一种用于农产品供应链风险预测评估的贝叶斯决策树算法模型
2024-03-18徐爽蔡鸿明赵林畅徐永驰
徐爽,蔡鸿明,赵林畅,徐永驰
1.贵阳学院 经管学院,贵阳 550005;2.上海交通大学 软件学院,上海 201100;3.贵阳学院 数信学院,贵阳 550005;4.贵阳学院 电通学院,贵阳 550005
供应链的概念出现在20世纪下半叶,当时的消费品制造商、生产商和销售商之间的合作得到了发展.21世纪世界经济的全球化导致世界各地的联系和服务范围扩大.商品和服务的自由流动使得各国经济突飞猛涨,主要表现在许多国家的国内生产总值增加,国民生活质量的提高和消费的增加,从而刺激了良好的经济增长.供应链对于经济的平稳运行至关重要[1].在现代经济体系中,供应链发挥着重要的作用,是衡量现代经济发展水平的一个重要指标.供应链中任何故障都会导致不利经济的现象,例如交付货物的技术质量下降、延迟或错过交付.任何制约因素都会限制供应链,导致生产和分销订单的执行延迟和中断.而供应链中断则会导致关键商品短缺、价格上涨、工厂关闭、集装箱卸载等负面影响.它们还影响着各种各样的产品,从汽车和电子产品等昂贵商品到食品、药品、石油和天然气等必需品,这些都会对生活成本产生影响.如果供应链不间断,同时原材料、组件、零件和其他配件的供应发展良好且顺畅,最终产品的生产就会顺利进行.什么时候会发生供应链中断?如果政治、经济和社会形势等外部条件稳定,供应链中断可能只是由于资金流动的损失或相对于供应的过度需求而导致链要素枯竭造成的.不稳定的经济状况,以及政治、社会和金融动荡,可能导致供应链崩溃和全球经济动荡的出现[2].而今几乎横跨所有大陆的经济联系均可能由于这种现象而失去其顺畅性,甚至瓦解.当供应链涉及跨越多个国家甚至大洲的大公司时,其相当于是一种大型物流事业.因此,对所有国家而言,供应、中间产品和生产投入的中断意味着出口萎缩幅度大于进口,这会对其贸易平衡产生极其负面的影响.
目前,大数据和机器学习被研究并应用于供应链的需求和供应情况很常见[3].王洪峰等[4]提出了一种基于随机优化法的方法来处理供应链系统中的不确定性.该方法可以有效地减少不确定性问题,并优化时间和复杂性.Ziari等[5]提出了一种战术供应计划模型,以克服产品生命周期短和需求不确定性等难点.该模型可以提供基于利润和交货时间最佳权衡的解决方案.邹筱等[6]使用支持决策的风险评估关系,提出了一种供应链系统的层次结构.张天瑞等[7]研究了供应链网络的可持续性.
在发展中国家,农业被视为第一产业,有助于消除贫困和保障粮食安全.农产品供应链是指以农产品为对象,围绕农业供应链的核心企业,通过信息流、物流和资金流,实施农产品的生产、加工和营销等过程.它将农业生产中的供应商(规模经营者)、农产品生产基地、农产品商品采购、物流服务经销商、分销零售商和消费者连接成一种功能型网络链.
农产品供应链具有结构复杂、市场不确定性、市场力量失衡和脆弱性等特点.农产品的农业生产和加工的供应,经过从批发商、零售商到最终消费者的各个环节.农产品的生产和消费存在时间和空间差异.然而,市场信息极为分散和不确定,无论是农民个体还是农产品流通加工企业都很难完全掌握市场需求信息.农产品供应链物流的能力包括运输、包装、储存能力,它们直接决定了农产品流通的规模和速度,也影响着农产品流通深度和广度.近年来,农产品价格大幅上涨,一方面是受物价整体上涨的社会环境影响.另一方面,农业生产、运输等环节遭到破坏,导致农产品供应链系统无法发挥正常的供应功能,使农产品供应链条结构和运行机制表现出极大的脆弱性.
