融合PVT多级特征的口罩人脸识别研究
2024-03-28冉瑞生高天宇房斌
冉瑞生 高天宇 房斌
摘要:呼吸系统疾病的流行使口罩扮演着重要角色,这给人脸识别算法带来了新的挑战。受到多尺度特征融合模型的启发,提出一种基于金字塔视觉Transformer (Pyramid Vision Transformer, PVT)的提取口罩人脸特征的模型。该模型引入自注意力机制来提取丰富的人脸信息,通过融合PVT多个层级的特征向量,来实现对口罩人脸的多尺度关注,相较于传统特征融合模型,具有更高的识别精度和更少的参数量。此外,模型采用Sub-center ArcFace损失函数来提升鲁棒性。模型在大规模模拟口罩人脸数据集上進行训练,并分别在普通人脸、模拟口罩人脸和真实口罩人脸数据集上进行了测试和评估。实验结果表明,所提出的方法与其他主流方法相比,具有较高的识别精度,是一种有效的口罩人脸识别方法。
关键词:口罩人脸识别;Transformer;自注意力机制;特征融合
中图分类号:TP391.41文献标志码:A文献标识码
Research on masked face recognition by fusing multi-level features of PVT
RAN Ruisheng1,GAO Tianyu1,FANG Bin2
(1 College of Computer and Information Science, Chongqing Normal University,Chongqing 401331, China;
2 College of Computer Science, Chongqing University,Chongqing 400044, China)
Abstract: The prevalence of respiratory diseases has made masks play an important role, which has brought new challenges to face recognition algorithms. Inspired by the multi-scale feature fusion model, a Pyramid Vision Transformer (PVT) based face mask feature extraction model is proposed. The model introduces self-attention mechanism to extract rich face information, and realizes multi-scale attention to mask faces by fusing multi-level feature vectors of PVT. Compared with traditional feature fusion model, the model has higher recognition accuracy and fewer parameters. In addition, the model adopts Sub-center ArcFace loss function to improve robustness. The model was trained on a large scale simulated mask face dataset, and tested and evaluated on ordinary face, simulated mask face and real mask face dataset respectively. The experimental results show that the proposed method has higher recognition accuracy than other mainstream methods, and is an effective mask face recognition method.
