基于单视图的带纹理三维人体网格参数化重建
2024-03-31洪沛霖檀结庆
邢 燕, 徐 冬, 洪沛霖, 檀结庆
(1.合肥工业大学 数学学院,安徽 合肥 230601; 2.安徽中医药大学 医药信息工程学院,安徽 合肥 230012)
0 引 言
三维建模在动画、服装设计、游戏、虚拟现实等领域有着广泛的应用。传统上,基于优化的方法[1-2]为由图像恢复姿态和形状提供了可行的解决方案,然而运行时间慢、依赖良好初始化、不正确的局部最小值会导致不精确、不稳定、鲁棒性差等。最近的研究重点转移到基于学习的方法上,研究用体素、点云、网格、隐式函数等表示重建三维对象的方法。由于从单幅二维图像获取三维形状的歧义性和关节动物的复杂性,从单幅二维图像重建三维人体模型是一个巨大的挑战。
三维人体重建可以分为参数化重建和非参数化重建2种方法。传统的非参数化方法一般需要借助激光扫描仪、深度相机等特殊的数据收集设备,而且容易受到噪声的影响。文献[3]使用深度相机从Kinect传感器获得的数据中恢复出三维人体;文献[4]根据2台Kinect传感器同时扫描获得的数据,提出一种基于全局配准的三维人体重建方法。深度神经网络的出现为三维人体重建提供了新的思路。一般对网格顶点直接变形,虽然重建的人体具有个性化和灵活性,但顶点变形不受约束,会出现变形异常、不符合人体测量学的情况,例如出现人体上不可能的关节角度或极瘦的身体等不合理现象。文献[5]使用基于图像的卷积神经网络,通过一系列的图卷积层对变形网格的三维顶点坐标进行回归;文献[6]通过在图卷积神经网络的损失函数中引入拉普拉斯先验和部分分割损失实现三维人体重建。
参数化人体重建方法仅需1组低维向量参数即可描述人体形状,其中常见的人体参数化模型有智能分类器和姿态估计(smart classifier and pose estimator,SCAPE)模型[7]和蒙皮多人线性(skinned multi-person linear,SMPL)模型[8]。文献[9]使用SMPL参数化人体模型,在网络中使用基于距离场的碰撞损失和深度排序感知损失估计三维人体姿态和形状;文献[10]提出一种采用SMPL模型的多级拓扑构建的图卷积神经网络重建三维着装人体;文献[11]以人体的二值化图像为输入,以人体形状参数误差、正/侧面轮廓误差为损失函数实现三维人体重建;文献[12]采用深度神经网络作为编码器、SMPL模型作为解码器,提出去噪自编码器模块,从结构误差中恢复人体。
文献[1-2]采用多阶段方法恢复三维人体网格:首先估计二维关节位置,然后根据这些信息估计三维模型参数。这种分阶段的方法通常不是最优的,本文提出一个端到端的解决方案,直接学习从图像像素到人体模型参数的映射。
