改进YOLOv5 的变电站反无人机目标检测算法
2024-03-25叶采萍陈炯马显龙胡宗杰
叶采萍,陈炯,马显龙,胡宗杰
(1. 上海电力大学电气工程学院, 上海 200090;2. 云南电网有限责任公司电力科学研究院,昆明 650217)
0 引言
随着人们对电力需求的广泛性不断提升,变电站的数量和规模也在不断扩张,作为电力系统中电能输送和配送环节的重要一环,变电站运维的安全性和可靠性至关重要[1-4]。但由于无人机技术发展迅猛,普及率高,极大降低了该类产品的使用门槛,导致无人机的“黑飞”现象严重,对变电站安全运行的不良影响逐渐增强,开展反无人机入侵的目标检测逐渐成为研究热点。
目前反无人机探测技术大多是利用各种传感器收集到无人机的物理属性(如光学特性、磁学特性、声学特性)来发现目标对象。常用的无人机检测技术主要包含雷达探测、无线电信号探测和光电探测[5]。但由于无人机体积小[6],传统雷达对无人机探测存在一定局限,雷达对无人机探测时受到地面杂波干扰严重,虽然探测距离可达近10 km,但是识别性能较差。光电探测又称无源光学成像技术,虽然成本低,但杂波和天气对其影响很大。无线电信号探测是通过不同波长的红外成像获得图像,然后对图像进行分析,但大部分微小型无人机的热学特征不是很明显,需要和具有大范围搜索能力的模块配合使用[7]。针对这些问题,基于深度学习的目标检测算法[8]为反无人机检测提供了更多的解决方案。
基于深度学习的主流目标检测算法主要分为两类,一类是基于候选区域的双阶段算法,另一类是基于回归分析的单阶段算法[9]。双阶段算法[10]的“看两眼”含候选框的提取和分类,与单阶段算法的“只需要看一眼”相比,虽然在检测正确率和精度上略占上风,但存在检测速度慢的问题,而且目前对单阶段算法引入损失函数、结构优化等举措不仅能保证检测的实时效果也能满足实际应用的精度要求。目标检测在反无人机检测中具有重要的应用价值。虽然现在的计算机视觉技术发展迅猛,但针对无人机这类异物检测的内容尚少,且基于视觉信息的无人机检测是一个非常具有挑战性的任务,现阶段主流算法的检测成功率都在70%∼80%之间。孙颢洋等人[11]结合深度残差网络和YOLOv3 提取目标类别信息和像空间位置信息。薛珊等人[12]将图片的SIFT 特征作为支持向量机的输入向量作为解决小样本问题的解决方案。崔令飞等人[13]将轻量化算法与国产嵌入式计算平台结合构建出MobileNet-SSD 模型。虽然这些算法的设计与研究对于目前较为空白的反无人机视觉检测技术作出了一定的贡献,但普遍存在对微小信息检测难、深层信息挖掘效果不佳的情况。
为了保证无人机检测算法的检测速度和检测精度,本文旨在从轻量化主干网络出发,在保障实时检测速度的同时提高模型对于物体小、移动速度快等特点的无人机目标的识别精度。本文主要贡献如下。
1)考虑实际工程应用,基于YOLOv5 Nano 轻量化的基准模型进行改进,并进一步减少模型参数量和计算复杂度。
2)为了改善小目标识别能力差的缺陷,本文设计了四尺度检测结构,在 YOLOv5结构上增加一个基于浅层特征图的检测层,增加深层语义与浅层语义信息的融合,有效地提升小目标对象的检测效果。
3)将通道注意力机制和多头注意力机制用于专注目标对象识别,提高对于目标特征信息的提取能力,增强背景干扰下待检测目标的显著度。
4)考虑到网络最深处下采样倍数大极易导致获取信息难度大的问题。因此,本文在C3 模块内嵌入Transformer 编码器模块从而加强像素块之间的关联性。
1 YOLOv5 Nano
