基于逆强化学习与行为树的机械臂复杂操作技能学习方法
2024-04-02宋越杰马陈昊孟子晗刘元归
宋越杰,马陈昊,孟子晗,刘元归
(南京邮电大学自动化学院人工智能学院,江苏南京 210023)
0 引 言
社会老龄化的加剧与各种意外事故的发生,导致老残人群数量日益增加,不同程度的肢体残障对老残人群的日常生活产生了较大影响。为在一定程度上解决上述问题,除了提供社会支持和无障碍环境外,助老助残辅助设备的开发也非常重要。随着机器人技术的发展,机器人在改善或替代受损肢体功能方面的研究,近年来取得了较多有影响力的成果[1],特别是伴随人工智能技术的引入,机器人在辅助老残人群日常生活活动操作方面,尤其是在机械臂学习人类的日常生活活动操作技能方面,国内外研究非常深入并取得了较好的进展[2]。
在机械臂学习人类的日常生活活动操作技能方面,针对较为简单的操作任务,可以分为模仿学习与强化学习两种不同类型的机器学习方法。模仿学习是一种监督学习方法,它通过观察和模仿专家的行为来获取人类操作技能的仿生学习方式[3],具体又可分为轨迹编码、动态系统及策略过程三种不同类型。在轨迹编码模仿学习方面,文献[4]运用基于参数化的高斯混合模型学习了人机协作搬运与装配操作技能,文献[5]基于Baxter 协作机器人平台并运用隐半马尔科夫模型学习了人类的穿衣技能。动态运动基元作为动态系统模仿学习方法的典型代表,在机器人辅助操作技能学习方面也得到了较好的应用。文献[6]通过融合动态运动基元与概率运动基元两类不同的动态系统模仿学习方法,构建了概率动态运动基元学习框架,并在机器人辅助日常生活拾取操作中进行了较好的验证。针对策略过程模仿学习方法,文献[7]为提高技能的泛化性能,运用逆强化学习方法学习了变阻抗控制参数及奖励函数,并通过机器人辅助插孔和杯盘放置实验验证了算法的有效性。同模仿学习不同的是,强化学习是通过智能体与环境的交互试错来学习最优策略的一种方法。文献[8]运用基于近端策略优化的强化学习算法,通过设计连续奖励函数,学习了双臂机器人从床上扶起患者的操作技能轨迹。文献[9]为在一定程度上解决深度强化学习在机器人本体上的部署问题,通过联合深度P 网络及对决深度P 网络,以减少样本数量并提高样本学习效率与稳定性。
