基于数据增强的小样本辐射源个体识别方法
2024-04-02王艺卉闫文君段可欣于楷泽
王艺卉,闫文君,段可欣,3,于楷泽,3
(1.海军航空大学,山东烟台 264001;2.31401部队,山东烟台 264001;3.91423部队,山东烟台 264001)
0 引 言
辐射源个体识别(Specific Emitter Identification,SEI)在通信对抗、频谱资源监测与管理、无线电干扰检测与定位、无线电设备管理与维护等领域应用广泛[1],通过准确识别辐射源个体可以锁定恶意信号或入侵个体[2],提高频谱利用率与无线电设备管理的有效性,确保通信系统的干扰冲突最小化。
在现实通信场景中,常常由于信号遮挡、长距离传输、电磁干扰、不良天气影响、信号加密等原因出现样本数据难以获取、捕捉样本类别不全面等样本数目不足的小样本困境。
近年来,小样本问题愈受关注,其问题的解决掣肘于数据量的缺乏。数据增强技术在图像分类、目标检测、自然语言处理等领域应用广泛且表现突出,为小样本困境的解决提供了可能。目前,较为主流的小样本学习方法有基于度量学习、基于模型改进和基于数据增强三种方法[3]。
基于度量学习的方法是通过距离度量样本间的相似性,具有代表性的有构造正样本、负样本和锚点来计算样本对间距离的共享网络参数孪生网络、利用双向长短时记忆的元学习匹配网络、以类别均值为中心的原型网络,其受限于缺乏数据而易受离群样本和错误标注样本的影响。基于模型改进的代表性方法有借助附加的记忆模块保存支持集中提取的特征信息进行学习的记忆增强的神经网络算法[4]、跨任务训练寻优的参数优化方法[5]、引入掩码变换网络使得任务参数具体对应子空间的高维网络参数元学习算法[6]、引入注意力机制和互信信息的权重生成小样本算法[7],显然地,使用附加记忆模块会提高计算成本和内存间的需求,优化模型或参数的方法使得难以平衡识别精度与学习速度。三者之中,数据增强策略更为直接。
数据增强(data augmentation)是一种通过扩充样本数量而直接有效解决样本不足问题的方法。在图像处理时常采用翻转[8-9]、旋转[10]、移位[11]、缩放[12-13]、噪声扰动[14]等实现数据扩充的方法可以借鉴延用到无线电信号领域[15],这些微小的改动虽然没有直接增加特征信息,但使得扩充数据集在特征空间的覆盖范围变大,细微差别的存在使神经网络将其视为不同的样本,是更加有助于分类面的选择和鲁棒性的提高。