Key words: masked face recognition;Transformer;self-attention;feature fusion
近年来,随着人工智能技术的不断发展,人脸识别技术已经被广泛应用于各个领域。然而,在当前全球呼吸系统疾病流行的背景下,佩戴口罩已成为一种必要的防护措施[1]。口罩对人脸的遮挡给人脸识别技术带来了新的挑战,成为降低准确率的主要原因之一。因此探索一种提取人脸鲁棒性特征的方法具有重要意义。当前,已经有部分口罩人脸识别算法被提出,例如,Mandal等[2]利用Resnet-50模型,对未佩戴口罩人脸数据进行训练后再迁移到口罩人脸数据,旨在通过对未佩戴口罩的人脸数据进行训练,实现对口罩人脸的识别。姜绍忠等[3]提出一种CNN与Transformer相结合的混合模型,在人工合成的口罩人脸数据集上进行训练,所训练的模型能同时处理戴口罩和不戴口罩的人脸识别任务,但该方法缺乏对真实口罩人脸的验证。Li等[4]提出一种基于裁剪和注意力机制的口罩人脸识别方法,该方法通过对人脸图像进行裁剪,以此来移除受损区域或降低遮罩区域的权重,并结合注意力机制来关注眼睛周围区域。这种方法能够更加有效地捕捉人脸的局部特征信息,从而提高模型的识别准确率。然而,该方法会降低无口罩人脸识别的准确率。Qian等[5]提出了一种方法,将ArcFace损失函数和pairwise loss结合起来,以增强遮挡人脸识别任务的性能。该方法旨在提高同一类别内样本的相似度,同时增加不同类别之间的差异性,从而提高遮挡人脸识别的准确性。
这些方法虽然能实现口罩人脸识别,但还是存在一些问题。首先,现有的大部分方式通过单一尺度特征进行预测,这样可能会忽略一些其他尺度的特征,例如,对于人脸而言,同时考虑眼睛大小和整个人脸轮廓的多尺度特征对于全面捕捉人脸特征至关重要。其次,当前的主流特征融合方法主要集中在特征图的整合上,这可能会增加计算负担。
针对以上问题,本文提出一种融合PVT各尺度特征的口罩人脸表征方法,该方法可同时用于佩戴口罩和不佩戴口罩的人脸识别场景。主干网络使用基于MSA (Multi-head Self-Attention)改进的PVT (Pyramid Vision Transformer)提取人脸的多尺度特征。在每个尺度阶段都使用1个cls (class token)向量来存储该尺度的人脸特征,并通过融合各尺度的cls以使得提取的特征更加丰富。最后,使用Sub-center ArcFace损失函数来进一步提高模型的鲁棒性。该方法使用多个数据集进行验证,涵盖了多种人脸场景。实验结果表明,本文方法能有效提高口罩人脸识别的准确率,同时特征融合的计算量也相对较低。
1 资料与方法
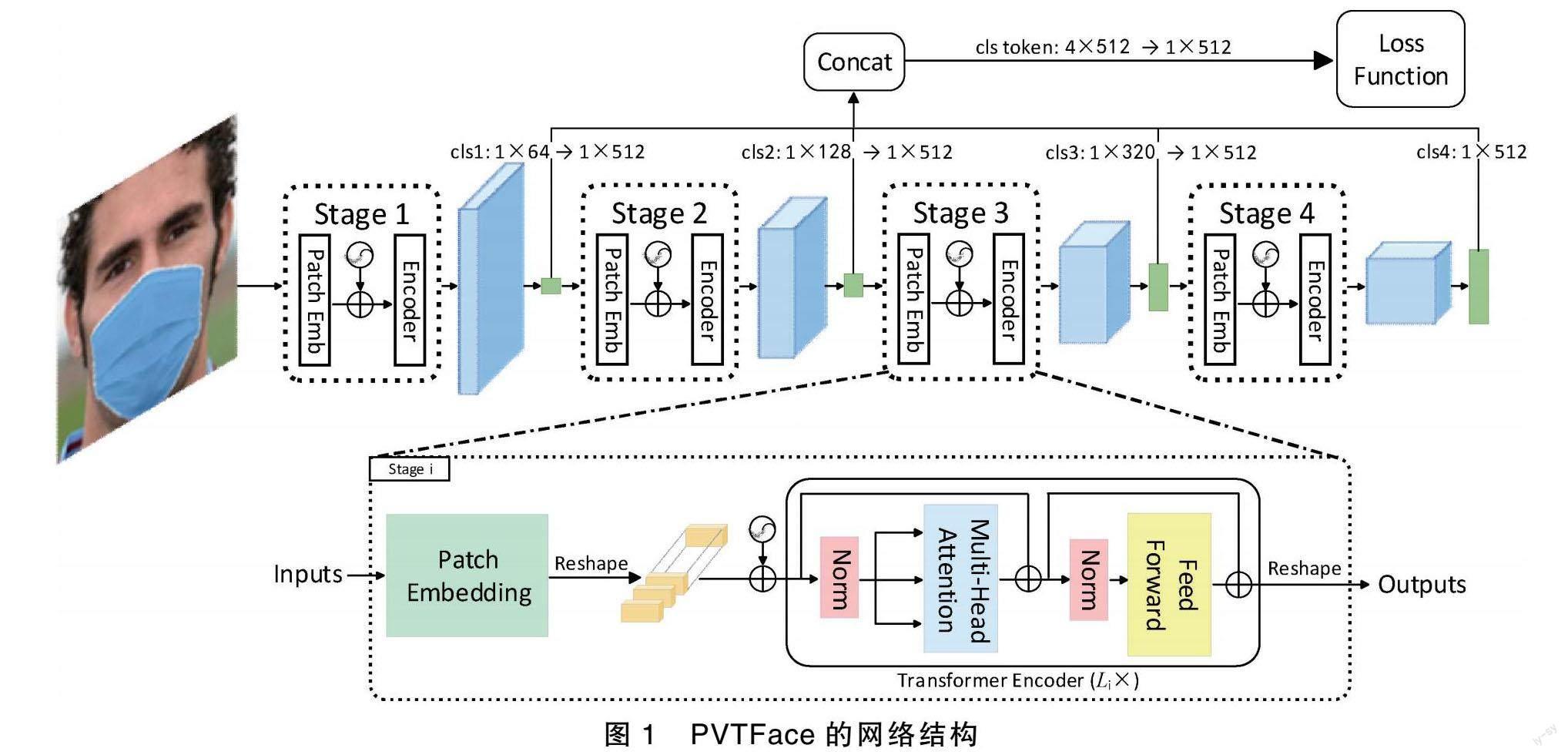
本文提出了融合PVT多级特征的口罩人脸识别模型,命名为PVTFace。
设输入图像为三通道(RGB)彩色图像,图像尺寸为112×112。PVTFace模型首先将图像分割为196个不重叠的图像块,每个图像块会被转换为向量形式,得到Patch Embedding,然后拼接cls向量并添加位置信息,cls用以存储图像特征,方便后续阶段的计算。随后将Patch Embedding输入到多个堆叠的Transformer Encoder中进行计算得到相应的特征图,Transformer Encoder中的注意力机制使用MSA[6]。特征图再输入到下一个Stage进行采样。完成各Stage采样后,再将各Stage的cls进行融合。最终,将融合后的图像特征送入Sub-center ArcFace损失函数进行计算。