文献[13]提出生成对抗网络(generative adversarial network,GAN),GAN在医学、自动驾驶、地理、图像处理等领域取得了令人瞩目的成就;文献[14]使用判别器鉴别生成的渲染图像和真实输入图像,重建鸟、牛、摩托车等对象;文献[15]使用判别器判断人体形状和姿势参数是否与真值相同,重建三维人体。这些研究都给本文提供了新的思路。本文采用GAN鉴别器作为弱监督,判断图像是来自真实输入图像还是渲染图像,从而使重建的纹理效果更加精确。
本文的主要工作如下:
1) 提出一个端到端的框架,与多阶段方法不同,可直接从单张二维图像恢复三维人体网格。
2) 大部分三维人体重建结果都是无纹理的,而本文不仅重建出三维人体的形状和姿态,还从二维RGB图像中学习到纹理图。
3) 设计三维损失、二维重投影损失、二维渲染损失和生成对抗损失的组合损失,提高了三维人体形状和姿态重建精度并生成较合理的纹理图。
1 方 法
本文以单视图为输入,利用编码器、解码器网络回归SMPL模型参数,借助GAN网络重建带纹理的三维人体网格。
1.1 模型管线图
本文的网络结构框架如图1所示。从输入的单幅RGB图像中提取特征,采用相机、纹理、光照以及形状编码器提取相机参数、纹理特征、光照参数和形状特征。形状编码器采用预训练的ResNet-50[16]对图像进行编码,得到的图像特征被送入三维回归模块,推断出三维人体SMPL模型参数;再用SMPL模型重建三维人体网格。相机、光照、纹理编码器都使用了二维卷积块、平均池化层以及线性层的结构,得到相应的属性参数。其中,纹理参数再被送入纹理解码器网络,得到纹理图。
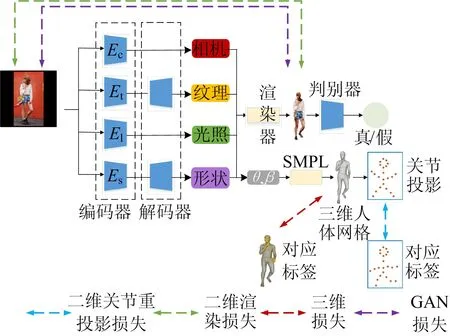
图1 网络结构的框架
本文将二维和三维约束相结合,使用三维损失、二维损失、GAN损失,二维损失使用关节点重投影损失,图像渲染损失。从这些约束条件出发,本文的网络结构可以精准重建出带纹理的三维人体形状和姿态。此外,本文模型在预测和训练阶段皆不需要真实的相机外参和光照系数,就能从输入的RGB图像中回归出相机参数和光线参数,这使得本文方法应用更加广泛。
1.2 属性编码器
设I∈RH×W×3表示高为H、宽为W的彩色输入图像,O(S,T)表示三维人体网格,S=(θ,β)为形状属性,其中θ∈R3K和β∈R10分别表示位姿参数和形状参数。纹理属性T∈RH×W×3表示分辨率为H×W的UV图。C=(a,e,d)为相机属性,其中a∈[0°,360°]、e∈[-90°,90°]、d∈[0,+∞]分别表示方位角、仰角和距离参数。光照属性L∈Rl由球谐函数建模,它由一个不同的角频率的球面基组成,l是球谐函数系数的维数。
