基于Sentinel-2时序数据的广东省英德市茶园分类研究
2024-04-08陈盼盼任艳敏赵春江李存军
陈盼盼, 任艳敏, 赵春江, 李存军, 刘 玉
北京市农林科学院信息技术研究中心, 北京 100097
引 言
茶树为多年生常绿灌木, 是一种高附加值的经济作物, 是我国南方山区实现乡村振兴和脱贫攻坚的重要抓手[1]。 至2020年, 我国的茶园面积为4748万亩, 其中广东省茶园种植面积为117.2万亩, 近年来茶树种植面积不断扩大[2]。 随着部分森林、 农田和山地转化为茶园用地, 导致众多生态问题频发, 如毁林种茶、 水土流失、 土地退化等[3-4]。 因此, 实现对茶园面积的快速、 动态监测对茶叶产业的可持续发展至关重要; 也可为政府部门的规划、 管理及茶叶生长监测及估产提供数据支持[5]。
通常, 传统茶园种植面积及其空间分布主要通过人工调查来获取, 该方法精度虽高但耗时耗力, 且无法快速动态的获取茶园的空间分布[6]。 遥感技术具有快速及高效获取数据的优势且成本较低, 已广泛应用于作物提取分类中, 尤其是在茶园提取中, 可为准确及时掌握茶园的空间分布提供强有力的技术手段[7]。 在茶园分类提取中, 遥感技术逐步由中低分辨遥感影像(Landsat、 MODIS)发展到高时空分辨率的遥感影像(ZY-3、 GF及Sentinel-2等)[8-10]。 有研究基于Landsat-8数据提取了云南省临沧市复杂地形中的茶园面积。 马超等采用MODIS数据对茶园进行分类研究, 利用时序的增强植被指数(enhanced vegetation index, EVI) 和归一化植被指数(normalized difference vegetation index, NDVI)构建分类特征[9]。 徐伟燕等采用资源三号卫星数据, 利用不同季节的NDVI差异实现了对平原区和山区的茶树种植进行提取[8]。 杨艳魁等利用高分二号影像数据利用植被指数和纹理特征对茶园进行了分类研究[11]。 上述研究以Landsat、 MODIS卫星影像数据为主的茶园分类提取, 虽然数据的时序性较好, 但影像的空间分辨率较低导致茶园错分漏分情况较多[10]。 以ZY-3和GF-2卫星数据为主的茶园分类研究, 虽然影像数据的空间分辨率较高, 但所获取的波段信息较少, 且在大尺度茶园分类提取研究中应用性较差。
Sentinel-2A/2B卫星具有13个较窄波段及高重访周期, 可以更好地区分不同地物的光谱响应特性差异, 灵敏捕捉各类物质特征波长间的细微差异[12]。 作物对电磁波谱中可见光中的红光波段、 近红外波段极为敏感[13], 尤其是近年来发现植被在红边波段的波动较为明显[14]。 目前, 含有红边波段的卫星有GF-6、 WorldView、 RapidEye、 Sentinel-2等, 尤其是Sentinel-2影像的发布, 包含3个红边波段, 可精准反映其生长发育过程, 为植被的分类提供了更多波段选择[15]。 