 不做热损伤处理, 其余8组在60、 70和80 ℃置于电鼓风烘干箱中做不同时长的热损伤处理, 获得9组不同损伤程度的玉米种子样品。
1.4 光谱采集
为获稳定的光谱数据, 试验前将高光谱成像仪预热30 min, 曝光时间为6.50 ms、 数据采集频率为50 Hz、 平台移动速度为25.11 mm·s-1、 高光谱相机镜头与自稳定扫描平台间距为32 cm。
玉米胚芽内含大量蛋白质、 脂肪及维生素等营养物质。 因此, 采集试验样本的胚芽侧图像信息。 为提高试验效率, 将种子试验样本均匀放置于黑色卡纸, 每次扫描一个样本类别。
为减少杂光干扰, 光谱采集全程在暗箱中, 采集后使用Lumo Scanner软件将样本的高光谱图像信息及黑暗、 白板图像信息导入计算机中, 用ENVI 5.3软件对高光谱图像黑白校正, 校正公式如式(1)。
(1)
式(1)中,R为样本校正光谱图像,I为样本原始光谱图像,IB为暗光谱图像,IW为白光谱图像。
玉米种子胚芽部位ROI区域选取大小为10×10 pixel, 如图2所示, 将ROI区域光谱信息导出, 即可得到每粒种子在ROI区域的平均光谱值和光谱反射率曲线, 波长范围为935.61~1 720.23 nm, 如图3所示。 为提高光谱测量精度, 增强光谱信噪比, 剔除935.61~959.81和1 702.33~1 720.23 nm信号噪声较大的两段光谱, 故实际有效波长范围为963.27~1 698.75 nm。 为确保采集准确性, 每隔10 min采集一次白板(重新校正)图像信息。

图2 ROI区域选取示意图
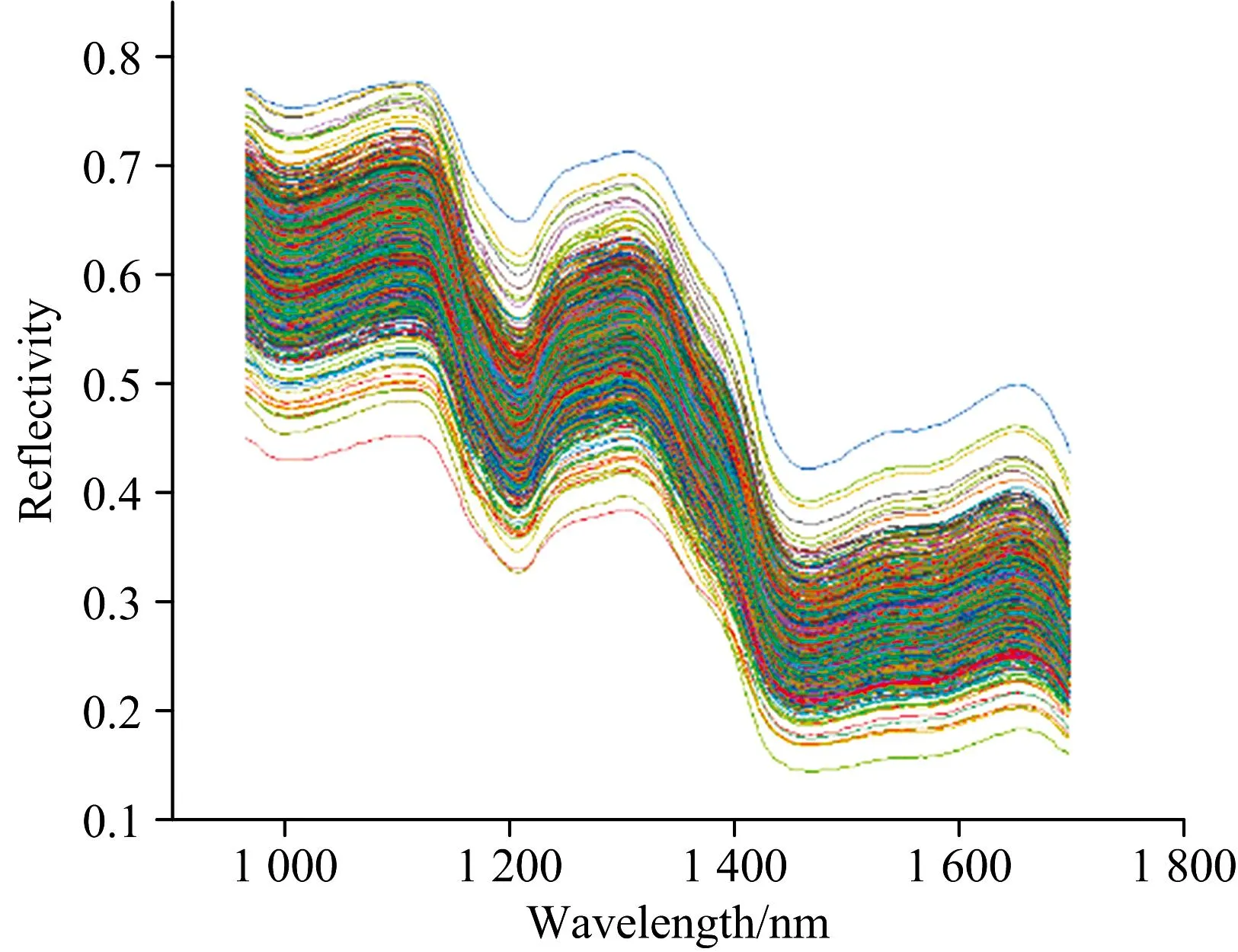
图3 样本原始光谱数据曲线图
1.5 发芽试验