Ultralytics LLC 在2020 年提出的YOLOv5 是用Python 语言开发的YOLO 系列的最新模型,采用pytorch 框架的YOLOv5 具有非常轻量级的模型结构,相比YOLOv4 模型量级小了近90%,使检测速度与精度达到较好的平衡。YOLOv3 和YOLOv4 的模型计算速度均受到网络结构影响,较深层级模型会消耗更多的计算成本。
因此,本文作者于2021 年推出了YOLOv5n(YOLOv5 Nano)用于支持移动端部署的最轻量化模型。YOLOv5n 是YOLOv5 系列中网络深度最浅、训练速度最快的网络结构。Nano 型号保持了YOLOv5s 深度倍数为 0.33,但将 YOLOv5s 宽度倍数从 0.50 减少到 0.25。YOLOv5n 拥有190 万个参数,相比于YOLOv5s 的750 万参数量减少近75%,计算复杂度大幅降低,故模型大小也从7.5 M降低至1.9 M。模型具备了更加轻量化、精度更高、速度更快的优势。其整体网络结构如图1所示。
在网络结构上,模型训练时除了采用Mosaic数据增强方式丰富数据集,还增加了MixUp 和Copy-Paste[14]增强方式,通过随机缩放图片、数据上采样等方式增加了训练样本的多样性,以此提高了网络鲁棒性的同时,还能提升模型训练效率。
为了能从图像中提取出丰富的特征信息,YOLOv5n的主干网络结构延续CSPDarknet53结构,通过解析重复的梯度信息帮助特征在网络路径中的传播,有效减少模型参数量。此外,YOLOv5n 在YOLOv5s的基础上对主干网络主要进行以下4处改动:1)Focus 模块替换为Conv 模块;2)将位于主干层P3 的C3 模块的堆叠个数降低至6 个;3)SPP 模块优化为SPPF 模块,并置于主干网络末端;4)最后一个C3 模块重新引入快捷方式。上述操作不需要引入过多的计算开销就可以提高速度,帮助高层特征进行提取与融合。YOLOv5 Nano 的颈部网络采用特征金字塔(feature pyramid network, FPN)和路径聚合网络(path aggregation network, PAN)相结合[15]的方式,FPN[16]自顶向下加强特征由底层向高层间的传递[17],PAN[18]则自底向上地传递位置信息,减少计算量,促进信息流的传输。
2 改进算法
2.1 网络整体结构
针对变电站场景下对无人机的检测精度和检测速度均需要较高要求的实际情况,本文提出基于YOLOv5n的改进算法。整体模型结构框架上本文继续延续原始版本的结构,主要是参考CSPDarknet53和路径聚合网络的结构作为本文算法的主干网络和颈部网络。CSPDarknet53在分类和其他问题上具有更为强大的特征提取能力,并且其颈部设计用于更好地利用主干提取的特征,并在不同阶段对主干网络提取的特征图进行再处理和合理使用。本文的整体架构如图2所示。
2.2 四尺度特征融合结构
原始YOLOv5 框架中采用路径聚合网络结构对多尺度特征进行融合[19],对小目标检测采用的浅层特征图是8 倍降采样输出的特征图,为了更充分地利用图片的语义特征来提高检测网络的检测精度,本文对这部分结构进行改进,如图3所示。

图3 新增检测层后的特征提取模型Fig. 3 Feature extraction model after adding detection layer
本文将640×640 大小的图像作为网络输入,新增一个更小的尺度来进行小目标检测,同时仍保留原有的 3 种不同大小尺寸。经过5 次卷积操作,其大小为2,步长(stride)为2,padding 为1 的下采样操作后,获得以下4 组不同尺度的特征图:20×20、40×40、80×80和160×160。