上述单纯基于模仿学习与强化学习的机器人辅助操作技能,在相对较为简单的操作任务场景中具有较好的效果,但是面对复杂多阶段的操作任务仍存在一定的欠缺。为解决上述问题,基于分层学习的机器人操作技能学习框架日益受到关注。文献[10]针对复杂多阶段的机器人辅助电缆布线任务,提出了一种分层模仿学习框架,其中底层采用行为克隆学习单个夹子布线操作技能,上层采用深度网络学习不同布线阶段的执行顺序,二者结合较好地完成了整个布线任务。作者所在课题组前期提出了一种基于分层强化学习的机械臂复杂操作技能学习方法,底层运用SAC(Soft Actor Critic)算法学习子任务操作技能,根据底层得到的子任务最优策略,上层进一步通过改进的最大熵目标强化学习算法学习子任务执行顺序[11]。文献[12]提出了一种基于层次强化学习的机械臂手内鲁棒控制方法,通过定义底层操作基元并结合中层深度强化学习网络,实现了物体位姿及手指接触点位置发生改变情况下的机器人操作方法,三指机械手的仿真实验验证了所提方法的有效性。
上述分层强化学习方法虽取得了一定的效果,但在实际应用中,一方面,底层子任务学习存在样本效率低、奖励稀疏等问题,上层任务规划学习面临学习时间过长甚至难以完全学会整个复杂任务的问题;另一方面,由于仿真与真实环境之间存在差异,导致仿真环境迁移到真实环境后的策略可能会失效。针对上述问题,本文提出了一种基于逆强化学习与行为树的机械臂复杂操作技能学习框架,其中,逆强化学习用于学习底层子任务最优策略,然后将具有最优策略的子任务作为节点,在上层构建行为树来实现不同子任务间的任务规划,进而实现机械臂复杂操作技能的学习与再现。
1 方 法
1.1 基于逆强化学习和行为树的机械臂复杂操作技能学习系统
为了解决分层强化学习算法底层子任务学习存在的样本效率低、奖励稀疏等问题,上层任务规划学习面临学习时间过长甚至难以完全学会整个复杂任务的问题,本文提出了基于逆强化学习和行为树的机械臂复杂操作技能学习框架。
本文提出的基于逆强化学习和行为树的机械臂复杂操作技能学习系统框图如图1 所示。该系统框图分为底层子任务学习和上层复杂任务规划,其中底层子任务学习主要包括复杂任务分割模块、RL 参数设计模块、逆强化学习模块;上层任务规划主要包括真实环境部署模块和行为树构建模块。主要实现方案为:通过仿真环境构建模块建立相应的仿真环境,并进行复杂操作任务演示,得到复杂任务演示轨迹;接着通过复杂任务分割模块进行分割,并确定分割后每个子任务的RL 参数,得到子任务专家策略集合;然后通过逆强化学习模块获取每个子任务的最优策略,并部署到真实环境中;最后通过行为树构建模块构建行为树,得到整体最优策略,在真实环境中执行复杂操作任务。