众多学者基于Sentinel-2影像数据针对作物分类提取已进行较多研究, 如水稻、 玉米、 大豆和甘蔗等作物[16-18], 但目前针对茶园分类的提取研究较少。 李龙伟等利用Sentinel-2影像结合物候和光谱特征, 采用决策树分类方法对浙江西北部地区的茶园进行了提取研究[19]。 Zhu等采用Sentinel-2影像数据, 结合NDVI、 纹理特征、 地形特征, 利用SVM和RF方法对河南信阳地区的茶园进行了提取[5]。 赵晓晴等采用Sentinel-2影像数据, 通过对时序影像的光谱特征和NDVI变化分析, 构建14个植被指数特征, 采用决策树分类对杭州西湖地区的茶园进行了分类研究[20]。 目前采用Sentinel-2影像的茶园提取主要是结合物候和光谱特征进行的, 但由于我国不同地区间物候、 地貌差异性较大, 不同地区的茶园提取特征也具有差异性, 且综合考虑茶园物候特征、 植被特征和纹理特征的茶园提取研究较少。 本文以广东省英德市为研究区, 采用时序Sentinel-2影像数据, 结合研究区的光谱、 植被指数及物候等特征进行茶园的提取, 采用RF和SVM分类方法进行对比研究, 探究时序哨兵数据在县域尺度的应用潜力及其精度。
1 研究区及数据来源
1.1 研究区概况
英德市位于广东省中北部, 粤北山区南部, 三江交汇处, 主要以山地和丘陵地貌为主(图1); 境内气候温和、 雨量丰沛, 为亚热带湿润性季风气候(subtropical monsoon climate), 年均降雨量为1 835.8 mm, 年平均气温约为21 ℃, 年均日照为1 739.4 h, 年均无霜期为319 d, 极适宜茶树生长[21]。 英德市是重要的红茶产区, 被誉为为“中国红茶之乡”, 广泛种植英红九号, 全市茶叶企业有346家, 省级茶叶农业龙头企业11家, 到2019年英德市茶园总面积14.7万亩, 全年干毛茶总产量1.1万吨, 总产值高达41亿元, 是当地重要的经济支柱[22]。

图1 研究区示意图
1.2 数据源及预处理
为了更好地对研究区茶园进行分类, 采用全年12个月的影像数据进行分析。 而实际的数据获取中, 由于研究区5月、 6月降雨较多, 数据的云量高达50%以上, 加之8月数据质量较差, 导致上述月份数据缺失。 因此获取了9个月的影像数据, 其数据信息如表1所示。 所有数据均来源于欧洲航空局哥白尼科学数据中心(European Space Agency’s Copernicus Scientific Data Hub, ESA CSDB)网站(https://scihub.copernicus.eu/)。 Sentinel-2A/B L1C影像数据未经辐射定标和大气校正, 首先利用Sen2cor插件完成对影像数据进行大气校正, 得到Sentinel-2 Level-2A数据; 然后利用SNAP 8.0处理软件对数据进行去云、 重采样、 镶嵌、 裁剪等预处理, 最终获取研究区10 m分辨率的影像数据, 转换数据格式导出至ENVI 5.3进行后续处理。

表1 Sentinel-2影像数据的信息
1.3 样本选取
