利用图像平滑结构信息指导图像修复
2024-04-08张家骏廉敬刘冀钊董子龙张怀堃
张家骏,廉敬,*,刘冀钊,董子龙,张怀堃
(1.兰州交通大学 电子与信息工程学院,甘肃 兰州 730000;2.兰州大学 信息科学与工程学院,甘肃 兰州 730000)
1 引言
图像修复是计算机视觉领域中的一个重要任务,旨在修复损坏、褪色和含噪图像。以合理逼真的内容和正确的上下文语意填充图像的孔洞区域,使之全景还原,提升画面质感。除此之外,图像修复技术还可用作图像编辑工具,如:移除图像中不需要的目标。
图像修复的早期方法可分为基于扩散的方法和基于块的方法。基于扩散的方法是利用图像中已知的像素信息来推断未知区域的像素值。这种方法在处理较大的缺失区域或复杂的图像结构时无法准确地恢复缺失的细节信息。基于块的方法是将图像分割成块,首先从待修补区域的边界上选取一个像素点,同时以该点为中心,根据图像的纹理特征,选取大小合适的纹理块,然后在待修补区域的周围寻找与之最相近的纹理匹配块来替代该纹理块。然而,当关键区域和重要结构缺损时这种方法面临挑战。
上述两种方法因无法处理结构复杂的图像,常常需要结合深度学习的方法包括基于卷积神经网络(Convolutional Neural Networks,CNN)[1]、生成对抗网络(Generative Adversarial Networks,GAN)[2]、注意力机制和变分自编码器(Variational Autoencoders,VAE)[3]修复方法等来提高处理结构复杂图像的能力。现有的基于结构特征的图像修复方法大致分为两类:非结构指导修复方法[4-8]和结构指导修复方法。非结构指导修复方法包括单阶段修复网络和多阶段修复网络。这类方法通常包含多个修复阶段或子网络,网络在训练时需要按照特定的顺序执行。使用这类修复方法必然会增加整个网络的复杂度和训练难度,也限制了网络的灵活性和适应性。在实际应用中,多阶段网络也会导致错误的累积和传播,影响最终的修复结果。结构指导修复方法[9-12]主要是通过图像的抽象结构特征指导图像修复。这类方法大多选择先修复图像的结构,再依靠完整的结构特征修复图像。网络设计为单方向单路结构,这样的设计导致了图像的修复效果过于依赖结构信息。如果图像的结构存在噪声或边缘不明显,这类方法就无法准确地修复缺失的区域。
本文基于深度学习,提出一种图像平滑结构指导图像修复的网络,网络由图像平滑结构提取网络Ns和图像修复网络Ninp并行组成。其中Ns网络由膨胀卷积组成,Ninp网络由残差门卷积组成。相比于高分辨率的复杂原始图像,图像的不规则平滑结构更容易修复,我们用容易修复的平滑结构图像指导修复困难的高分辨率图像,无疑会降低整个图像修复的复杂程度。Ns网络对Ninp网络的指导功能通过我们提出的多尺度特征指导(Multi-Scale Features Guidance,MFG)模块实现,Ninp网络的解码层利用MFG 模块特征均衡后的指导信息进行图像重建。