基于CEEMD-BiLSTM-RFR的短期光伏功率预测
2024-03-22冯沛儒江桂芬徐加银叶剑桥李生虎
冯沛儒, 江桂芬, 徐加银, 叶剑桥, 李生虎*
(1.国网安徽省电力有限公司经济技术研究院, 合肥 230061; 2.合肥工业大学电气与自动化工程学院, 合肥 230009)
近些年,随着光伏发电渗透率不但增大,电网的稳定性、可靠性和经济性受到较大影响[1-2]。站在电网角度,有必要对光伏发电进行精准预测,以提高电网对光伏的调度能力和消纳效率[3],增强电网的灵活性和稳定性。
目前,光伏预测模型主要可分为物理预测、统计预测和组合预测[4]。物理预测是基于天气预报,然后根据光电转换效率得到光伏系统输出功率,如何建立详细的光电转换模型是预测的关键。文献[5]对光伏物理模型进行了总结,表明物理建模需要较大的运算时间。文献[6]比较了多种光伏物理模型,通过对辐照强度分离和转置建模,其预测精准度有较大提升。物理预测优点在于不需大量的历史数据,但是在物理模型中通常一些气象因素测量难度大或无法测量,在实际工程中会存在模型适用性差、精度较低等问题。
统计预测是通过统计算法建立输入和输出映射模型,本质上是“拟合”过程。常见预测方法有时间序列[7]、回归分析[8]、特征工程[9]、随机森林[10]、神经网络[11-12]等。通常这些方法将气象因素作为整体输入预测模型中,但气象因素之间的时间尺度、影响大小是不同的,在预测中将其统一作为输入可能会影响模型精确性[13]。
组合预测方法通过对光伏出力特征的有效分解然后对每个分量进行预测,能发掘原始数据在不同时间尺度的变化趋势[14-15]。为此,文献[16]提出由经验模式分解(empirical mode decomposition,EMD),然后通过相关向量机模型来预测短期光伏功率,但EMD分解后会丢失原始序列的一些细节,导致效果精度下降。