根据GB/T 3543.4—1995, 采用纸培法进行发芽试验, 如图4所示。

图4 发芽试验
第7天测定发芽率, 按照式(2)计算发芽率
(2)
式(2)中,G为发芽率,M1为全部发芽种子数目。M为试验种子总数。
1.6 建模方法和模型评价标准
采用多元散射校正(MSC)与标准正态变换(SNV)对数据预处理, 连续投影算法(SPA)和竞争性自适应加权算法(CARS) 实现数据降维, 支持向量机(SVM)用于定性分析和预测, 遗传算法(genetic algorithm, GA)寻找支持向量机中惩罚系数c和核函数参数g的最优解。 SVM通过确定决策面, 使正例和负例间的距离边最大化, 具有概括及预测能力。
2 结果与讨论
2.1 发芽试验结果分析
9种损伤程度种子处理方法和发芽率如表1所示。

表1 9种损伤程度处理方法和种子发芽率
从发芽试验结果可以发现: 同一温度下, 随干燥时间增加, 玉米种子发芽率均下降; 相同时间下, 随温度增加, 玉米种子发芽率下降; 组别②(60 ℃/10 min)下玉米种子发芽率达91%。 其他种子发芽率均低于正常种子, 表明玉米种子受到热损伤。
2.2 训练集与斥试集的划分
本次试验将采样的900个样本按照3∶2的比例划分为训练集(540个)和测试集(360个), 其中每个类别的训练集与测试集个数为60个和40个, 分析训练集与测试集的平均鉴别准确率(Accuracy)。
2.3 光谱数据预处理
由于光谱数据易受噪声、 杂散光等无关信息干扰, 因此建立模型前需对光谱数据预处理, 提高模型精度。 本研究选择多元散射校正(MSC)及标准正态变换(SNV)对ROI区域内光谱数据去噪。 预处理后光谱平均反射率曲线图, 如图5和图6所示。