本文通过4个子编码器独立预测属性,相机编码器Ec预测1个由(ax,ay,e,d)组成的4维向量,其中:e和d分别表示相机的仰角和距离参数;ax和ay表示方位角的笛卡尔坐标,a=atan2(ax,ay)。用这种方式计算方位角参数,可以避免在定义域[0°,360°]中出现不连续的回归问题。用ResNet-50作为形状编码器Es的网络,得到的图像特征被送入三维回归模块,迭代推断出三维人体SMPL模型参数θ∈R3K和β∈R10,其中K=23个关节点。对于纹理编码器Et,本文不是通过编解码器模型直接输出纹理UV图,而是先预测一个二维流图,然后应用空间变换生成纹理UV图T。对于光照属性,子编码器El直接编码一个l维向量,作为球谐函数模型系数。
输入图像Ii∈RH×W×3,i=1,2,…,N,其中N为训练样本的数量。三维人体网格重建是训练编码器Eη,从单幅图像预测三维人体网格属性:
Ai=(Ci,Li,Si,Ti)=Eη(Ii)
(1)
其中:η为编码器的可训练参数;Eη为4个子编码器的并集。
1.3 可微渲染
给定三维属性A=(C,L,S,T),在相机视图C和光照环境L下,三维人体网格O(S,T)可以渲染为二维图像。三维人体的渲染过程可表示为:
Ir=R(A)=R(C,L,S,T)
(2)
其中:Ir为输出的渲染图像;R为可微渲染器,不包含任何可训练参数。
1.4 回归的SMPL模型参数
SMPL模型是一种参数化人体模型,可以进行任意的人体建模和动画驱动。SMPL模型又是一种生成模型,通过参数可对人体的形状和姿势进行调整,如人体的身高、体重、身体比例以及三维表面随关节的变形。形状参数β∈R10由形状的主成分分析空间的前10个系数组成。位姿参数θ∈R3K由K=23个关节以轴角表示的相对三维旋转组成。SMPL模型由N=6 980个顶点的三角网格M(θ,β)∈R3N组成,通过调整参数β、θ,根据关节旋转角度θ进行正运动学拼接,再用线性混合蒙皮对曲面进行变形获得。
1.5 损失
本文整体的训练损失L包括二维损失L2D、三维损失L3D、生成对抗损失Lgan3个部分,即
L=λ1L2D+λ2L3D+λ3Lgan
(3)
其中,λ1、λ2、λ3为权值常数。
1.5.1 二维损失
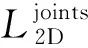
(4)
三维关节点X(θ,β)∈R3K重投影的二维关节点为:
(5)
其中,Π为投影运算。
为了使关节重投影误差最小,人体位姿更准确,设置了关节重投影损失,即
(6)
其中:xi∈R2K是第i个真实的二维关节点;vi∈{0,1}表示每个模型中K个关节的可见性,若可见,则为1,否则为0。
本文希望渲染的图像和输入的图像是接近的,因此定义二维渲染损失:
(7)
其中:Ii为第i幅图像;Eη为Ec、El、Et和Es的并集;R(·)为可微渲染器,它将二维图像空间与三维属性空间连接起来。
1.5.2 三维损失
