基于属性意义的约简及其在驾驶行为中的应用
2024-03-20孙乾智
孙乾智
(西南石油大学 计算机科学学院,四川 成都 610500)
0 引言
属性约简是粗糙集和粒子计算中一项重要的应用,现实中很多数据集存在大量的冗余属性,这些属性不仅增加了分类训练的计算量,而且还降低了分类性能,属性约简的目的就是消除冗余属性。目前,学者们提出大量如下的属性约简方法。
何海琦等[1]运用邻域粗糙集构造了属性约简算法。Dai等[2]基于信息系统信息粒化的熵理论提出了相应的属性约简。Lin等[3]运用邻域粗糙集中的邻域粒化构造了数值属性约简。Zhang等[4]基于模糊粗糙集模型提出了高效的属性约简。Ma等[5]运用决策粗糙集理论提出了保持决策区域的近似约简。在增量式学习中,Jing等[6]提出了多种增量式属性约简方法。在并行计算领域中,Chen等[7]提出了相应的并行属性约简算法,这些算法的不断提出,使得关于属性约简的研究不断趋于完善。陈毅宁等[8]根据距离比值尺度,进行属性约简。
近年来,段詠程等[9]通过粗糙集理论确定数据集中每个属性的重要性, 用随机森林算法对重要程度低的属性进行约简, 删除冗余属性,虽然实验结果在精度上有所提升,但在删除冗余属性时忽略了每个属性的实际意义。例如:在葡萄酒数据研究中,酒精和葡萄酸等化合物是影响葡萄酒口感的直接属性,虽然颜色对口感的影响很低,但是酒的颜色同样是消费者关注的属性,所以在做属性约简时如果直接忽略了颜色对酒的影响,虽然也能提升口感分类精度,但却失去了现实消费意义,颜色单属性所占精度如下:原花色度14%,颜色强度26%,色调18%。
与段詠程等[9]直接删除冗余属性不同,本文为寻找具有实际意义、低权重属性之间的隐藏关系,提出一种改进的属性约简方法,通过随机森林算法对属性进行权重分析,再利用因子分析方法将权重低的属性进行挖掘,从而找到和低属性存在的隐含关系,再使用SVM算法将同类别权重低的属性进行融合,将存在隐含关系的属性分别提取出来。利用SVM算法能够理解特征的相互作用,分别对每组提取出来的属性进行分类训练,得到一个新的分类结果,将这个结果定义为存在隐含关系属性融合后的新属性,最后将属性融合后的数据集用随机森林分类器进行分类训练,本文方法实现了在考虑所有属性权重和现实意义的前提下对数据进行分类训练。
本文使用UCI公共数据集中的葡萄酒以及公园大火数据集进行训练,驾驶行为数据集为四川某汽车公司所采集的真实数据。实验结果表明,新的属性约简算法在保留属性意义的同时,分类结果更精确。
