基于国产ARM架构CPU的导航卫星精密定轨解算效率优化方法
2024-04-02唐成盼周善石陈建兵胡小工冯学斌陈桂根
廖 敏 唐成盼 周善石 陈建兵 胡小工 冯学斌 陈桂根 李 凯
1 中国科学院上海天文台,上海市南丹路80号,200030
2 中国科学院大学,北京市玉泉路19号甲,100049
3 探索数据科技(深圳)有限公司,深圳市留仙洞路33号,518055
提高导航卫星精密定轨解算效率是GNSS卫星精密定轨技术的研究重点之一[1-2]。Ge等[3]采用消参方法,在每个历元时刻消去法方程中的过时参数,极大地减少了最终法方程解算参数的个数,从而有效提高了导航卫星精密定轨解算的效率,该方法是从算法层面对解算效率进行优化。随着CPU的迭代发展,部分学者开展基于CPU技术提高计算效率的研究,包括基于CPU的多核、多线程并行运算技术[4-5]和基于CPU分层存储架构的方法[6]。
目前,关于提高GNSS数据处理软件计算效率的研究几乎都是基于X86架构的Intel CPU,涉及国产ARM架构CPU[7]上效率提升的实验和研究很少。在科学计算中,线性代数库是运行效率优化的重要工具,Lapack能以高效的方式实现科学计算的接口规范[8],并且适用于X86、ARM和PowerPC等不同架构平台。Intel CPU发展至今已经很成熟,Intel可实现适应其CPU的高效运算库Intel Math Kernel Library(MKL)。表1为导航卫星精密定轨处理软件分别运行于Intel CPU中性能突出的X86架构Intel(R) Xeon(R) Gold 6134 CPU(表中Intel)和国产CPU中性能突出的飞腾ARM FT-2000+CPU(表中ARM)的运行耗时,软件运行时采用相同的数据和场景。可以看出,采用Lapack时,Intel CPU的解算效率是ARM CPU的3倍多;采用MKL后,Intel CPU的解算效率是ARM CPU的5倍多。由此可知,ARM CPU还需要寻求更合适的优化方法以提升导航卫星精密定轨的解算效率。