基于此,本文提出基于数据增强的小样本辐射源个体识别算法。首先,通过时域翻转、振幅反转、振幅缩放和噪声处理等方法对小样本数据集进行数据集扩充;其次,将噪声序列和类别标签输入生成器进一步生成“以假乱真”的生成样本,提高生成样本的多样性并通过辅助分类器同步完成真假样本判别和类别预测;最后,根据判别器动态反馈渐进式调整损失函数权值,重点关注高质量样本进一步优化网络,提高识别准确性。
1 数据预处理
1.1 数据特点
本文采用ADS-B 1090 MHz S 模式扩展电文数据链进行分析,其最大下行数据长度达112 位,数据率可达1 Mbit∕s。如图1 所示,ADS-B 消息主要由前导脉冲(preamble)部分和数据(data block)部分组成,消息的前导脉冲位置在消息的前端即信号的前8 μs 时间,是信息头部分,总共有4 个脉冲。数据部分共112 位,表征下行链路格式、通信能力、飞机唯一标识符、地表位置、空中位置和速度等信息。

图1 ADS-B 1090ES信息数据块格式及数据位PPM调制
ADS-B 信号采用脉冲位置调制(PPM)实现数据位报文编码后在数据链路中传播,其基带PPM信号为
式中,bm表示第m个二进制符号,p(t)表示一个脉冲宽度为Ts= 0.5 μs的矩形脉冲。
1.2 数据增强
聚焦样本不足的核心问题,借鉴图片分类算法中常用的翻转、平移、拼接等方法对电磁信号进行时域翻转、振幅反转、振幅缩放和噪声扰动实现数据扩充。
1.2.1 时域翻转
由图2可知,时域翻转是将信号的时间轴进行翻转,对于ADS-B 信号这一离散信号S(n)而言,时域翻转可表示为
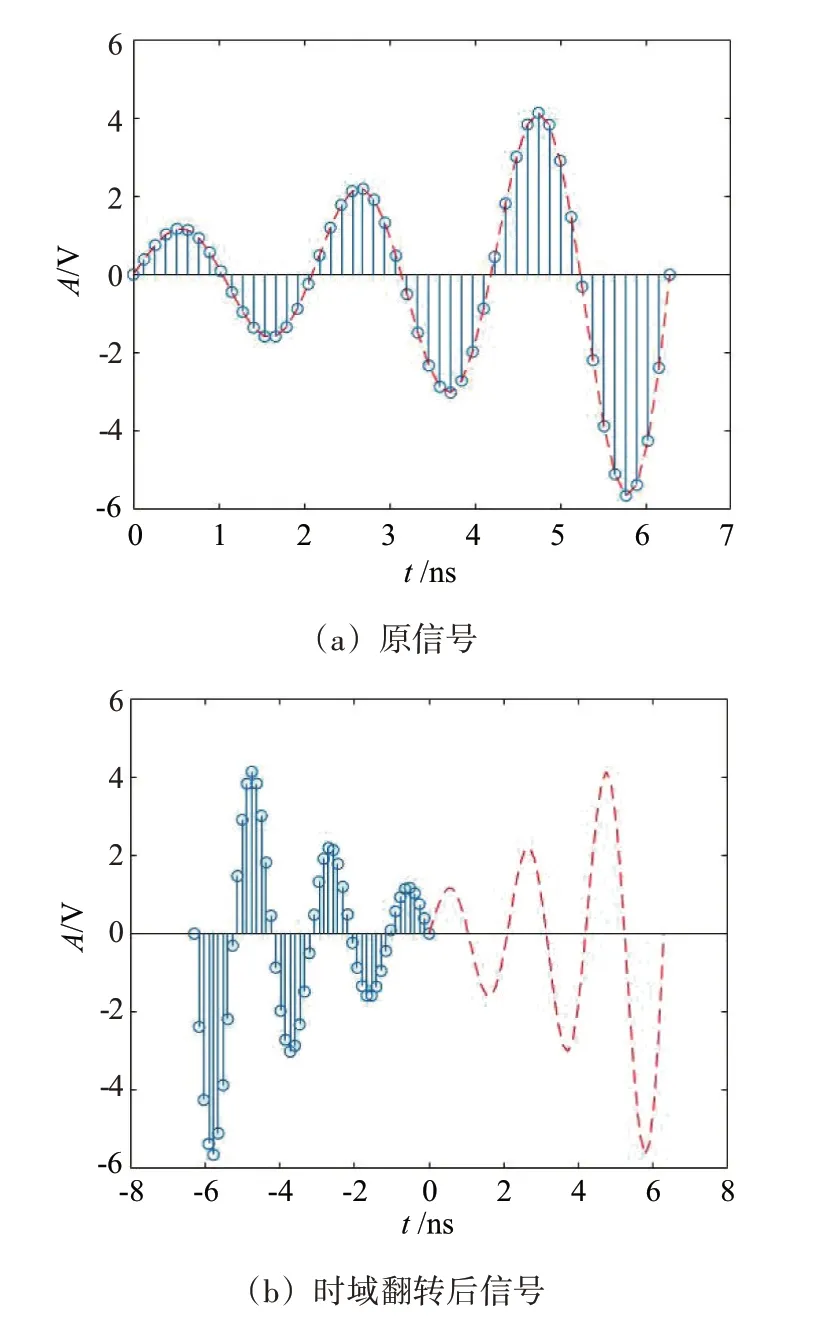
图2 时域翻转处理
式中:N为信号长度;n为时间索引,取值范围为[0,N-1]。
1.2.2 振幅反转
由图3可知,振幅反转是将信号沿时间轴进行反转,对于ADS-B 信号这一离散信号S(n)而言,振幅反转可表示为

图3 振幅反转处理
式中,n为时间索引,Sf(n)为振幅反转后的信号。
1.2.3 振幅缩放
由图4可知,振幅缩放是通过缩放因子调整信号的幅度特征,对于ADS-B 信号这一离散信号S(n)而言,振幅缩放可表示为
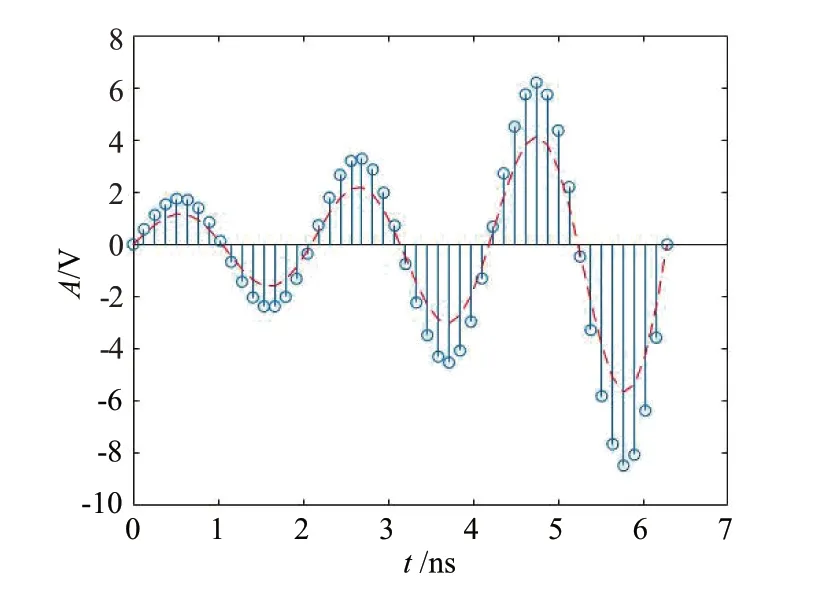
图4 振幅缩放处理
式中,n为时间索引,Ss(n)为振幅缩放后的信号,α为缩放因子。当将超参数α设置为大于1 时振幅增大,小于1 时振幅缩小,但过小或过大的缩放因子会造成信号截断等信号溢出或失真的影响,在后续实验中选取α= 1.4。