通过风险分析和研究,可以确保农产品的质量和安全,提高供应链的效率,增加供应链的利润,这是适应农业生产经营模式和社会化大生产加快需求转变的有效途径.因此,开展农产品供应链风险研究具有重要的理论和现实意义.为此,本文研究并设计了一种基于贝叶斯决策树的农产品风险评估模型.在综合考虑影响农产品供应链各个随机变量的基础上,采用ID3算法与贝叶斯算法建立决策树模型,并提取风险评估权重.实验结果证明本文模型具有较高的预测准确性以及市场敏感性,可为供应链中的决策者提供实际参考价值.
本文的贡献如下:
1) 在综合考虑影响农产品供应链的各个随机变量的基础上,采用ID3算法与贝叶斯算法建立决策树模型并提取风险评估权重.
2) 决策树模型应用于农产品供应链(APSC),提出了APSC管理框架,有助于决策者进行评估分析,以降低农产品供应链风险.
3) 使用接近专家推理来评估供应链风险,为供应链管理提供了一个新的决策支持维度.
1 供应链风险研究
目前,关于供应链的研究主要集中在风险识别、风险评估和风险管理等方面.丁存振等[8]根据不确定性和外部因素造成的供应中断确定了供应链的风险.Tarei等[9]开发了一个用于评估供应链风险缓解策略的评估支持系统,该系统通过集成异构技术构建,采用系统评审方法探索主动和被动风险管理的推动者,利用基于规则的模糊推理系统(FIS)来抵消评估变量中涉及的不确定性.Rathore等[10]使用失效模式效应和模糊VIKOR来分析评估粮食供应链中的风险.他们使用模糊VIKOR对食品供应链风险因素进行优先级排序.这是一种多属性评估技术,旨在根据标准对FSC的风险因素进行排序.Lotfi等[11]将混合模糊和数据驱动的稳健优化与供应商管理的库存方法相结合,以实现弹性和可持续医疗保健供应链.陈美燕等[12]提出了基于贝叶斯的风险评估方法,用于使用历史数据的供应链管理.该方法可以帮助供应链经理尽早识别风险因素.Yasamin等[13]提出了一个降低易腐食品供应链风险的模型.他们使用模糊最佳-最坏方法(F-BWM)对确定的策略进行了优先排序.最佳-最坏方法的模糊扩展有助于将模糊性纳入评估中,是一种具有更高一致性的高效评估方法.梁冠宇等[14]开发了一个框架来识别、分析和评估供应链中断因素和驱动因素.基于实证分析,在现实世界的工业环境中,确定并检查了4个破坏因素类别,包括自然、人为、系统事故和财务,共有16个破坏驱动因素.Khan等[15]使用MCDM方法优先考虑清真食品供应链中的风险.该方法使用系统的文献综述来确定清真食品供应链条中的各种风险因素,并将其与专业人士和学者的专业知识相结合.然后,应用模糊层次分析法(FAHP)对识别出的风险要素进行优先级排序[16].翟羿蒙[17]进行了一项调查,以检查整个食品供应链的欺诈和真实性以及食品欺诈对消费者和生产商的影响.结果表明,食品造假的普遍程度因行业而异,因此评估和检测具有挑战性.王晓梅等[18]回顾了新型冠状病毒肺炎疫情期间农业食品部门面临的挑战,并推断由于需求缺乏弹性,全球对食品的需求保持相对稳定.华树春等[19]综合多学科研究了新型冠状病毒肺炎疫情如何影响食品供应链,包括如何影响食品安全和保障,人与动物相互作用的风险评估,以及如何导致食品行业的物流和规程发生变化.
农产品供应链中的风险包括内源性因素和外源性因素,一个阶段的风险可能会给整个食品供应链带来损失.外源性因素包括自然环境风险、经济环境风险、政策环境风险和法律环境风险.何军等[20]研究了自然环境风险对农产品供应链的影响.肖文金[21]分析了经济环境风险对生鲜农产品供应链的影响.内源性因素是由供应链节点之间不可避免的利益冲突和信息不对称引起的风险.例如,农业生产中的基础设施限制加剧了运输成本和风险,从而导致农业生产者的收入减少.风险在食品供应链上是传递的.目前对特定农业供应链风险的研究还很少,这不利于特定农产品的风险规避,容易影响农产品整体市场.