PVTFace网络结构如图1所示,接下来将对所改进的模块进行详细阐述。
1.1 注意力机制
Spatial-Reduction Attention (SRA)[7]是PVT中提出的一种注意力机制,相较于MSA,SRA通过对键矩阵K和值矩阵V进行空间上的下采样,以达到降低计算复杂度的目的,SRA与MSA的结构对比如图2所示。
然而,在口罩人脸识别的场景下,使用SRA对人脸图像进行下采样可能会导致忽略一些重要的特征。因为口罩遮盖了部分面部特征,如嘴巴、鼻子,所以降低空间分辨率可能会造成信息的丢失。在这种情况下,使用SRA可能会降低对于口罩人脸的识别准确性。
Self-Attention可以在输入序列中建立长依赖关系,且能对输入序列中的所有位置进行关注,从而能够捕捉全局的语义信息。在人脸识别任务中,由于人脸图像中的各个部分之间存在较强的相关性。
Self-Attention可以有效地将这些关系建模,提高人脸识别的准确率。并且Self-Attention对于输入序列的变化(例如旋转、缩放、遮挡等)具有很强的适应性,因此可以提高模型的鲁棒性。其公式表述为:
Attention(Q,K,V)=softmaxQKTdkV。(1)
其中, Q, K, V分别为查询、键、值,它们由神经网络训练得到。
传统的Transformer使用基于Self-Attention机制的MSA。MSA是Self-Attention的扩展形式,它通过使用多个注意力头来提供多个视角的关注能力。每个注意力头可以专注于不同的特征子空间或关系,从而捕捉到输入序列的不同方面和语义信息。通过融合多个头的结果,MSA能够提供更全面和丰富的表示,进而增强模型对输入序列的建模能力。因此,本文使用MSA作为注意力模块,以便更好地捕捉序列的多样性特征和语义信息。
1.2 特征融合
以往的基于深度学习的人脸识别模型都过于注重深层次特征,即只使用网络的最后一层特征作为身份特征,这样可能会忽略浅层次的人脸特征[8]。在此基础上,本文提出一种基于PVT的人脸识别架构,通过融合各层次的特征来提取人脸的鲁棒性特征。
在每个Stage中,输入数据首先计算得到Patch Embedding,随后通过concat方式拼接1个cls向量用于存储该Stage的特征信息,再输入到多个堆叠的Transformer Encoder中进行计算,4个阶段的cls维度分别为1×64,1×128,1×320,1×512。再将各Stage中的cls维度全部映射为1×512,这样做的目的是为了保证各个Stage的特征信息可以得到充分的利用,并且各个特征具有相同的维度,便于后续的特征融合和计算,过程如图1所示。将各Stage的cls进行concat拼接得到维度为4×512的cls token,具体的特征融合过程可以表示为:
cls1:dim1×64→dim1×512,
cls2:dim1×128→dim1×512,
cls3:dim1×256→dim1×512,
cls4:dim1×512。
cls token=cls1+cls2+cls3+cls4,
cls token:dim4×512→dim1×512。(2)
式中,dim表示cls的维度,→表示维度映射变化。随后将拼接得到的cls token的维度由4×512映射为1×512,这样就使得PVTFace计算出的图像表征与原始PVT计算出的图像表征具有相同特征维度,却又包含了更加丰富的表征信息。
1.3 Sub-center ArcFace损失函数
目前主流的深度人脸识别方法,如CosFace[9]、ArcFace[10]在無约束的人脸识别中取得了显著的成功。然而这些方法通常只为每个类别设置一个中心,这种设计在受到噪声和变化的影响时可能会导致较差的鲁棒性。Sub-center ArcFace[11]为每个类别引入了K个子中心,训练样本只需要接近K个正向子中心中的任何一个。这样的设计可以更好地处理真实世界中的噪声和变化,提高模型的稳健性。