MFG 模块的设计融入transformer,利用transformer 在局部和全局上下文之间强大的建模能力,使网络能够学习到图像中不同区域之间的依赖关系。本文提出的网络结构可以有效地避免网络中错误信息的累加和传播,MFG 的指导信息能够自动检验并及时纠正错误的填充内容,保证修复结果的准确性。除此以外,我们的方法不同于之前结构指导修复的方法。之前的方法大多是先重建出图像的结构,然后在图像结构的基础上重建出完整图像。而在我们的方法中,结构重建和图像重建是同步进行的,图像的结构信息不作为次级阶段网络的输入。这种设计提高了图像修复的准确性,图像修复结果与结构指导信息之间的依赖性较低,图像修复结果不会因为图像结构中存在噪声或模糊而受到影响。
2 相关工作
2.1 传统图像修复方法
传统的修复方法主要包括基于扩散的方法和基于块的方法。传统方法更加依赖于对图像的先验假设,导致对于复杂结构的图像处理存在一定的局限性。
基于扩散的方法是一种基于局部信息的修复方法,最早由Bartalmio 等人[13]引入到图像处理中,利用待修补区域的边缘信息,采用一种由粗到精的方法来估计等照度线的方向,利用传播机制将信息传播到待修补的区域内。在基于扩散的图像修复方法中,最著名的方法是各向异性扩散[14],该方法的基本原理是根据图像中像素的梯度信息和邻域像素差异计算扩散系数,调整各向异性扩散的强度和方向。除此之外,全变分方法[15]通过对欧拉-拉格朗日偏微分方程求解来迭代传播信息,但视觉连贯性较差。随后,Chan 等人[16]又提出一种曲率驱动扩散模型并将其运用在古壁画修复中,该模型弥补了全变分模型修复视觉不连贯的缺陷。这类方法本质上都是基于偏微分方程和变分法的修复算法,只能处理较小孔洞的修复,无法修补缺失区域的合理结构。
基于块的方法是利用图像块的纹理合成技术填充缺失区域。该方法的核心思想是:将图像分成许多小的块,在缺失区域的周围寻找与之相近的纹理块来匹配缺失区域,借此恢复整个图像。基于块的方法主要有基于块匹配的修复方法、基于块内插的修复方法和基于块稀疏表示的修复方法[17]。Irani 等人[18]最早提出一种多尺度图像匹配算法被广泛的应用在图像修复任务中。随后Criminisi 等人[19]提出一种区域顺序填充方法,根据边缘像素点的填充优先级,在剩余区域查找与优先级最高的像素点相似的像素块,对缺失孔洞进行填充,但这种方法使用信息有限,在高频时效果较差。Barnes 等人[20]提出一种块匹配算法,利用图像的局部相关性实现快速的相邻块匹配。Huang 等人[21]利用图像中间的平行结构,提出了一种块填充的自动补全算法。这类方法在面对大面积缺损且纹理结构复杂的图像时,无法对图像深层的语义信息进行分析。