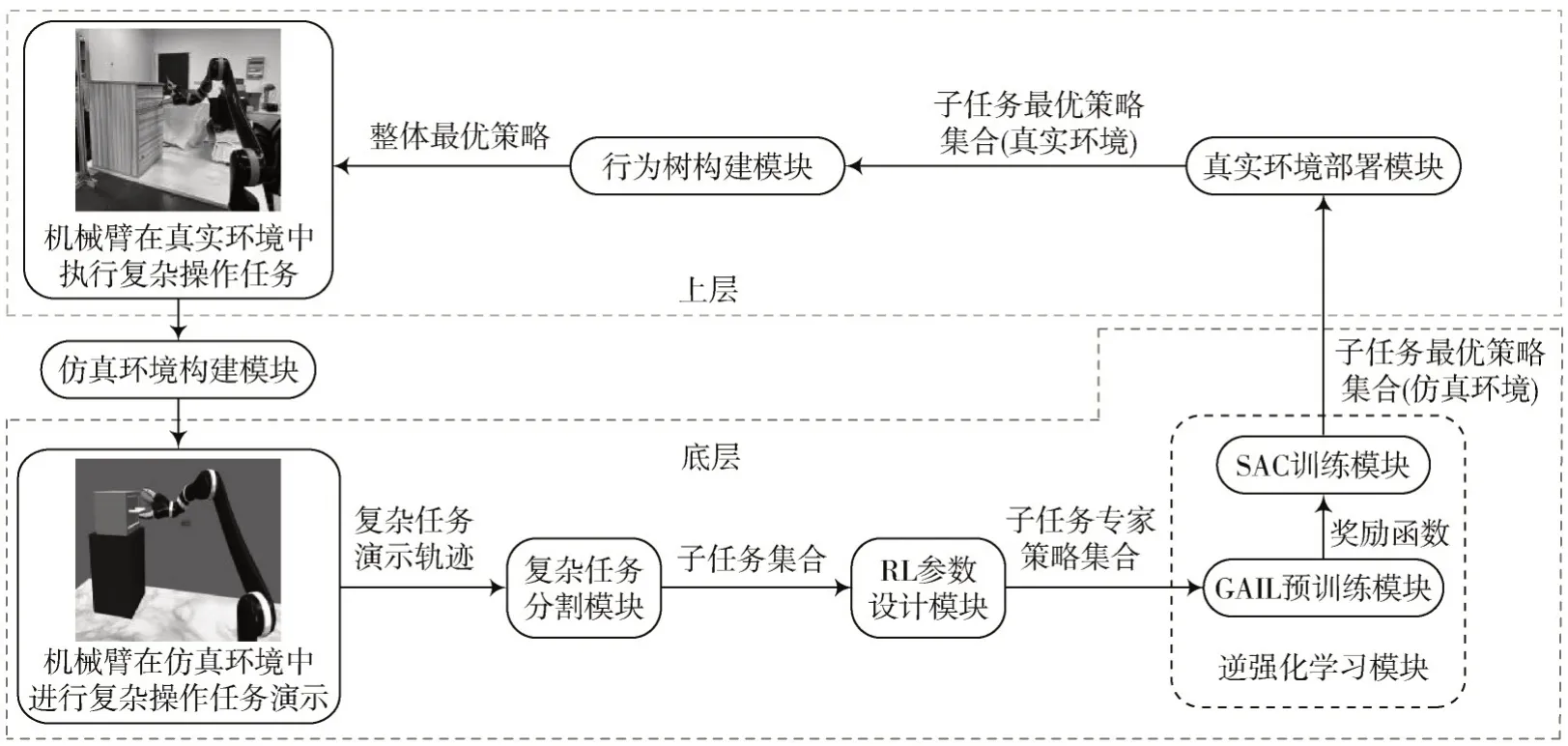
图1 基于逆强化学习和行为树的机械臂复杂操作技能学习系统框图
1.2 基于GAIL 和SAC 的底层子任务学习方法
本文使用文献[11]所在课题组分割复杂任务的方法,采用基于β过程的自回归隐马尔科夫模型分割复杂任务,并且设计了底层子任务的学习方法。
1.2.1 底层子任务学习框架
逆强化学习是利用有限的专家样本推断奖励函数,并根据该奖励函数寻找最优策略的一种方法。本文采用生成对抗模仿学习[13]从专家演示轨迹中学习到子任务的奖励函数,在此基础上进一步根据奖励函数并通过SAC算法寻找到子任务最优策略,其算法框图如图2 所示。
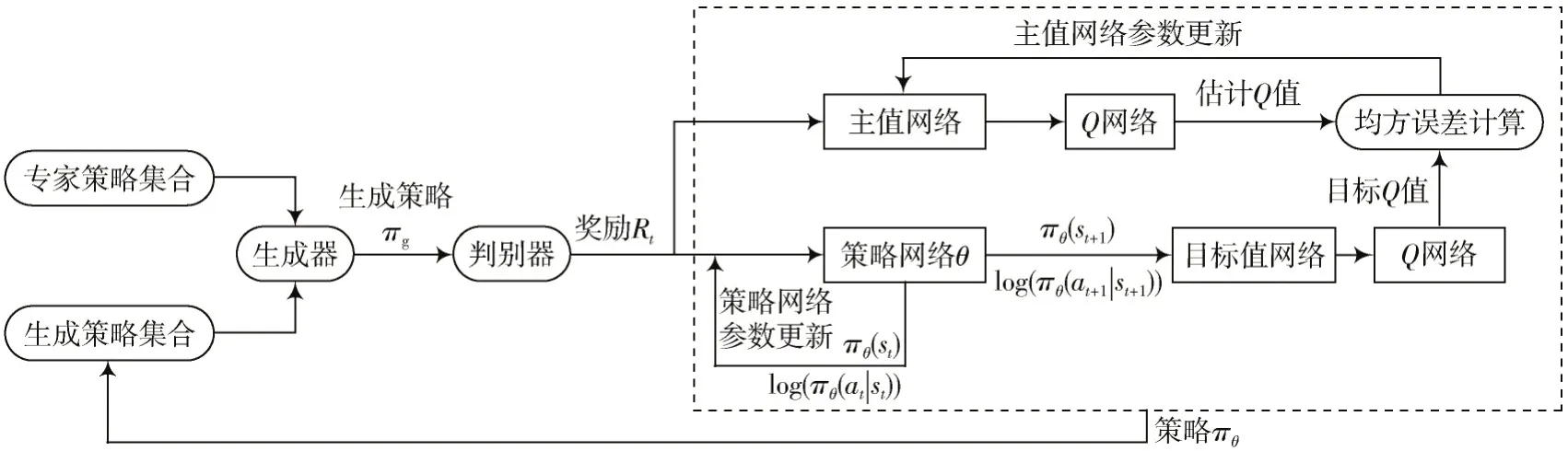
图2 GAIL+SAC 算法框图
生成对抗模仿学习主要由生成器和判别器两个部分组成。生成器根据专家策略产生生成策略,力求使判别器无法分辨其与专家策略的差异;而判别器则旨在辨别生成器产生的生成策略是否是专家策略。生成器和判别器相互博弈,通过不断对抗,最终训练出一个优越的奖励函数和策略网络。
在得到奖励函数和策略网络后,使用SAC 算法进行训练,通过GAIL 得到奖励函数和生成策略,SAC 算法不再从头开始训练策略,而是在有限的专家经验基础上,更高效地训练出适应性强、性能优越的子任务智能体。
1.2.2 底层子任务学习方法
底层子任务通过GAIL+SAC 框架来学习得到子任务最优策略。
GAIL 包括生成器和判别器的网络结构。首先为生成器提供少量的专家策略,记为πE,记生成器网络输入为子任务专家策略集合πE中的状态动作对(s,a),输出为生成器模仿子任务专家策略生成的子任务生成策略πg,记为策略Gw(s,a),生成器的损失函数LG为:
式中:Eπg表示期望值;DΦ(Gw(s,a) )表示判别器D 判断策略,DΦ(Gw(s,a) )= sigmoid(Gw(s,a)),其中sigmoid 是一种激活函数,Gw(s,a)是专家轨迹的概率。
通过添加熵来鼓励生成器生成多变的轨迹,熵损失LE为:
式中:σ为熵损失系数;softplus 是一种激活函数。