在2020年9月和2021年5月分别对英德市的茶园分布情况开展野外调查, 走访了英德市15个主要的茶叶分布乡镇, 采集了68个茶园的经纬度信息, 如图1中所示; 结合Google遥感影像, 按照茶园、 森林、 农田、 水体、 居民地等5大类型, 共计选取了627个训练样本与验证样本。 使用分层随机抽样方式, 选择5种地物全部样本区的80%作为训练样本集, 20%的样本作为验证集。
2 实验部分
主要采用研究区9期Sentinel-2影像数据和DEM数据, 通过对所选取的植被指数和纹理特征进行时序变化分析, 并采用Relief算法对植被和纹理特征进行降维, 并结合时序特征构建不同分类场景, 分别利用SVM、 RF等浅层机器学习算法, 获取茶园的空间分布, 最后结合验证数据集评价茶园的分类精度, 对比不同分类方法在不同的分类场景下的精度,选取适合茶园分类提取的最优分类场景和分类方法, 为茶园分类提取提供技术支撑。 技术路线如图2所示。
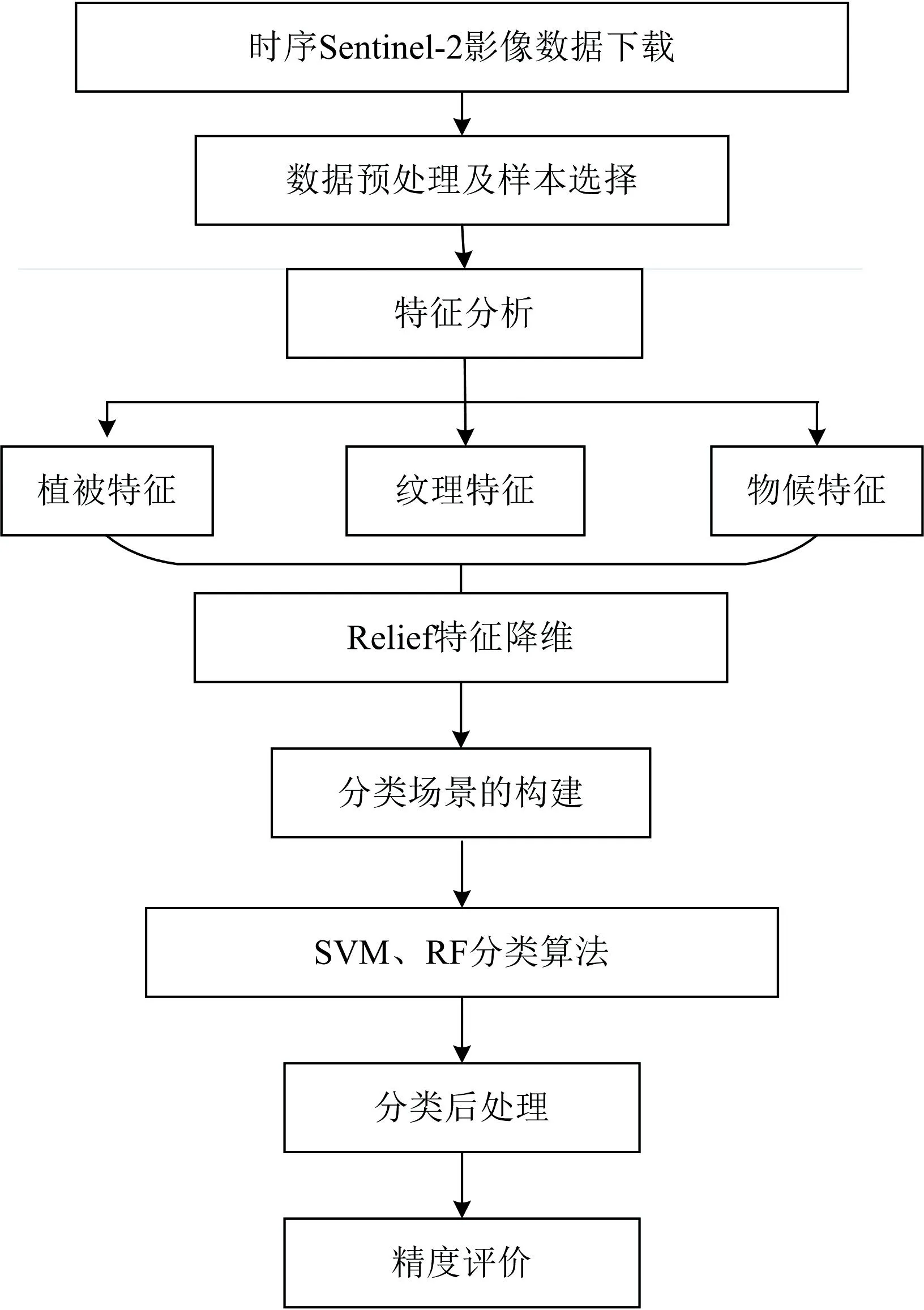
图2 技术流程图
2.1 特征分析
分析并构建茶树作物的物候特征, 可为作物最佳时相的选择提供依据[23]。 为了解茶树的物候特征, 通过询问及文献资料查阅, 获取了英德市茶树生长物候图(图3)。 茶树的生长阶段从每年的3月中下旬开始, 直至当年的10月中下旬, 当年10月中下旬至次年的3月中上旬为茶树生长的休止期, 该时段可更好的积蓄营养[5]。 茶树在当年内大体可分为3个生长阶段: 第一生长阶段为3月下旬至5月上旬、 第二生长阶段为整个6月和第三个生长阶段为8月到10月上旬, 根据采摘的时间将其分别对应为春茶采摘期、 夏茶采摘期、 秋茶采摘期。 为了采摘高品质的茶鲜叶, 在茶树生长的周期内进行修剪, 通常在5月份进行1次深修剪, 分别在8月和9月进行2次轻修剪。
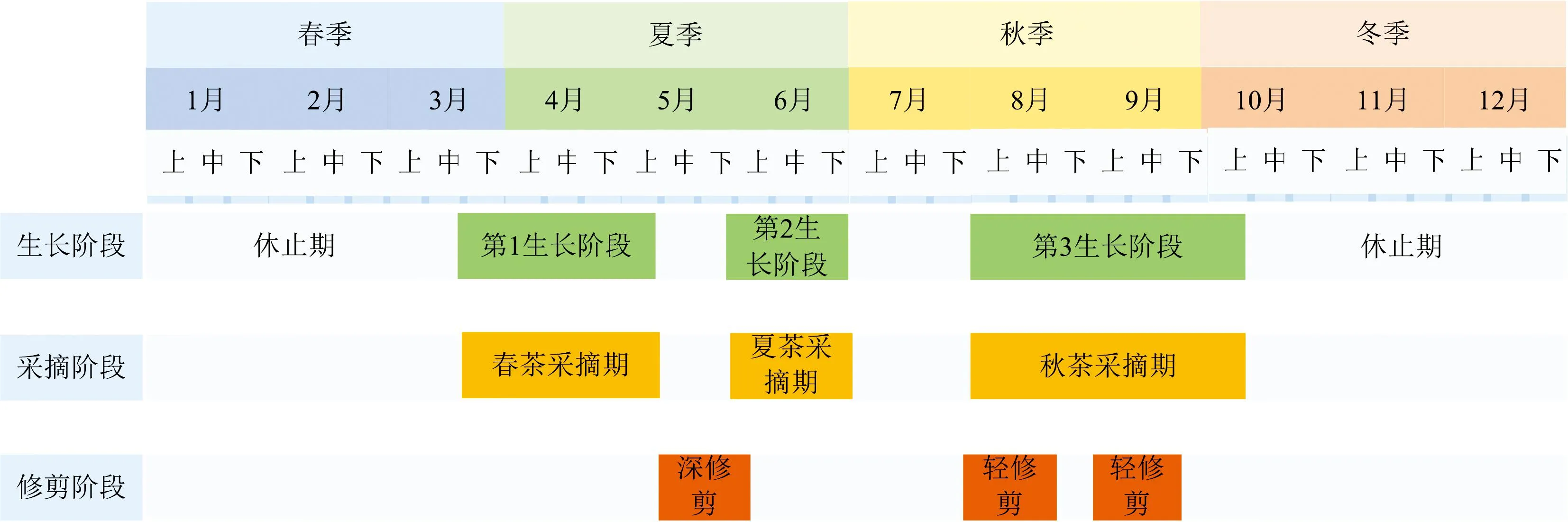
图3 英德市茶树生长物候图
植被指数特征主要是利用植被呈现的不同光谱反映拓性, 遵循经验或半经验模型获取不同的波段组合且具有一定指示意义的数值, 衡量植被的生长及覆盖情况, 并有助于提高遥感影像的解译能力[24]。 结合茶树提取过程中常用的植被指数, 选取了归一化差值植被指数(normalized difference vegetation index, NDVI)、 土壤调节植被指数(soil adjusted vegetation index, SAVI)、 土壤亮度指数(the second brightness index, BI2)、 差值植被指数(difference vegetation index, DVI)、 垂直植被指数(perpendicular vegetation index, PVI)、 修正型叶绿素吸收比值指数(modified chlorophyll absorption ratio index, MCARI)、 特定色素简单比值植被指数(pigment specific simple ratio chlorophyll index, PSSRa)等7个植被指数特征来进行时序分析, 更好地了解茶树在不同季节的植被指数变化, 为茶园的分类提供参考。