文献[17-18]通过采用变分模式分解,对分量分别采用回声状态网络和卷积神经网络预测,但由于该分解方法需先定义分解个数,不能自适应分解,可能使预测精度降低。文献[19]将气象因素EMD分解后降维分析得到的主成分,然后建立LSTM预测模型,但未分析各主成分和光伏之间相关性,忽略了时间尺度的影响。文献[20]采用相似日处理气象数据,以达到数据降维的目的,但相似日数据量不同可能会影响预测精度。
综上,现有组合预测方法未体现分解后光伏分量和气象因素关系,即忽略光伏分量的时间尺度和气象因素的时间尺度的相关性。现提出基于互补集合经验模态分解(complementary ensemble empirical mode decomposition,CEEMD)、双向长短期记忆循环神经网络(bi-directional long short-term memory,BiLSTM)和随机森林(random forest regression,RFR)的组合算法的光伏预测模型。首先,利用CEEMD将光伏分解为具有不同时间尺度的分量,以体现出光伏的时间特性;然后对光伏分量与空气温度、太阳辐射度、风速、风向和空气湿度5种气象因素进行相关性分析,划分强、弱相关分量,即在光伏中体现气象因素的时间尺度;对于强相关分量采用RFR预测,而弱相关分量采用BiLSTM预测,以增加气象因素和分量之间关联;最后,由各个分量模型预测结果进行组合得到最后预测结果。
1 气象因素和光伏分量相关性
在短期光伏预测中,气象因素存在一定的时间尺度,例如,温度在几分钟内不会剧烈变化,而风速在短时间内可能会出现较大变化。传统方法直接分析气象因素和光伏序列的相关性无法体现光伏发电中的气象因素的时间尺度。而光伏发电量在分解后可得频率不同的分量,其各个分量的时间尺度和气象因素时间尺度存在相关性。考虑气象因素和各光伏分量的相关性大小,则可体现出光伏分量和气象因素的关系,对不同光伏分量筛选不同气象因素和使用不同预测模型,可提高预测精度与效果。同时能提高对气象数据的利用效率。