判别器的输入为Gw(s,a),输出为DΦ(Gw(s,a) ),判别器的损失函数LD为:
因此,生成对抗模仿学习模型的总损失函数为:Ltotal=LG+LE+LD。
通过训练好的判别器D 的输出作为奖励函数训练模仿者策略,所述奖励函数R(s,a)为:
式中:β表示熵损失权重;DΦ(Gw(s,a) )表示判别器D 判断策略Gw(s,a)是专家轨迹的概率。
通过GAIL 预训练得到奖励函数和策略网络后,将其引入到SAC 算法进行正式训练。
SAC 算法的过程是:
1)从经验池中采样当前时刻的状态st、动作at、奖励r、下一时刻的状态st+1后,送入策略网络,输出下一时刻的策略πθ(st+1)和熵log (πθ(at|st)),同时更新策略网络参数,更新公式如下:
其中:
2)将经验池中当前时刻的状态st、动作at、奖励r输出至主值网络,通过主值网络中的两个Q网络Net1 和Net2 来计算估计Q值Qt(ϕ1)、Qt(ϕ2)。
3)将策略网络输出的策略和熵通过目标值网络中的两个Q网络Net1 和Net2 来计算目标Q值,并输出两个目标Q值中的较小值,与主值网络计算的估计Q值作均方误差计算,其目标函数如下:
同时目标值网络参数通过主值网络参数进行软更新,更新方式如下:
4)主值网络的参数更新方式如下:
1.3 基于行为树的上层子任务规划方法
1.3.1 真实环境部署
现有强化学习方法大多采用先在仿真环境中进行训练,再部署到真实环境中的方法,但由于仿真环境和真实环境存在一定的误差,比如建模差异、环境差异、姿态差异等,导致在部署过程中会产生策略失效的问题。
在本文的实验中,仿真环境与真实环境的差距主要为机械臂末端的姿态差距。为了弥补姿态差距,首先将真实环境中的机械臂置于初始位姿,获取此时机械臂每个关节的旋转角度JR1、JR2、JR3、JR4、JR5、JR6以及真实环境中机械臂末端位置xR、yR、zR和姿态的四元数dxR、dyR、dzR、dwR;接着将姿态四元数dxR、dyR、dzR、dwR转换为欧拉角XR、YR、ZR,在仿真环境中机械臂每个关节的旋转角度JS1、JS2、JS3、JS4、JS5、JS6置为JR1、JR2、JR3、JR4、JR5、JR6,并获取此时仿真环境中机械臂的欧拉角XS、YS、ZS;最后求出仿真环境与真实环境中机械臂的姿态差ΔX=XR-XS、ΔY=YR-YS、ΔZ=ZR-ZS。