1 相关算法介绍
1.1 属性约简
属性约简是从属性集合中挑选出所需要元素的过程,通过对数据集降维、删除重复多余元素,选择关键元素。由于数据来源不同、数据量庞大且数据类型多等特点,因此对大数据集进行降低数据维度、减少重复多余属性、提取关键属性成为属性约简的重要过程。当前属性约简的方法有主成分分析法、奇异值分解法和粗糙集等,其中使用最多的是粗糙集方法。粗糙集方法具有强大的学习能力和无需任何先验知识,避免了部分重要信息的损失,且不会改变原始数据的决策信息。
1.2 随机森林
随机森林是指使用随机的方式建立一个森林,森林里有很多决策树,决策树之间相互独立,没有关联。随机森林建成后,如果有一个新的样本进入森林,森林里所有决策树都会判断这个新样本属于哪一类,判断是哪一类被选择得最多,也就是受影响的是哪一类。最后,就可以得到一个预测值,确定这个样本是属于哪一类的。随机森林构造过程如图1所示[10]。

图1 随机森林构造过程
随机森林算法的优点:随机森林算法可以处理高维度数据,不用特征选取;可以判断特征的重要程度;可以判断不同特征之间的相互影响;不容易过拟合;训练速度比较快,容易做成并行方法;实现起来简单;对于不平衡的数据而言,它可以平衡误差;如果有很大一部分的特征遗失,仍可以维持准确度。
随机森林算法的缺点:随机森林算法已被证明,在噪声较大的分类或回归问题上会过拟合;对于不同取值的属性数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值不可信。
1.3 支持向量机算法
支持向量机(Support Vector Machine,SVM)算法一种基于统计学习理论(Statistical Learning Theory,SLT)的分类方法。基于统计学习理论中的结构风险最小化原理和维数理论,通过核函数将输入样本从原始空间映射到高维特征空间,并在高维特征空间中构造最优分类超平面。它具有学习能力强、选择参数少、泛化能力强、拟合精度高、训练时间短、全局最优等优点,为解决小样本、高维、非线性问题提供了一个有效的工具,并可推广到其他机器学习问题,如函数拟合等。