为判断两个变量之间密切程度,即各个分量和气象因素之间的相关程度,定义Pearson相关系数,表达式为
(1)
式(1)中:at为t时刻的气象因素数值;xt为t时刻光伏出力数值;n为采样时间点个数。相关系数R的绝对值越趋近于1,表示变量之间的相关关系越强;反之,则表示相关关系越弱。
主要考虑空气温度、太阳辐射度、风速、风向和空气湿度5种气象因素。图1为预测主要研究思路。通过对光伏序列分解,得到光伏的不同时间尺度的分量,再分析各分量与气象因素相关性,以此体现气象的时间尺度对光伏分量的影响,能最大利用气象因素数据,提高预测精度。
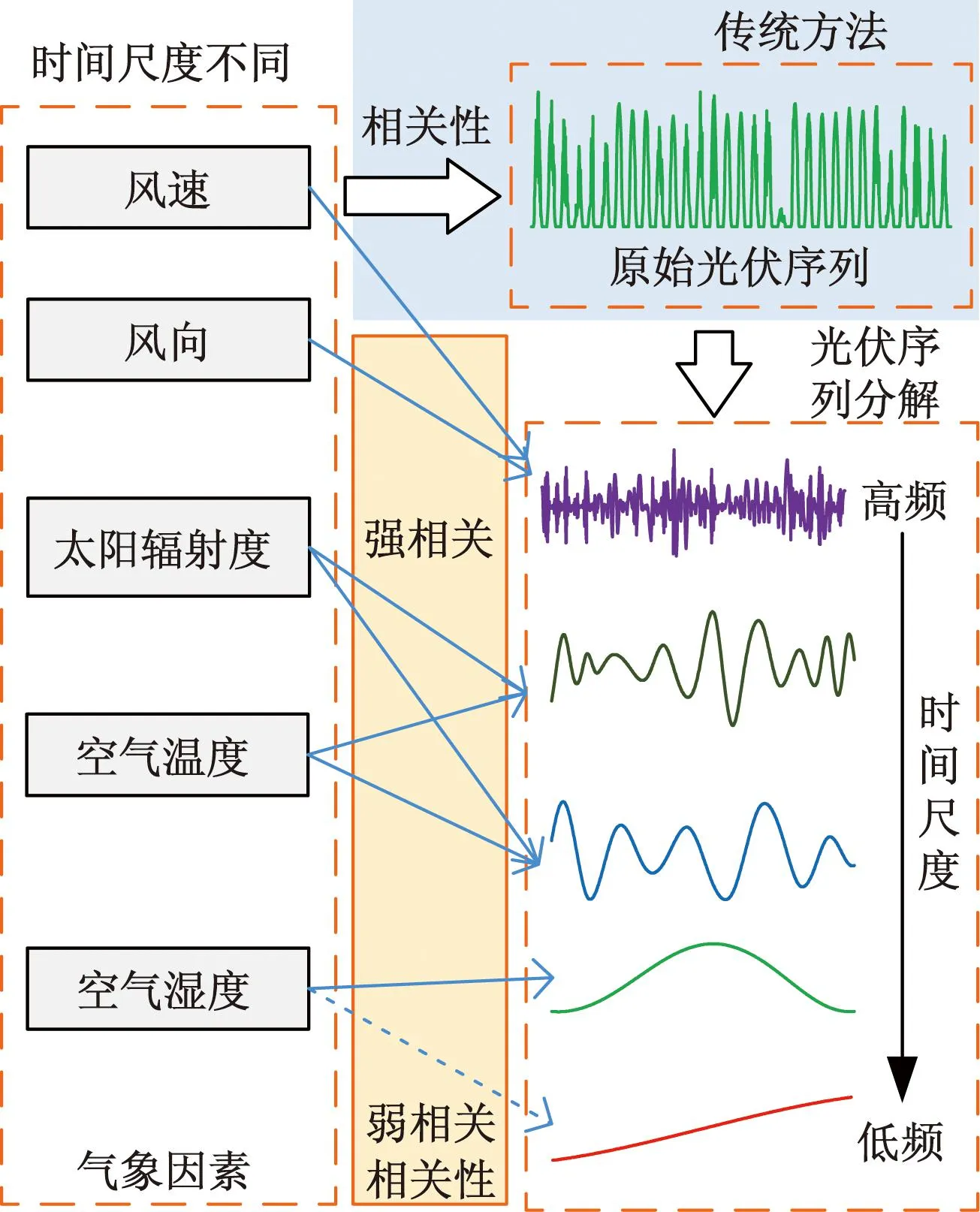
图1 预测主要研究思路
根据分量的相关性,即弱相关分量受气象因素的影响程度很小,利用光伏分量存在时间特性,采用BiLSTM模型预测。强相关分量可通过气象因素进行回归预测,由于神经网络存在对多变量预测时间较长问题,利用RFR模型预测,以提高预测速度。
2 预测模型相关理论
2.1 CEEMD分解原理
为体现光伏序列中的时间尺度,需要对其进行分解处理。EMD可实现自适应分解,相比其他分解算法无需指定分解层数和基函数。EMD[21]分解后原始序列可表示为
(2)
式(2)中:zi(t)为第i个t时刻本征模态函数(intrinsic mode function,IMF)分量;r(t)为残余分量;t为采样时刻;n为IMF的数量。但EMD由于参数设置不当,易产生模态混叠等问题。
CEEMD在原始序列加入N对正、负的白噪声,避免模态混叠现象,处理如下。
(3)
2.2 BiLSTM神经网络
由于弱相关分量不受气象因素影响,可通过光伏分量本身的时间特性进行预测。而长短时记忆网络(long short term memory,LSTM)适用于有关时间序列预测问题。LSTM结构如图2所示。

图2 LSTM神经网络结构