1.3.2 基于行为树的上层子任务规划
行为树是一种用于描述和控制智能体行为的图形化模型。它是一种树形结构,其中每个节点代表一种行为或控制逻辑,主要包括控制节点、装饰器节点、条件节点、动作节点等。
行为树的节点构建如图3 所示。子任务的行为树执行由一个带记忆功能的顺序节点来确定执行顺序,该顺序节点的子节点包括一个条件节点和一个动作节点。其中条件节点根据当前环境状态和任务目标判断是否满足执行子策略的前提条件,如果满足执行条件,则向顺序节点返回成功,顺序节点继续执行;如果不满足执行条件,则返回失败,顺序节点向其父节点返回失败,直接结束当前回合。动作节点根据当前环境的状态执行强化学习子策略,并接收实时奖励,如果实时奖励大于任务成功奖励,则向顺序节点返回成功,顺序节点继续执行下一个子任务;如果在一定时间后未达到成功奖励,则向顺序节点返回失败,顺序节点向其父节点返回失败,直接结束当前回合。
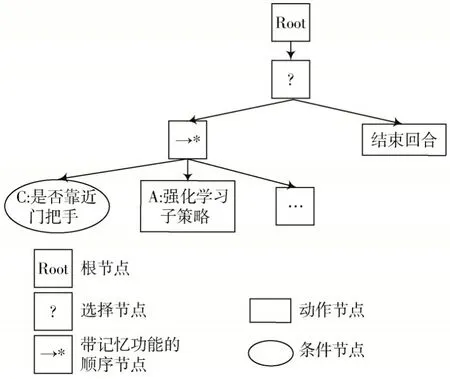
图3 行为树节点构建
2 实验与仿真
2.1 实验任务设计
本实验的仿真环境通过物理仿真引擎MuJoCo 对基于逆强化学习和行为树的机械臂复杂操作技能学习进行验证,所使用的是Kinova Jaco2 机械臂,型号为j2n6s300;真实环境通过rviz 可视化机械臂操作,并通过行为树来控制机械臂。
为了充分考虑家庭环境中任务的多样性和复杂性,同时考虑到老年人日常需求,本文将拉开抽屉拿取药瓶作为实验任务。
首先建立拉开抽屉拿取药瓶的实验场景,如图4所示。
接着执行拉开抽屉拿取药瓶的实验任务,记录下机械臂末端的轨迹,0 即机械臂末端的位置和姿态。然后采用基于β过程的自回归隐马尔科夫模型对所采集的演示数据进行分割,分割结果如图5 所示。

图5 机械臂复杂操作任务分割结果
图5 为位置和四元数随时间变化的曲线图,不同颜色的区间表示基于β过程的自回归隐马尔科夫模型算法分割得到的不同任务区间。根据四元数可以看出分割出了4 段具有明显物理意义的分段,分别为抓取抽屉把手(分段①)、拉开抽屉(分段②)、抓取物体(分段⑥)、放置物体(分段⑨)。
最后为所有分割的子任务建立仿真训练环境,图6为4个子任务的训练环境。图6a)为抓取抽屉把手,任务目标为机械臂末端抓取抽屉把手;图6b)为拉开抽屉,任务目标为机械臂末端将抽屉把手拉至目标点;图6c)为抓取物体,任务目标为机械臂抓取抽屉中的物体;图6d)为放置物体,任务目标为将物体放置到蓝色小球处。