2 模型理论
2.1 数据预处理
首先,选择构建决策树所需的样本属性,并将数据分为2部分:训练样本和测试样本.使用贝叶斯方法来补齐缺失的训练样本数据,并对数据进行离散化处理.朴素的贝叶斯方法使用已知的样本属性,将后验概率最高的类Cx分配给未知的样本属性.假设有s个数据,属性相互独立,其中数据I已知z个属性i1i2,…,iz,但属性i是未知的,那么未知属性属于Cx的概率为:
(1)
U(I)=U(i1)U(i2)…U(iz)
(2)
(3)
U(I∣Cx)=U(i1∣Cx)U(i2∣Cx)…U(iz∣Cx)
(4)
2.2 构建决策树
计算决策树根节点的每个属性的信息增益,选择对应最大值的属性作为根节点的属性,然后从上到下递归计算其他子节点的属性.假设样本有s个数据,叶子节点有w个不同的分类Cx(x=1,2,…,w).sx为Cx的样本数,ux是样本属于Cx的概率.假设样本的某个属性G有q个不同的类别,根据属性G可以将样本S分为q个子集,sxy为子集sy中分类Cx的样本数,uxy=sxy/sy是sy中样本属于Cx的概率.那么,样本分类所需的期望值X、基于属性G划分子集的熵E(G)、子集sy的期望X以及属性G对应的信息增益A(G)分别为:
(5)
(6)
A(G)=X(s1+s2+…+sw)-E(G)
(7)
(8)
在父节点和子节点之间添加贝叶斯节点,检验父节点的属性是否可知(Y:已知,N:未知).并在构建完决策树后,对其进行后期剪枝(图1).

图1 贝叶斯决策树示意图
3 模型设计与开发
使用随机变量来预测分析可能发生的风险,并根据观察数据对其进行量化评估.风险作为状态是固定存在的,但也会随着自然变化随机发生.本研究将农产品市场供应链系统建模为5个流程:来源、供应、需求、未来市场波动和市场价格.随机变量是使用来自APSC操作的先验知识设计和构建的.
将随机变量分为3类:观察到的、微观的和宏观的.观察到的随机变量评估直接环境情况,微观随机变量代表供应链活动,宏观随机变量评估市场行情.根据熵权法得到各随机变量的权重详见表1~表3.

表1 观察到的随机变量风险评估
3.1 观察到的随机变量
观察到的随机变量权重基于5个APSC评估类型,总结在表1中.
气候问题影响农产品的生长和收获,可以通过气象站观测或开放数据服务中获得.利用种植面积估计农产品产量,可以手动完成或使用传感器自动完成.气候问题和种植面积提供有关来源的信息并暗示原材料加工.
原材料成本,如农产品市场价格可以通过开放数据服务观察到,从中还可以看到损害次级生产量的基础信息.劳动力资源反映生产能力,通过已登记的劳动力和法定节假日数据获得.原材料成本和劳动力资源对于评估供应链中的供应环境至关重要.
对于需求,所需信息涉及产品消费和物流.出口成本和货币兑换是关键因素.这些信息可以从石油价格指数和网络服务的货币兑换中获得.此外,生产消费因农产品和市场性质而异.有些产品可能通过代理进行交易,而更多的产品则是通过标售进行交易.这意味着未来市场的波动性是用空盘量、交易量和市场价格来解释的,这些可以从业务数据服务中观察到.市场价格是由政府部门或代理人保留的农产品的指数市场价格,可以直接观察到.
表1中所有随机变量都是通过开放数据、信息系统和服务观察获得的,我们还需要针对特定的市场环境明确变量的状态.例如,在气候变化的情况下,根据农产品产量的脆弱性重点关注干旱、季风和洪水等风险.其他变量根据APSC非平稳特征得出的波动(下跌、平稳、上涨)和趋势(下降、横盘、上升、波动)进行分类.选择状态的标准是基于它的长短期波动如何影响交易过程.例如,原材料成本显示了对生产制造业的影响,而空盘量、交易量和市场价格则反映了市场的需求.由于长期受到交易过程的间接影响,因此它们的状态需根据趋势进行分类.
3.2 微观随机变量
微观随机变量权重是根据APSC的先验知识阐述的,总结在表2中.

表2 微观随机变量风险评估
农产品产量代表了市场来源的水平.生产能力是市场供应生产的中间步骤.消费者偏好概括了产品需求,反映了市场需求.市场波动是影响市场需求的外部因素.
这些微观随机变量利用低、正常和高状态来反映其市场环境.其中,因市场波动监控市场情况,故使用下跌、稳定和上涨来定义.