LSTM模型共有3个输入,分别为当前时刻状态xt、上一时刻的短期信息ht-1和上一时刻的长期信息Ct-1。LSTM门控单元状态值计算如下。
(4)
式(4)中:σ为sigmoid函数;ft、It、ot分别为t时刻遗忘门(f)状态、输入门(I)状态和输出门(o)状态;W、b分别为门控单元的权重系数和偏置系数。
得到门控单元状态后,计算长、短期信息Ct、ht状态,公式为
(5)

BiLSTM构建前、后向LSTM双层训练结构如图3所示,在时间维度上考虑到未来因素,其输出结果由前、后向LSTM决定[22],即有

图3 BiLSTM神经网络结构
Ht=concat(ht,f,ht,b)
(6)
式(6)中:Ht为BiLSTM输出;concat为矩阵拼接操作;ht,f、ht,b分别为前、后向LSTM的输出。
2.3 随机森林回归原理
利用RFR对共线性数据不敏感、算法收敛快的优点,通过气象因素对强相关分量进行预测[23]。RFR由决策树组成。
RFR从原始样本集中有放回地随机抽取训练样本,并训练得到单个弱学习器,在随机森林回归模型中该弱学习器为回归树,重复这一过程生成多棵回归树组成随机森林,并由所有树的预测值的平均值决定最终预测结果,RFR流程如图4所示。
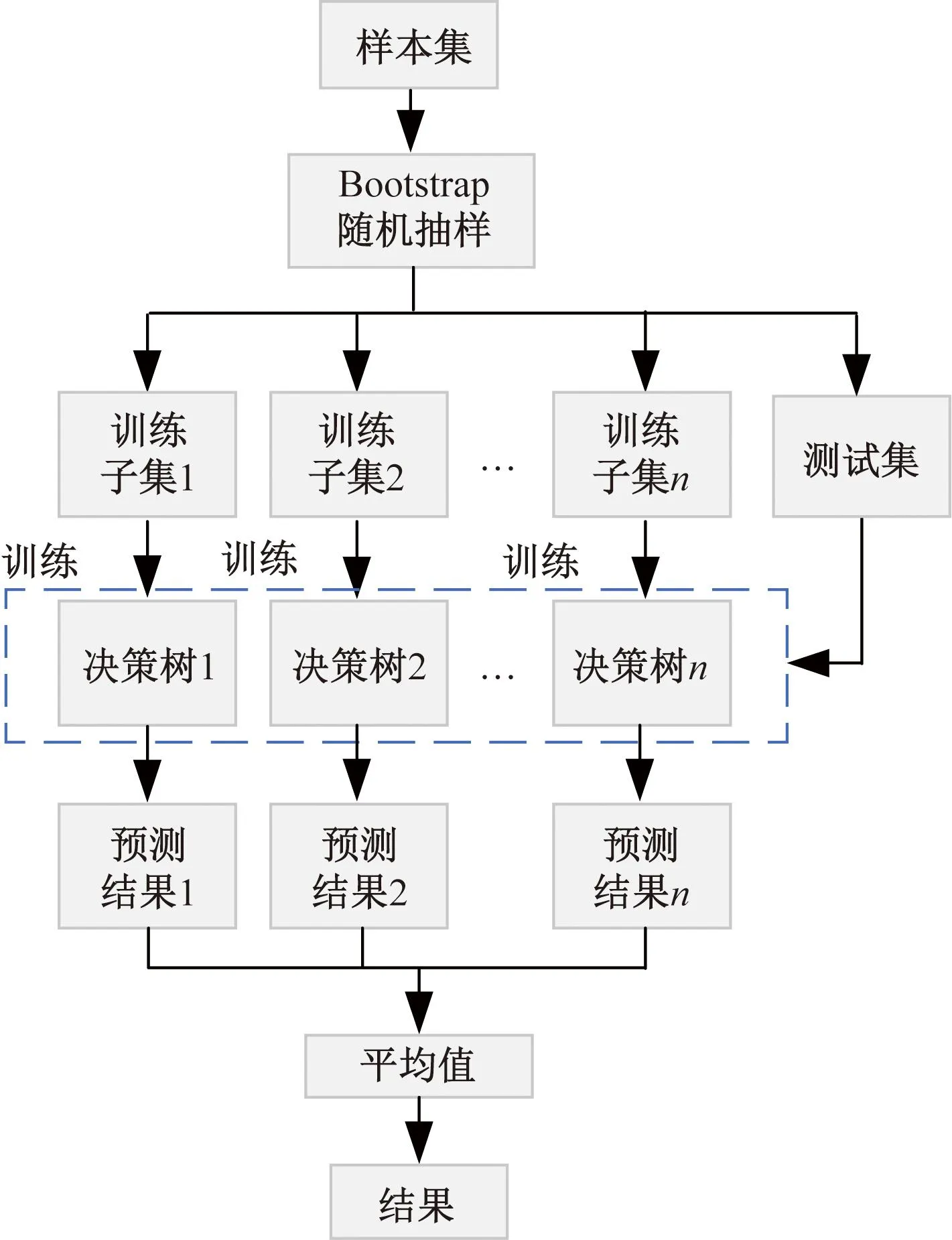
图4 RFR预测流程
生成决策树的节点误差函数为
(7)
式(7)中:Fu为节点误差函数;M为当前节点样本个数;S1、S2分别为左、右子节点的训练样本;sa1和sa2分别为左、右子节点的训练样本均值;s为当前节点。
3 CEEMD-BiLSTM-RFR预测模型
3.1 预测模型建立
CEEMD-BiLSTM-RFR预测模型如图5所示。相比传统组合预测方法,主要考虑了气象因素和光伏分量之间的相关性,分析不同时间尺度分量和空气温度、太阳辐射度、风速、风向和空气湿度的相关性,划分强、弱相关分量;根据分量特性不同所采用不同预测模型。具体步骤如下。