SVM是基于模式识别方法和统计学习理论的一种全新分类技术,主要用于模式识别领域。1963年,ATE-T Bell实验室研究小组在Vanpik的领导下,首次提出支持向量机理论方法。这种方法是从样本集中选择一种样本,对整个样本集的划分可以等同于这组样本的划分,这组样本子集被形象地称为支持向量。但是当时,SVM在数学上并不能被明晰地表示,人们对模式识别问题的研究并不完善,因此SVM的研究没有得到进一步的发展与重视。
1971年,Kimeldorf提出使用线性不等约束来重新构造SVM核空间,使得一些线性不可分的问题得到了解决。
20世纪90年代,形成了一个比较完善的理论体系——统计理论。此时,一些新的机器学习方法遇到了一些新的困难,如神经网络的欠学习和过度学习,如何确定网络结构。局部极小问题在求解中表现出许多独特的优势,可以推广到函数等其他机器学习问题上[11]。
SVM算法的优点:SVM算法可解决大型空间特征的高维问题;能够理解特征的相互作用;无需依赖整个数据;可以提高泛化能力。
SVM算法的缺点:当观测样本很多时,SVM算法效率并不高;对非线性问题,没有通用的解决方案,有时很难找到一个合适的核函数;在噪声过多的情况下,SVM很容易过拟合。
1.4 因子分析
从量表的全部变量中提取一些公因子,各公因子代表量表的各个基本结构,分别与一群特定的变量表的结构进行关联,这是因子分析的主要功能,也被认为是获得观察变量(Observed Variable)背后潜在变量(Latent Variable)的最典型方法和最有效的效度分析手段。
找出不可预测的潜在变量作为公共因子、用不可观测的随机变量来计算可观测的随机变量,是因子分析研究的主要目的。它的主要工作是分解,将可观测的变量进行分解,即分解为特殊因子、公共因子和误差3个部分[12]。
2 改进属性约简算法
本文提出一种基于实际意义低权重属性融合的属性约简方法,权重比界限根据多次实验给定,在多次试验中,单分类精度最低为70%,例如在葡萄酒口感分类实验中,酒精在不同测试集与实验集比例下,最低分类结果为71%,在驾驶行为分类实验中速度在不同测试集与实验集比例下,最低分类结果为73%,故选取70%为权重分类界限,具体流程如图2所示。

图2 算法流程
因为随机森林算法在有很大特征遗失的情况下,仍可以维持准确度,所以,选择随机森林算法对所有属性进行权重分析,可以得到每个属性的单独权重。
根据之前的分析,很多数据集都存在属性权重占比低、但具有实际意义,却被直接删除这些属性,使得分类结果存在误差的问题。针对这一问题,本文提出一种寻找属性之间隐含关系的方法,通过挖掘属性之间存在的隐含关系来变相保留这些属性的实际意义。