对40×40 和80×80 两个中尺度特征图而言,同一级网络的输入节点和输出节点之间加入残差模块,保证特征信息的传递的同时融合更多的特征。对新增预测尺度160×160 而言,在4 倍下采样的部分开始提取特征,然后对8倍、16倍和32倍下采样特征再进行上采样,最后将相同尺寸的特征进行级联从而输出4倍降采样的特征融合检测层。
当前,新增特征映射尺寸为160×160,其含有更为丰富的浅层特征信息,对应原图的感受野较小,检测效果显著提升,能有效缓解小目标漏检情况。
对大尺度160×160 特征图而言,由于其含有较多位置信息,感受野最小,故用来检测小目标。同理,大尺度特征图应配小尺度锚框,小尺度特征图应用大尺度锚框进行预测框的回归。本文采用四尺度特征融合结构,各尺度的特征图大小与锚框尺寸的对应关系如表1 所示,当前锚框均在COCO2017数据集上,通过K-Means聚类算法统计得出。

表1 特征图大小与锚框尺寸对应关系Tab. 1 Corresponding relationship between the sizes of feature drawing and anchor frame
2.3 改进C3TR模块
本文受Transformer 编码器结构具有提取特征能力显著和运行效率高的启发,将其从自然语言处理(natural language processing, NLP)领域应用于计算机视觉[20-21],以C3 模块为基础结构嵌入注意力机制改进为C3TR模块。
Transformer编码器的核心在于注意力值计算和特征加权聚合,通过注意力值计算获取两块像素图(pixel)之间的关系,再用注意力值作为权重指导去聚合其他像素图的特征,最终效果使得特征的表征更加显著,信息量更多。本文的编码器结构与Attention is all you need[22]的编码器结构类似,使用了多头注意力机制和全连接网络(multi-layer perceptron, MLP)两种残差块,其区别在于前置模块采用了归一化层Norm(normalization)并通过MLP替换了前馈网络,Transformer编码器结构如图4所示。

图4 Transformer 编码器模块Fig. 4 Transformer encoder module
C3 模块[23]原型为BottleneckCSP 模块,以跨阶段局部(cross stage partial, CSP)结构为架构,上支路先通过一个1×1 的点卷积减少通道数,再通过瓶颈模块(bottleneck module)先降后升维并获取特征,与下支路的Conv模块并行后进行拼接(concat),再经过一个Conv 模块还原通道数,从而实现分层特征融合时减少计算量。具体结构如图5(a)所示。
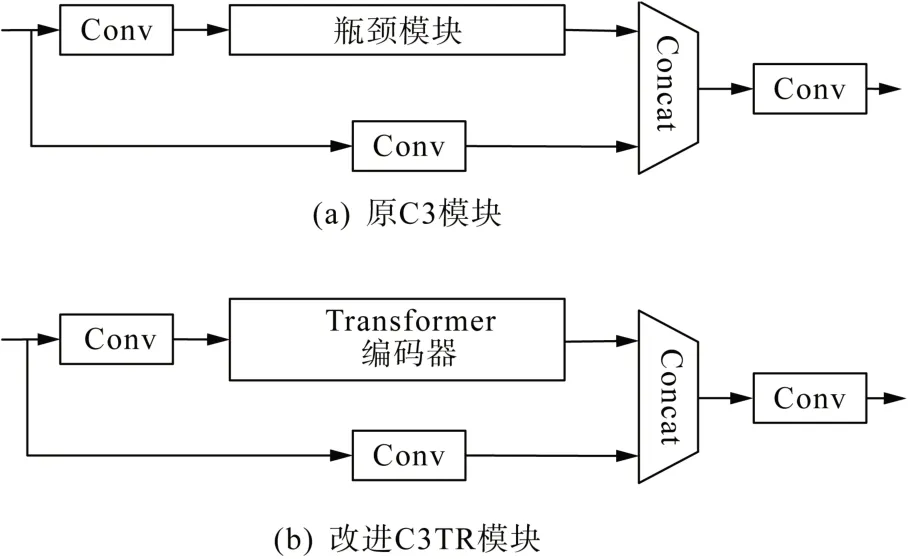
图5 改进前后模块对比图Fig. 5 Comparison of module before and after improving
C3TR 模块的结构延续CSP 主体包含3 个标准卷积层的架构。其优化点方式如下。
1)原瓶颈模块是通过先降维后升维的方式减少卷积层参数量,而C3TR 模块嵌入3 层Transformer编码器模块替代原瓶颈模块,保持原有结构带来的低推理量特性,计算复杂度更优。
2)利用编码器中的两个主要模块:多头注意力机制和全连接层MLP。其中,多头注意力机制不仅可以帮助当前节点注意当前特征,还可以获得前后像素块的相关性,而归一化层和丢弃层(dropout layers)则有助于网络更好地收敛,防止网络过度拟合。C3TR模块如图5(b)所示。