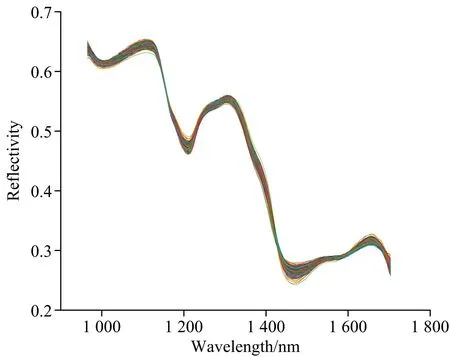
图5 MSC处理后光谱
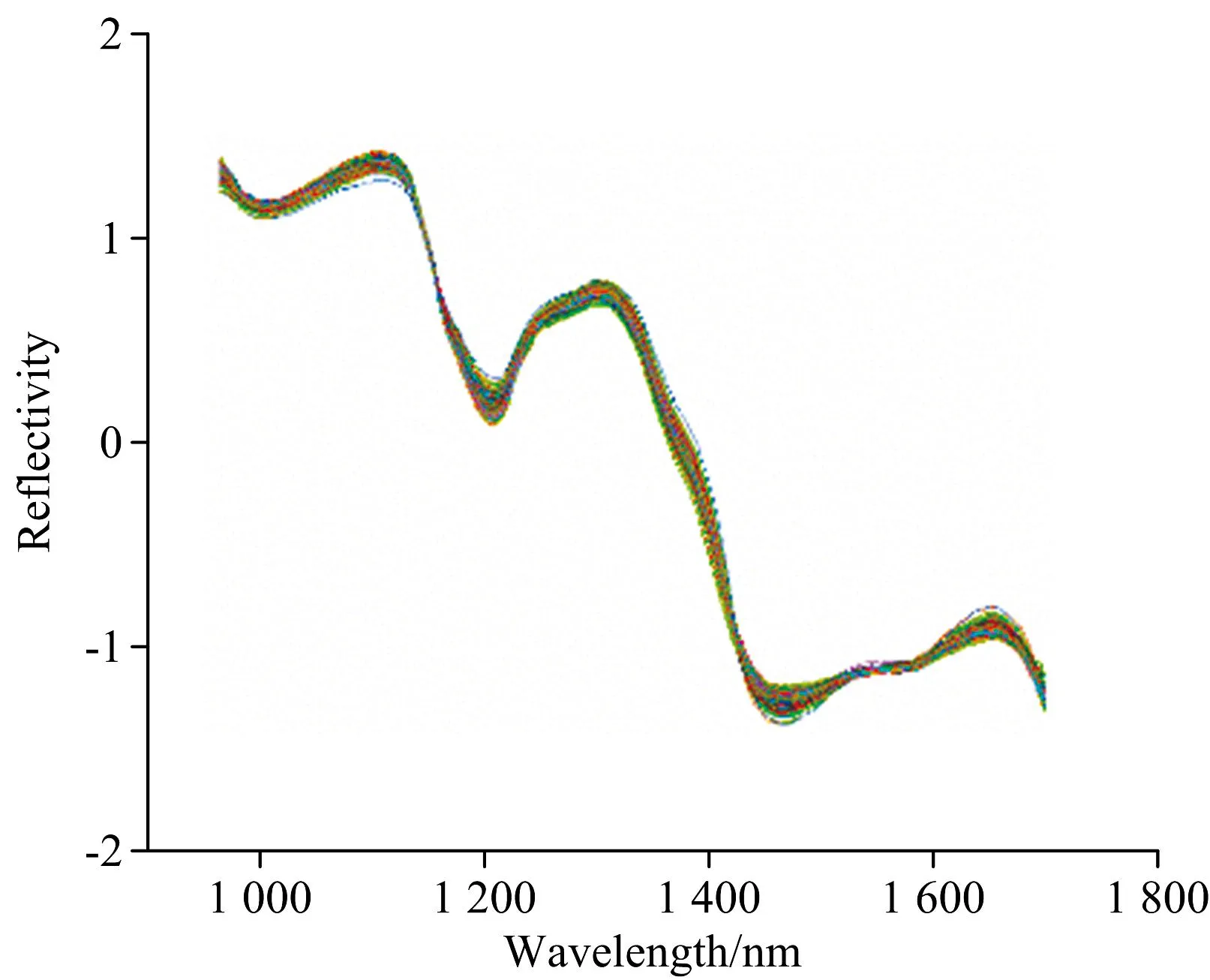
图6 SNV处理后光谱
2.4 基于MSC和SNV的全波段建模
为选择最佳的预处理方法和模型组合, 将原始光谱数据和经过SNV、 MSC预处理后的光谱数据分别输入SVM模型进行比较。 结果发现: 经过MSC处理后的光谱数据建模精度最高, 其测试集准确率高于95%, 明显优于SNV预处理的建模结果, 如图7所示。
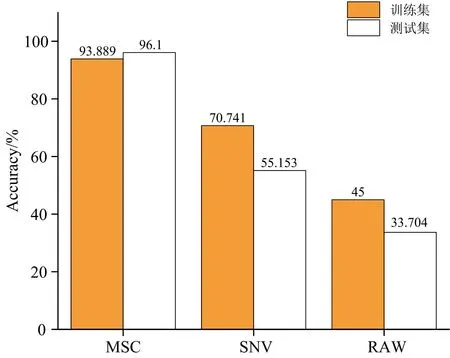
图7 MSC、 SNV和原数据建模对比图
2.5 特征波段提取
由高光谱全波段建立的SVM模型的结果可以发现, 模型对热损伤种子具有较好的识别能力, 但是因其数据量庞大, 存在较多的特征冗余, 影响最终模型准确率, 因此采用SPA算法和CARS算法对MSC预处理后光谱数据进行特征波段筛选。
2.5.1 连续投影算法(SPA)
首先, SPA选择最小的串联变量和最小冗余变量及最大投影矢量。 其次, 根据多元线性回归(MLR)校正的验证集中最小的验证均方根误差(RMSEV)来确定特征变量。 最后, 根据相关度的大小来安排所选的特征变量[18]。 SPA设置最大波长数为210。
SPA提取特征波段如图8所示, 随变量数目增加, RMSE先急剧下降, 随后减缓下降趋势, 当变量数为64时, 此时RMSE为1.327, 表明该数量波段包含热损伤玉米种子最佳特征, 随变量数目持续增加, 其特征波段包含过多冗余, 故选择特征波段数目为64。

图8 SPA算法提取特征波段
2.5.2 竞争性自适应重加权算法(CARS)