2.2 基于深度学习的修复方法
在基于深度学习的方法中,Pathak等人[22]早期提出一种无监督的视觉特征学习方法,提出的架构通过逐像素重建损失和对抗损失来训练网络。但自动编码器网络的生成能力欠缺,导致了结果的不可信。Yang等人[23]提出了一种残差学习方法,该方法旨在学习缺失区域的丢失信息,当关键结构缺失,全局图像和局部不一致时,该方法无法实现有效恢复。为此,Iizuka等人[4]引入了全局和局部上下文判别器来训练全卷积修复网络。在Iizuka工作基础上,Demir等人[5]进一步提出了结合全局GAN和新型PatchGAN鉴别器,以达到全局结构一致性和更好的纹理细节。以感受野为关键点,Chen等人[24]结合了全局和局部判别器,提高了图像全局一致性和特征利用率。同样,Quan等人[25]以不同感受野为基础,提出了一种局部和全局细化的三阶段修复网络。Zhang等人[26]基于全局和局部判别器,加入了感知操作,以感知损失引导编码特征接近真实值。在之前全局和局部判别器基础上,Yu等人[7]提出了一种利用训练获取周围图像特征的方法,比GLCIC模型[4]收敛更快,但是无法判断修复位置与整个区域的相互关系。Liu等人[27]关注到不规则孔洞图像填充问题,提出了部分卷积,通过过滤有效像素,解决了修复图像产生的颜色差异和模糊的伪影问题。随后,针对部分卷积,Yu等人[6]提出了门卷积,门卷积的动态特征选择机制弥补了部分卷积的不足,显著提高了图像的颜色一致性和修复质量。Xie等人[28]提出一种可学习的注意力图模块,用于端到端的特征重归一化和掩码更新学习,能够有效地适应不规则孔洞和卷积层的传播。现有的图像修复技术可以生成合理的结果和语义上的有效输出,但是每种掩膜图像只能生成一个合理结果。Zheng等人[29]开创性的提出了一种多元图像修复方法。类似的,Zhao等人[30]通过将实例图像空间和修复图像空间映射到低维多样性空间的方式实现了多结果修复。GAN网络在训练中常出现梯度消失或梯度爆炸问题,Xu 等人[31]提出一种重构采样和多粒度生成的对抗策略,优化了GAN 的训练过程。在图像超分辨率重建任务中,Yi 等人[8]提出了一个上下文残差聚合机制,可实现对2K 图像的修复。在结合图像结构实现重建的工作中,Peng 等人[32]受 到VQ-VAE[33]的启发,通过VQ-VAE 中的矢量量化对结构信息的离散分布进行自回归建模,从分布中采样生成多样的高质量结构。Ren 等人[11]提出了一种结构和纹理生成器组合修复图像的网络,将边缘平滑处理后的图像作为结构表示引导图像修复。Yang 等人[34]提出一种由粗到细的残差修复网络,先修复图像的低频粗糙轮廓,再将细节作为残差添加到粗糙轮廓中。除了深度学习外,我们发现基于脉冲耦合神经网络的类脑算法[35-36]在图像修复领域也具有较大潜力。
