Lightweight Intrusion Detection Using Reservoir Computing
2024-03-12JiaruiDengWuqiangShenYihuaFengGuoshengLuGuiquanShenLeiCuiandShanxiangLyu
Jiarui Deng ,Wuqiang Shen ,Yihua Feng ,Guosheng Lu ,Guiquan Shen ,Lei Cui and Shanxiang Lyu,⋆
1Joint Laboratory on Cyberspace Security,China Southern Power Grid,Guangzhou,510080,China
2College of Cyber Security,Jinan University,Guangzhou,510632,China
3Guangdong Power Grid Company Limited,Guangzhou,510663,China
4School of Computer Science and Technology,Guangdong University of Technology,Guangzhou,510006,China
5China Southern Power Grid,Extra High Voltage Transmission Company,Guangzhou,China
ABSTRACT The blockchain-empowered Internet of Vehicles (IoV) enables various services and achieves data security and privacy,significantly advancing modern vehicle systems.However,the increased frequency of data transmission and complex network connections among nodes also make them more susceptible to adversarial attacks.As a result,an efficient intrusion detection system (IDS) becomes crucial for securing the IoV environment.Existing IDSs based on convolutional neural networks(CNN)often suffer from high training time and storage requirements.In this paper,we propose a lightweight IDS solution to protect IoV against both intra-vehicle and external threats.Our approach achieves superior performance,as demonstrated by key metrics such as accuracy and precision.Specifically,our method achieves accuracy rates ranging from 99.08%to 100%on the Car-Hacking dataset,with a remarkably short training time.
KEYWORDS Echo state network;intrusion detection system;Internet of Vehicles;reservoir computing
1 Introduction
Advances in the Internet of Things(IoT)and vehicular ad-hoc networks(VANETs)have catalyzed a new era of the blockchain-empowered Internet of Vehicles(IoV),which integrates humans,vehicles,things,and environments into a comprehensive network system to provide real-time or long-term services [1–3].By utilizing established network technologies such as deep learning,and blockchain,IoV can obtain,organize,and process vast amounts of data from both vehicles and external entities,and preserve data security and privacy [4–8],thereby enhancing the computability,extensibility,and sustainability of intricate network systems and information services.In practical terms,IoV can alleviate traffic congestion,prevent accidents,and even address safety concerns caused by the escalating vehicular density.
As an open and integrated network system,the development of IoV relies on the integration of multiple technologies,services,and standards.However,the resulting heterogeneity,coupled with a large number of vehicles,renders IoV vulnerable to cyber-attacks [9,10],highlighting the need for robust IoV security measures.Moreover,due to the inherent characteristics of blockchain-empowered IoT,such as transparency and non-comparability,IoV faces new challenges in terms of security.Attackers can exploit vulnerable connection points to access privacy,manipulate vehicles,and carry out malicious acts,including controlling the brakes,tracking the car,or even shutting it down,resulting in disastrous consequences [9].Cyber-attacks in IoV can infiltrate two areas: intra-vehicle networks(IVNs)and external vehicular networks.In IVNs,electronic control units(ECUs)exchange information via the controller area network(CAN)bus to execute functions and instructions.Security threats mainly arise from message injection attacks due to the lack of message authentication and the broadcast transmission strategy.Regarding external vehicular networks,there are diverse external entities to interact with,such as pedestrians,smart devices,and infrastructures.The likelihood of vehicles being exposed to outer attacks,which tend to be various and frequent,is significantly amplified.
Countermeasures against cyber-attacks are crucial for the long-term robustness and sustainability of IoV.Intrusion detection systems(IDSs),as essential protection mechanisms,detect potential threats and malicious content both internally and externally by monitoring and analyzing network data such as network traffic,connections,objects,etc.,and take security measures immediately.With the advances in machine learning(ML)and deep learning(DL),particularly the success of convolutional neural networks(CNN)in pattern recognition,researchers have explored ML-based IDS and achieved remarkable results in intrusion detection[11–15].However,applying ML-based IDS to IoV remains challenging due to several reasons.Firstly,deploying IDS in the IoV scenario is subject to hardware constraints such as computing power,memory size,and communication capability.Conventional ML techniques generally consume a large amount of computational resources to train and deploy a model,while the well-trained parameters also occupy substantial storage space.Secondly,IDS,as a safetycritical system,should fulfill real-time and high-precision requirements simultaneously.Some MLbased IDSs overemphasize detection accuracy,resulting in complex and time-consuming methods.Lastly,data preprocessing and feature selection are essential aspects of IDS.IoV involves a high volume of network traffic data,but only a negligible proportion of the total data constitutes malicious content.Therefore,data preprocessing measures should be employed to mitigate the class imbalance problem.Additionally,traffic data contains a plethora of features,and it is crucial to remove irrelevant features to improve detection accuracy and alleviate the computational burden.