图5 CEEMD-BiLSTM-RFR流程
步骤1CEEMD将光伏序列分解若干个独立的分量,其体现了时间尺度。
步骤2用Pearson相关系数分析各IMF分量与气象因素之间的关系。
步骤3筛选与气象因素显著相关的强相关光伏分量,采用RFR建立预测模型;而不显著相关的分量,可通过BiLSTM进行预测。
步骤4将预测后分量相加,重构光伏序列。
3.2 数据预处理和评价指标
将原始光伏数据和气象因素进行标准化处理以消除单位差异,表达式为
(8)
式(8)中:Zt为标准化后的数据。
用归一化平均百分误差(normalized average percentage error,MAPE)、均方根误差(root-mean-square error,RMSE)、平均绝对误差(mean absolute error,MAE)和判定系数(Rsquared,RS)为评价依据,判断模型预测精度,计算公式如下。
(9)
(10)
(11)
(12)
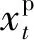
4 算例分析
4.1 算例描述
实验数据为安徽省蚌埠市光伏电站提供的2021年7月1—31日共31 d的出力数据,时间精度为30 min,共计1 488个采样点,并对数据进行脱敏处理。光伏电站环境检测仪获取的空气温度、太阳辐射度、风速、风向和空气湿度5种环境序列数据。其环境监测仪器的运行情况良好,数据来源可靠。以2021年7月1—22日数据为训练集,2021年7月23—31日数据为验证集。
短期预测的时间尺度在0~72 h,主要用来制定调度计划、预测电力市场等,对过于久远历史数据依赖性不高。文献[25-26]所述的训练数据集大小和本文数据集大小相似。
4.2 CEEMD分解与模型参数设置
设置CEEMD的噪声标准偏差为0.2,白噪声次数为50,最大迭代次数为200。分解结果如图6所示。
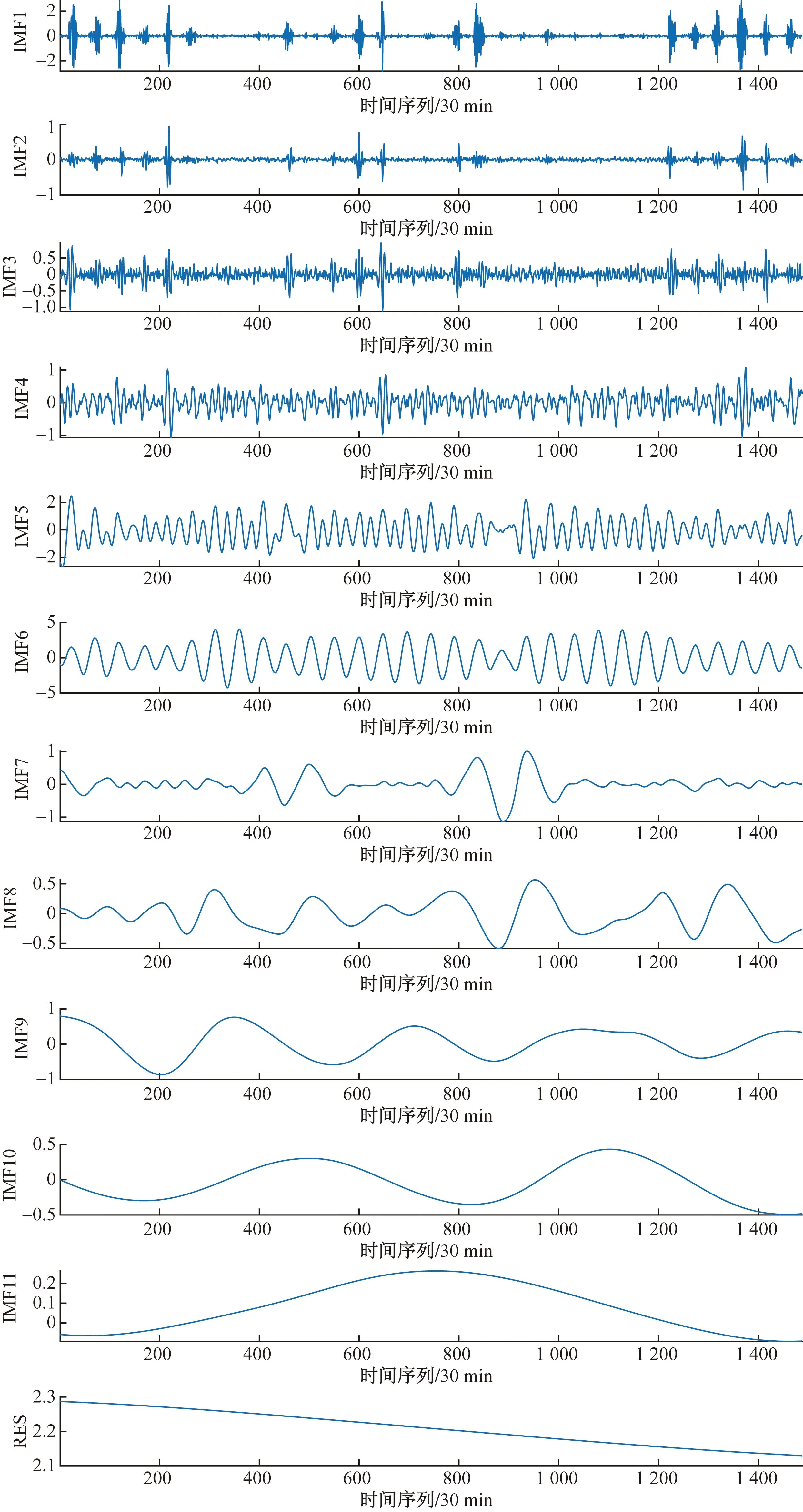