3.3 宏观随机变量
宏观层面的随机变量总结了供应链动态,标识农产品供应链形势.它由3种可能的状态组成:均衡(指需求量和供给量相同)、短缺(指需求过剩)和过剩(指供给过剩).但需求、供应和市场价格之间的关系很复杂.例如,如果需求上升而供应下降,那么根据市场理论,就会出现农产品短缺导致价格上涨的情况.相反,如果供求关系引发价格下降,仍然是农产品短缺导致供应链异常的情况.后一种情况反映了市场政策功能失调,市场管理者必须实施修正(即控制参考市场价格或设置市场价格上限).
表3列出了需求、供应和市场价格波动背景下农产品供应链的风险权重,旨在帮助管理者评估及预测市场风险.

表3 宏观随机变量风险评估
市场控制农产品的生产和供应与消费者之间的需求关系.我们利用这些信息对随机变量之间的评估假设进行建模,随机变量指标使用决策树模型运行后的结果如图2所示.
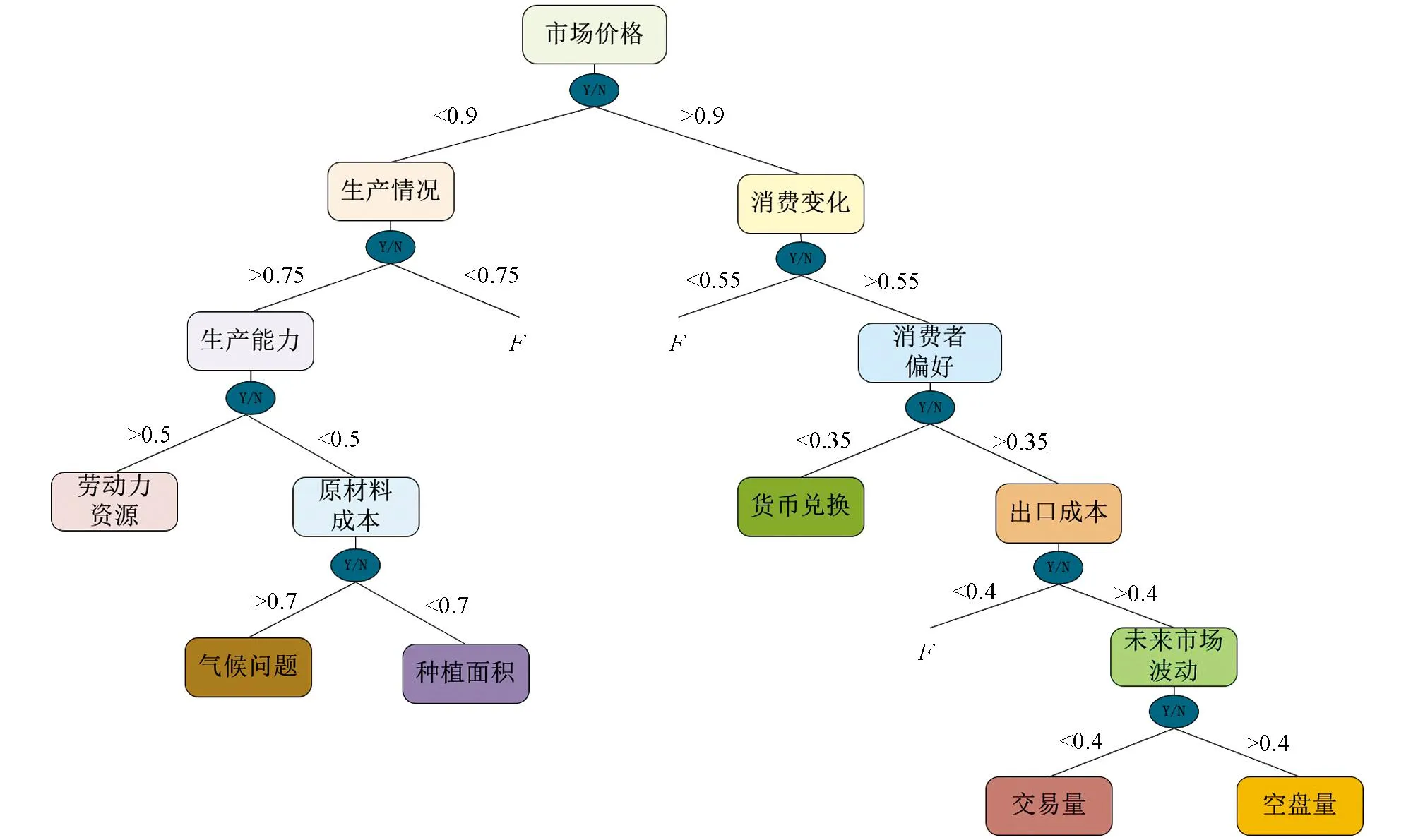
图2 随机变量决策树模型
最后将该决策树模型应用于农产品供应链,提出了一个APSC管理框架,有助于决策者进行评估分析,以降低农产品供应链风险.该框架编码了一种类似人类推理的方法,用于APSC管理(图3).

