基于Spring Cloud 的分布式医疗数据平台建设
2024-03-20胡珊珊陈敏莲
汪 睿,胡珊珊,陈敏莲,徐 骁
(湖南省儿童医院数据信息管理中心,湖南长沙 410007)
0 引言
伴随互联网技术的进一步发展,海量数据和多源异构数据不断增加,大数据时代已经来临,其中在医疗领域更是如此。在医疗领域中,医疗数据来自多种来源,如电子档案、生物特征数据、门诊登记、住院记录、患者报告、B 超和CT 图片等。以数字方式收集和存储的数据量呈指数级增长,数据类型也逐渐变得复杂多样。
医疗数据通常具有半结构化、高数据量、数据格式复杂、不完整、更新速度快等特点。因此,传统的信息技术无法有效处理海量的医疗数据,同时也因为缺少相应的规范,海量的医疗数据也处于不同的系统或者平台之中,彼此互不联通,难以挖掘和使用[1]。
针对这些现状,在整个医疗行业中,医疗大数据的研究与应用已经越来越多,各类机器学习与人工智能算法在医疗领域被广泛的使用和研究,这些研究与应用明显改善了医疗实践与患者护理,同时也优化了医疗流程。然而复杂的疾病也使得临床数据变得多样,不同医疗系统里面的数据也呈现出无法联通的景象,特别是一些非结构化数据,更是加强了医疗数据挖掘和分析的难度。而在大数据方面,具体技术落地较少,大部分还停留在理论和概念阶段,阻碍了医疗大数据的潜在价值的发挥与挖掘。因此,医疗数据方向的研究与应用仍然是一个具有挑战性的课题。
在大数据时代,海量的数据使得传统信息化平台在各个领域不再适用,而繁杂的数据格式和内容也使得经典的关系型数据库在数据存储和检索方面捉襟见肘。因此,为了解决医疗大数据的可靠存储问题,有效的处理多源异构数据,加强医疗数据的检索能力,充分发挥大数据时代医疗信息化的潜力,提出了一种基于Spring Cloud 的分布式医疗数据平台建设方案,该方案通过Spring Cloud 技术来构建分布式架构,选取MongoDB 非关系型数据库作为分布式存储,同时对数据进行标准化、分词等操作,从而实现一个异构数据可存储、系统高可用、规模易扩展、检索高效率的医疗数据平台。
1 技术选型设计
1.1 Spring Cloud
Spring Cloud 是一系列框架的有序集合,是在Spring Boot 基础上的分布式系统开发。Spring Cloud 将经过验证的、成熟的组件或框架整合起来,进行再封装,屏蔽其内部复杂的实现和配置,最终形成一套易开发、易部署的开发工具。其中常用的功能模块有链路追踪、服务注册与发现、服务路由、服务网关等,这些功能模块的实现大都是整合优秀的开源组件,如feign 组件用于服务间调用;ribbon 组件用于负载均衡;config 组件用作配置中心;zuul 组件用作服务网关等[2]。此外,Spring Cloud 本身就是分布式架构的集大成者,在进行分布式应用开发时,具有相当大的便利,并且Spring Cloud具有约定优于配置的特性,可以基于注解来开发。同时,对大量的组件进行了封装,简化了开发难度,使组件与组件之间,具有强解耦性,从而在开发时更加灵活,可以实现尽可能轻量的系统而又能最大限度的满足实际需求的开发。
在分布式医疗数据平台开发中,使用Eureka 来进行服务注册与发现,使用Ribbon 来负责其中的负载均衡,使用Feign 进行声明式服务调用,添加Config 来实现应用配置的外部化存储,使用Zuul 来组成平台网关,进行访问过滤等操作,最终形成基于Spring Cloud的分布式医疗数据平台框架(图1)。
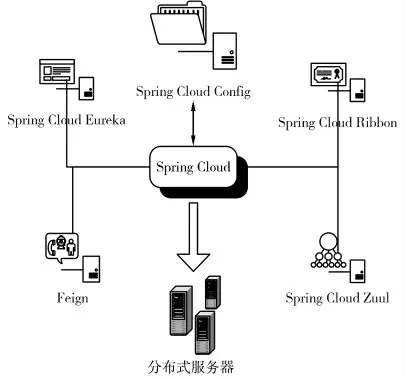
图1 分布式医疗数据平台技术框架
1.2 MongoDB
MongoDB,是当前Web 应用的高性能数据存储的主流存储数据库,MongoDB 在设计之初就具有分布式的特性,其内核是分布式文件存储。MongoDB 在非关系型数据库中,功能较为丰富,采用的bson 数据存储结构,是一种二进制形式,这是一种类似json 的格式,支持文档对象和数组对象,具有高效、轻量、可遍历等特点,针对于结构化数据或者非结构化数据都有着良好的描述效果。相对比于json 而言,bson 有着更快的遍历速度、更简单的操作和额外数据存储类型。面向对象思想在MongoDB 中得以体现,将每一个记录当做文档对象,以此来存储数据。同时,为了提高数据检索性能,MongoDB 是采取的内存映射文件的方式进行管理。此外,MongoDB 支持复制集、主从复制、自动分片、故障恢复等特性。其中,前两者可以保证系统的可靠性,实现服务器自治,自动分片可以有效的实现数据库的水平扩展,且这种扩展并不会影响到其他服务器[3]。因此,MongoDB 这些优秀的特性,使得它成为了当前Web 应用可扩展的高性能数据存储解决方案[4]。MongoDB 集群模式如图2 所示。