依次对不同地类的时序植被特征进行了统计, 如图4所示。 以PSSRa植被特征为例, 农田、 建设用地、 水体的PSSRa值与森林和茶园的PSSRa值差异性较大, 易于区分。 森林和茶园的PSSRa时序特征在春季和夏季时逐渐增大, 冬季逐渐下降。 茶园和森林的PSSRa最低值出现在2月和1月, 分别为4.45和6.99; 茶园和森林的PSSRa值保持增长到10月份达到最大, 分别为12.97和13.42。 但在2月份时, 两者的差异达到最大, 因此在利用PSSRa进行分类提取时, 优先选择春季2月的PSSRa特征来参与后续分类。 其他特征进行同样分析可知, NDVI植被特征差异比较明显的月份在2月, SAVI、 BI2、 DVI、 PVI和MCARI等植被特征差异比较明显的月份均在10月。
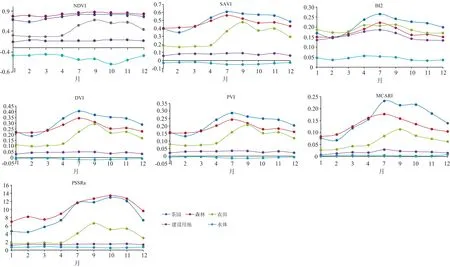
图4 七项植被指数特征时序变化图
利用多特征, 尤其是纹理特征进行组合、 优化和遴选最佳分类特征也是目前常用的分类方法[25]。 纹理特征作为遥感影像在空间上分布和变化的结构特征, 不同的地物类型其纹理特征不同, 可有效提高遥感影像在茶园分类中的精度。 灰度共生矩阵(gray level co-occurrence matrix, GLCM)是一种常用的纹理特征分析方法, 可较好地反映图像中任意两点之间灰度的空间相关性[26]。 本纹理特征主要是基于灰度共生控阵方法, 选取了6个GLCM纹理指标, 即同质性(Homogeneity)、 对比度(Contrast)、 差异性(Dissmilarity)、 熵(Entropy)、 均值(Mean)、 方差(Variance)进行实验, 其窗口大小设置为99像素, 默认设置为等概率量化器来进行纹理提取。 同时考虑到灰度共生矩阵具有方向性, 因此在其角度设置为全方向, 即纹理值为0°、 45°、 90°、 135°四个方向的平均值。
依次对不同地类的时序纹理特征进行了统计(图5)。 以Contrast(对比度)纹理特征为例, 主要侧重易混淆地类茶园和森林来重点分析可知: 茶园的Contrast纹理特征时序变化较大, 在3月时Contrast纹理特征变化最小(26.18); 随后逐渐增大, 在10月份时, 达到最大(144.05)。 森林的Contrast纹理特征在4月份时 Contrast纹理特征值为最小(7.74); 在10月份时, 达到最大(38.23)。 在所有地物中, 茶园的Contrast纹理特征变化最为明显, 且在10月份时茶园和森林的Contrast纹理特征差异达到最大。 因此在利用Contrast进行分类提取时, 优先选择10月的Contrast特征来参与后续分类。 其他特征进行同样的分析可知, Homogeneity、 Dissmilarity、 Entropy、 Mean、 Variance等纹理特征差异比较明显的月份分别在4月、 10月、 4月、 1月和2月。
