基于深度自编码器的智能电网窃电网络攻击异常检测*
2024-03-20李金灿杨霞琴李佩李梓
黄 燕,李金灿,杨霞琴,李佩,李梓
(1.广西电网有限责任公司,广西 南宁 530023;2.广西电网有限责任公司南宁供电局,广西 南宁 530000;3.广西电网有限责任公司梧州供电局,广西 梧州 543002)
0 引言
电力盗窃不仅会使电网过载,还会对电网的稳定性和效率产生负面影响。因此提出了使用机器学习模型来识别电力盗窃[1-2]。基于机器学习的检测器包括监督分类器和异常检测器。监督分类器包括浅层机器学习分类器,如朴素贝叶斯[3]和支持向量机(SVM)[4],还有基于决策树和SVM 的两步检测器[5]。虽然上述分类器检测准确率高,但过于依赖于客户耗电数据的良性和恶意样本的可用性,只能检测到已经训练过的攻击类型。
与监督分类器既需要良性数据又需要恶意数据不同,异常检测器如单类SVM、自回归积分移动平均(ARIMA)[6]、主成分分析[7]和异常值检测[8]可以仅使用良性数据检测窃电。但由于它们呈现出静态(不包括ARIMA)和浅层结构,因此无法捕获复杂的用电模式,从而影响检测性能。因此,有必要开发只在良性负荷曲线上训练还能表现出更好检测性能的实用异常检测器。
本文提出基于长短期记忆(LSTM)的序列对序列(seq2seq)结构的深度(堆栈)自编码器。自编码器是只在良性客户数据上进行训练的无监督异常检测器,能够基于对学习到的良性模式的偏离来检测不同的窃电活动,不仅克服了恶意数据可用性有限的问题,还有助于检测未知攻击;同时自编码器的深度结构能从能源消耗数据中提取更多相关且有代表性的特征。还结合了序列到序列(seq2seq)的动态结构,以更好地理解和建模数据的时间序列性质。实验证明了所提编码器提高了检测性能。
1 窃电检测器设计
本节提出了基于数据驱动的异常检测器的设计,以识别针对智能电表的窃电网络攻击。为了提高检测性能,研究多种自编码器结构,并进行了超参数优化。
1.1 简单的自编码器结构
SAE 是最简单的异常检测器。SAE 的结构如图1所示。

图1 SAE 结构示意图
定义异常的一种有效方法是基于重构误差[9],可以使用堆栈自编码器(SAEs)来实现。在编码阶段,使用叠加的SAE 降低数据的维度,然后在解码阶段重构数据。SAE 使用良性数据进行训练,以确定将重构误差最小化的编码器和解码器参数。用H=fθ(x)表示编码器,R=gθ(x)表示解码器,其中x为XTR的 行,θ表 示SAE 参数,由下式决定:
其中,C(x,gθ(fθ(x)))表示代价函数(即均方误差(mse)),它衡量gθ(fθ(x))重构的数据与原始数据x之间不相似的程度。根据代价函数(式(1)),良性数据的重构误差会较小,异常数据的重构误差会较大。使用重构误差来表示模型对给定测试实例的熟悉程度;当超过一定阈值时,就会检测到窃电。采用以下两种SAE 结构。