图3 APSC管理框架构建流程
该框架由4个部分组成:数据感知、观察识别、形势解释和风险评估.
数据感知通过全球定位系统(GPS)、地理信息系统(GIS)、遥感技术和基于Web的应用程序等来源检索APSC相关数据.原始数据通过观察识别模块转换为可用于APSC的观测数据.尽管这些观察数据详细描述了APSC的信息,但它们并没有详细说明APSC之间的关系,这需要更深入地了解APSC的情况.形势解释以类人推理的方式产生基于决策关系的理性解释.最后,评估预测主动规划的风险因素,从开放数据、信息系统了解的市场行情,并根据当前的APSC情况推断出可能产生的风险结果.由此产生的评估结果有助于决策者决定解决方案并及时调整计划政策.
4 实验结果与分析
4.1 模型性能验证
为验证本文模型对APSC风险的预测能力,首先对模型进行了性能评估.
根据农产品供应链形势可知,目标类别分布在9个可能的结果上,并且是不平衡的.根据10倍是最优值,对本文基于贝叶斯的离散模型进行交叉验证.将数据重新采样为10个子集,在每次迭代中使用9个子集进行训练,其余的用于测试.采用10折交叉验证来估计模型性能.
解释验证结果的度量标准是准确性,通过测量本文模型在学习过程中的预测性能来判断,结果如图4所示.
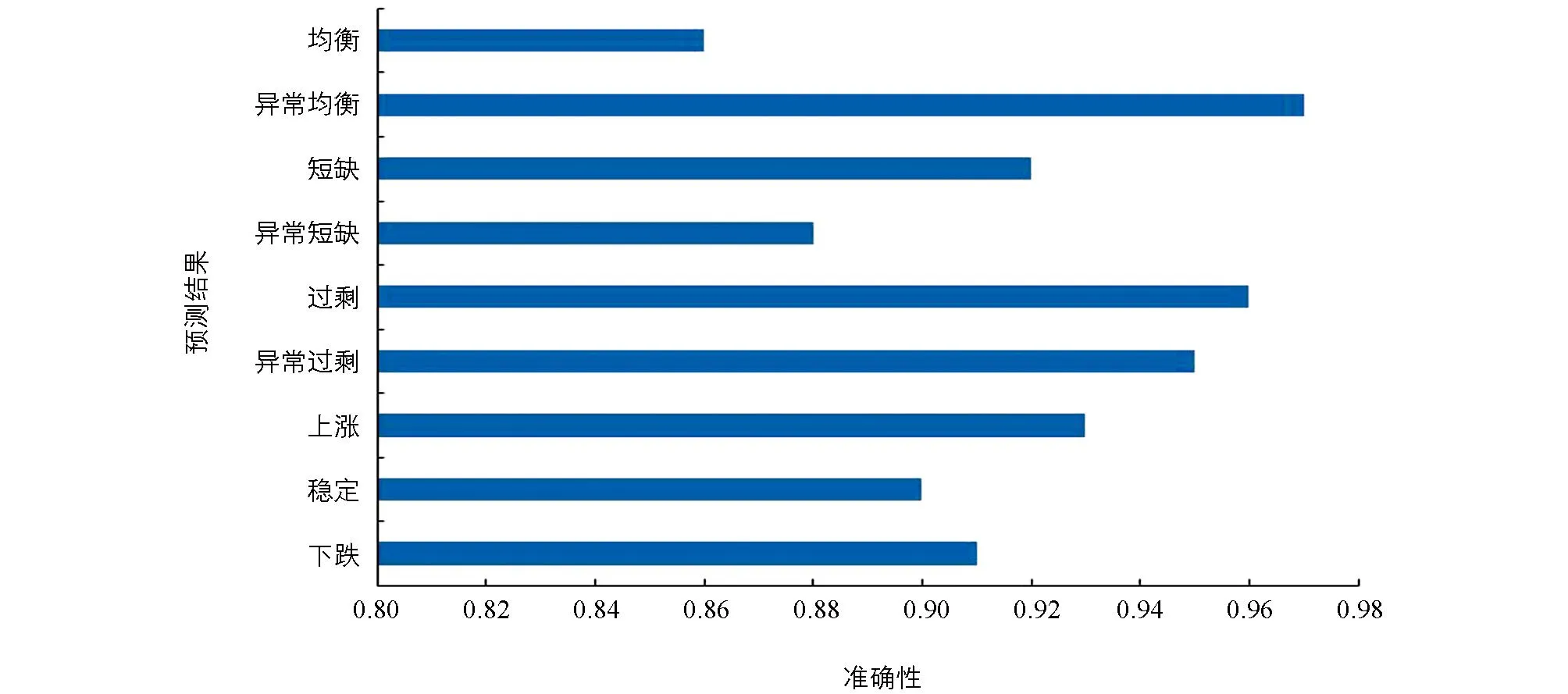
图4 10折交叉验证本文模型的预测精度
图4显示整体评价准确性高达92%.均衡和异常短缺是罕见事件,在样本比例中的发生概率分别约为7%和8%,所以准确率低于90%.由于市场环境是动态变化的,所以均衡状态是理想但很少发生的.同样,异常短缺是指供不应求,是一种与供求规律相矛盾的异常情况,也是一个罕见的事件.
实验结果表明,本文提出的模型具有良好的性能,可以应用于农产品供应链风险评估研究,该模型对市场风险评估情况正确且合理.
接着通过对模型正确性的预测性能测试,以及模型合理性的敏感性分析来验证本文模型的有效性.