重投影损失使得神经网络生成一个三维人体,解释二维关节位置;然而人体测量学上不合理的三维物体或具有自交的物体可能使重投影损失最小化。因此本文引入三维损失:
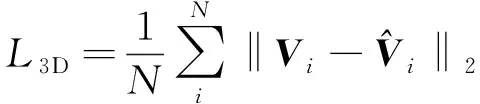
(8)
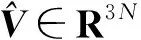
1.5.3 生成对抗损失
本文使用生成对抗性损失训练模型中4个子网络,使得重建的三维人体渲染图更接近输入图像。本文模型的生成对抗损失定义为:
Lgan=LG+LD
(9)
其中
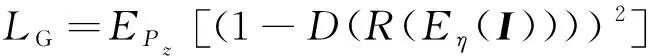
(10)
LD=EPz[D(R(Eη(I)))2]+
EPdata[(1-D(I))2]
(11)
其中:G(·)生成器;D(·)为判别器;Pdata、Pz分别为真实数据分布和生成数据分析。
2 实 验
2.1 数据集和评估指标
2.1.1 数据集
本文使用UP-3D数据集[2]和THuman数据集[17]进行单幅二维图像的三维人体重建实验。在UP-3D数据集中,使用了8 000多个数据项,每项包含1张RGB图像,对应的关节点和真实的SMPL参数。THuman数据集大约有7 000个数据项,剔除了多人图像,在训练中使用了其中4 000多个数据项。大约按3∶1划分训练集和测试集。
2.1.2 评估指标
在定量评估时,使用逐顶点误差平均值(mean per vertex error, mPVE)作为第一评价标准,计算真实顶点与预测顶点之间的欧氏距离;倒角(Chamfer)距离作为第二评价标准,用来测量预测点集和真实点集(P1、P2)间的相似性,定义如下:
(12)
此外,还用二维图像的评估指标FID(fréchet inception distance)[18]评估渲染图像。FID计算真实的输入图像和生成的渲染图像在特征空间的距离,FID值越低意味着图像的质量越高。本文从0°~360°每30°一个间隔的视角计算FID的平均值。这3个评估指标数值越小表示结果越好。
如文献[19]所述,常用的度量不能完全反映几何重建的质量,如表面的平滑度和连续性。因此本文认为视觉效果也很重要。
2.2 实验设置
本文的网络是使用Pytorch实现的,形状子网络的图像编码器使用在ImageNet[20]上预训练的ResNet-50模型。在训练中,人形模板网格有N=6 980个顶点和13 776个面,输入图像的分辨率为128×128。本文使用β1=0.5、β2=0.999的Adam优化器,批处理大小设置为16,学习率初始化为1×10-4,学习率衰减策略使用余弦退火学习率。整个训练过程一共500个epoch,每20个epoch进行一次测试。本文网络框架中的一些超参数设置为:λ1=1,λ2=1,λ3=0.000 1,μ1=1,μ2=0.1。