表1 Intel CPU和ARM CPU单次迭代平均耗时
本文选取国产飞腾CPU的最新型号FT-2000+进行卫星精密定轨解算效率优化研究。
1 GNSS卫星精密定轨解算
1.1 解算原理
设历元i的第j条观测是接收机r与卫星s的伪距相位观测,添加动力学约束的观测方程为:
(1)

将式(1)在近似值处线性化得到:
(2)
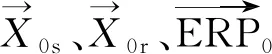

表2 GNSS精密定轨中待估参数的时效性
由表2可以看出,卫星钟差参数和接收机钟差参数个数总量远大于其他待估参数个数。然而钟差参数的有效期仅为一个历元,属于局部参数,因此将其约化处理进行定轨解算。式(2)的向量形式可表示为:
Pj(ti)=
(3)
更一般地,历元i第j条观测的观测向量方程可表示为:
(4)
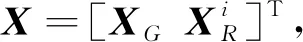
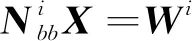
(5)
(6)
式中,m为历元i中的观测数量。根据式(5)和(6),历元i的法方程可写为:
(7)
根据式(7)可得:
(8)
将式(8)代入式(7),可获得消去局部钟差参数后的历元i的法方程:
(9)
根据式(9)对各历元法方程进行叠加,可建立所有历元观测数据统一的法方程:
(10)
式中,n为历元个数。对上式求逆解算可得:
(11)
式中,XG为最小二乘全局参数最优解。将XG代入式(8)可得到各历元时刻的局部参数解。
1.2 解算耗时分析
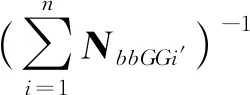

表3 导航卫星精密定轨解算各环节复杂度分析
2 GNSS卫星精密定轨解算效率优化