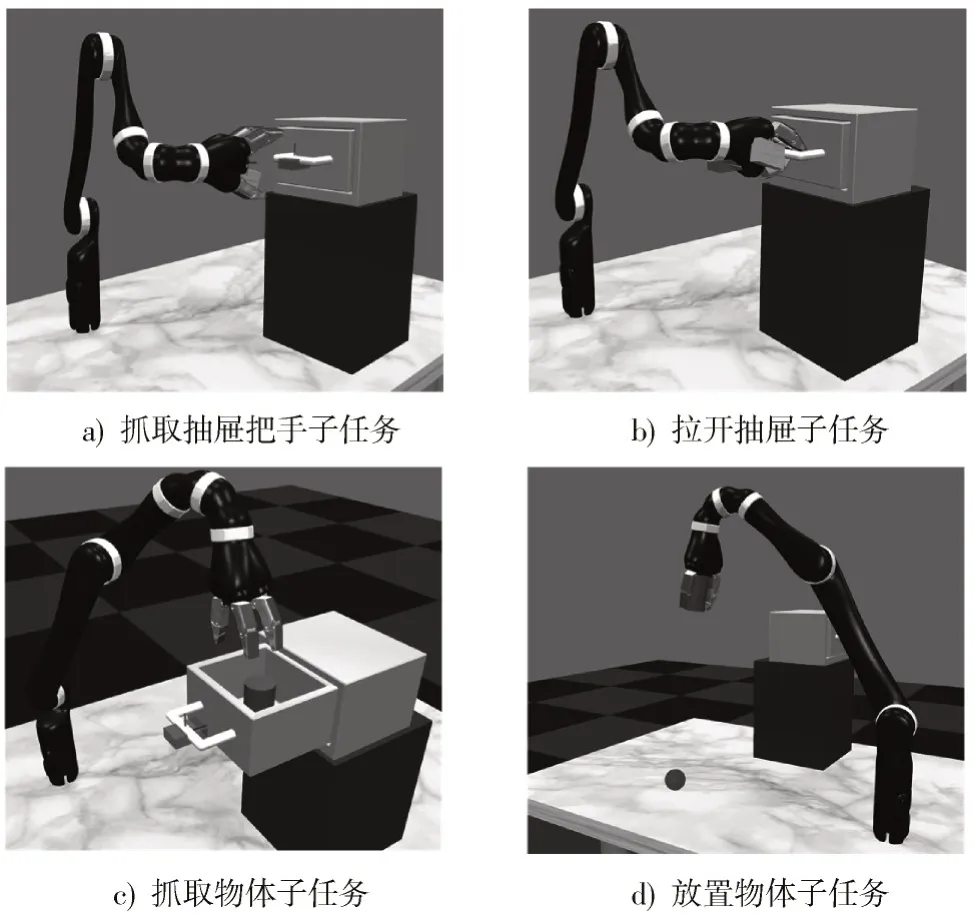
图6 子任务仿真训练环境
在所有子任务的仿真环境都建立好后,接下来进行实验参数设置。
2.2 实验参数设置
2.2.1 子任务专家策略的RL 参数设置
每个子任务的专家策略包括:机械臂当前时刻t的状态空间St、当前时刻t的动作空间At、下一时刻t+ 1 的状态空间St+1、当前时刻t的实时奖励Rt、一个回合结束的最终奖励Repisode和一个回合开始的标志位Estart。其中状态空间为所有子任务状态空间的并集,包括机械臂夹持器1 维、机械臂位置3 维、机械臂姿态3 维、药瓶位置3 维、抽屉把手位置3 维、药瓶放置位置3 维、药瓶放置姿态3 维、目标点位置3 维、目标点姿态3 维,总计25 维;所有子任务的动作空间都是7 维,其中前6 维表示机械臂末端的位置和姿态,第7 维表示末端夹持器开合程度;实时奖励Rt为机械臂在状态St时的奖励函数;最终奖励Repisode为回合结束后机械臂得到的奖励;标志位Estart在开始时为1,表示回合开始,其余时刻均为0。
2.2.2 GAIL 与SAC 网络参数设计
在GAIL 算法的网络结构中,预训练的总时间步total_timestep 设为100 万,学习率learning_rate 设为7×10-9,预训练的迭代次数n_epochs 设为10 000,验证间隔interval 设置为100,每个epoch 中训练策略的步数g_step设为3,每个epoch 中训练鉴别器的步数d_step 设为3,奖励分配器步长d_stepsize 设为0.000 3,生成器熵损失系数σ设为0.001,判别器输出奖励函数的熵损失权重β设为10-8。
在SAC算法的网络结构中,每个网络层之间的激活函数采用ReLU函数,经验池大小buffer_size设置为16 384,每次训练从经验池中采样样本数量batch_size 设为256,学习率learning_rate 为7×10-5,折扣因子gamma 为0.99,Actor网络和Critic网络均采用Adam 优化器进行优化。
2.3 实验结果
2.3.1 底层子任务训练结果