3 平滑结构指导图像修复模型
本文提出的图像修复方法由两个并行网络组成:图像结构修复网络Ns和图像全文修复网络Ninp,如图1 所示。Ns网络的目标是重建受损图像的平滑结构。Ninp网络的目标是修复受损图像的全文信息。为了匹配图像的结构和纹理,我们提出多尺度特征指导(MFG)模块,利用MFG 模块特征均衡后的信息指导Ninp网络完成受损图像的重建。和孔洞内的无效像素区域组成。Ns网络和Ninp网络的特征处理层由残差门卷积[6,37]和膨胀卷积[38]组成,如图1 所示。考虑到传统卷积和其他采样方式[39]在训练中会出现填充内容模糊和颜色差异等问题,因此在设计网络时,我们使用门卷积来消除掩码区域伪影,实现填充内容与图像原有内容的连贯。在图像生成任务中,膨胀卷积被用来扩大感受野,使网络能够有效地捕捉更大范围的上下文信息。此外,为了稳定训练过程,防止梯度消失或梯度爆炸,我们在Ninp网络的每个卷积层中引入了光谱归一化方法[40],通过限制权重矩阵的变化范围,使判别器满足Lipschitz 条件,提高模型的鲁棒性。
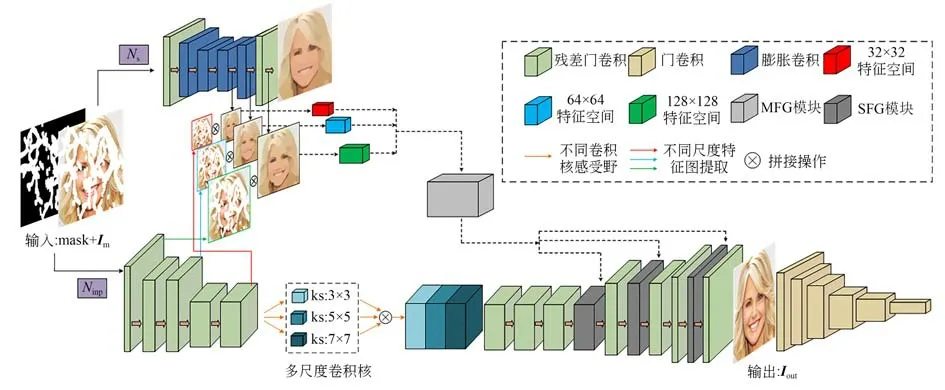
图1 本文方法的总架构Fig.1 Overall architecture of the proposed method in this paper
在对受损图像重建的过程中,Ns网络主要对图像做全变分平滑处理,提取图像的结构信息。平滑结构图像包含了原图像中的多元信息,如图像的边缘、纹理、形状、颜色和亮度。不同于边缘结构,平滑结构主要用于表现图像中的变化程度。在训练过程中,Ns网络对Ninp网络的指导通过MFG 模块实现,MFG 模块的输入包含三个不同维度的多特征空间,特征空间尺寸分别为32×32,64×64 和128×128。特征空间由Ns网络解码层的完整平滑结构图像特征和Ninp网络编码层的受损图像特征融合而成。平滑结构图像经过平滑、滤波和细节模糊处理后更易于分析,比起原始受损图像也更容易修复。因此,我们将相同尺寸的完整结构图像和缺损图像进行匹配,通过MFG 模块对两种特征信息进行建模,建立联系。特征均衡后的信息根据不同卷积层尺度传播到Ninp网络的解码层,指导信息即为图1 中的结构特征指导(Structural Features Guidance,SFG)层。在深度学习中,不同感受野可以捕捉不同尺度的特征信息。其中,较小的感受野适合捕捉局部细节信息,较大的感受野能够捕捉范围更广的上下文信息。不同感受野的设置有助于模型全面地理解数据特征,保证重建后的图像上下文语义一致,Quan 等人[25]已证明不同感受野在图像修复中的有效性。因此,我们在Ninp网络中设置了三个不同感受野使网络充分感知图像中的纹理细节,建立上下文之间的联系。