Sub-center ArcFace具体实现方式是,为每个身份设置1个K,并根据嵌入特征xi∈R512×1和所有子中心W∈RN×K×512进行归一化处理,通过矩阵相乘计算得到子类的相似得分S∈RN×K,然后对子类相似度得分进行最大池化以得到类的相似度评分S′∈RN×1。Sub-center ArcFace损失函数可以表述为:
ArcFacesubcenter=-logescos(θi,yi+m)escos(θi,yi+m)+∑Nj=1,j≠yiescosθi,j。(3)
其中,θi,j=arccosmaxkWTjkxi,k∈{1,…,K}。
2 结果与分析
本文实验在Linux环境下进行,使用的GPU为单个NVIDIA A100 PCIe,批量大小为128,总epoch为20,优化器为AdamW,初始学习率为3×10-4。本节将介绍本文所使用的数据集及相关处理,并通过分析实验结果来验证本文所提方法的有效性。
2.1 数据集
MS-Celeb-1M[12]是微软公司于2016年发布的一个大规模人脸数据集,其中包含400万张照片和79 057个人物的标签信息。本文首先对MS-Celeb-1M数据集进行清洗,再使用开源工具MaskTheFace[13]来对该数据集中的人脸生成虚拟口罩,得到MS-Celeb-1M_masked,并以此作为训练集。
本文使用了多个测试集,分别为LFW[14],LFW_masked,SLLFW[15],SLLFW_masked,CPLFW[16]和RMFD (Real-World Masked Face Dataset )[17]。其中LFW是由美国马萨诸塞州立大學阿默斯特分校计算机视觉实验室整理完成的数据库,包含13 233张照片和5 749个人物的标签信息;LFW_masked是使用MaskTheFace对LFW人脸进行掩码处理后生成的口罩测试集。SLLFW数据集是基于LFW实现,它构建了一组相似但非同一人的人脸对,该数据集旨在考察算法对于相似人脸的区分能力,提供更接近真实场景中的人脸验证情况。SLLFW_masked是MaskTheFace对SLLFW人脸进行掩码处理得到的口罩数据集。CPLFW数据集是在LFW基础上进行扩充,包含了多个姿态的人脸图像,如正脸、侧脸等,目的是提供更具挑战性的人脸验证场景。RMFD是武汉大学国家多媒体软件技术研究中心开放的真实口罩人脸数据集,涵盖了525人的5 000张口罩人脸图像。部分数据集图像如图3所示,这些数据集包括正常人脸、模拟口罩人脸和真实口罩人脸数据,同时考虑了人脸姿态等多种场景,可更全面地评估模型的识别性能。
2.2 实验与分析
2.2.1 实验与分析
本文通过与Resnet-50[18],Resnet-50f,GhostNet[19],MobileFaceNet[20],ViT[21]以及PVT等模型进行对比,其中,ViT和PVT是基于Transformer实现的模型。Resnet-50f是基于Resnet-50实现特征融合模型,用于与基于PVT特征融合的PVTFace进行比较。以上与PVTFace对比的方法全部使用CosFace作为损失函数。评估结果如表1所示,PVTFace在各测试集上的识别准确率均明显高于其他模型。这表明PVTFace在仅能提取少量特征的情况下进行训练就能兼顾戴口罩、不戴口罩、多姿态以及相似人脸区分等复杂情况。
值得注意的是,ViT虽然在处理自然图像等领域表现优异,但其只关注深层次特征,在处理面部遮挡等复杂场景下存在局限性,因为其缺乏空间信息的连续性和不变性,难以充分捕捉面部的细节特征。而金字塔模型(PVTFace和Resnet-50f)可以使用不同的感受野来捕捉不同尺度的信息,包括全局尺度和局部尺度。在全局尺度上,模型可以识别人脸的大体特征,如整体轮廓和人脸区域的大小和形状。在局部尺度上,模型可以更加精细地识别人脸的细节特征,如眼睛、额头等部位。