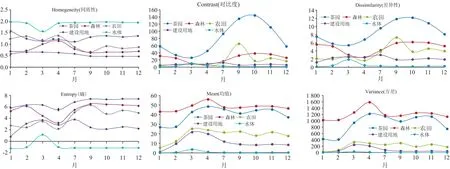
图5 纹理特征时序变化图
2.2 特征筛选
Relief是一种多变量过滤式特征权重算法, 采用样本距离来衡量特征的重要性, 即通过设定权值的阈值, 移除小于阈值的参数可以实现特征降维; 该算法能处理多种类型的数据, 简单、 快捷且高效, 可以很好地去除无关特征[27-28]。 其Relief算法的主要步骤如下:
(1)定义所有样本数据为m×n维数矩阵, 把n个样本的特征数据存放于数据库中, 并把待训练的第i个样本的N个特征对应在第i列中。
(2)寻找n的同类样本中最近邻样本H和不同类样本中的最近邻样本M;
(3)如果样本n中的特征与同类H的距离小于与不同类M的距离, 则表明该特征可以实现不同地类的分类, 也进一步说明该特征的权重值较高。 则训练第p个特征样本过程为:
定义不同维数特征初始权值为0, 且p=1, 2, …,N。
①定义训练的样本总数为n, 在1到n中重复选取i值;
②定义所有不同样本特征总数为N, 在1到N中重复选取p值;
③更新特征p的权值如式(1)所示。
(1)
其中, diff()函数形式如式(2)所示。
(2)
(4)重复迭代步骤3次, 获取不同特征的平均权重值。 特征权重值越大, 则该特征对茶园分类的贡献度越高。 本特征排序主要是基于python编程语言, 采用Relief算法实现, 结果如图6所示。

图6 特征因子权重示意图
2.3 分类场景构建
根据特征排序结果, 选取特征权重值加权大于90%所有特征, 即NDVI_2、 PSSRA_2、 BI2_10、 Variance_2、 MCARI_10、 MEAN_1、 SAVI_10、 PVI_10、 DVI_10等9个特征, 依次递增, 构建了9类分类场景, 如表2所示。

表2 九种不同分类场景组合
2.4 分类方法及评价
为了评估上述分类场景对茶园提取的影响, 根据特征排序的权重值依次递增特征, 组合成上述9类分类场景。 采用随机森林分类方法对9种分类场景进行处理, 主要由于随机森林(random forest, RF)在处理高维数据时具有较强的灵活性且速度较快, 可解决过度拟合的问题[29]。 同时为了探究不同分类方法对茶园提取的影响, 在利用随机森林分类方法确定最佳分类场景后, 进一步采用支持向量机(support vector machines, SVM)分类方法来验证不同分类方法对茶园提取精度的影响。 其中, 支持向量机分类方法核心思想是求解能够正确划分训练数据集并且几何间隔最大的分离超平面, 该方法可以自动寻找对分类有较大的区分度的支持向量并构造分类器, 使得各类之间的间隔最大[30]。 为了更好地评价分类结果, 选取总体精度(overall accuracy)、 Kappa系数(Kappa coefficient)、 生产者精度(producer accuracy)和用户精度(user accuracy)4个指标来对茶园分类结果进行评价。