(1)全连接SAE:FC-SAE 的编码器由一个输入层、一个隐含层和若干个密集隐藏层组成。解码器由若干密集隐藏层和一个输出层组成[9]。输入层有48 个神经元,以能量消耗曲线x∈XTR为输入。编码器部分的隐藏密集层将输入压缩到隐含层l′,然后通过解码器的隐藏密集层进行滤波,以重构输出。编码器和解码器的隐藏层由L层组成,每层有Nl个神经元。令表示第l-1 层神经元n′到第l层神经元n的连接权值。权重矩阵用Wl表示。定义bl n为第l层中神经元n的偏置。第l层的偏置向量用bl表示。神经元n的输入加权和为,其中al=ϕ(zl),ϕ(·)为激活函数。SAE 的训练目标是寻找满足式(1)的模型参数Wl和bl,记为θ。使用迭代梯度下降算法来最小化式(1),该算法采用随机梯度下降(SGD)实现,学习速率为η。
(2)Sequence-to-Sequence SAE:客户的能消耗曲线为时间序列数据,具有明显的时间相关性。虽然FCSAE 的计算复杂度较低,但是无法利用能耗曲线中时间相关性。因此与FC-SAE 相比,基于深度RNN 的自动编码器有望提供更好的检测性能。采用基于LSTM 的RNN 变体来解决学习过程中长时间间隔内的时间相关性的梯度消失问题。门控循环单元(GRU)可以通过使用较少的门数来缩短训练时间,LSTM 则可以牺牲训练时间来提供比GRU 更高的精度[10]。深度LSTM-SAE 模型由两个LSTM-RNN 组成,一个是深度LSTM 编码器,另一个是深度LSTM 解码器[11]。LSTM 编码器的输入是能耗曲线(x∈XTR)的时间序列,该时间序列向量被LSTM 编码器加密为隐藏状态。因此编码器的输入层后面跟着若干个隐藏的LSTM 层L,每层包含Nl个LSTM 单元。LSTM 编码器的输出作为LSTM 解码器的输入,解码器重构原始的时序数据。LSTM-SAE 的目标是最小化重构均方误差,以便得到更准确的重构时间序列数据。
1.2 变分自编码器结构
变分自编码器(VAE)结构如图2 所示。由于SAE 表示确定性映射,将其建模为对狄拉克delta 分布均值的映射。如果正常数据和异常(窃电)数据具有相同的均值但有不同的方差,SAE 模型无法准确识别出异常情况。相比之下,VAE 是一种更好的异常检测选择[1]。
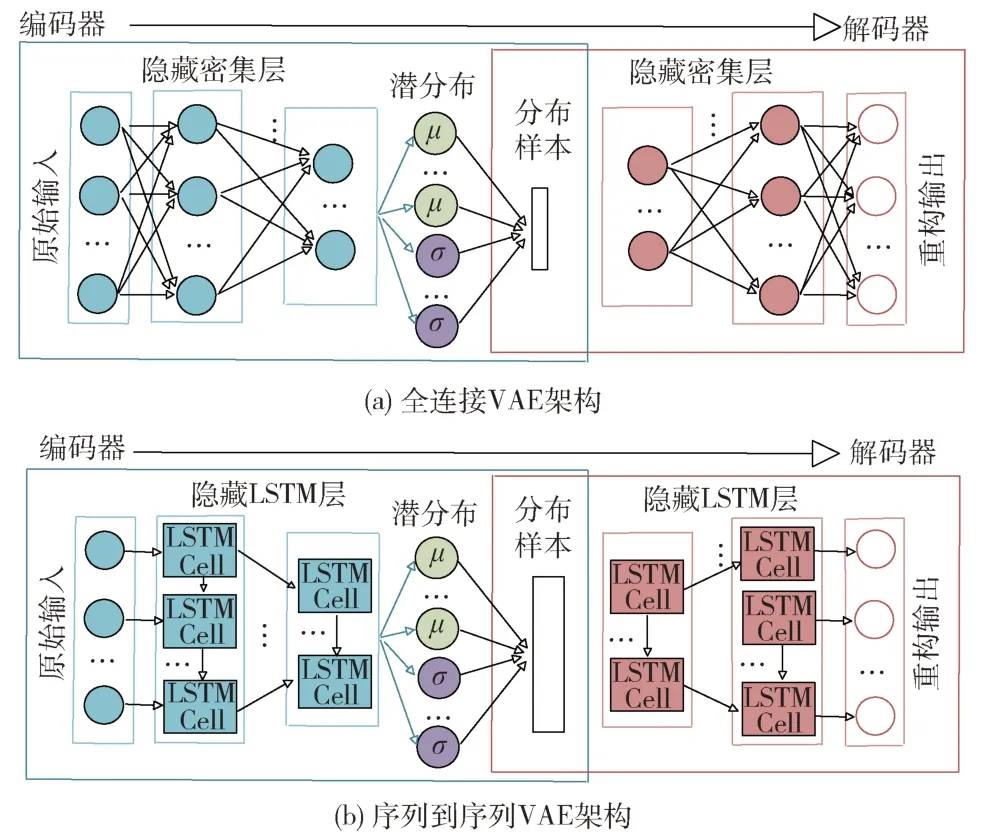
图2 VAE 结构示意图
VAEs 假设数据中的任何点x都是基于未观测到的连续随机变量k生成的。首先,通过先验分布p(k),生成一个特定的值k′。然后,基于条件分布p(x|k),生成数据实例x′。由于k的值是未知的,并且难以推断p(k|x)的精确分布,因此VAE 通过近似来逼近编码器中的p(k|x)和解码器中的p(x|k)。q(k|x)描述了真实后验分布p(k|x)的近似。对于数据点x,其对数似然是:
其中,库尔贝克-莱布勒(KL)散度用DKL表示,模型参数用θ表示,对数似然的变分下界为:
由于L(θ;x)≤logp(k),θ通过优化L(θ;x)来学习;采用重参数化技巧[1]将随机变量k~q(k|x)建模为确定性变量。k=μ+σN,其中N为均值为零、方差为零的正态分布,如果将潜变量表示为单变量高斯分布,则高斯分布的均值(μ)和方差(σ2)由编码器前向传递的激活确定[12]。p(x|k)的分布参数由解码器的前向传递激活决定。因此,VAE对数据分布参数而不是数据本身进行建模。