为了更进一步评估模型的整体性能水平,本文以LFW数据集测试结果为基础绘制了上述各方法的ROC曲线进行对比分析。如图4所示,纵轴代表真阳性率(TPR),横轴代表假阳性率(FPR)。以ROC曲线下方的面积(AUC)来评价方法的优劣,由此可见,PVTFace的识别效果远高于其他方法。
图5为本次实验7种模型在测试集LFW的准确率折线图,其中,基于特征融合实现的方法(如PVTFace, Resnet-50f)的识别准确率明显高于其他方法。PVTFace迭代四轮以后就能达到最佳效果。
表2展示了PVT使用不同特征融合方式识别准确率,各模型除了特征融合方式以外其他条件均一致。其中,cls_add表示使用add相加的方式将各Stage的cls向量相加;AFF表示使用基于注意力实现特征融合的AFF (Attentional Feature Fusion)[22],将不同尺度的特征图进行融合;FPT表示使用FPT (Feature Pyramid Transformer)[23]所提出的特征增强方式对各尺度的特征图进行融合与增强;cls_concat是本文所使用的特征融合方式,将各Stage的cls向量通过concat方式拼接。实验结果表明,cls_add方式在LFW_masked数据集的识别率略高于本文方法,但在其他数据集上的验证并不如本文方法。AFF方式在RMFD数据集的验证中取得了最佳结果,但由于其使用特征图融合的方式,参数量是本文方法的2倍多,提升效果却并不高。FPT方式也会产生较多模型参数,且效果不佳。
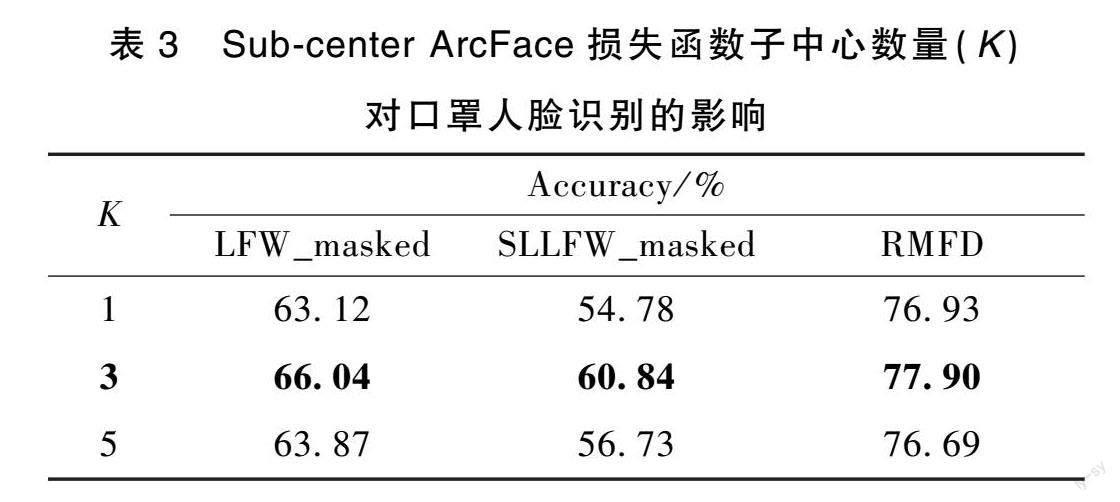
针对Sub-center ArcFace损失函数中子中心数量(K)对提取口罩人脸特征的影响,本文分别对K取值1、3、5在口罩人脸数据集上进行实验,结果如表3所示。观察发现,当K取值3时,在3个数据集中均取得了最优效果。这表明针对口罩人脸数据集,适当放宽数据的类内约束可以提高模型的鲁棒性。
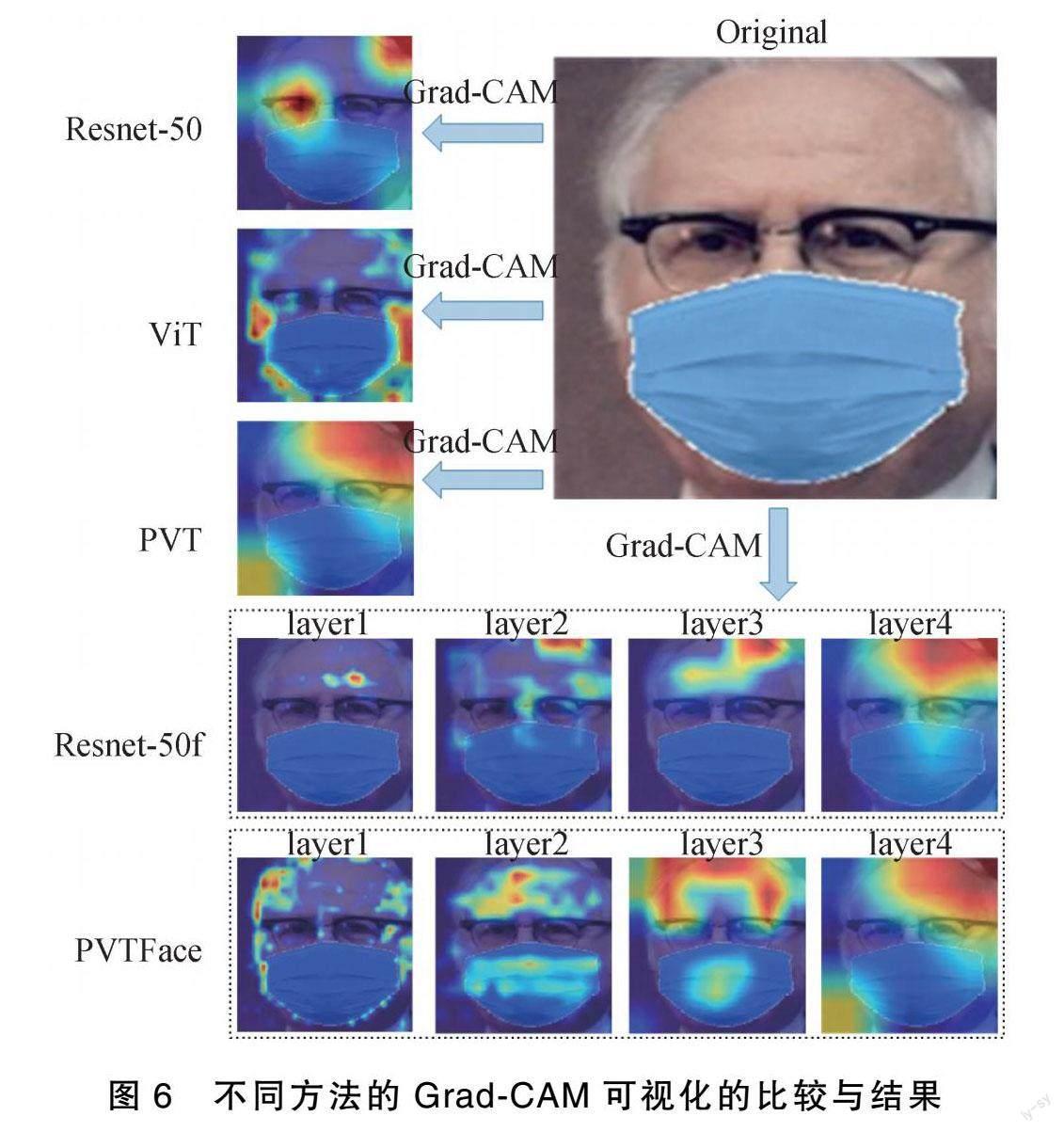
2.2.2 Grad-CAM可视化
为了更加直观的分析实验结果,本文使用Grad-CAM[24]生成类热力图,以此来可视化Resnet-50,ViT,PVT,Resnet-50f和PVTFace的注意力分布。如图6,图中颜色越深代表此处模型权重越高,即模型更加关注该区域。PVTFace各层关注点为面部轮廓、额头以及眼睛区域,将各层特征进行融合以后基本可以得到除口罩以外的所有面部区域。Resnet-50f各层关注重点集中在额头区域,而忽略了眼睛部位和面部轮廓的信息。其他模型都只关注了局部面部信息,这也是这些方法准确率低的重要原因。
2.2.3 模型参数量与计算量分析
表4展示了Resnet-50,ViT,PVT,Resnet-50f和PVTFace的参数量(Params)和计算量(MACs)。其中,Resnet-50f具有较多的参数量,这是因为在进行特征融合时它融合了整个特征图,而PVTFace仅融合了cls向量,从而大大减少了模型的参数量。
另外,ViT是基于自注意力机制的柱状结构,因此导致其计算量较大。相比之下,PVTFace相对于PVT仅增加了少量的模型参数和计算量,却取得了显著的识别效果,这表明所增加的参数量和计算量是值得的。此外,PVTFace的参数量和计算量都小于Resnet-50模型,突显了所提出模型的优越性。
2.3 消融实验
本节通过在各测试集上进行消融实验来验证该方法的有效性,实验结果如表5所示。表5的第一列为模型名称,其中“+”表示在上一个模型基础上进行的改进。“+MSA”表示将基准模型(PVT)的注意力机制由SRA改为基于自注意力机制的MSA;“+Sub-center”表示在上一個模型的基础上,将损失函数替换为Sub-center ArcFace;“+Feature Fusion”表示在上一个模型的基础上,将各层特征进行融合。通过这些消融实验,证实了每个改进对模型性能的影响,并展示了提出方法的有效性。