其中:i表示对应图像的三个尺度,分别是32×32,64×64 和256×256。Igs(i)表示原始完整图像的平滑结构,ISou(ti)表示Ns网络的生成结果。M表示二进制掩码(mask=1)。LShole表示孔洞区域的图像重建损失,LSvalid表示非缺损区域的图像重建损失。表示Ns网络的重建总损失,λrec为平衡因子。
图像全文修复网络Ninp的目标是生成上下文语义一致,色彩纹理完整的图像。Ninp网络的损失函数设置包括重建损失、对抗损失、风格损失和感知损失。重建损失设置与Ns网络相类似,如下式所示:
在重建图像和真实值之间的计算中,我们分别计算三个尺度的重建损失,然后对不同尺寸的损失值累加求和,如图2 所示。多尺度重建损失能够使模型在不同尺度上更好的捕捉图像的细节和结构,也能更好地理解图像的全局和局部特征,从而生成具有更多细节的图像。
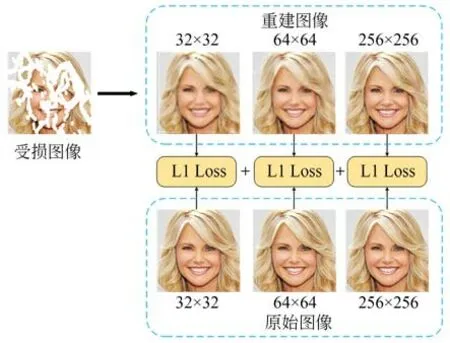
图2 Ninp网络中解码层与真实值之间不同尺度的重建损失Fig.2 Reconstruction losses of different scales between the decoding layer and ground truth values in the network
对抗损失的设置采用LSGAN方法[41]。与传统GAN 的对抗损失相比,这种方法可以使生成器产生更真实的结果,降低了梯度消失或梯度爆炸的风险,从而提高模型的稳定性和生成效果。对抗损失定义如下:
其中:LD为判别器对抗损失,LG为生成器对抗损失。受诸多图像修复工作[9,27-28,42]启发,我们还设置了感知损失[43]和风格损失[44]。我们使用训练好的VGG-16 网络对图像进行特征提取,在空间特征中计算两者的损失。通过对图像语义信息和纹理特征的比较,感知损失能够有效的衡量生成图像和真实值之间的差异,进而优化生成模型。上述的风格损失中使用格莱姆矩阵捕捉图像的风格特征,计算图像之间的风格差异。格莱姆矩阵是基于特征图的空间信息进行计算的,它可以将特征图通道之间的相关性转化为矩阵的形式。这种相关性可以反映出图像的纹理和结构信息。感知损失和风格损失定义如下:
其中:Fi表示预先训练好的VGG-16 网络中第i 层特征图。Gi表示格莱姆矩阵,代表了特征之间的协方差矩阵以及每种特征之间的相关性。综合上述,图像全文修复网络Ninp的总损失为:
其中,λg和λp都为平衡因子。
图像修复任务的难点在于面对复杂的纹理和结构时,网络模型难以重建出语义合理,内容连贯的图像。图像结构的指导能够在修复过程中准确的定位图像受损区域,然后根据结构信息与受损图像之间的匹配关系进行修复。为了建立结构特征和受损图像特征之间的联系,我们提出MFG 模块对图像关系进行建模,并对Ninp网络的解码层进行指导。如图3 所示,MFG 模块的输入为三个不同尺寸的特征空间。不同特征空间的注意力映射矩阵采用transformer encoder 计算。Transformer 方法可以将图像所有像素展平进行位置编码,有利于网络捕捉全局上下文的信息,建立图像中不同位置之间的依赖关系。不同于传统卷积神经网络需要逐层逐通道计算,transformer 可以并行处理输入序列,拥有更高的计算效率和处理速度。特征空间的注意力映射计算如下所示:
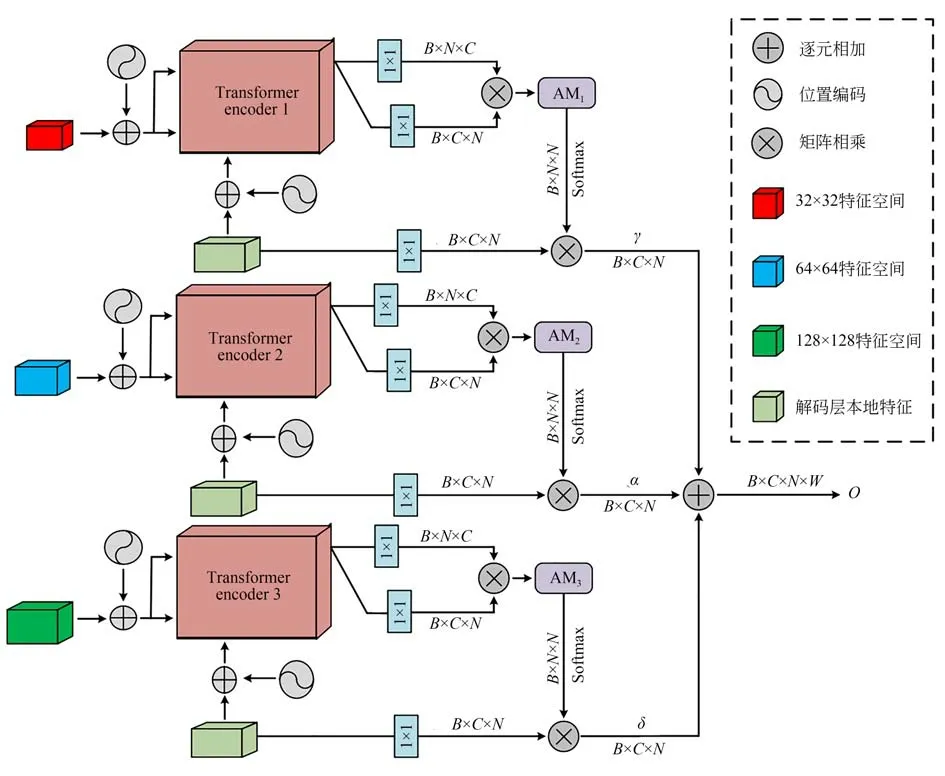
图3 MFG 模块结构图Fig.3 MFG module architecture
其中:Wq和Wk是1×1 卷积滤波器。fi和fj分别表示特征空间中第i个位置和第j个位置的特征。AMij表示对应特征空间的注意力映射。βk,j,i表示第k个特征空间在合成第j个区域时,模型对第i个位置的关注程度。最后MFG 的输出为O,通过不同的尺度变换分别对Ninp网络的解码层进行指导,计算公式如下所示:
其中:γ,α和δ分别为平衡权重的可学习尺度参数,初始值设置为0。F1,F2和F3分别对应32×32,64×64 和256×256 的特征空间。
4 实验与结果
本节阐述了实验中选用的数据集、对比方法和详细的参数设计。通过对比实验,验证本文方法的优越性。最后,通过消融实验验证了本文利用结构特征对修复网络指导的有效性。
4.2 定量分析
本文采用了五种广泛使用的图像质量评估指标:平均绝对误差(Mean Absolute Error,MAE)、学习感知图像块相似性(Learned Perceptual Image Patch Similarity,LPIPS)、弗雷歇初始距离(Frechet Inception Distance,FID)、结构相似性(Structure Similarity Index,SSIM)和峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)。不同的评价指标可以从不同方面反应图像的重建质量[49],这五个常用指标都用于度量图像之间的相似性和失真度。实验中测试掩码使用Liu 等人[27]公布的大型掩码数据集,该数据集共有12 000 张不规则掩码图像,专门用于图像修复任务。根据掩码大小,依次选取了1%~10%,10%~20%,20%~30%,30%~40%,40%~50% 和50%~60%六张掩码图像用于测试,如图4 所示。每张测试图像的分辨率为256×256。表1~表3列出了使用不同比例掩码图像测试下,本文方法与其他五种先进算法之间的测试数据对比。通过定量分析发现,我们的方法虽然没有在每项指标中都得到最好的结果,但从整体数据来看存在明显的优势。
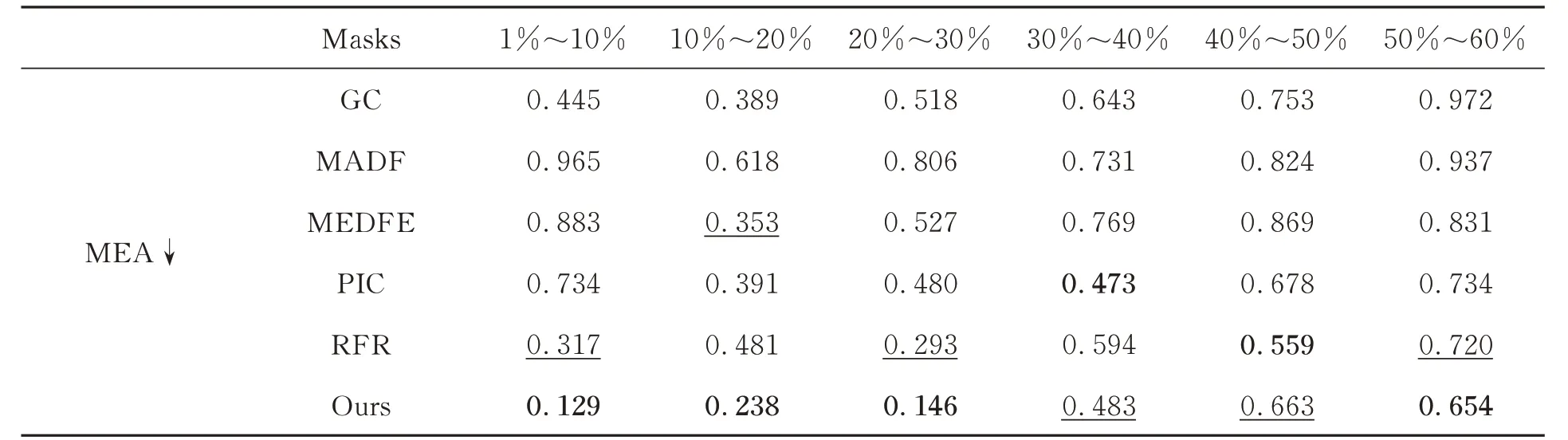
表1 使用CelebA-HQ 数据集测试Tab.1 Tested on the CelebA-HQ dataset