假设概率编码器和解码器分别服从潜在变量空间和原始输入空间的多元高斯分布。使用良性能耗数据训练的概率编码器确定输入数据分布参数。针对分布参数生成的多个样本,使用概率解码器恢复分布参数,并计算原始数据从该分布中生成的概率。所有样本的概率均值称为重构概率。由于VAE 模型参数为良性数据,异常数据的重构概率将会很低。如果重构概率低于所定义的阈值,则检测到电力盗窃。
(1)全连接VAE:全连接VAE(FC-VAE)和FC-SAE在输入层和隐藏密集层方面具有类似的结构。但是,在生成建模方面,VAE 比SAE 具有优势,因为其潜在空间以一种连续的方式使得随机采样更容易进行插值。通过产生平均值μx和方差向量来形成随机变量向量的参数,然后将其传递给解码器来实现。解码器使用μx和生成用电数据样本。为了检测窃电,计算重构概率并将其与阈值进行比较。VAE 的损失函数约束重构和正则化项为:
FC-VAE 与FC-SAE 训练算法类似,不同的是FCVAE 添加了概率分布参数(μx和σ2x)的生成以及在给定迭代梯度下降的情况下计算最优参数的计算。先使用这些生成的概率分布参数(μx和σ2x)并假设为高斯分布,然后由解码器生成输出。使用式(4)计算损失;用反向传播更新编码器和解码器的参数。
(2)Sequence-to-Sequence VAE:考虑概率编码器和解码器的LSTM 结构[13]引入LSTM-VAE。最初,LSTMVAE 用于生成语言建模应用程序的数据[14]。在本文中,将其用于异常检测。LSTM-VAE 的结构与LSTM-SAE相似,但增加了潜在分布。就逻辑而言,LSTM-SAE 和LSTM-VAE 的训练算法也是相似的,LSTM-VAE 生成μx和用于在解码器中生成样本。
1.3 具有注意力机制的自编码器架构
对于上述模型,存在输入和输出序列大小的限制,这会影响检测性能。AEA 结构如图3 所示。在SAE 和VAE 模型中,编码器的作用是检查输入的时间步,并将整个序列编码为具有固定长度的上下文向量。解码器的作用是检查输出的时间步,同时查看上下文向量。因此,这类模型的能力受到编码器生成的固定大小的内部表示的限制。AEA 模型扩展了这种架构并解决了这一局限性[14]。注意力机制通过为每个时间步分配不同的权重和分数,有助于克服传统seq2seq 网络的性能损失。

图3 AEA 结构示意图
由于AEA 模型的本质是序列性的,因此只有在添加注意力层时使用seq2seq 算法才有意义[15]。AEA 架构类似于LSTM-SAE,但增加了一个新层,即注意力层,位于编码器和解码器之间。注意力层有两个输入:编码器在时间步t处的隐藏状态和解码器在时间步长为t-1 时的隐藏状态。注意力层通过对不同时间步骤赋予权重,使得对于对于产生所需输出的贡献更大的时间步骤,赋予更高的重要性。因此,在发生窃电时,重构误差会更大。这是通过在注意力层中使用对齐评分、Softmax 和乘法运算来实现,如图4 所示。