本文在 YOLOv5 Nano 的基础上只在主干网络末端和预测部分使用C3TR 模块,在底层特征图上形成一个基于C3TR 的预测头。由于网络末端的特征图分辨率较低,在低分辨率特征图上应用C3TR预测头可以有效地减少计算量和存储成本。同时结合其他3 个尺度的预测头,本文所提改进YOLOv5算法的四头结构可以更加有利于小目标物体的识别。此外,为了达到模型轻量化效果,只需在底层特征图上应用一个C3TR 预测头,过多增加预测头虽然会让该尺度特征图对微小物体敏感,但相应的计算和储存成本也会增加。因此,在模型的小目标检测性能差距不大的情况下应用于深层网络对模型整体而言更优。
2.4 卷积注意力模块
为了提高无人机目标的局部特征表达能力,本文在YOLOv5 网络模型Neck 中的每一尺寸预测输出前都加入了卷积注意力模块(convolutional block attention module ,CBAM)[24],其结构图如图6所示。

图6 CBAM模块结构图Fig. 6 Structure of the CBAM module
CBAM 模块包括两个注意力模块,即一个通道注意力模块和一个空间注意模块[25]。首先,它通过通道注意模块执行全局最大池化(max pooling)和平均池化(average pooling),然后分别通过MLP 层添加结果并传递Sigmoid 激活函数,从而提高特征图的准确性。通道注意力模块输出权重参数张量MC(F)计算公式如式(1)所示。
式中:σ(·)为Sigmoid 非线性函数;MLP(·)为MLP 层的计算函数;Maxpool(·)为全局最大池化的计算函数;Avgpool(·)为平均池化的计算函数;特征图F为尺寸为H×W×C的图片R,以图片R最左上角点为原点,水平向右为x轴,竖直向下为y轴,建立坐标系,其中H为R的高度,即纵坐标值,W为R的宽度,即横坐标值,C为通道数,图片R作为RGB 图像,其颜色空间有3 个通道,分别为:红(red)、绿(green)、蓝(blue);和分别为经过最大池化和平均池化的输出特征;W0和W1分别为MLP层的隐藏层权重和输出层权重。
然后将生成的通道特征映射通过空间注意力模块传递,利用空间子模块提取内部空间中的关系并计算出相应显著特征,从而降低特征信息在网络中跨连接问题造成的图像丢失概率,其空间注意力模块输出权重参数张量MS(F)计算公式如式(2)所示。
式中:f7×7为7×7的卷积层;和分别为在空间注意力模块中经过最大池化和平均池化的输出特征。
输入特征图F=RH×W×C。在经过通道注意模块和空间注意模块后为MC=R1×1×C和MS=RH×W×1,该过程如式(3)—(4)所示。
式中:F′为经通道注意力模块特征变换的输出结果;F″为经空间注意力模块特征变换的输出结果。
融合该模块后可以使模型更加关注关键处特征并抑制不相关的信息,以此能够有效提高识别精度和识别效率的同时又能保持原基础模型的检测速度,实现小目标的快速检测。本文引入了4 个卷积注意力模块,分别位于每个特征融合的末端、预测输出的前端。根据Sanghyun Woo所做实验[26]可知,在不同的分类和检测数据集上将 CBAM 集成到不同的模型中后模型的性能得到了很大的提高,这证明了CBAM模块的有效性。在变电站的背景下检测场景包含各类用电设备,监控画面中寻找小目标无人机存在一定困难,引入CBAM可以增强复杂背景中待检测目标的显著性,提升网络抵抗混乱信息的能力,对检测精确性也有一定程度的帮助。引入通道注意力模块后其部分特征可视化效果如图7所示。

图7 特征图可视化效果Fig. 7 Visualization effect of feature map
3 实验结果及分析