4.2 预测性能测量
实验测量了本文模型的预测性能.目标类别是农产品供应链中随机变量的状态,它们有助于在供应链系统中提供最终评估结果.
使用标准分类算法来比较本文模型与其他4种模型(文献[22]-文献[25])在精确率、召回率和F1度量值3个指标上的预测性能.精确率(P)指的是正确预测正类样品的比例,其计算公式为:
(9)
其中TP是真阳性预测,FP是假阳性预测.
召回率(R)指的是正确预测为正类的占全部实际为正类的比例,其计算公式为:
(10)
FN是假阴性预测.
F1度量值是P和R之间的平衡,其计算公式为:
(11)
分类器的性能取决于算法的参数,这些模型由具有默认参数设置的Python库scikit-learn实现.例如,文献[22]模型设置100个隐藏层,0.001学习率,200个epochs,ReLU作为激活函数,adam作为优化.使用测试数据集评估模型,每个模型的平均分数如图5所示.

图5 预测性能比较
图5显示了每个模型的精度、召回率和F1度量值,平均值远远超过80%.其中文献[25]模型的精确率最低,为85%.该模型认为供应链的特征是独立的,只取决于结果.事实上,对于功能通常相互依赖的供应链而言,情况并非如此.文献[22-24]模型的精确率分别为91%,90%和92%,这些数据分数都很高,因为所有模型都是使用准备充分的数据进行训练和验证的.而本文模型相对更高,精确率可以达到96%,证明本文模型可以更好地应用于预测系统.本文模型在传统的供应链管理中也非常有效.传统供应链是与现代供应链相对应的概念.与现代供应链具有的数字化、智慧化、平台化、服务化、绿色化、全球化等特征相比,传统供应链的数据多数来源于企业内部,存在信息封闭的现象,而且在传统的供应链管理中,许多公司会聘请专家来评估短缺或过剩的可能性.然而,小公司缺乏这方面的专业知识,因此对他们而言预测分析更加耗费人力和时间.而本文模型可以帮助这些小公司准确评估供应链风险.