根据实验结果,可以发现在使用MSA和Sub-center ArcFace损失函数后,模型的识别准确率有了显著提升。而在进行特征融合后,模型的识别率进一步提高。这表明所引入的MSA、Sub-center ArcFace损失函数以及特征融合操作对提升模型性能起到了积极的作用。
3 结论
针对口罩人脸识别问题,本文提出融合PVT多级特征的模型。将PVT的SRA替换为基于自注意力机制的MSA以提取更丰富的人脸特征,并通过特征融合使模型集中关注未被口罩遮挡的人脸区域。为了减少模型的参数量和运算量,本文提出了一种融合各Stage的cls向量的特征融合方法。最后,本文采用Sub-center ArcFace作为损失
[7] WANG W H, XIE E Z, LI X, et al. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions[C]∥2021 IEEE/CVF International Conference on Computer Vision(ICCV), 2021: 568-578.
[8] ZHANG J W, YAN X D, CHENG Z L, et al. A face recognition algorithm based on feature fusion[J]. Concurrency and Computation: Practice and Experience, 2022, 34(14): e5748.
[9] WANG H, WANG Y T, ZHOU Z, et al. Cosface: Large margin cosine loss for deep face recognition[C]∥2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018: 5265-5274.
[10] DENG J K, GUO J, YANG J, et al. Arcface: Additive angular margin loss for deep face recognition[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019: 4690-4699.
[11] DENG J K, GUO J, LIU T L, et al. Sub-center arcface: Boosting face recognition by large-scale noisy web faces[C]∥European Conference on Computer Vision,2020: 741-757.
[12] GUO Y D, ZHANG L, HU Y X, et al. Ms-celeb-1m: A dataset and benchmark for large-scale face recognition[C]∥European Conference on Computer Vision, 2016: 87-102.
[13] ANWAR A, RAYCHOWDHURY A. Masked face recognition for secure authentication[J].arXiv: 2008.11104, 2020.