为充分发挥ARM架构CPU的计算效能,采用基于CPU的多核、多线程并行运算技术和基于CPU的分层存储架构对上述2个计算耗时最长的矩阵进行优化。采用多线程方法对钟差参数约化解算部分进行优化,采用OpenBlas对统一方法求逆部分进行优化。OpenBlas是同时采用上述2种方法实现矩阵运算效率提升的开源高性能科学计算库。
2.1 基于多线程的消参并行解算优化
通过式(5)可以获得NbbGRi、NbbGRi和NbbRRi,然后计算NbbGRi(NbbRRi)-1NbbRGi,最后完成式(9)的计算。由此可知,钟差参数约化解算部分NbbGRi(NbbRRi)-1NbbRGi在解算过程中是完全独立的,可以单独对其进行优化。优化过程为:首先优化矩阵运算NbbGRi(NbbRRi)-1,然后优化矩阵运算NbbGRi(NbbRRi)-1NbbRGi,这2步的优化方法一致。矩阵乘法运算可表示为CI×J=AI×PBP×J。软件中代码实现是对浮点数的一个3层循环运算,见图1,图中aip、bpj、cij分别为矩阵A、B、C的元素,是一个串行执行过程。
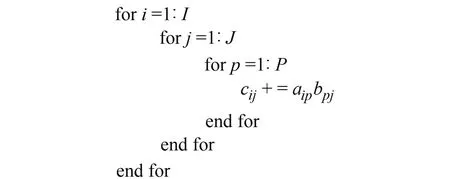
图1 矩阵乘法的3层循环实现
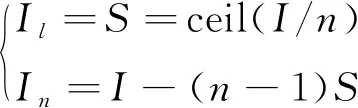
2.2 基于OpenBlas的矩阵求逆解算优化
Lapack相比基础线性代数程序从算法层面进行了许多优化,OpenBlas继承了这些优点,并进一步采用前文基于CPU技术特点的2个优化方法对矩阵运算进行优化。基于CPU分层存储架构优化计算效率的具体思路见文献[9]。
在多线程并行优化方面,OpenBlas采用仅将矩阵B作列拆分的方式进行多线程优化[10]。在此基础上,考虑每个线程独有的缓存资源以及共享缓存资源,根据线程数调整内核GEBP[9]的大小,使内核GEBP适合缓存大小,以减少缓存不命中的情况,详细过程见文献[10]。
3 实验分析