图4 注意力层示意图
注意力层的对齐评分函数Γ是一个前馈神经网络,使用两个输入和与模型联合训练。神经网络Γ学习给重要的时间步骤赋予权重。对齐分数m是该前馈神经网络的输出,公式为:
注意力权重是对齐分数的Softmax 函数:
其中,|m|表示向量m的基数。上下文向量是编码器隐藏状态向量的加权和。
在输入通过隐藏的LSTM 层顺序处理后,将其传递到注意力层,在那里进行了上述的线性组合过程。然后,它们被传递到潜在层。最后,在循环的seq2seq LSTM 层中进行重构。AEA 的训练算法与之前算法逻辑类似,不同的是添加了注意力层。∑(cV,t,x)被馈送到解码器的隐藏层中。cV,t为上下文向量和x为重构输出。
对于以上构建的所有体系结构,在使用XTR完成训练后,应用测试数据集XTST。如果代价函数(计算SAE和AEA 的原始和重构电力消耗数据之间的均方误差或VAEs 的重构概率)大于特定阈值,则标记为Y=“1”表示恶意样本;否则,分配Y=“0”标签表示良性样本。
1.4 检测器的性能评估
为了评估所研究检测器的性能,使用多个评估指标。灵敏度(DR)使用正确识别的恶意样本计算(DR=TP/(FN+TP))。FA 使用错误标记的良性样本来计算(FA=FP/(FP+TN))。特异性(SP)表示为(SP=100-FA)。精确度(PR)是指正确识别的恶意读数占所有恶意读数的比例(PR=TP/(FP+TP))。真阳性(TP)是正确检测到的恶意样本,真阴性(TN)是正确检测到的良性样本,假阳性(FP)是错误检测的良性样本,假阴性(FN)是错误检测的恶意样本。准确率(ACC)是DR 和SP 的算术平均值。F1 分数表示DR 和PR 的调和平均值。接收器操作特征(ROC)曲线下的面积(AUC)将TP 与FP 绘制在一起。
对于每个所提的检测器,将预测标签YCAL与YTST进行比较,以构建混淆矩阵,用于计算性能评估指标的得分。为了获得异常检测器的YCAL,引入了阈值。将重构误差/概率与此阈值进行比较可区分良性和恶意样本。对于异常检测器,根据ROC 曲线的四分位间距(IQR)的中位数设置阈值。低于该阈值的数表示良性样本,高于该阈值的数表示恶意样本。
1.5 超参数优化
超参数的优化选择提高了窃电检测器的检测性能。调整了以下超参数:隐藏(密集或LSTM)层的数量(L);编码器和解码器的层数相同,每层的最优神经元数(Nl),优化器(O),丢包率(D),隐藏激活(AH),输出激活函数(AO)。采用序列网格搜索,通过对ISET 数据集的XTR进行交叉验证选择超参数。超参数最佳设置用P*表示,提高了验证集的DR。
2 实验
使用Keras 序列API 对正在研究的检测器进行训练和测试。先将所有开发的检测器(和基准)在供电公司进行离线训练,随后再对恶意样本进行实时在线检测。
2.1 基准检测器(Benchmark Detectors)