1.2.4 加噪处理
对ADS-B 信号这一离散信号S(n)加入高斯噪声可以表示为
式中:n为时间索引,Sn(n)为添加高斯噪声后的信号,N是服从均值为0、方差为σ2的高斯分布的随机数,如图5所示。

图5 加噪处理
2 基于数据增强的辐射源个体识别方法
2.1 辅助分类生成对抗网络
Augustus 等在文献[16]中以GAN 为基础提出了可同时实现样本分类预测和真假样本判别的辅助分类生成对抗网络(Auxiliary Classifier GAN,ACGAN),其损失函数分为判别是否为真实样本的损失LS和分类准确性的损失LC两部分:
式中:x真实样本对应类别标签为yx,z和y为输入生成器的噪声序列和标签,生成样本为G(z,y);x~Pdata(x)表示样本x服从真实样本分布,将样本x判别为真实样本的概率为DS(x),将输入的G(z,y)判别为真实样本的概率为DS(G(z,y)),LD表示为分类损失,故而AC-GAN判别器损失为
生成器损失为
2.2 渐进式权值调整的AC-GAN
AC-GAN 在创造性地实现样本真假判别和分类双重任务的同时,可通过辅助分类器有效控制生成样本的类别,联合生成器损失、判别器损失和分类器损失加强模型训练稳定性,但在实际应用中仍存在以下不足:
1)AC-GAN 在训练数据较少时易引发生成样本多样性不足的问题。
2)AC-GAN 平等地关注判别结果参差不同的样本,限制了模型的识别能力。
基于此,本文提出渐进式动态调整损失函数权重的辅助分类生成对抗网络(PW-ACGAN)的辐射源个体识别算法,合理利用1.2 节中对原始样本进行时域翻转、振幅反转、振幅缩放及噪声扰动等方法产生的扩充样本提高原数据集的特征覆盖情况,使得模型能更好地获得数据的分布,提高生成样本的多样性;根据反馈动态调整损失函数的权重,更加关注将输入的生成样本G(z,y)判别为真实样本和将输入真实样本x判别为假的“颠倒是非”的理想欺骗状态,有效降低低质量生成样本对模型的影响[17-18],具体步骤如下:
1)定义权值调整因子与权重初始化:定义介于0到1之间的权值调整因子γ以控制生成器的损失函数权重,表示生成器损失函数的相对权重。起初,将生成器和鉴别器损失函数的权重设置为相等的值,实现初始权重平衡。
2)关注判别结果动态调整γ:在训练过程中记录生成样本被判别为真实样本(DS(G(z,y)) →1)和真实样本被判别为生成样本(DS(x) →0)的判别概率,在理想情况下,每次判别器输出的概率值为1∕2,即判别器无法区分真实数据和生成数据。