3 结果与讨论
3.1 不同分类场景结果对比
根据上述9种分类场景, 采用随机森林分类方法对英德市的茶园进行了提取实验, 并采用上述4个指标对分类结果进行验证(表3)。 由表3可知, 仅利用NDVI(Scenes_1)进行分类时, 其分类提取结果精度较低, 总体精度为72.02%, Kappa系数为0.64; 当分类特征逐渐增多时, 在Scenes_6场景时, 分类精度达到最大, 总体精度为91.48%, Kappa系数为0.89, 生产者精度和用户精度分别为89.86%和73.31%。 随后增加分类特征, 但总体精度基本保持约91%, 且用户精度降低。 由此可知其最佳分类场景为Scenes_6。

表3 不同分类场景精度评价结果
3.2 不同分类方法结果对比
为了进一步探讨不同分类方法在茶园提取精度上的优劣, 基于上述9种分类场景中的最优分类场景(Scenes_6), 采用相同的训练和验证样本数据集, 采用支持向量机(support vector machine, SVM)分类方法进行茶园的提取实验, 其统计结果如表4所示。 RF分类算法的总体精度为91.48%, Kappa系数为0.89, 生产者精度和用户精度分别为89.86%和73.31%; SVM分类算法的总体精度为91.56%, Kappa系数为0.89, 生产者精度和用户精度分别为80.22%和84.56%。 由上述分析可知, 在进行茶园分类时SVM算法分类精度较高, 分类结果如图7所示。 实验可知, SVM算法的总体精度及用户精度相对于RF算法都较高, 对所分类的地类较细致, 这样间接提高了分类的用户精度, 而在一定程度上牺牲了生产者精度, SVM算法总体精度优于RF。 但在数据处理过程中, SVM方法相比于RF方法耗时较长, 这在一定程度上也削弱了SVM的优势。

表4 不同分类方法精度评价结果

图7 英德市茶园分布示意图
主要探讨了基于Sentinel-2影像并结合多时序多特征信息在茶园提取中应用。 王斌[31]等采用Landsat-8 OLI影像, 选择多季节的光谱、 纹理和物候特征进行组合, 研究表明多季节特征融合提取精度高于单季节, 其总体精度为92.4%, Kappa系数为0.897, 生产者精度为87.5%。 本工作同样通过构建多季节时序的植被、 纹理特征进行不同场景组合, 可知分类场景为Scenes_6时精度较高, 其总体精度达到91.48%, Kappa系数为0.89, 生产者精度和用户精度分别为89.86%和73.31%, 本研究结果与其结果相一致, 也证明了多季节特征构建对于茶园提取精度具有重要作用。 本工作2月和10月为最佳提取时间, 可能是由于2月茶树长出嫩绿的新叶与周围森林植被较易区分, 而在10月上旬茶树进行修剪阶段, 茶树的植被指数和纹理特征比较明显, 进而2月和10月的特征组合茶园提取的精度较高。 