2.3 实验结果及比较
2.3.1 定量结果
本文定量比较的结果见表1所列。本文使用mPVE和Chamfer作为度量标准,卷积网格回归(convolutional mesh regression,CMR)方法[5]的结果是最好的,本文结果是次好的,与CMR的数据非常接近;接着是人体网格重建(human mesh recovery,HMR)方法[15]和SMPLify-X[21];最后是分层网格变形(hierarchical mesh deformation,HMD)方法[22]。CMR方法是非参数方法,它利用图卷积对所有顶点进行变形,定量结果相对参数方法更好一些,但顶点变形使人体表面不太光滑,也可能会出现奇异点,视觉效果不太理想。而使用SMPL模型参数是为了在任何情况下重建视觉上有说服力的人体几何结构。从定量结果来看,本文方法优于HMR、SMPLify-X、HMD 3种参数化方法的。对比的4种研究结果取自于文献[5,15,21-22]。
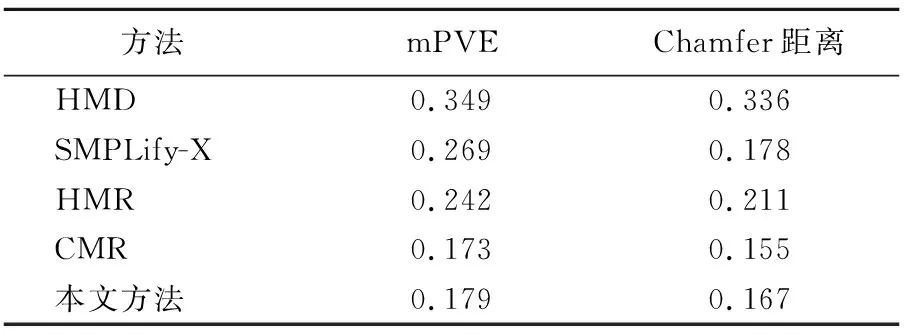
表1 与先进方法的定量比较
2.3.2 定性结果
数值指标不能完全反映重建质量,因为一些具有良好数值指标的重建结果在视觉上并不令人满意,所以在与其他方法比较时,不仅要定量比较数值结果,而且要注意视觉效果的比较。在UP-3D数据集上,本文方法重建的三维人体模型如图2所示。图2a、图2b中:第1列表示输入图像;第2列表示图像视角观察到的重建的三维人体网格;第3列表示其他视角观察到的重建的三维人体网格;第4列表示带纹理的三维人体。从图2可以看出,本文方法不仅能从RGB图像重建三维人体的形状和姿态,而且能根据输入的RGB图像重建三维人体的纹理,而作为比较的其他方法都没有给出人体的纹理。参数化方法重建的人体模型更加光滑和完整。

图2 本文方法的可视化结果
HMR方法、CMR方法、CMR延伸的参数化方法和本文方法的定性比较如图3所示,可以从视觉上直观看出三维人体重建结果的差异。图3中:第1行是输入图像;第2、第3行是HMR方法重建的相应视角及其他视角结果;第4、第5行是CMR方法重建的三维结果;第6、第7行是CMR延伸的参数化方法重建的三维结果;第8~第10行是本文方法重建的三维结果和二维纹理展示。由图3的第1、第2列可以看出:CMR非参数化方法的一个缺点,即当人物在图像中占比很小时,CMR方法重建的结果可能连基本人体形状都没有;虽然HMR方法和CMR延伸的参数化方法可以重建三维人体,但姿态不正确;而本文方法不仅重建正确的三维人体形状和姿态,还学习到人体纹理。由图3的第3列可以看出,本文方法重建的人体双臂是自然下垂的,其他3种方法重建的胳膊姿态都不正确,其他视角也可以佐证。图3第4列的HMR方法的人体腿部没有像输入图像那样交叉站立。由图3第5、第6列CMR方法的其他视角图上的人体腿部可观察到非参数方法的另一个缺点,即重建的身体不是很光滑。