底层子任务的训练过程中采用GAIL+SAC 算法对子策略进行训练,并将其与仅采用SAC 算法的训练进行对比,对比结果展示在图7 中。

图7 底层子任务训练结果
观察到GAIL+SAC 方法所需的时间步远远少于仅采用SAC 方法的情况。在放置物体任务的过程中,由于庞大的状态空间,SAC 算法训练的模型甚至出现了局部最优的情况。
接着对每个子任务的最优策略在仿真环境中进行25 次测试,测试结果见表1。研究表明,采用GAIL+SAC 算法的成功率明显高于仅采用SAC 算法的情况。

表1 子任务最优策略在仿真环境中的成功率 %
2.3.2 上层复杂任务执行结果
基于复杂任务的执行逻辑,构建了如图8 所示的行为树。其中行为树的叶子节点为已完成真实环境部署的强化学习子策略,在执行前需要判断是否满足条件,如果满足就执行子策略,如果没有满足条件,直接结束当前回合。
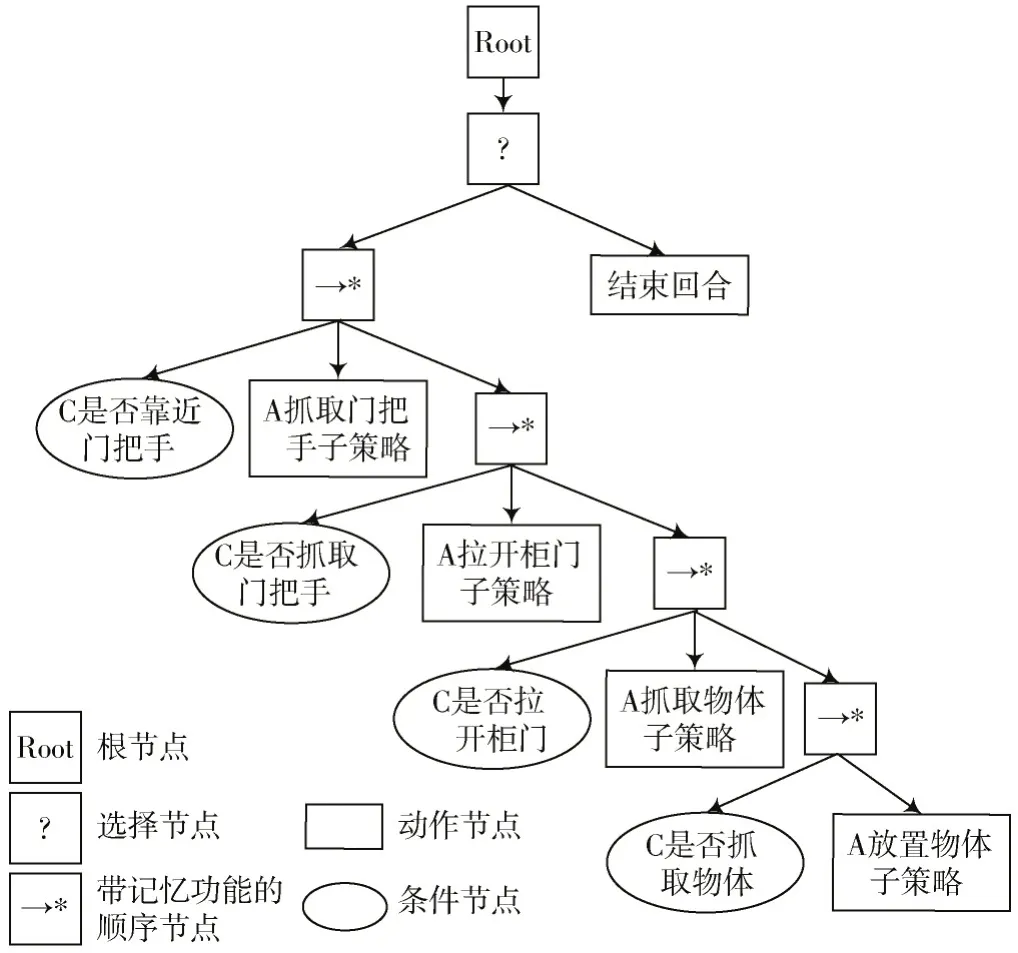
图8 基于行为树的子任务规划
为与传统强化学习算法进行对比,根据所构建的行为树,分别采用传统SAC 算法和本文所提出的GAIL+SAC 算法,进行了真实环境中的机械臂复杂操作技能对比实验,结果分别如图9 和图10 所示,在25 次测试实验中,传统SAC 算法的成功率为28%,GAIL+SAC 在真实环境中成功率为76%。由于传统SAC 算法在仿真环境中放置物体子策略的成功率较低,导致整体任务的成功率偏低。而本文提出的算法在仿真环境中成功率较高,但由于并不能完全消除仿真环境和真实环境的差距,在真实环境中的成功率有所降低。

图9 真实环境中基于SAC 的机械臂复杂操作技能再现

图10 真实环境中基于GAIL+SAC 的机械臂复杂操作技能再现
以上实验结果表明,基于逆强化学习和行为树的复杂操作技能学习方法成功完成了从仿真环境到真实环境的部署,并且在真实场景中的成功率高于传统强化学习算法。
3 结 语
本文提出一种基于逆强化学习和行为树的机械臂复杂操作技能学习方法,用于解决传统分层强化学习方法底层子任务样本效率低、奖励稀疏,上层学习时间过长,以及策略在真实环境中部署困难的问题。该方法底层采用逆强化算法学习子策略,保证了子任务的学习效率;上层通过行为树来规划子任务,构建整体策略。实验结果表明,该方法成功学习到了复杂操作任务,大大减少了训练的时间,并在性能上优于其他算法。