CARS算法提取特征波段如图9所示。 蒙特卡洛采样次数设置为50, 使用5折交叉验证法提取特征波段。
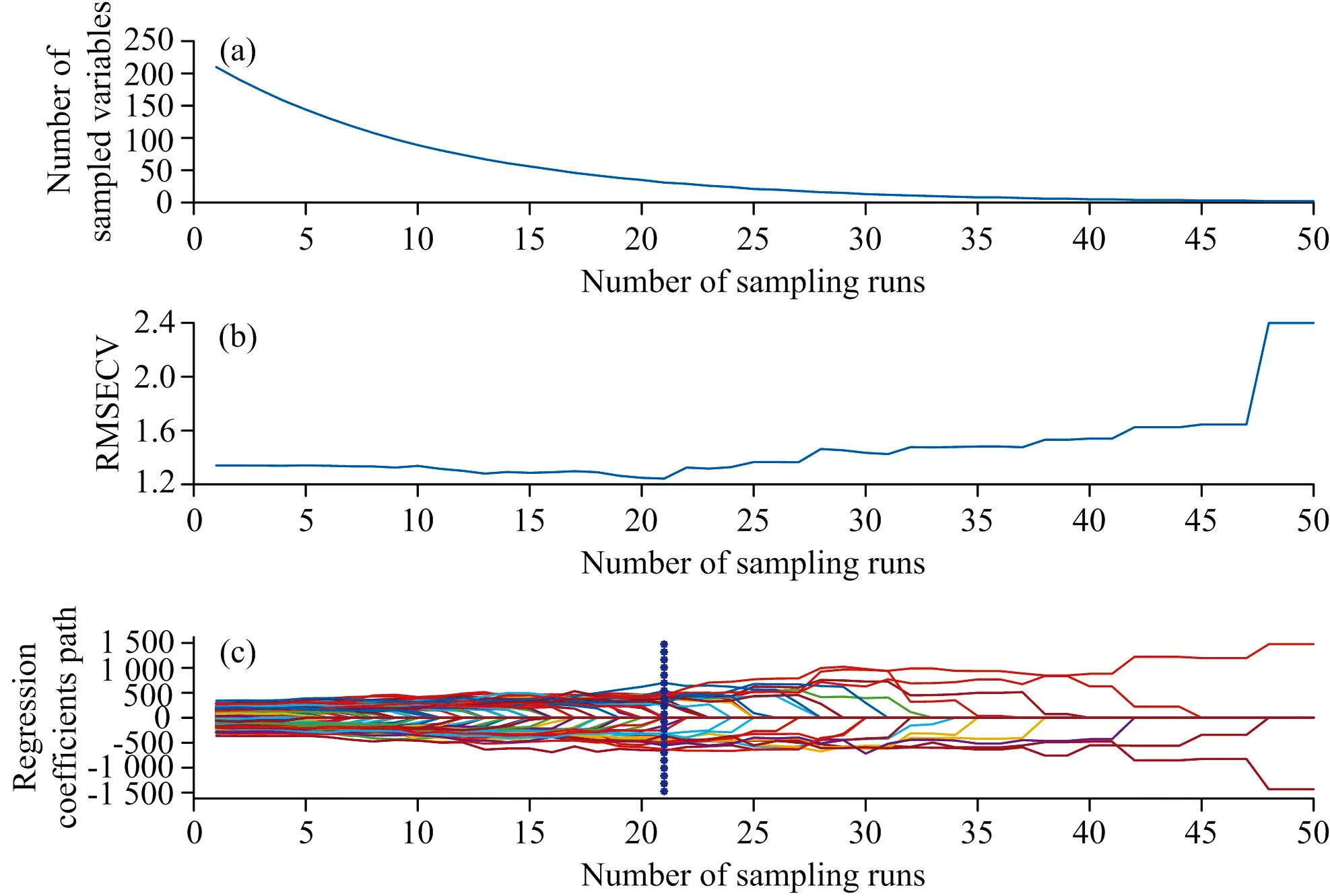
图9 CARS算法提取特征波段
图9(a)中, 特征波段变量数目随着采样次数逐步增加而减少, 在第21次采样之后, 特征波段变量数目下降变缓; 图9(b)表示交叉验证的均方根误差在第21次时达到最小, 之后逐步上升, 在第45次时急剧上升, 说明45次采样后CARS筛选过度, 使有效特征变量数目减少, 导致最终预测模型精度下降, RMSECV上升。 图9(c)表示在第21次采样时, RMSECV最小, 此时特征波段变量数目为31, 表明该采样的特征波段数目包含热损伤玉米种子的有效波段。 因此, CARS选出的特征波段数目为31。
2.4 支持向量机模型建立
分别将SPA提取出的64个特征波段及CARS提取31个特征波段建立SVM模型, 模型准确率如表2所示。 Kappa值越高, 分类效果越好, 模型越稳定。 如式(3)所示
(3)

表2 基于特征波段的建模准确率
式(3)中,po为每类分类正确的样本数之和除以总样本数。
(4)
式(4)中,a为每类样本总数,b为每类样本预测正确个数,m为样本类型数,n为总样本个数。
MSC-SPA-SVM模型的训练集和测试集的平均鉴别准确率为96.30%和95.45%, 其Kappa系数为0.956; 而MSC-CARS-SVM模型的训练集和测试集的平均鉴别准确率为96.48%和96.38%, 其Kappa系数为0.970, 因此MSC-CARS-SVM模型性能最佳, 故选择其为最佳分类模型。
2.5 参数寻优