故以1∕2为界,当PDS(G(z,y))→1大于1∕2或PDS(x)→0的判别概率小于1∕2 时,将判别概率与权值调整因子γ比较大小,若判别概率P大于γ则将P赋值给γ,调整并更新损失函数。
PW-ACGAN判别器损失为
PW-ACGAN 生成器损失函数保持不变,判别器损失函数为
3)权值平衡与稳定:过度重视生成样本的逼真程度会降低生成样本的多样性,过强的生成器会造成模型崩溃,过强的判别器会引起梯度消失。通过以1∕2 为界,γ= max(γ,P)将权值调整因子限制在0.5 至1 之间,保持生成样本多样性与逼真性的平衡。
2.3 实现步骤
如图6所示,信号样本经过数据增强处理后形成扩充数据集,按设置比例划分成训练集和测试集,随机抽取m个训练样本x;在PW-ACGAN 中,随机生成m个满足正态分布的噪声序列z和生成样本标签y经过生成器G输出生成样本G(z,y)。将样本x和G(z,y)一同送入判别器D 判别,并通过反向传播调整优化生成器与判别器。

图6 PW-ACGAN整体结构
3 仿真实验
3.1 仿真条件
3.1.1 数据采集及数据集设置
为采集ADS-B 信号架设工作频率设置为20 MHz,采样频率2 MHz, 接收增益为80 的USRPB210 作为信号接收装置采集1 090 MHz ADS-B S模式响应信号,信号采集过程如图7所示。在航班密集程度不同的时间段和地点采集ADS-B 射频信号并进行抗混叠滤波和步进增益,将信号解调至中频,经转换与解码处理后得到ADS-B 报文,其中部分ADS-B信号如图8所示。

图7 数据采集场景

图8 部分ADS-B采集信号
为分析类别数目与样本数目对识别结果的影响,现设置多个数据集,其中训练集与测试集比为3∶1。DATA 设置类别数量为8,单类别样本数为32,时域翻转和振幅反转根据真实样本最多只能1∶1 生成,故而依1.2 节中数据增强方法扩充数据集时,人为将扩充样本比例设定为1倍。
3.1.2 实验设置
实验基于TensorFlow 的keras框架网络模型的设计与训练过程采用Pycharm 软件完成,硬件配置为Intel(R)Core(TM)i9-9900K CPU,运行内存16 GB,主频3.6 GHz。输入判别器数据尺寸统一为1×1 000 格式,模型训练过程采用Adam 优化器进行权值优化,每次迭代样本数为32,训练次数设置为30,学习率为0.01。
3.1.3 网络模型搭建