[14] HUANG G B, MATTAR M, BERG T L, et al. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments[C]∥Workshop on Faces in ′Real-Life′ Images: Detection, Alignment, and Recognition, 2008.
[15] DENG W H, HU J N, ZHANG N H, et al. Fine-grained face verification: FGLFW database, baselines, and human-DCMN partnership[J]. Pattern Recognition, 2017, 66: 63-73.
[16] ZHENG T, DENG W. Cross-pose lfw: A database for studying cross-pose face recognition in unconstrained environments[R]. Beijing University of Posts and Telecommunications, Tech. Rep, 2018, 5(7).
[17] WANG Z Y, WANG G C, HUANG B J, et al. Masked face recognition dataset and application[J].arXiv: 2003.09093, 2020.
[18] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]∥2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2016: 770-778.
[19] HAN K, WANG Y H, TIAN Q, et al. Ghostnet: More features from cheap operations[C]∥IEEE Conference on Computer Vision and Pattern Recognition, 2020: 1577-1586.
[20] CHEN S, LIU Y, GAO X, et al. MobileFaceNets: Efficient CNNs for accurate real-time face verification on mobile devices[C]∥Chinese Conference on Biometric Recognition, 2018: 428-438.
[21] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv: 2010.11929, 2020.
[22] DAI Y M, GIESEKE F, OEHMCKE S, et al. Attentional feature fusion[C]∥2021 IEEE Winter Conference on Applications of Computer Vision(WACV), 2021: 3560-3569.
[23] ZHANG D, ZHANG H, TANG J, et al. Feature pyramid transformer[C]∥European Conference on Computer Vision, 2020: 323-339.
[24] SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-cam: Visual explanations from deep networks via gradient-based localization[C]∥Proceedings of the IEEE Conference on Computer Vision, 2017: 618-626.
(責任编辑:编辑郭芸婕)