2.1 寻找属性之间的隐藏关系
属性之间的隐含关系往往不能够直接被观察出来,本文利用因子分析方法挖掘属性之间的隐含关系,具体过程以人的受欢迎程度为例,长相是影响受欢迎程度的主要原因,这是一个二维数据,如表1所示。

表1 二维数据
但这样的结论描述不够详细,需要加入更多的属性,这里加入7条属性来描述,如表2所示。

表2 多维数据
随着属性的增加,可以描述得更加清晰,但是却不能像之前那样很容易地知道每个人受喜欢的程度,因此需要用到属性约简,来更加清楚地识别每个人的受欢迎程度。由于上面的每个属性都是评价人的具有实际意义的属于不能删除的属性,所以需要寻找属性之间存在的隐含关系,通过因子分析方法得到属性之间如下的隐含关系,如表3所示。
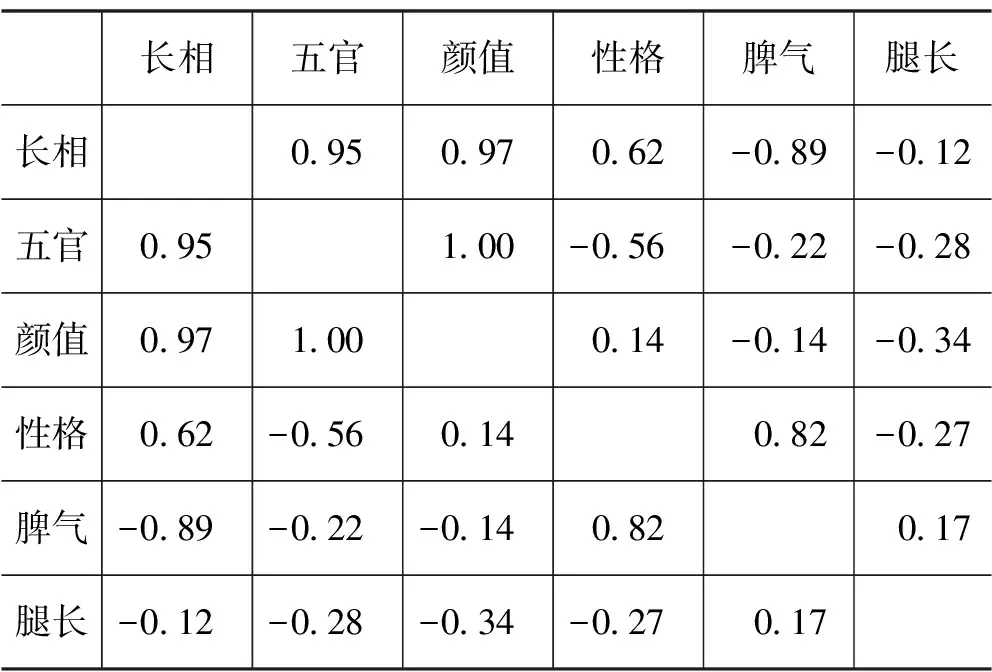
表3 属性隐含关系
通过寻找变量之间的相关性,2个变量之间协同变化。通过这种方法,就可以找到属性之间存在的隐含关系。
2.2 SVM融合法
通过以上方法,找到了存在隐含关系的属性。本文通过SVM算法,将这些属性进行融合。融合后的新属性,既可对数据集的属性进行约简,又可以保留数据集属性的所有含义。
SVM算法的优点是能够理解特征的相互作用;无需依赖整个数据。这样只需要几个单独的属性就可以对数据集进行很全面的分类。将隐含关系的属性分组,然后将每组属性分别通过SVM算法进行分类训练,这样每组属性都会得到一个新的值,这个值就是这组属性融合后的新属性,这样既能对数据进行属性约简,降低维度,又可以保留属性的意义。
根据上一节分析可以得知,{长相、五官、颜值}为一组,{脾气、性格}为一组,{腿长、身高}为一组,将每组属性通过SVM算法进行训练会得到一个新的分类结果,得到的这个结果就是每个组的新属性,如表4所示。
2.3 分类训练
具体分类训练步骤如下。
Step1 输入数据;
Step2 通过随机森林算法对每个属性进行分类,得到每个属性的精确度;
Step3 对属性进行因子分析,找出同类型的属性;
Step4 找出权重占比低且同类别的属性;
Step5 通过SVM算法,将找出的属性进行融合从而得到属性约简;
Step6 更新数据,得到新的数据集;
Step7 通过随机森林算法对新的数据集进行分类;
Step8 得到新的分类结果。
3 实验
