基于图像融合与深度学习的人脸表情识别
2024-03-23焦阳阳黄润才万文桐
焦阳阳,黄润才,万文桐,张 雨
(上海工程技术大学电子电气工程学院,上海 201600)
0 引 言
在面对面交流中,面部表情的变化往往反映了一个人内心情感变化情况。随着计算机技术的发展,人脸表情识别被广泛运用在智慧课堂、智能驾驶[1]、医疗保障等领域。
人脸表情识别可分为3个步骤:图像预处理、特征提取与表情识别。特征提取是其中最关键的环节,分为传统特征提取和深度学习特征提取方法,传统方法通过特征描述符来提取表情特征,深度学习特征提取方法是指使用卷积神经网络进行特征提取。最近几年大量研究人员投入了对表情识别的研究中,Chen J 等人[2]使用方向梯度直方图(histogram of oriented gradient,HOG)提取人脸表情特征,然后使用支持向量机(support vector machine,SVM)进行表情识别。Boughida A等人[3]使用Gabor滤波器进行表情特征的提取。但传统方法提取的信息单一,并且缺乏高级语义信息,不能很好地满足人脸表情识别任务。
因此众多研究人员开始尝试使用深度学习方法来提取特征。冯杨等人[4]采用小尺度卷积核提取面部表情特征,提高了表情识别的准确率。Zhang S等人[5]设计了一种混合深度分离残差网络用于表情特征提取。但深度学习无法利用图像的局部特征信息,并且无法区分表情图像中重要的部分。因此,张翔等人[6]通过在神经网络中加入注意力模块来提高表情识别准确率。Wang H等人[7]使用MO-HOG与深度学习特征进行融合。
针对上文中提到的单一特征描述符提取信息有限,而深度学习无法关注有效图像信息等问题,本文提出了一种基于图像融合与深度学习的表情识别方法,对不同纹理特征图像进行融合,随后构建改进后的神经网络模型,将融合后的图像输入模型中进行高级特征提取,最后使用SoftMax进行表情分类。
1 人脸表情识别模型
本文提出的人脸表情识别模型流程:首先对图像进行预处理,随后使用局部二值与差分激励算子分别提取局部二值模式(local binary pattern,LBP)与韦伯局部描述符(Weber local descriptor,WLD)图像,差分激励描述了图像的局部强度信息,但忽略了边缘的方向信息,而局部二值描述了图像的边缘方向信息,却忽略了强度信息。将两种图像进行融合得到新的图像作为神经网络的输入图像。下一步构建改进后的残差神经网络(residual neural network,Res-Net),加入改进后的注意力机制与空洞卷积,使模型在扩大感受野的同时关注到有用的信息,减少对无用特征的关注,最后对表情进行识别。
2 表情识别模型具体设计
2.1 图像预处理
在原始图像中存在着许多对表情特征提取无关的信息,因此需要对表情图像进行预处理,包括人脸检测、灰度及尺寸归一化等。首先检测并裁剪出人脸部位,然后将三通道三原色(RGB)图像转换为灰度图,统一缩放成相同规格的尺寸大小,得到模型所需要的输入图像。
2.2 图像融合
2.2.1 LBP特征
LBP算子由Ojala 等人在1994 年提出,被广泛运用于人脸识别等领域。原始的LBP 算子计算中心像素与周围8个像素之间的关系,从中心像素的左上角位置开始,依次将邻域像素与中心像素进行比较,小于取0,大于取1。最后得到8个二进制数,将其按照顺时针的顺序排列,转换为一个十进制数,就得到了该中心像素的LBP值
其中,(xc,yc)为中心像素,p为邻域点的个数,ip为相邻像素灰度值,ic为中心像素灰度值,s为符号函数
2.2.2 WLD特征