CPU具体架构信息见表4,GNSS卫星精密定轨软件的具体解算策略见表5。采用32颗卫星和不同数目的测站检验精密定轨解算优化情况,每次定轨解算执行8次迭代,每次迭代均重复执行消参和法方程求逆解算。
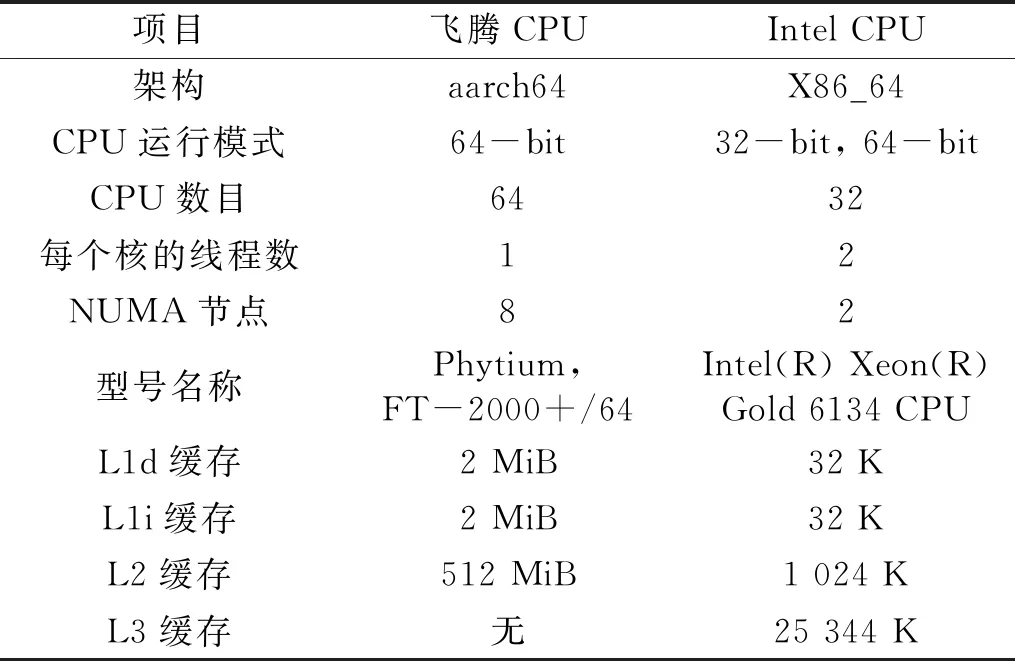
表4 国产飞腾CPU和Intel CPU架构信息

表5 GNSS卫星精密定轨软件解算策略
在飞腾CPU上进行解算时,采用16个线程的多线程方法对消参部分进行优化,优化前后解算效率对比见图2。可以看出,相比于原始单线程,采用多线程后消参解算效率大幅提升。随着测站数量的增加,采用单线程消参解算耗时急剧上升,而多线程解算耗时平缓上升,且多线程解算效率提升效果更明显。在100个测站的情况下,统计第1次迭代中各历元单线程和多线程消参解算耗时。单线程解算1个历元平均耗时1.105 s,而多线程仅为0.188 s。100个测站情况下所有8次迭代消参耗时情况见图3。由图可知,与第1次迭代耗时情况一致,多线程解算效率约为单线程解算效率的6倍。
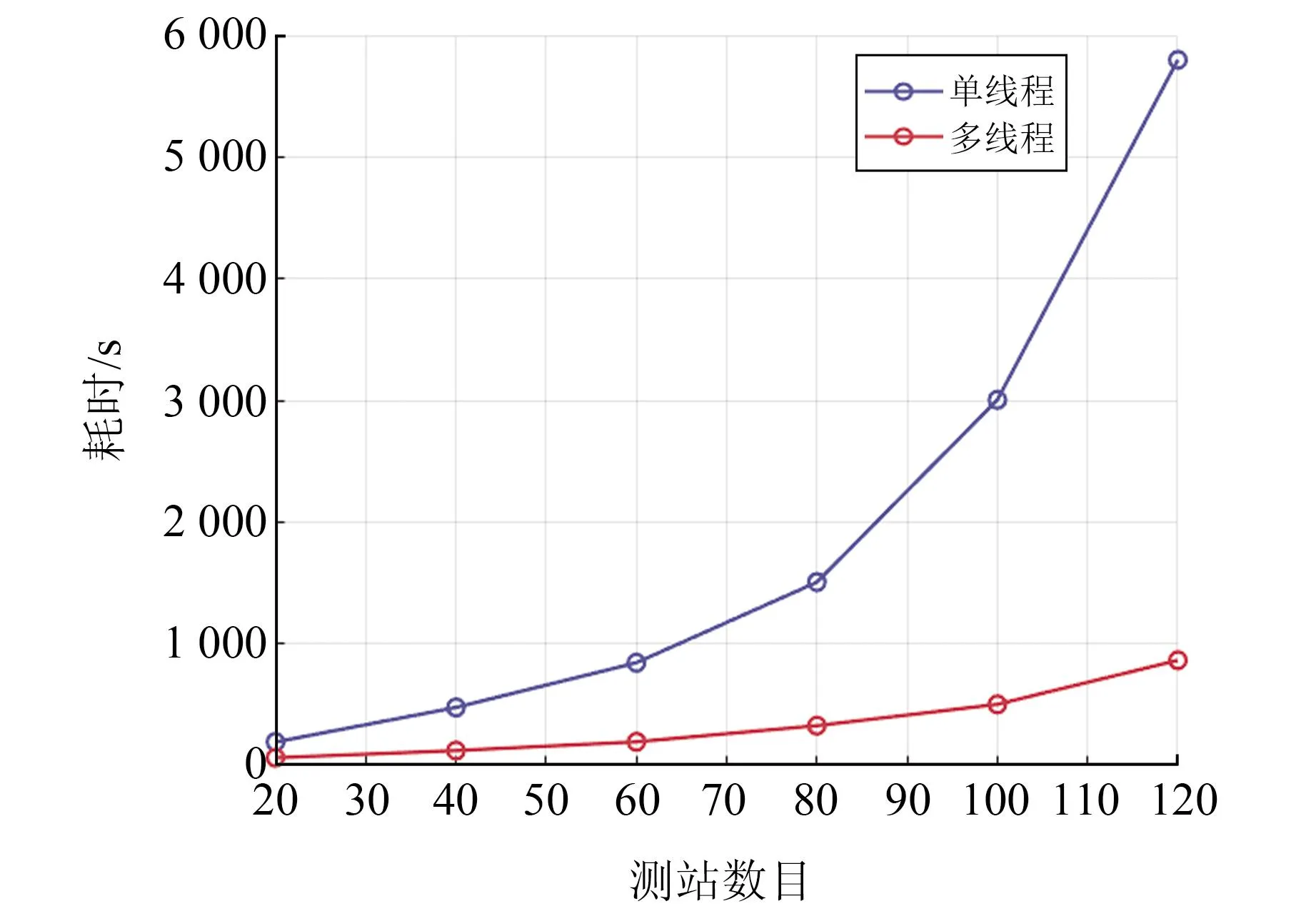
图2 消参部分采用单线程和多线程解算耗时对比

图3 100个测站解算8次迭代消参耗时
对于求逆解算,将采用单线程和多线程矩阵运算优化方法的OpenBlas库和原始Lapack库进行解算对比。OpenBlas库采用16线程,统计每次解算中8次迭代统一法方程求逆耗时的平均值,图4为不同测站情况下采用Lapack库和OpenBlas库法方程求逆平均耗时对比。可以看出,OpenBlas库解算效率明显优于Lapack库,且随着测站数目的增加,OpenBlas库的优势更加明显。图5为在100个测站情况下,8次迭代中二者法方程求逆解算耗时对比。经统计,采用Lapack库平均耗时为2 264 s,采用OpenBlas库平均耗时仅为78 s。
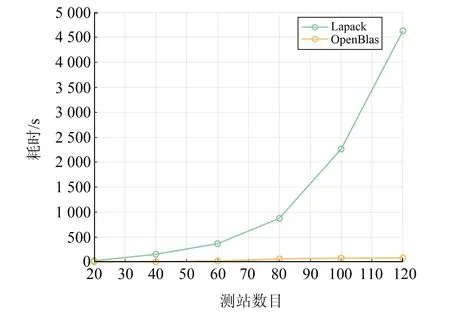