采用SVM建立分类模型, 需合理设置惩罚参数c和核函数参数g才能得到理想的预测准确率, 因此本研究采用遗传算法对SVM模型参数寻优, 设置迭代次数为200。 种群数量为20, 得到MSC-SPA-SVM模型最佳惩罚系数c为1.939, 最佳核函数参数g为5.561; MSC-CARS-SVM模型中最佳惩罚系数c为14.019, 最佳核函数参数g为1.698; 全波段模型最佳惩罚系数c为1.597, 最佳核函数参数g为2.925。 如表3所示三个模型的平均识别准确率均提升至100%, 结果表明使用优化算法对SVM模型参数寻优, 选出最佳参数建模能提升模型识别准确率。
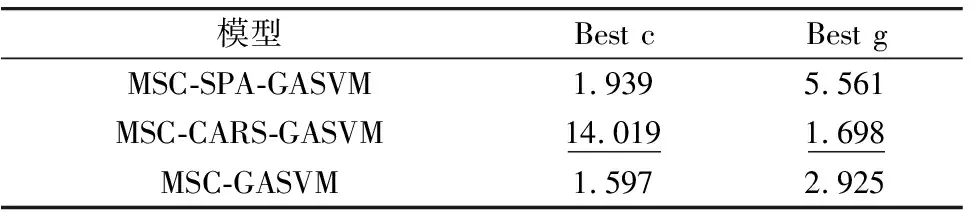
表3 GA算法参数寻优结果
3 结 论
为鉴别劣质种子, 使用鼓风式烘干箱对玉米种子完成热损伤试验, 获得不同热损伤程度的玉米种子, 利用高光谱成像技术, 通过预处理、 特征波段提取、 建模分析, 构建热损伤玉米种子的高光谱无损检测模型。
(1)利用MSC与SNV两种预处理方式对光谱原始数据降噪处理, 建立未处理光谱、 MSC为和SNV的三种SVM全波段模型, 最后以MSC为预处理方式的模型准确率最高, 其训练集与预测集分别是93.89%和96.10%, 故选择MSC预处理。
(2)采用SPA和CARS对用MSC处理后的光谱数据特征波段的提取, 通过建模结果识别准确率分析, 发现CARS>全波段>SPA, CARS的训练集和预测集准确率分别为98.89%和98.33%, 较全波段与SPA分别提升了5%和2.88%、 2.59%和2.23%。
(3)使用遗传算法优化选择SVM中惩罚系数c和核函数参数g, 使得SVM最终模型识别率达到100%, 可实现对热损伤劣质玉米种子的快速准确鉴别。