WLD 特征是根据韦伯定律所提出的一种纹理特征描述符[8]。韦伯定律是反映心理量和物理量之间关系的定律,它表明能够引起感觉差异的差别阈值与原始刺激的强度之比是一个常量,即
式中k为常量,ΔI为差别阈值,I为原始刺激的强度。WLD包含2 个算子:差分激励算子和方向算子,方向算子通过计算中心像素垂直与水平像素差之比得到方向信息,本文仅使用差分激励算子。差分激励描述了窗口内图像像素的强度变化,通过计算中心像素与周围8 个点的像素差值和,将和与中心像素点灰度值进行比值计算,再利用反正切变换将比值映射到(π/2,-π/2)之间,其计算公式为
式中xc为中心像素值,xi为邻域像素值,P为邻域像素点个数。
2.2.3 图像融合
WLD中的差分激励算子描述了图像的局部强度信息变化,但其原始方向算子计算比较简单,故使用局部二值算子计算图像的方向信息。通过设置加权融合系数α,根据式(5)得到融合后的图像
式中XL为LBP图像,Xw为WLD图像,X为融合后图像。
2.3 改进ResNet
本文以ResNet18 为骨干网络进行神经网络模型的搭建,通过将前2个Block的卷积核替换为空洞卷积,扩大感受野范围。并在残差结构中加入改进后的注意力机制,有效提高特征的表征能力。
2.3.1 Dil-Block模块
原始的ResNet18是以残差块构成的神经网络,残差块的原理为输入特征图通过两个卷积层进行特征提取,最后与输入特征进行相加,得到输出。其中的卷积核大小均为3 ×3,但由于前后特征图尺寸均不同,因此需要对前面残差块扩大卷积核的采样范围,使模型获得更大的感受野。本文将前2个残差块的卷积核替换为空洞卷积。空洞卷积在与传统卷积一样的计算量情况下,可以扩大感受野的范围。图1为Dil-Block的示意,输入特征图首先经过2 个空洞卷积层进行特征提取,然后经过注意力层提取注意力,再与输入特征图进行相加,最后通过ReLU 激活函数得到输出特征。

图1 Dil-Block示意
2.3.2 改进注意力模块
在Dil-Block中添加注意力模块,旨在加强重要特征的权重。Wang Q等人[9]提出了ECA-Net注意力模块,使用一维卷积进行注意力权重的提取。ECA-Net 在进行通道注意力的提取时,仅使用全局平均池化,本文使用2 种不同池化方式来计算通道注意力。ECA-Net 仅计算了通道注意力,本文则在通道注意力后添加空间注意力的计算,得到完整的注意力权重,图2为改进注意力示意。
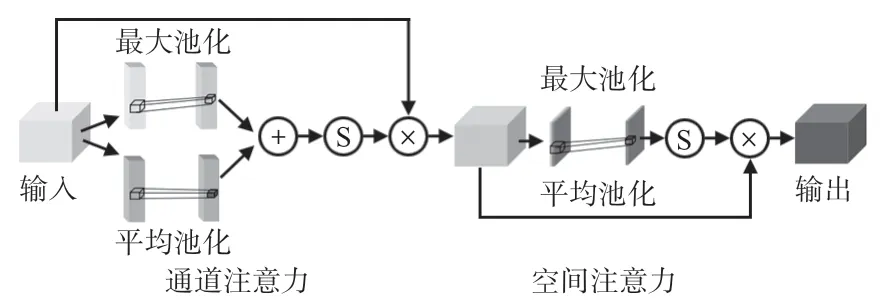
图2 改进注意力示意
图2 中的通道注意力部分将输入按照空间方向进行全局平均与最大池化,然后分别使用卷积核大小为k的一维卷积来计算相邻通道之间的相关性。k决定了通道之间交互的范围,本文采用以下公式计算k的大小
式中c为通道数量,Odd 为选择最近的奇数,γ和b分别设置为2和1。将2个注意力矩阵相加并通过Sigmoid函数得到注意力权重,与输入图像进行相乘,得到通道注意力特征图,接着按照通道方向进行全局平均和最大池化,得到一个二维特征图,使用7 ×7的二维卷积进行空间注意力的提取,最后通过Sigmoid 函数与特征图相乘得到最终的特征图。
2.4 表情分类
将上文中进行融合后的图像输入到改进后的神经网络中,经过一系列残差块的特征提取后得到最终的特征向量,再经过全连接层后通过SoftMax 进行表情分类。在本文模型训练过程中,使用了交叉熵损失函数作为优化函数
式中为真实值,为预测值,N为样本数。通过反向传播不断降低损失值来更新神经网络的权重参数,提高模型预测的准确率。
3 实验与结果分析