图4 采用Lapack库和OpenBlas库法方程求逆平均耗时对比
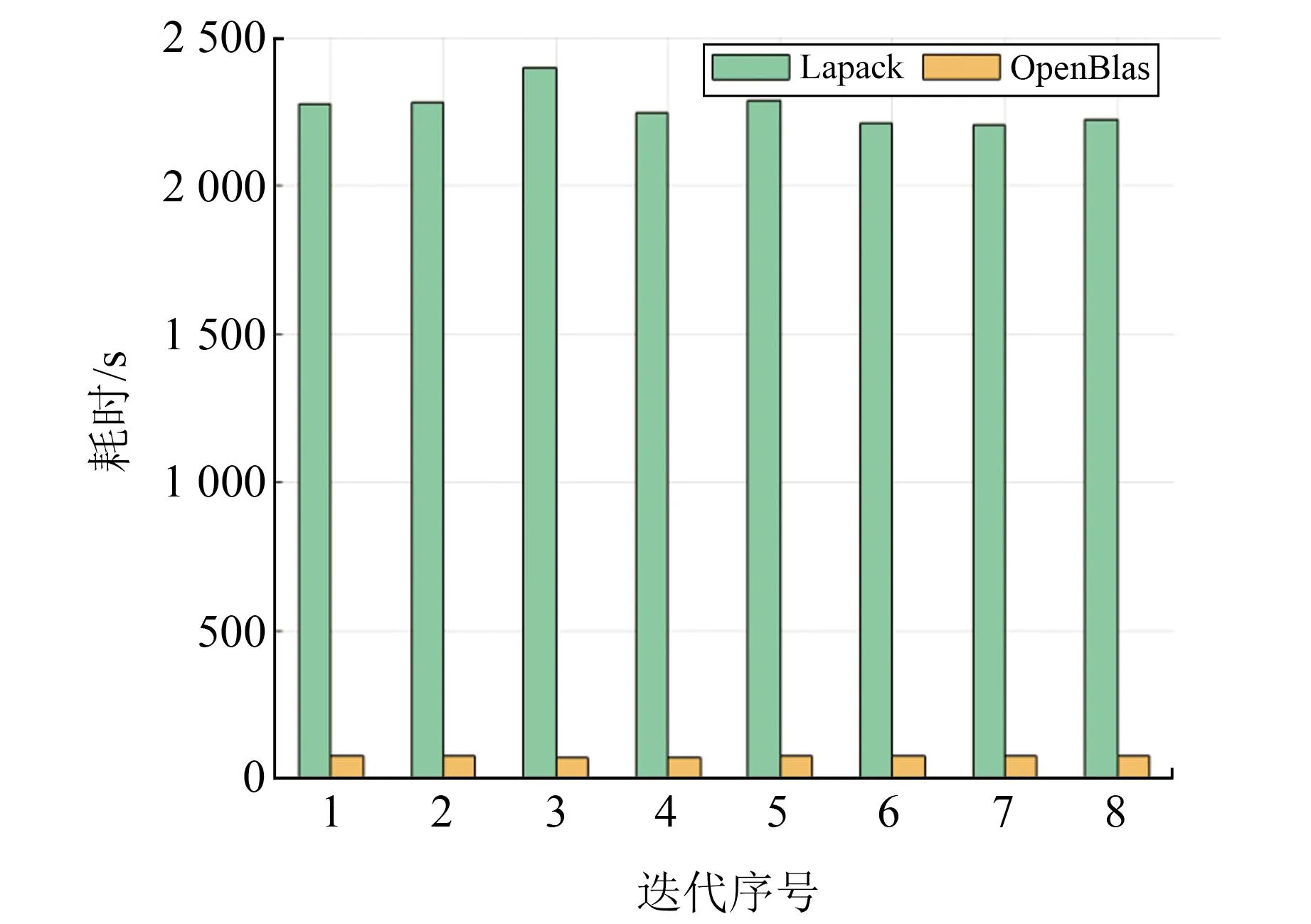
图5 8次迭代法方程求逆耗时对比
表6为本文优化策略下使用ARM CPU和Intel CPU单次定轨的平均迭代时间。由表可知,在ARM CPU上通过上述2种方法优化(ARM+多线程+OpenBlas)的定轨解算效率为表1中原始定轨处理(ARM+Lapack)的6倍左右,并且超过原始软件在Intel CPU(Intel+MKL)上的解算效率。本文优化方法在Intel CPU上也可以提高解算效率,采用MKL(Intel+多线程+MKL)时解算效率还是最高的。ARM CPU上最优解算耗时与Intel CPU上最优解算耗时相比,从原来的5倍缩小到3倍,说明本文方法可以提升ARM CPU的计算效能,提高导航卫星定轨解算效率。

表6 优化后ARM CPU和Intel CPU 单次定轨的平均迭代时间
4 结 语
以国产飞腾CPU为例,讨论在国产ARM架构CPU基础上的导航卫星精密定轨解算效率优化方法。影响导航卫星精密定轨解算效率的最主要因素为钟差参数约化和法方程求逆运算,对前者采用多线程优化方法,对后者采用OpenBlas开源库进行优化。优化后,2个部分的解算效率均大幅提升,且随着所需解算参数的增加,效率提升的倍数不断增加。在100个测站32颗卫星和OpenBlas采用16线程的情况下,针对矩阵乘法同时进行单线程和多线程运算优化的法方程求逆解算时,OpenBlas库的解算效率为Lapack库的29倍,这个优化倍数已突破仅通过多线程优化所能达到的最理想倍数(16倍),说明OpenBlas中单线程矩阵运算优化同样可以大幅提升解算效率。后续研究将进一步根据ARM CPU的架构特点和OpenBlas的原理,针对ARM架构对OpenBlas内部参数进行适配性调整,以进一步提升ARM CPU解算卫星精密轨道的效能。