将所提出检测器与监督分类器和异常检测器的性能进行比较。监督分类器包括浅层分类器(如多类SVM和朴素贝叶斯[16])和深度分类器(如前馈和LSTM);异常检测器包括浅层单类SVM 和ARIMA。SVM、朴素贝叶斯和基于前馈的检测器是静态分类器,无法捕获能量数据的时间序列特性。ARIMA 模型是动态的,能够捕获时间序列特性,但具有浅层结构。LSTM 模型是动态的,具有深层结构,但它是一个监督模型。
2.2 阈值
为了绘制ROC 曲线并确定阈值,使用ISET 数据集的XTR进行相同的交叉验证。基准检测器和自编码器的ROC 曲线分别如图5 和图6 所示。将每条曲线分成3 个四分位数,然后取IQR 的中位数,得到的最佳阈值为:ARIMA 和单类SVM 分别为0.58 和0.45,FC-SAE 和LSTM-SAE 分别为0.58 和0.61,FC-VAE 和LSTM-VAE分别为0.43 和0.47,AEA 为0.51。图6 还绘制了其他监督基准检测器的ROC 曲线。

图5 所提自动编码器的ROC 曲线

图6 基准检测器的ROC 曲线
2.3 超参数优化
采用序列网格搜索对基准检测器和所提检测器的超参数进行优化。在浅层检测器中,朴素贝叶斯分类器的最优方差为10-9。对于ARIMA 模型,差分阶数为1,移动平均值为0。对于基于SVM 的检测器,最优的核函数和Gamma 值分别为scale 和sigmoid。对于多类SVM,最优的正则化参数为1.0。
对于深度基准检测器和所提出的自编码器,从以下范围选择最优值:对于层数L={2,3,4,5},神经元数量N={100,200,300,400,500},优化器O={SGD,Adam,Adamax,and Rmsprop},丢包率D={0,0.2,0.4,0.5},隐藏层激活函数AH={ReLU,Sigmoid,Linear,Tanh},输出层激活函数AO={Softmax,Sigmoid}。对于前 馈模型,L∗=5,=500,O∗:Adamax,D∗=0,A∗H:ReLU,A∗O:Softmax。对于LSTM 模型,L∗=4,=300,O∗:Adam,D∗=0.2,A∗H:ReLU,A∗O:Sigmoid。表1 总结了每个自编码器的优化超参数值,表明了基于LSTM 的检测器通常比基于全连接的检测器层数更少。此外,基于全连接的检测器在使用Softmax 输出激活函数时性能更好,而基于LSTM 的检测器则更适合使用Sigmoid。对于FC-SAE,4 个编码层中的神经元数量Nl为:(400,300,200,100),在解码器中则顺序相反。对于LSTM-SAE,两个编码器层中的神经元数量分别为(500,300),解码器中则顺序相反。FC-VAE 的编码器部分神经元数量为(500,400,300,100),LSTM-VAE 模型的编码器部分为(400,300),解码器中神经元数顺序相反。AEA模型的编码器内3 层神经元数量分别为(500,300,200),解码器中神经元数顺序相反。

表1 最优超参数值表
2.4 性能评估
表2 和表3 总结了使用SGCC 和ISET 数据集开发的检测器的性能。报告的性能基于完全未见过的数据(测试集),这与用于选择超参数和构建ROC 曲线的数据(验证集)不同。