图6 CEEMD分解结果
由图6可知,光伏数据分解11个IMF分量和1个余项RES,IMF1~IMF4波动频率较高,具有很强的随机性;IMF5和IMF6呈周期波动,幅值变化较为均匀,可能与气象因素的时间尺度相吻合;IMF7~IMF11比较平滑,波动较小;余项呈下降趋势,属于长期分量。
分别计算空气温度(W1)、太阳辐射度(W2)、风速(W3)、风向(W4)和空气湿度(W5)和各个光伏分量的Pearson相关系数,如表1所示。

表1 光伏分量与气象因素Pearson相关系数
可以看出,光伏分量IMF5和IMF6和太阳辐射度、空气温度、空气湿度呈较强的正相关性,可认为IMF5和IMF6时间尺度和三种气象因素时间尺度高度相似;IMF9受风向、空气湿度影响较大;IMF10的时间尺度和风速的时间尺度存在相关性。
用随机搜索调整回归树数目、内部节点再划分所需最小样本数和叶子节点最少样本数3个参数,以避免RFR过拟合。BiLSTM主要由输入层、输出层和隐藏层决定。模型调整后参数设置如表2所示。

表2 模型参数设置
4.3 预测结果分析
为验证所提算法有效性,分别建立LSTM、BiLSTM、EMD-LSTM[27]、EMD-BiLSTM、CEEMD-BiLSTM、CEEMD-RFR和本文算法共7种模型,以晴天(7月23日)和多云(7月30日)预测结果为例,计算评价指标,结果如图7、表3、图8、表4所示。
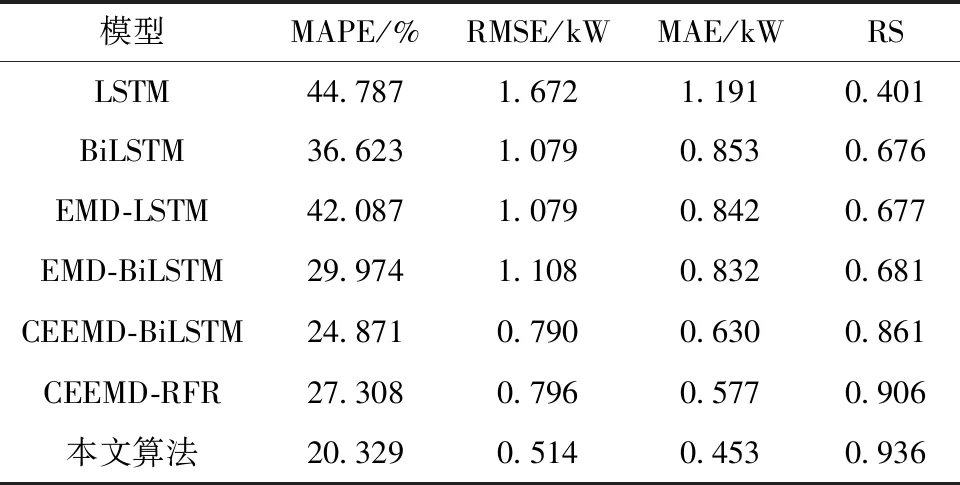
表4 多云(7月30日)不同算法预测结果指标对比

图7 晴天(7月23日)预测结果对比

图8 多云(7月30日)预测结果对比