图3 本文与其他方法的定性比较
总体来看,虽然CMR非参数化方法的数值结果最好,但视觉效果还有很多不足。与这些方法相比,本文方法重建小尺寸人物优于其他方法,重建中大尺寸人物也具有竞争力,此外还给出人体的纹理。
2.4 消融实验
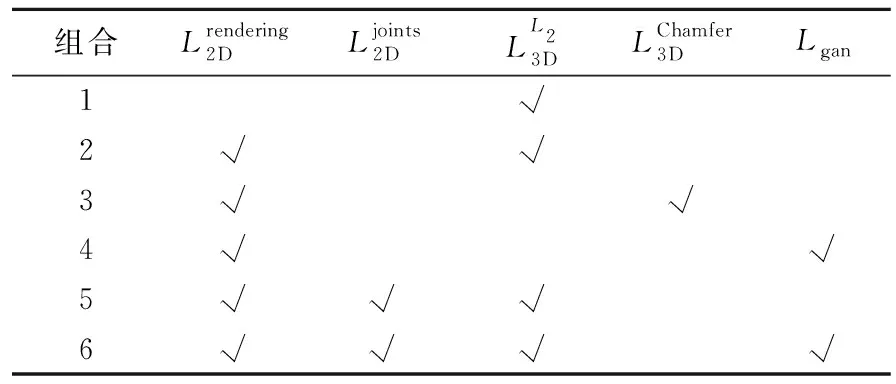
表2 消融实验设置
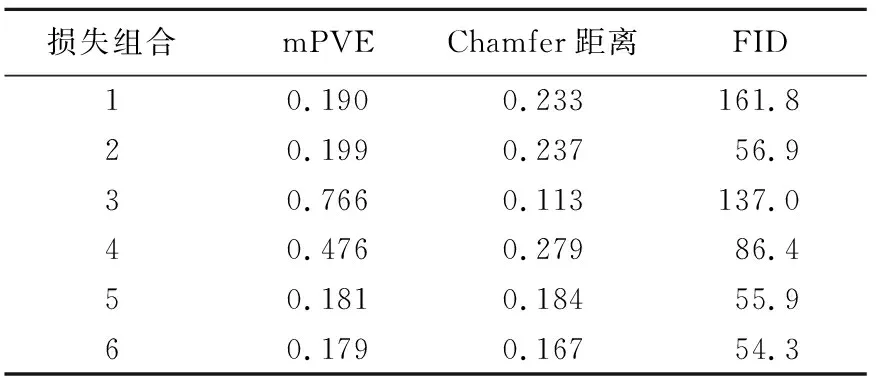
表3 不同损失组合的消融研究
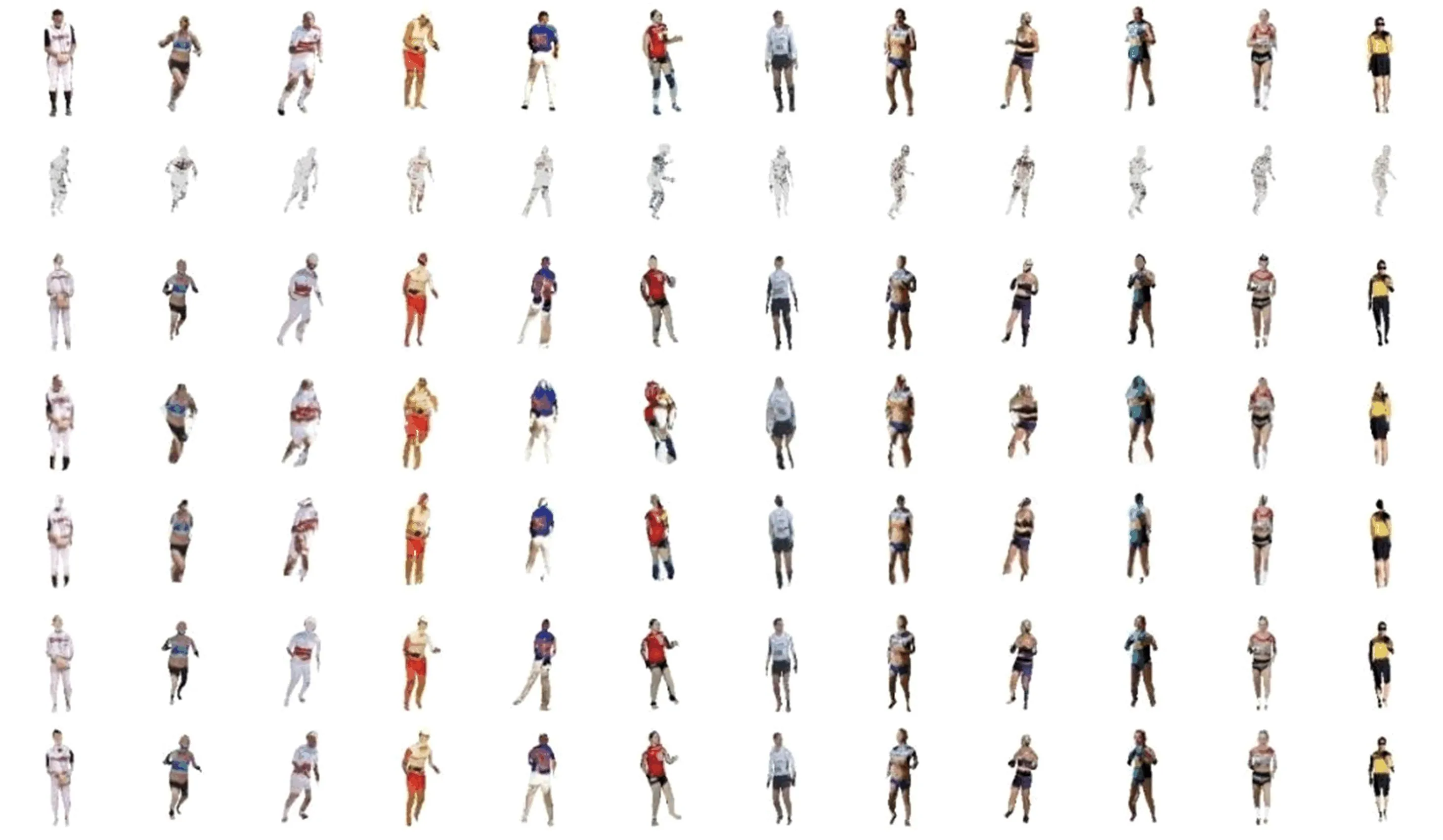
图4 具有不同损失的消融研究结果的可视化结果
在消融实验中,首先仅考虑三维监督,用顶点误差的2-范数作为损失函数,这时三维损失较小但渲染损失很大(见表3损失组合1);视觉效果见图4第2行,只用三维监督,纹理不正确,相机视角也没有被正确估计。接着加上了二维渲染损失,表明渲染质量的FID指标有明显降低,但是三维质量的误差稍微变大(见表3组合2);图4第3行也表明这时重建出较正确的三维形状、姿态和纹理。为了对比2-范数和Chamfer距离在三维损失中的效果,表3组合3把三维监督中的2-范数换成Chamfer距离,Chamfer距离是找重建点集和真实点集之间每个顶点和最近顶点的双向距离的平均值,这时Chamfer距离明显降低,而mPVE和FID都显著增大;对应的图4第4行中人体的头部肩部会出现相连的情况,这是因为在特征显著或细节丰富而顶点不够密集的区域,Chamfer距离作为损失过分追求损失最小化造成人体形状和姿势的扭曲。再考虑不用三维监督的情况,只用二维渲染损失和一个生成对抗损失。这时,因为缺少三维损失,三维指标和图像指标与组合2相比都变差(见表3组合4);由图4第5行也可以看出重建结果缺少人体胳膊纹理。在组合1~组合4中,组合2综合指标最优,因此本文最终选择了二维和三维混合监督的方法,并且三维损失中使用2-范数。但由于形状和姿态与输入图像(图4第1行)还不是特别一致,尝试加上二维关节重投影损失(见表3组合5),所有指标都进一步改善。最后添加生成对抗损失,所有指标达到最优(见表3组合6),视觉效果也有所改善(见图4第7行)。
3 结 论
本文提出一种端到端的网络框架,在三维损失、二维渲染损失、二维关节重投影损失和GAN损失的混合监督下,利用4个子网络,在允许没有真实相机参数和照明系数的情况下,可以重建带纹理信息的精准三维人体网格。在后续工作中,将探索在没有三维监督的情况下重建具有纹理且形状姿态准确的三维人体网格。