李龙伟[19]采利用多时相的Sentinel-2影像, 通过构建归一化茶园指数(normalized difference tea garden index, NDTI), 仅选取2月的NDVI和5月的NDTI, 利用决策树分类方法对浙西北的茶园进行了提取, 总精度达93.83%, Kappa系数为0.917, 茶园生产者精度为95.50%, 用户精度为92.00%。 赵晓晴[20]等采用多时相的Sentinel-2影像, 结合红边波段和NDVI构造了18个茶园的提取特征进行实验, 并采用决策树分类算法对浙江杭州西湖区的茶园进行了提取, 分类精度较高的前3个特征总体精度依次为96.71%、 94.24%和93.43%。 柏佳[34]等利用GF-1和Sentinel-2时序数据, 对浙江省武义县王宅镇的茶园进行了提取, 结合光谱和纹理特征, 采用随机森林分类方法进行研究, 结果表明总体精度为96.91%, 茶园提取的精确率为 89.00%。 同时, 将SVM和RF分类结果与Chen等[33]采用决策树方法进行茶园分类结果对比可知: 基于决策树的茶园分类结果, 用户精度较高, 生产者精度较低; 而采用机器学习(RF和SVM)等算法进行的茶园分类结果可知生产者精度较高, 用户精度较低, 这主要是由于在利用决策树分类时, 相关参数的阈值设置直接影响了用户精度, 在进行阈值设置时阈值设定的范围越小, 不同地类错分的可能性就较小, 但同时由于阈值设定的范围较小, 导致不同地类漏分的可能性增大, 因此在分类结果中导致用户精度较高, 生产者精度较低。 围绕Sentinel-2数据的茶园种植提取的精度略高于本文, 这主要是由于李龙伟和赵晓晴等在进行分类方法选择时采用了决策树分类方法, 该方法可以更加直观地确定所选分类特征的阈值范围。 与其他研究区相比, 本研究区的总面积相对较大, 而茶园总面积相对较少, 也对本提取精度造成了一定的影响。
4 结 论
以9期时序Sentinel-2影像数据, 分析了茶树生长的物候特征, 并详细研究了5种典型地物的植被指数和纹理特征时序变化, 采用Relief算法对所有特征进行重要性排序, 旨在发掘可用于茶园提取的植被指数和纹理特征与最佳时间窗口, 探索多时相多特征融合在茶园遥感识别中的应用潜力。 构建了9种分类场景, 并采用RF算法对所有分类场景进行精度评价, 选取最佳分类场景, 并进一步探讨了RF分类算法和SVM分类算法对茶园提取的可行性。 通过对研究结果进行分析, 得出结论:
(1)在进行英德市茶园提取时, 2月和10月是采用多时相构造茶园多特征最佳组合的时间。
(2)通过Relief算法对所选取的特征进行筛选排序, 其重要性排序为NDVI_2>PSSRA_2>BI2_10>Variance_2>MCARI_10>MEAN_1>SAVI_10>PVI_10>DVI_10>Dissimilarit_10>CONTRAST_10>Homogeneity_4>Entropy_4。
(3)RF分类方法与SVM分类方法相比, 后者的精度略高, 其总体精度达到91.56%, Kappa系数为0.89, 生产者精度和用户精度分别为80.22%和84.56%。