本文实验环境为Microsoft Windows 10,2.9 GHz Intel Core i5,8 G RAM,使用SVM算法、随机森林算法以及因子分析方法,验证数据集为UCI公共数据集中的葡萄酒数据集和公园大火数据集,实验数据集为四川某汽车公司所记录数据。将本文方法分别与传统随机森林算法、SVM算法以及段詠程等[9]基于RSAR的随机森林属性约简方法进行对比。
3.1 数据预处理
(1)筛选样本的过程中发现,有些车辆全程GPS速度都为0,本文研究驾驶行为特征的识别,这样的样本无法作为研究目标,所以删除这样的样本。
(2)通过研究分析明确所需要的指标,基于准确、有效、易量化的原则对数据中的指标进行筛选。最终保留的指标为速度Sp、经度Lat、维度Lng、开始时间ST、结束时间ET、持续时间DT、事件类型Alarm。
驾驶行为数据是通过GPS收集来的数据,数据庞大且存在噪声,表5为处理后的部分数据片段。{28-超速、30-空挡滑行、4-点火、27-怠速、7-急刹车、302-异常怠速、27-空挡滑行、301-紧急事件、5-熄火、6-转速过高、41-急加速}[13-14]。

表5 驾驶行为数据片段
3.2 实验分析
采用SVM算法、随机森林算法、段詠程等[9]的方法以及本文提出的算法分别对驾驶行为数据集进行分类得到实验结果如表6所示。

表6 驾驶行为结果
实验结果表明,本文方法在考虑属性实际意义的情况下,驾驶行为分类精度相较于传统随机森林算法和SVM算法分别提升了6%和8%,相较于段詠程等[9]的方法提升了2%。
为了进一步验证本文算法的有效性, 从UCI数据集中选取了葡萄酒数据集和公园大火数据集,实验结果如表7—8所示。
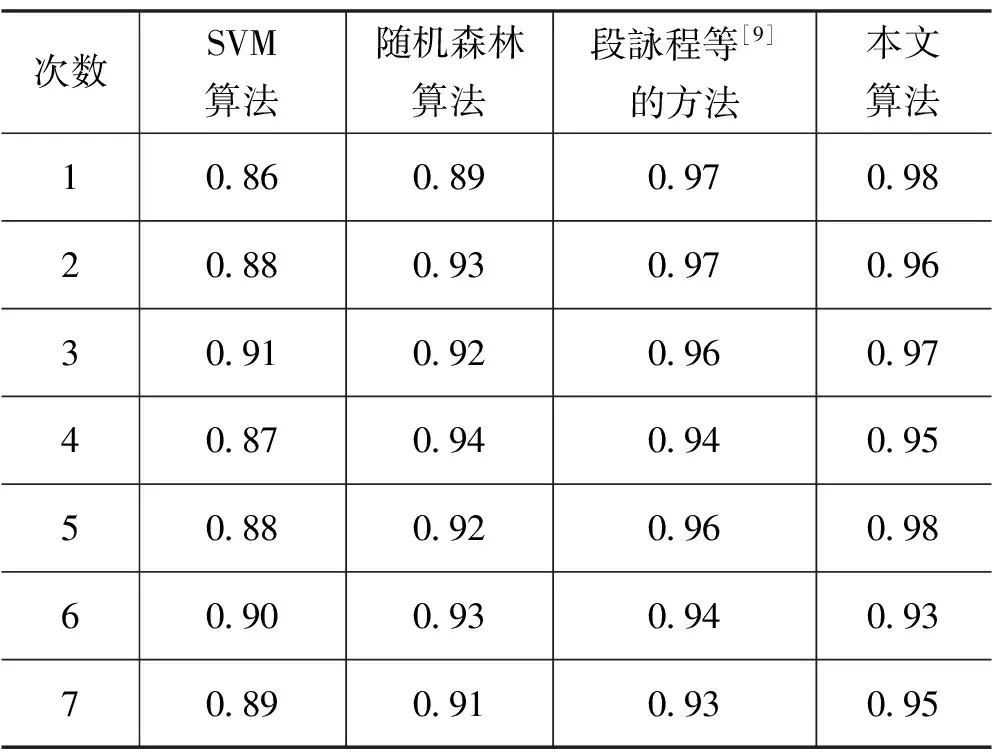
表7 葡萄酒结果
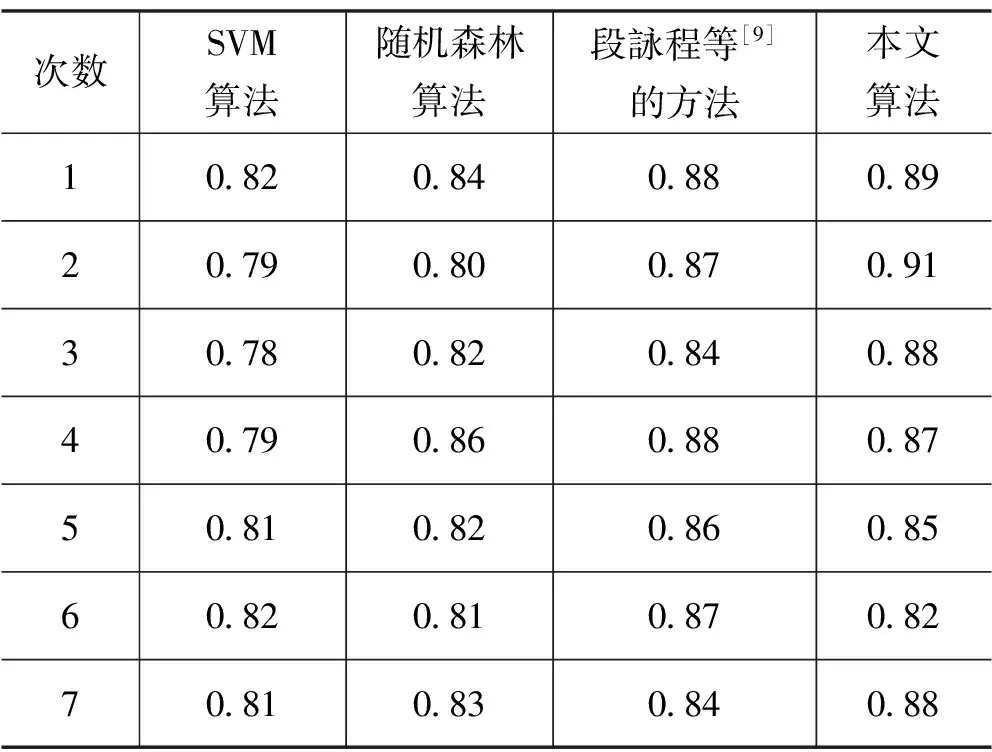
表8 公园大火结果
实验结果表明,本文方法在考虑属性实际意义的情况下,葡萄酒数据集和公园大火数据集分类精度相较于传统随机森林算法和SVM算法分别提升了4%和7%,相较于段詠程等[9]的方法提升了3%。
4 结语
本文算法主要是考虑每个属性的实际意义来进行属性约简,从而减少权重较低的属性对分类结果的影响,得到更加精确的分类结果。通过对比,对属性进行约简得到的结果比约简之前得到的结果更佳。与不考虑实际意义的属性约简算法相比,实验结果有所提升,在保证分类精度的前提下更有实际意义。