图2 MongoDB 集群模式
1.3 中文分词
在数据进行有效存储之后,接下来就是检索数据,发挥数据的价值。而在数据检索的过程中,为了提高检索的效率,通常会对文本内容进行分词,得到关键词组,从而提高检索效率。然而,市场上常用的分词是英文单词分词,与实际应用中的中文分词有一定的差别,实际检索效果也有很大的区别。因此,在综合考虑现有成熟的分词引擎之后,选取使用JieBa 分词库进行中文分词,以此来取得良好的数据检索效果,从而实现具有高效率检索的医疗数据平台。
JieBa 分词是一个中文自然语言处理的分词库,是属于概率语言模型分词,其中,常用3 种分词模式:全模式:快速的扫描成词的词语;精确模式:尝试精确地切开语句,可进行文本分析;搜索引擎模式:对长词进行再次切分,提高召回率。
选用搜索引擎模式,并且选用内置的TF-IDF进行关键词抽取,先将医疗数据使用JieBa 分词进行关键词抽取,并进行切分,获取处理后的词组集合。再构建一份停用词表,对处理后的词组集合,去除停用词,最后得到被检索的关键词,以此来提高检索效率。
2 平台建设方案
2.1 总体架构
在综合考虑使用便利性、稳定性、兼容性等方面后,基于Spring Cloud 的分布式医疗数据平台采用的是BS架构。相对比于CS 架构,BS 架构可以很方便地适配到各个不同系统,同时在前端页面上,也能针对性地做好优化,保证用户在各个终端之间所见的一致性。此外,BS 架构的设计模式,可以有效的兼容移动端的使用,为以后数据平台的使用范围扩展提供良好的基础。同时,业务扩展更方便简单,可以通过浏览器随时随地地进行浏览、查询等业务。
基于Spring Cloud 的分布式医疗数据平台,主要分为5 个模块,前端显示模块用于显示数据到网页上,与用户进行交互;服务注册与发现模块用于注册服务端,并将新增加的服务端暴露给其他调用者;配置模块用于放置平台所有相关的配置,包括一些需要经常改动的数据;网关模块用于将访问请求进行过滤,并加入负载均衡功能,将访问请求合理的分配给相应的服务端;数据提取模块用于将不同医疗数据提取并进行处理,再将数据存入数据库。基于Spring Cloud 的分布式医疗数据平台总体架构如图3 所示。

图3 分布式医疗数据平台总体架构
2.2 平台功能
基于Spring Cloud 的分布式医疗数据平台为用户提供医疗数据存储与检索功能,推行线上医疗和线下医疗相结合的模式,可以有效减轻医护人员的工作量,加强医护人员的工作效率。在具体应用方面,主要包括基础业务系统数据、关键词、异构数据源、数据检索4 个模块。
2.2.1 基础业务系统数据
基础业务系统数据模块主要对医疗基础业务系统数据的抽取,这是医疗数据平台的数据来源,也是对数据处理的第一步,常抽取的是4 大医疗基础系统:His(医院信息系统)、Lis(检验科系统)、Pacs(影像科系统)、EMR(电子病历系统),在业务系统数据抽取之后,进行数据的预处理和关键词提取。
2.2.2 关键词
关键词模块在上一步的基础上进行,主要是对所有存入数据库的数据进行关键词提取,先把基础业务系统数据进行标准化,将不同结构的系统数据,以统一的规范进行整理,各自不同的信息以json 串的形式存入文档,然后进行中文分词,选用JieBa 分词的搜索引擎模式,并用TF-IDF 进行关键词抽取。
2.2.3 异构数据源
异构数据源模块是将各个不同来源的数据存入MongoDB 中,主要的非结构化数据包括语音、视频等数据。在异构数据源模块,开放对外接口,统一接口入参,保证不同数据源能够简易接入医疗数据平台,并对处理后的数据进行校验,避免缺损数据和无意义数据存入数据库中。
2.2.4 数据检索
数据检索模块主要是对各个存入的数据进行检索,这里使用MongoDB 自带的查询功能,配合Spring Cloud分布式架构,保证能处理大量的并发请求,并且能取得良好的检索性能,同时在内存足够的情况,将数据放入内存,有着完整的索引支持,能取得更加迅速的检索效果。
3 结束语
对大数据情况下的医疗数据平台建设,进行了一定的研究,综合当前医疗数据的现状,提出了基于Spring Cloud 的分布式医疗数据平台的建设,该平台可以处理大量医疗数据的存储问题,有效解决异构数据的持久化问题,同时通过标准化、分词操作,再搭配MongoDB 的优秀的检索性能,形成一个异构数据可存储、系统高可用、规模易扩展、检索高效率的医疗数据平台。但医疗数据平台也出现了一些问题,比如检索性能依赖于硬件,相较于专门的检索数据库,MongoDB的数据检索有待提高;异构数据虽然得以有效存储,但是却无法有效使用,无法挖掘和分析出数据的价值,这些问题需要进一步的研究和完善。