3.1 实验环境与参数设置
实验环境使用Windows 10 操作系统,使用NVIDIA GeForce 1080Ti显卡进行模型训练和测试,CPU 配置为Intel(R) Core(TW) i7-10700CPU,CUDA 版本为10.1, Pytorch 版本为1.11.0,Python语言环境版本为3.8。
目前公开的无人机数据集较少且尚无权威数据集。本文所用数据集主要由两部分组成,一部分选用Real World 公开数据集,其中包含51 446 张图像,另一部分选用Det Fly 公开数据集[27],包含13 798 张图像,两种数据集环境背景均包含天空、城镇、田野和山脉,视角都包括前视图、顶视图和底视图。本次实验选用上述数据集作为模型训练和测试的数据集,将样本图像大小统一调整为640×640。采用动量参数为0.937 的梯度下降法[28](stochastic gradient descent,SGD)作为优化策略,总迭代次数(epoch)为100 次,迭代批量大小(batch_size)为16,初始学习率lr0=0.01。为了避免初始训练时发生过拟合现象,本文在在前3 次迭代时使用动量参数为0.8 的Warm-up 方法进行预热。Warm-up 结束后采用余弦退火方式对学习率进行更新,达到最终学习率0.0001。
3.2 评价指标
为了客观评价本文算法的优势,本文采用召回率(recall)、准确率(precision)、平均精度(average precision, AP)[29]和平均检测处理时间(frames per second, FPS)[30]作为评价指标,各指标具体计算公式如式(5)—(8)所示。
式中:Recall为召回率;Precison为准确率;NTP为正确分类数;NFP为错误分类数;NFN为含有真值框但错判的数量;AP为平均精度;p(r)为Precision-Recall曲线中横坐标r对应的纵坐标p值。
式中:NFPS为平均检测处理时间;Nframes为算法所处理图像的帧数;Ttime为处理全部帧图像所消耗的单位时间,通常是1 s。
3.3 与主流算法的对比
为验证本文改进算法的有效性及轻量化水平,将本模型与YOLOv4[31]、MobileNet-YOLOv5[32]、YOLOv5s、 YOLOv5n 等主流算法作为对照,MobileNet-YOLOv5是以MobileNetv3[33]为主干网络的算法,其余算法的主干网络均为CSPDarknet53,以上算法均使用相同样本和参数进行训练,并与本文提出算法进行性能比较,实验结果如表2所示。

表2 主流检测算法模型性能对比Tab. 2 Performance comparison of mainstream detection algorithm models
从表2可以看出,本文算法与主流算法相比较,模型复杂度最低、检测准确度最高,并且保持着较高的推理速度,对于计算能力较弱的设备更加友好。
从准确率(precision)和召回率(recall)来看,本文算法的准确率最高,可达90.2%;召回率为85.0%,较MobileNet-YOLOv5、YOLOv5s、YOLOv5n 模型分别提高了7.1%、2.4%和4.3%。虽然略低于YOLOv4 的召回率,但YOLOv4 过低的准确率会导致错检率的提升,且该模型实时性低,无法达到变电站安全运维要求。
从平均精度(AP)来看,本文算法的AP 为89.5%,与YOLOv4 相差不大,相比MobileNet-YOLOv5、YOLOv5s、YOLOv5n 模型分别提高了4.8%、1.5%和4%。