深度卷积生成对抗网络(Deep Convolution GAN,DCGAN)的提出创造性地将卷积神经网络引入了生成对抗网络[19],优化了模型的生成质量和稳定性。PW-ACGAN 以DCGAN 网络结构为基础,生成器和判别器网络模型设计如表1和表2所示。

表2 PW-ACGAN判别器网络模型
3.2 实验结果分析
3.2.1 不同数据增强方法对识别效果的影响
为验证不同增强方法对识别效果的影响,选用与PW-ACGAN 的判别器结构相同但去除输出层判别概率分支的CNN 网络模型为识别网络。不同的增强方法在训练样本时取8 种类型的信号样本各32 个,分别将未经增强的原始样本记为None、Time domain flipping、Amplitude reversal、Gaussian noise 与组合使用增强方法的混合增强样本Mix 在不同信噪比条件下进行识别效果比较。
由图9可知,不同增强方法的识别准确率在不同信噪比条件下均有不同程度的提高,在信噪比较低的情况下,识别准确率稳步提升,在达到8 dB时识别准确率趋于稳定;单一增强方法中时域翻转的增强方法表现最佳,加噪处理的增强方法表现最为逊色,振幅缩放增强方法的识别准确率稍微优于振幅反转;而混合增强方法优于单一增强方法,为优化实验效果后续实验采用混合增强方法产生增强样本。
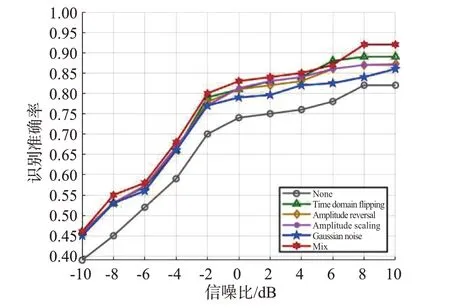
图9 不同增强方法的识别准确率比较
3.2.2 小样本条件下识别效果分析
为对比CNN、ACGAN 及PW-ACGAN 在小样本条件下的识别效果,在SNR=2 dB 条件下对混合增强样本Mix 进行20 次蒙特卡罗实验并记录识别准确率,绘制盒子图可知其最大最小值、上下四分位数和中位数及分布情况。
由图10 可知,以图中红色横线标注的中位线为标准,PW-ACGAN 的识别准确率明显优于CNN和ACGAN 算法;PW-ACGAN 的识别准确率分布最为集中,表明其平衡了生成样本的稳定性与多样性,更好地突破了训练集数目少易引发的测试集易过拟合的小样本限制,进一步证明了PW-ACGAN算法的有效性。
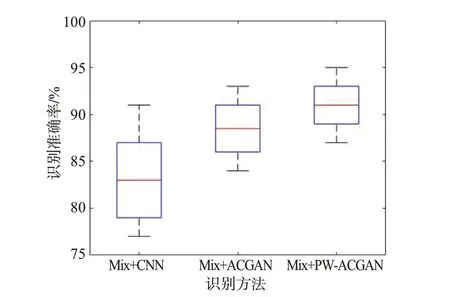
图10 不同识别方法的识别准确率
3.2.3 不同识别方法比较
为进一步说明本文算法在小样本辐射源个体识别中的优势,采用通过对比实验进行分析。其中,Augmented data with screening 是以文献[20]中基于粗细粒度筛选的生成对抗网络数据增强方法;Meta Learning 是以文献[21]中基于元学习的跨任务信号识别方法;LDCGAN+SVM 是以文献[22]中基于深度卷积生成对抗网络扩充样本后利用支持向量机进行分类识别方法。