图7为晴天(7月23日)7种模型预测结果比,7种模型都有较好的预测结果。由表3可知,EMD-LSTM相比EMD-BiLSTM的MAPE、RMSE和MAE指标降低了24.62%、0.218和0.09,RS指标提高了0.026。同时,通过对比CEEMD-BiLSTM和CEEMD-RFR指标可知,分解后采用BiLSTM比RFR预测精度要高,故所提算法中使用BiLSTM是合理且有效的。本文算法相比其他算法MAPE、RMSE和MAE指标最低,RS指标最接近于1,其预测精度较高。
图8为多云(7月30日)预测结果对比,由于为多云天,光伏出力波动较大,7种模型都存在预测误差,但本文算法拟合效果最好。由表4可知,采用单一整体预测模型(LSTM和BiLSTM)由于未充分考虑光伏随机波动性带来的影响,导致其预测精度较差。经过EMD或者CEEMD引入,分解出了光伏不同时间尺度下的分量,其预测结果都有提高。其中, CEEMD-BiLSTM相比EMD-BiLSTM的MAPE、RMSE和MAE指标降低了5.103%、0.318和0.202,RS指标提高了0.18。本文算法由于考虑到气象因素和分量之间的关系,相比CEEMD-BiLSTM的MAPE、RMSE和MAE指标降低了4.524%、0.276和0.177,RS指标提高了0.075。相比CEEMD-RFR的MAPE、RMSE和MAE指标降低了6.979%、0.282和0.124。对7种模型误差指标分析,本文算法相比其余算法,由于考虑光伏分量和气象因素的关系,对分量预测精度进一步提高,故预测效果较好。
5 结论
提出了一种基于CEEMD-BiLSTM-RFR的光伏预测方法,考虑到光伏分量和气象因素的关系,体现了气象因素的时间尺度,提高了气象数据利用效率和预测精度。结论如下。
(1)采用CEEMD方法自适应分解光伏序列,使光伏的时间尺度分解地更加清晰、明确。
(2)对所提模型与CEEMD-BiLSTM模型的对比分析,采用相关性划分强、弱分量可提高模型的精度。特别地,在多云天气,所提模型预测精度可提高18.26%。
(3)所提算法CEEMD-BiLSTM-RFR在预测精度方面要比一般的单一模型或没有深度处理的组合模型更高。