从检测速度来看,本文模型FPS可达160帧/s,显然高于其他模型,相比YOLOv4、MobileNet-YOLOv5、YOLOv5s、YOLOv5n算法每秒分别提高了64帧、26帧、4帧、2帧。实时监测普遍要求检测帧率大于25帧/s,本文算法可以达到实时目标检测标准。
从轻量级角度来看,轻量级网络应具备参数少、计算量小、推理时间短的优势。本文通过模型的参数量(params)和计算量(giga floating-point operations per second, GLOPs)具象化评估模型的计算空间复杂度和计算时间复杂度。MobileNetv3在图像实时分类领域以轻量化著称。但是从表2中可以看出,MobileNet-YOLOv5 虽然相比YOLOv4 和YOLOv5s在参数量和浮点运算数上大幅降低,但本文模型不仅比MobileNet-YOLOv5 复杂度低,平均精度还提高了4.8%。本文模型比原模型YOLOv5n 的190 万参数量减少了6.8%,计算量减少了6.7%。
综合来看,本文算法相比于其他算法,从综合模型大小、算法复杂度、平均精度和检测速度考虑,在保证检测精度较高的同时兼顾了较快的检测速度,实现了以较小的检测精度换来模型复杂度的大幅降低,与其他算法相比具有一定的优势。
3.4 消融实验
为验证每个改进点对本文算法的贡献,本文进行消融实验。在相同实验条件下以YOLOv5n 模型作为基准算法,在此基础上逐步添加四尺度特征融合结构、混合注意力模块、改进C3TR 模块的顺序加入基线模型中。消融实验结果如表3所示。
从表3 中可以看出,实验2 新增一大尺度预测层,检测平均精度稍微提升,但贡献度不够大。实验3 在网络中嵌入的混合注意力模块和改进C3TR模块,AP 达到88.2%,说明在本文算法中注意力机制的融合对网络精度贡献度高于结构上的改进。实验4 是在实验2 的基础上嵌入混合注意力模块,可以看出,在四尺度特征融合结构下引入混合注意力模块可以增强模型对目标框的识别能力,提高模型检测平均精度。最后将实验3 与本文算法综合分析,在精度近似的情况下召回率比其他实验都有显著提升,能有效缓解小目标检测的漏检情况,使得模型平均精度得到有效提升。
消融实验整体证明,相较于基准模型,本文提出的3 处改进点对精确度和召回率都有所提高,在模型大幅减少计算量和参数量的同时对网络性能提升也有一定帮助。
3.5 本文算法检测效果
为了验证优化后算法在真实场景中的检测效果,本文挑选一些具有代表性的无人机视频进行检测,检测结果如图8所示。
图8(a)和8(b)分别为无人机在背景干扰时的原图和检测图,图8(c)和8(d)分别为无人机近距离的检测图,图8(e)和8(f)分别为多架无人机远距离超小目标时的原图与检测图,图8(g)和8(h)分别为较暗环境下无人机的原图与检测图。可以看出,本文算法对不同拍摄角度下的复杂背景和超小目标都展现出较为优异的检测效果,还能有效抑制背景噪声干扰,一般情况下人眼很难在这些图中迅速找到无人机,但通过改进后的YOLOv5检测模型能够对这些场景中的无人机快速准确识别。
4 结语
当前无人机缺乏规范管控,且其目标小,速度快,成为目标检测领域的难点。为提高变电站背景下对无人机的实时检测能力,本文对YOLOv5模型的结构改进,新增一个大尺度检测层,提高模型对微小目标的检测能力。考虑到特征在深层网络中传递容易造成信息丢失的问题,对小尺度检测层改进C3 模块设计,引入Transformer 编码器模块从而增强像素信息之间的关联性。在Neck 网络集成入混合注意力模块,一定程度上提升模型对于特征筛选能力。实验结果表明,本文算法可同时兼备轻量化、高精度和实时性要求,可以更好服务于变电站安全运行场景。