由图11 可知,本文所提识别算法在不同的信噪比条件下均优于其他三种对比算法,尤其在-10~-2 dB 低信噪比条件下,不同识别算法的识别效果差异显著,本文所提基于混合数据增强和PW-ACGAN 较将LDCGAN 生成数据映射到高维特征空间利用支持向量机分类识别的方法提高了15%左右,表明本文算法对低信噪比环境有较好的适应性。

图11 不同算法的识别准确率
3.2.4 样本数量对识别效果的影响
小样本学习旨在解决样本不充足、不全面的条件限制问题,但训练样本数量仍在一定程度上影响识别结果。首先在信噪比为8的条件下,设置不同的每个类别样本数量进行识别准确率比较,查看数据增强在不同数量的小样本条件下的作用效果。由图12 横向对比可知,随着每个类别样本数目的增加,识别准确率明显提升,表明充足的训练样本对模型的拟合能力至关重要;纵向来看,在样本数目较少的情况下,数据增强通过扩充样本数量提高样本的特征覆盖率,更好地使模型学习数据特征,从而实现了小样本条件下识别准确率的跃升,但当样本数量较为充足并能够支撑分类器获得较好的分类面时,数据增强的作用效果微弱。
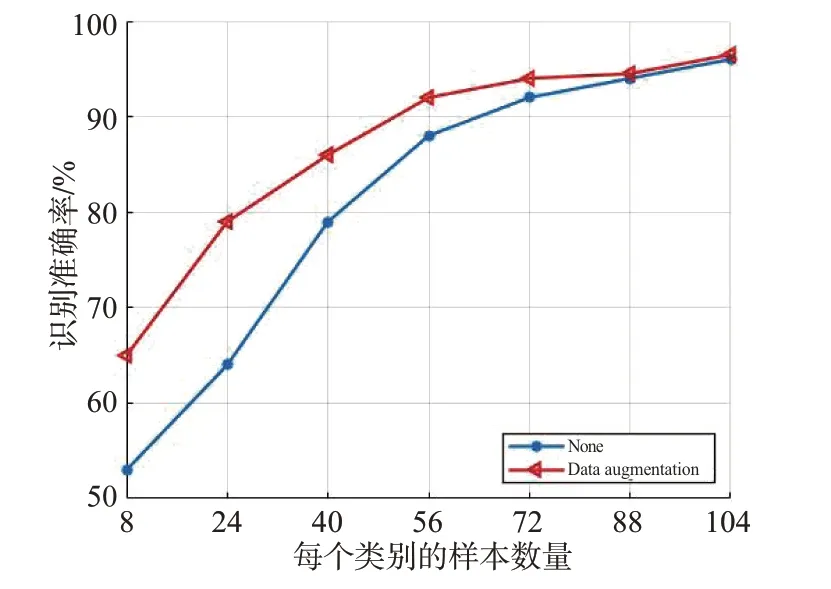
图12 不同数量样本的识别准确率
为进一步验证小样本条件下增强样本数量对识别准确率的影响,取不同数量的增强样本进行多次实验,取平均识别准确率进行比较。由表3可知,随着增强样本数量的增加,识别准确率稳步提升,当达到增强样本数量与原始样本一致时,识别准确率提升近23%。

表3 各类增强样本在不同数量下的识别准确率
4 结束语
针对复杂电磁环境中缺少高质量、数量充足训练样本的困境,提出基于数据增强的小样本辐射源个体识别方法。首先,通过数据增强扩充样本集,提高原数据集的特征覆盖情况,使得模型能更好地获得数据的分布;然后,将噪声序列和类别标签输入生成器进一步生成“以假乱真”的生成样本,提高生成样本的多样性并通过辅助分类器同步完成真假样本判别和类别预测;最后,根据判别器动态反馈渐进式调整损失函数权值,重点关注高质量样本进一步优化网络,提高识别准确性。实验结果表明,本文算法在不同数量样本下和不同信噪比条件下均表现出较为稳定的识别能力,尤其对低信噪比条件具有较好的适应性,为复杂信道条件下的小样本辐射源个体识别提供了可能。