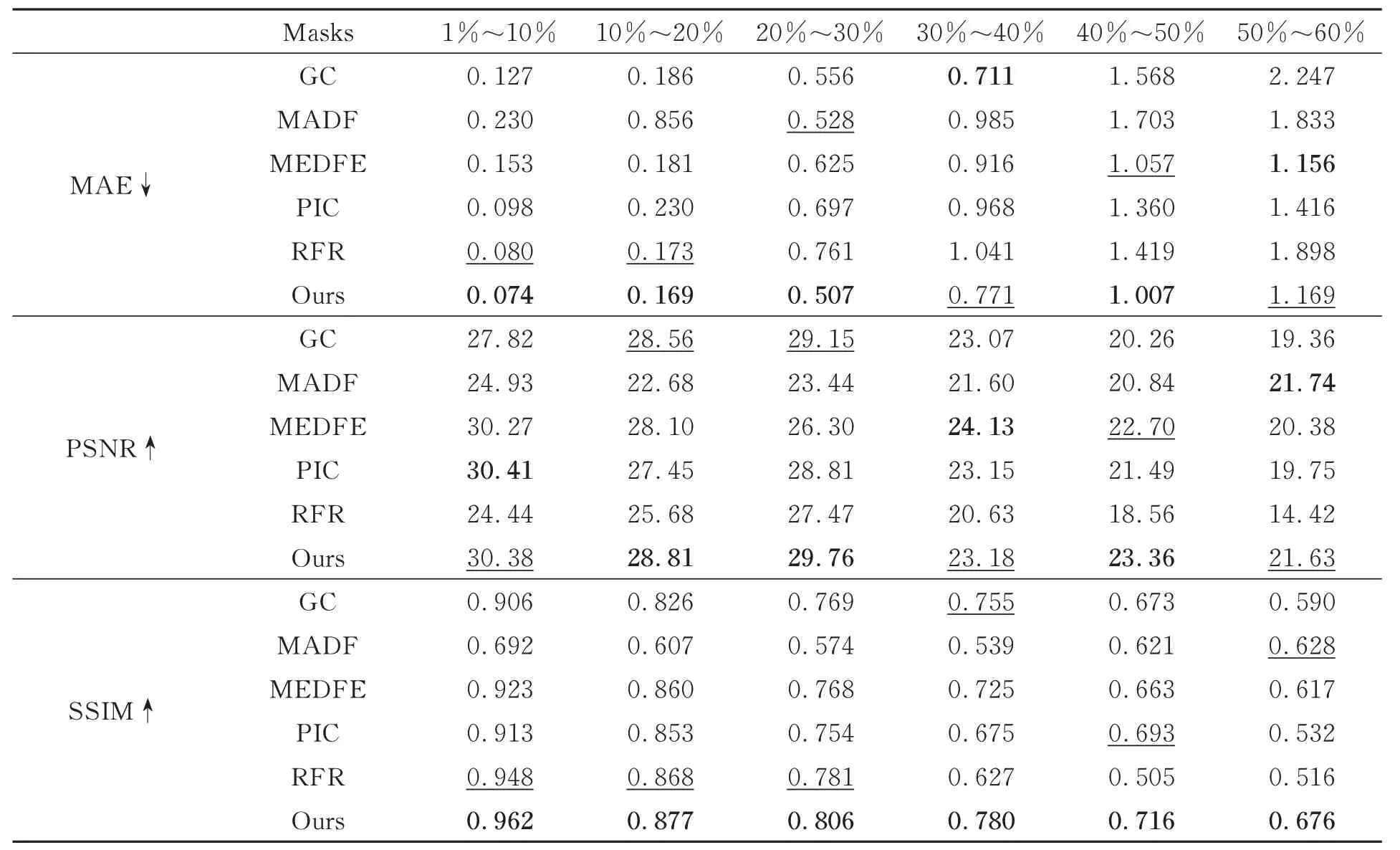
表3 使用Places2 数据集测试Tab.3 Tested on the Places2 dataset

图4 定量比较中所选取的6 种掩码图像Fig.4 Six mask images selected for quantitative comparison
4.3 定性分析
我们用本文方法与其他五种图像修复方法在CelebA-HQ,Paris Street View 和Places2 数据集上做相同掩码区域的测试,如图5 所示。比较方法包括GC,PIC,MEDFE,RFR 和MADF。首先,在CelebA-HQ 数据集上,本文方法修复出的图像更加准确细腻,可以完整地恢复出人物面部特征,并且没有产生模糊和伪影。其他方法的修复结果则出现了伪影、像素模糊和语义不合理等一些问题且重建内容不符合人眼的视觉特性。其次,在Paris Street View 数据集测试中,PIC 方法存在明显的噪声(第三排和第四排的第六张图像),受损图像的填充纹理出现语义错误。最后,在Places2 数据集测试中,RFR 和GC 方法的测试结果较为模糊(第五排的第五张和第七张图像),其中RFR 测试结果的不同信息(山脉和天空)发生混叠且边缘不明显。MADF 和RFR 方法得到的结果虽然合理,但是出现了明显的较大像素块(第六排的第三张和第五张图像),像素块区域分辨率低,导致图像整体衔接不自然。在实际图像测试中,本文方法的测试结果完全符合上下文语意,并且修复后的图像没有模糊的纹理块和伪影。

图5 本文方法与其他方法在三种数据集上的定性比较。前两排为CelebA-HQ 数据集图像,第三和第四排为Paris Street-View 数据集图像,最后三排为Places2 数据集图像。每组图像都使用不同的掩码进行测试。GT 表示图像真实值。Fig.5 Qualitative comparison between the proposed method and other methods on three datasets.The first two rows display images from the CelebA-HQ dataset,the third and fourth rows show images from the Paris StreetView dataset,and the last three rows present images from the Places2 dataset.Different masks were used for testing in each image set.GT represents the ground truth.