4.3 敏感性分析
尽管本文模型的结果可以很好地应用于预测系统,但它并没有给出支持评估的解释.因此,我们需要通过敏感性分析来解决这个问题,以显示随机变量之间联系的强度和敏感性.该实验可以为影响农产品供应链的随机变量的状态提供参数,从而为本文模型评估市场结果提供合理解释.实验对其他供应链风险评估模型与本文模型进行了对比,本文使用了贝叶斯的条件依赖,它根据数据依赖生成关系,因而采用了基于场景的敏感性分析来解释模型的合理评估.
我们使用最敏感的场景,“农产品供应链中的均衡状态”.该事件发生的概率最低,但对评估的影响最大.根据农产品供应链的后验概率可能受到生产能力、消费者偏好和市场价格的影响,我们假设基本情况对其随机变量的状态变化敏感.
利用敏感性分析根据未知变量的偏导数计算后验概率分布,敏感性计算公式为:
(12)
式中,i是一个目标变量,对I=in的基本情况比较敏感,而u(in|e)是给定证据的基本情况的后验分布.
以所有证据为条件的平均敏感性介于0和1之间.0表示农产品供应链形势的变化导致后验概率的绝对变化减少,在后验分布计算中表现出鲁棒性.敏感性分析可以测量农产品供应链形势后验敏感性的微小变化(即非平衡的原因).本质上,这种分析是基于农产品供应链形势的不确定性,以专家推理的方式计算评估之间的敏感性.
龙卷风图是风险定量分析中常用的一种敏感性分析工具,它将各敏感参数按其敏感性进行排序,可以形象地反映出各敏感参数对价值评估结果的影响程度.本文使用龙卷风图表示,易于阅读和解释.图6中的x轴表示农产品供应链的均衡状态在0和1之间的敏感度.y轴是影响均衡条件的参数.随机变量状态有27个可能的参数,但只有5个最敏感的参数出现在图6中.

图6 本文模型和其他3种模型的龙卷风图结果对比
图6显示了本文模型和文献[23]模型、文献[24]模型以及文献[25]模型的敏感度水平,敏感度分别为0.068,0.072,0.075和0.081.
本文模型和其他对比模型之间的区别是影响农产品供应链敏感性的随机变量的数量.本文模型对市场价格、生产能力和消费者偏好高度敏感,而其他对比模型分别对市场价格、交易量、空盘量、货币兑换敏感.变量的数量反映了资源和处理时间.本文模型的后验分布对市场价格高度敏感.消费者和供应商的行为是影响农产品供应链的主要因素,本文模型可以帮助人们使用接近专家推理来评估供应链风险.
模型的前3个参数表明均衡状态已经收敛到零.这意味着生产能力、消费者偏好和市场价格的变化导致农产品供应链形势变得不平衡(短缺或过剩).本文模型和其他对比模型中的最后两个参数也不同,相比本文模型,其他对比模型对交易量、空盘量、货币兑换高度敏感.然而,由于交易量、空盘量、货币兑换不能被用来评估农产品供应链风险情况,所以这些模型的评估结果并不合理.专家给予的解释是这些随机变量是影响农产品供应链的间接原因,其通常通过影响其他方式传递未来市场、出口成本和消费者偏好.实验结果表明本文模型对生产能力、消费者偏好和市场价格的变化很敏感,符合领域专家的预测推理,为供应链管理提供了一个新的决策支持维度.
5 结论
由于全球人口不断增加、气候条件不断变化以及自然界中占主导地位的其他因素,农业实践变得越来越难以预测.此外,农作物的产量会直接影响农产品供应链的可持续性.因此,将新技术纳入农业实践是当务之急.本研究设计和开发了一个用于农产品供应链风险预测评估的决策树模型.该模型应用贝叶斯决策树算法对收集到的随机变量进行分类,使用熵权法得到各随机变量的权重并用于风险评估.最后将决策树模型应用于农产品供应链(APSC),提出了一个APSC管理框架.通过与其他模型在预测性能测量上的对比,验证了本文模型具有较高的预测准确性.同时,敏感度分析实验结果证明本文模型具有较高的市场灵敏度,可以有效地评估供应链风险,帮助决策者更好地预测及应对市场变化.然而,基于专家知识的本文模型具有一定的主观性.需要根据不同供应链特征的市场调整模型的预测假设,并根据不同的历史数据重新调整参数.在未来的工作中,我们将研究其他更具客观性的数据,用于不同供应链风险预测.