表2 使用SGCC 数据集进行性能评估表

表3 使用ISET 数据集进行性能评估表
使 用SGCC 数据集 时,LSTM-SAE 将DR 提高了3%,FA 提高了2%,这是由于LSTM-SAE 可以更好地捕捉电力消耗数据的时间序列特征;当使用VAE 检测器时,VAE 能更好地捕捉用电数据中的可变性。所以可以观察到VAE 检测器将DR 提高了4%~7%,FA 提高了3%~5%,进一步提高了窃电性能。
相对于全连接模型,基于LSTM 的模型在DR 和FA方面将检测性能提高了3%。相对于VAE 模型,AEA 进一步提高了DR 和FA,分别提高了3%~6% 和2%~5%。相对于SAE 模型,AEA 在DR 和FA 方面分别提供了高达10%~13%和8%~10%的改进。这些结果表明,与全连接模型相比,基于LSTM 的模型增强了检测性能。基于AEA 的检测器提供了最佳的检测性能。与基准检测器相 比,AEA 将DR 和FA 分别提高了4%~21% 和3.5%~12%。
使 用ISET 数据集 时,LSTM-SAE 模型比FC-SAE 模型的DR 高了4%,FA 高了2%。而VAE 检测器又比SAE模型的DR、FA 分别高了3%~7%、2%~4%。与完全连接模型相比,基于LSTM 的模型在DR 和FA 方面的检测性能分别提高了3%、4%。AEA 模型比VAE 模型的DR、FA 分别提高了3%~6%、2%~6%;比SAE 模型的DR、FA分别提高了9%~13%、8%~10%。与基准检测器相比,AEA 检测器将DR、FA 分别提高了3%~21%、3%~13%。这表明AEA 模型的深层和循环结构提供了优越的性能。
表4 给出了在不同大小的ISET 数据集上训练所提出的检测器所需的时间,其中|XTR|大小为6 000 万,|·|表示基数。从表4 可以看出,AEA 需要的时间最长为3 h。所有开发的检测器的在线测试需要1 s~2 s 来报告决策。

表4 使用ISET 数据集计算的复杂度
表5 显示了在6 个不同攻击函数上单独测试时所提出的自动编码器的DR 和FA。模型仅使用ISET 数据集中的良性样本上进行训练,使用上文中讨论的最优超参数和阈值进行训练,而不使用ADASYN,因为数据已经平衡。从结果可以看出,使用图5 得到的阈值,在多次实验中可以得到一致的结果。虽然DR 随攻击复杂性的不同而变化,但平均值仍然与表3 中的结果一致。
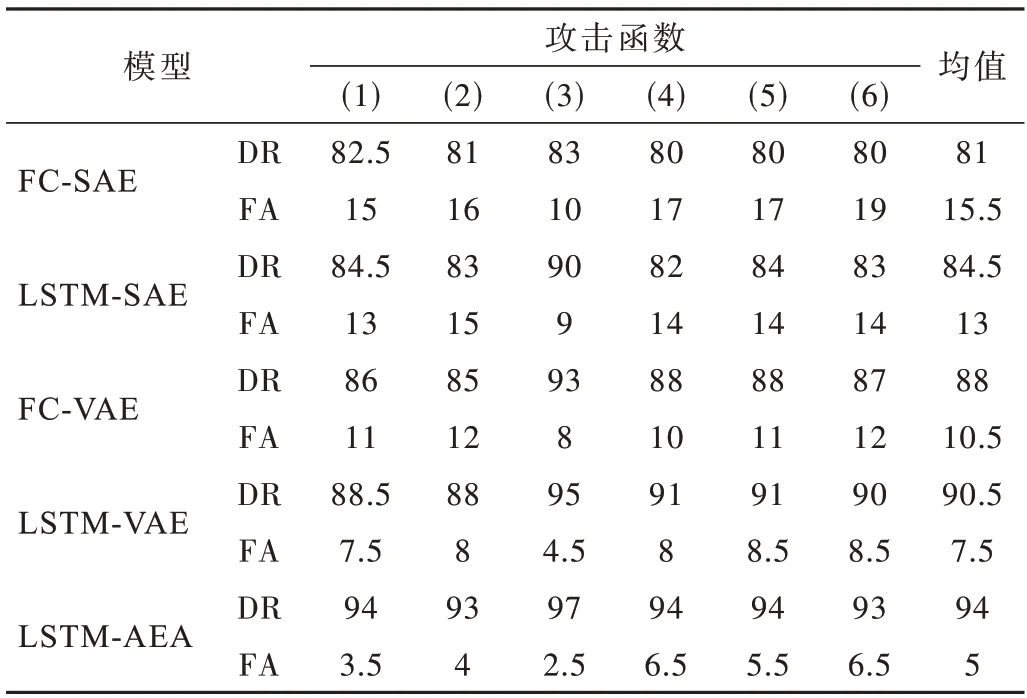
表5 针对各攻击的性能评估
3 结论
本文提出了多个深度自编码器异常检测器用于窃电检测,克服了恶意用电数据样本有限的问题。深层结构相对于浅层检测器,可以提供更好的检测性能;基于循环LSTM 的结构与静态的全连接检测器相比能提高检测性能。实验结果表明,当使用深层和周期性异常检测器时,与浅层和静态结构相比,性能有了显著的改进。其中LSTM-AEA 表现出最佳的检测性能,在DR 和FA 方面分别提高了4%~21%和4%~13%。