4.4 消融实验
为了验证Ns网络和Ninp网络拼接后的特征空间通过MFG 模块指导图像修复的有效性,我们将MFG 模块换为简单的特征融合模块进行训练,将训练后的网络与原网络进行比较,比较结果如图6 所示。第一组图像中,没有MFG 模块的网络无法合理的修复出人物的眼睛特征。修复结果和结构指导图像中的人物眼睛一大一小,无法合理的修复出图像。图6 中的第二组图像也是如此。没有MFG 模块网络的修复结果中,人物的嘴部结构变形且对应的结构指导信息没有这一区域的结构特征。

图6 有MFG 模块网络与无MFG 模块网络的修复结果比较Fig.6 Comparison of inpainting results between networks with MFG module and networks without MFG module
除了定性分析,还对测试结果进行了定量比较,如表4 所示。无MFG 模块的网络修复结果在五种客观指标下都低于有MFG 模块的网络。通过实验,证明了只将结构指导特征融合,无法有效的指导网络解码出语义合理的完整图像。MFG 模块对图像修复任务的贡献在于建立了受损图像和图像结构之间的联系,使修复结果内容合理且满足上下文语义的一致。

表4 消融实验定量分析Tab.4 Quantitative analysis of ablation experiments
4.5 置信度分析
为了验证所提出的网络结构和MFG 模块的有效性,选择了MEDFE[9]和BGCI[50]网络与本文方法进行置信度比较,这两种网络的设计方式和功能组成模块与本文类似,适合与本文方法进行横向对比实验。MEDFE 网络是通过结构和纹理的特征均衡对解码器进行指导,与本文方法的平滑结构特征指导修复类似。BGCI 网络是基于transformer 进行的图像修复,与本文方法中基于transformer 的MFG 模块类似。在图像修复中,置信度是指网络对修复结果的可信度,一般表示修复结果的可靠性和质量。在实验中,依次对MEDFE 网络中接受指导信息的解码器部分、BGCI 网络中transformer 后的解码器部分和本文网络中MFG 模块后的解码器部分进行了置信度分析。为了便于观察,将置信度分布的像素矩阵可视化为256×256 的图像,如图7 所示。

图7 置信度分布可视化图示Fig.7 Visualization of the confidence level distribution
从置信度分布的可视化结果来看,颜色越暗的区域表示预测的生成结果区域与图像真实值越接近,颜色越亮的区域表示预测的生成结果区域与图像真实值越不一致。第一组人脸图像测试中,BGCI 方法在人物五官的重建能力方面明显不如MEDFE 和本文方法。而MEDFE 方法的总体置信度分布低于本文方法。第二组街景图像测试中,本文方法在整体修复和细节修复方面都胜于其他两种方法。通过与本文方法类似结构和类似模块的横向对比实验发现,本文网络中的指导设计和MFG 模块对图像修复任务具有较好的效果。
4.6 目标移除
目标移除就是去除图像中不需要或不想要的对象,以改善图像的外观或满足特定的需求。为了验证我们的方法可以有效地移除图像中不需要的目标,在Places2 和Paris Street View 数据集上进行了测试并做出定性分析。定性分析如图8 所示。MADF 方法的测试结果中存在掩码区域的轮廓伪影,并且目标移除后的区域存在模糊的纹理块,该方法的目标移除效果并不理想。GC 方法虽然可以在Paris Street View 数据集上完美地移除图像中的目标,但是在Places2 数据集上目标移除后的图像出现了伪影和模糊的纹理块。本文方法可以成功地将图像中的目标人物移除。目标移除后的图像在视觉上实现了逼真的效果,且图像的掩码区域没有产生模糊和伪影。

图8 不同场景下我们方法与其他两种方法的目标移除效果对比(GT 表示图像真实值,Mask 表示掩码图像)Fig.8 Comparison of object removal effect between our method and other two methods in different scenarios(GT represents the ground truth,and Mask represents the mask image)
5 结论
本文设计了一个由图像平滑结构指导图像修复的并行网络结构,使用多尺度特征指导模块对网络的图像重建进行指导和约束。图像结构指导图像修复的设计与操作,避免了错误特征的传播,降低了结构对图像生成能力的依赖,极大提高了网络的鲁棒性。本文最后给出的定量与定性对比实验数据表明,本文方法不仅在图像修复效果上具有优越性,还可作为具有目标移除功能的图像编辑工具。