模型由Pytorch框架搭建,操作系统为Ubuntu 18.04,硬件配置如下:CPU 为Xeon®E5-2678,GPU 为NVIDIA Tesla K80,内存为8 GB。Python 版本为3.8,其中神经网络参数设置如下:优化器使用Adam,batch_size 为64,epoch 设置为20。
3.1 实验数据集
实验使用JAFFE和CK +数据集。由于2 个数据集中样本数据均较少,采用仿射变换的方式来进行数据增强。JAFFE数据集经过扩充后为4 540 张样本,CK +数据集为6 564张样本,并将两者按照9∶1 的比例划分出训练集和测试集。
3.2 融合系数α实验
在进行图像融合时,使用系数α进行融合比例的控制,分别选用不同的融合系数进行实验。图3为实验结果。
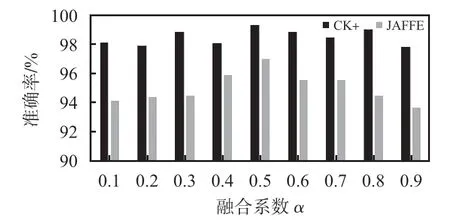
图3 融合系数α结果
从图3中可以看出,当融合系数取0.5 时,识别准确率最高,证明此时的融合图像既包含局部强度信息也包含方向信息。因此,本文后续实验均将融合系数设置为0.5。
3.3 消融实验
为了验证本文提出的表情识别模型的有效性,进行了模型消融实验,共设置了4 组对照实验。实验一的输入图像为LBP图像;实验二的输入图像为WLD图像;实验三的输入图像为融合图像,但将模型的前2个Block换为原始卷积核;实验四则将注意力机制去除。分别在JAFFE与CK +数据集上进行实验,与本文模型进行对比。消融实验结果如表1所示。

表1 消融实验结果%
从表1中的实验一与实验二的结果可以看出,2个数据集的准确率均不高,证明单个纹理特征所包含的信息有限。实验三的结果表示,对ResNet18 中的前2 个Block 进行卷积核的替换,有效增加了感受野的范围,使得模型能够在前期关注到更多的信息。在实验四中,添加注意力后,2 个数据集的准确率有了3%的提升,证明了注意力机制能有效提高模型对于重要特征的关注。
3.4 注意力对比实验
本文对ECA注意力机制进行了改进。为了验证改进注意力机制的有效性,与其他注意力算法进行对比,分别设置3组对照实验,第一组使用SE-Net,第二组使用CBAM注意力,第三组使用ECA-Net,最后为本文模型。实验结果如表2所示。
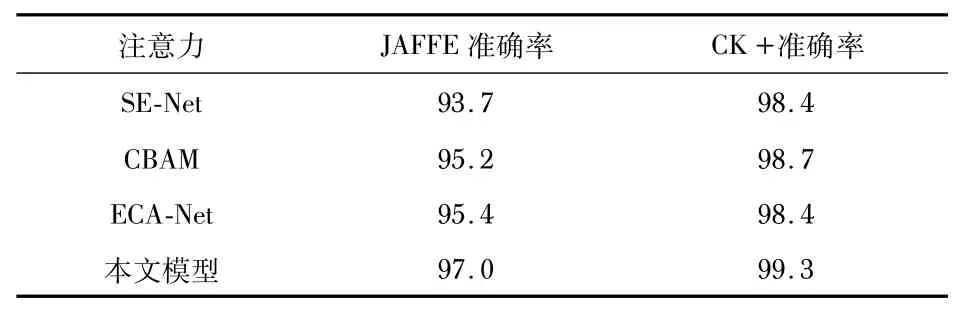
表2 注意力对比实验结果%
从表2中可知,本文模型取得了最高的识别准确率,分别为97.0%与99.3%。SE-Net使用全连接层来提取注意力权重,ECA-Net通过一维卷积进行通道注意力的提取,CBAM则对通道与空间注意力均进行了计算,通道注意力采用了与SE-Net相似的结构,空间注意力使用二维卷积进行计算。本文提出的改进注意力算法对上述算法的缺点进行了改进,使模型能够将注意力放到对表情识别有用的特征上。
3.5 与其他算法对比
表3为本文提出的方法与其他主流表情识别算法的识别率对比。通过表3 可知,无论传统方法还是深度学习方法,本文均取得了最高的识别准确率,证明了本文方法的有效性。
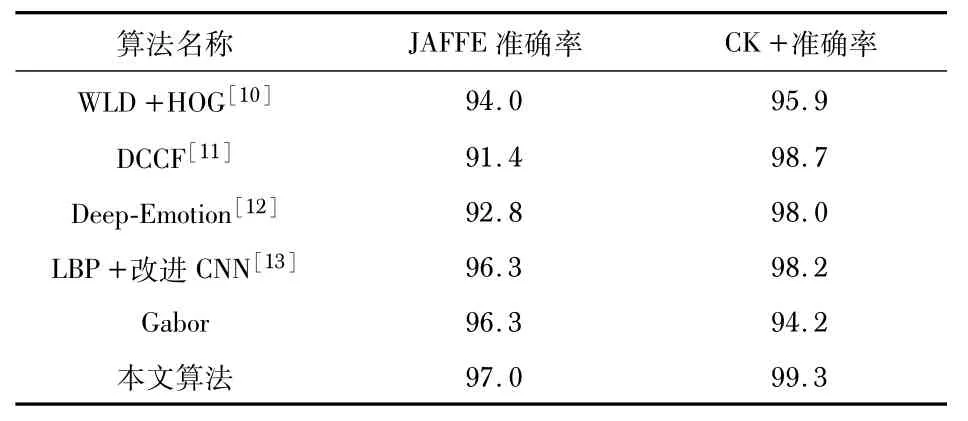
表3 本文算法与其他算法识别率对比%
4 结束语
本文提出了一种基于纹理图像融合与改进ResNet的人脸表情识别算法。通过WLD与LBP图像融合的方式进行局部纹理特征的融合,弥补了单一纹理特征无法有效表达图像信息的不足。同时对ResNet 进行改进,通过空洞卷积解决了感受野较小的问题,改进后的注意力模块则有利于模型关注重要特征。将融合后的图像输入到改进后的神经网络中进行表情识别,在JAFFE 与CK +数据集上进行验证,取得了不错的识别率。但模型对某些表情的识别率较低,后续将继续研究如何改进部分表情的识别率。