This paper proposes an IDS model based on reservoir computing(RC)to protect the IoV system.RC,as a framework for computation,has been successfully applied to address real-world problems in various domains,including time series forecasting,handwriting recognition,and network anomaly detection[16–18].In contrast to typical recurrent neural networks(RNNs),RC offers computational efficiency with less memory demand,attributed to its architecture and training algorithm.RC can be considered a simplified RNN,with a recurrent (reservoir) topology randomly determined,and only the readout layer requires training using simple linear regression.RC can be employed in online intrusion detection,which deals with streams of large input data in real time by classifying regular and anomalous data points.
The main contributions of this paper are summarized as follows:
• We propose a lightweight IDS for IoV.Unlike existing CNN-based methods,the proposed RCbased method requires significantly less training time and storage space.This is the first time that RC has been applied to intrusion detection in IoV,addressing the computational resource and memory space limitations of traditional machine learning models and opening up a new avenue for intrusion detection in IoV.
• The proposed scheme converts processed traffic data into images and feeds them into RC for intrusion detection.Additional resampling and feature engineering steps are employed to improve data quality and increase detection accuracy,addressing class imbalance and feature redundancy in external data.
• We validate our scheme using the Car-Hacking dataset[19]and the CICIDS2017 dataset[20],which simulate internal and external IoV networks,respectively.Experimental results demonstrate that our scheme achieves high accuracy requirements with computational efficiency.
The remainder of this paper is organized as follows.Section 2 introduces the basis of RC.Section 3 elaborates on the proposed scheme.Section 4 presents simulation results and discussions.Section 5 concludes this paper.
2 Related Work
IDSs for IoV networks are generally classified into two groups,namely IDSs based on traditional machine learning and IDSs based on neural networks.In this section,we provide a brief overview of recent advances in IDSs from these two perspectives.
2.1 Traditional ML Algorithms
The field of IoV has seen numerous research into intrusion detection systems based on traditional machine learning techniques.In a study by [21],various ML methods,including logistic regression,naïve Bayes,decision tree,support vector machine,k-nearest neighbor,random forest,and XGBoost,were validated on a large-scale,heterogeneous dataset known as ToN-IoT.Chi-square and SMOTE were used for data preprocessing.This study concluded that XGBoost outperformed other ML-based methods.The study in[22]focused on DDoS attacks,devising an IDS consisting of a real-time network traffic collection module and a network detection module and evaluating NSL-KDD and UNSWNB15 datasets.In the context of big data,this work introduced a distributed architecture using Spark and Hadoop Distributed Files Systems to speed up data collection and processing.Random forest was adopted for classification in the detection module.Researchers in[23]built an ensemble learning model for intrusion detection utilizing tree-based ML algorithms,including decision trees,random forests,extra trees,and extreme gradient boosting.To tackle class imbalance and computational costs,SMOTE oversampling and tree-based averaging feature selection techniques were also adopted.Results on CAN intrusion and the CICIDS2017 dataset demonstrated the efficiency of the proposed IDS.In[24],the authors combined Logarithmic Ratio(OBLR),outlier detection,and metric learning to combat dataset imbalance and achieve efficiency.The detection process is implemented by Light-GBM after genetic algorithm feature selection.Evaluations were performed on UNSW-NB15 as an external network dataset and ROAD,Car-Hacking CAN-intrusion as intra-vehicle datasets.
2.2 Neural Networks
Compared to traditional ML-based IDSs,deep neural network methods can exploit the nonlinear relationship between features,which cannot be extracted by expert domain and feature selection methods.Reference[13]used a feed-forward neural network for IDS based on multi-layer perceptron,which obtained 99% accuracy on the CICIDS2017 dataset.Convolutional Neural Network (CNN)is an important research direction in DL-based IDS construction.The authors of [11] designed a 1D CNN to protect the in-vehicle CAN bus system.The ID CNN-based classifier achieved 99.99%accuracy on the dataset generated from three car models.By removing the redundant part of the Inception-ResNet architecture,Song et al.[12] proposed a deep CNN (DCNN) model to learn temporal sequential patterns of input data and detect in-vehicle attacks.The proposed DCNN was proved to be effective by experiments compared to other ML-based algorithms.In [25],the authors also trained a 1D CNN model for IDS with the ToN-IoT dataset.The highlight of this work is the application of the SHAP method to explain the performance of the CNN-based IDS.Reference[26]proposed an intelligent IDS (IIDS) for IoV based on a modified CNN model with hyperparameter optimization.Experimental results showed that the proposed IIDS achieved 98%accuracy in detecting attacks.Reference[14]transformed vehicle network traffic data into images for CNN to distinguish attack patterns and achieved satisfying results on Car-Hacking and CICIDS2017 datasets.Among various pre-trained CNN models,the authors preserved the bottom layer and only fine-tuned the top layers based on transfer learning to save training time.From the point of exploiting temporal relationships within network data,Recurrent Neural Network(RNN)and its variation Long Short-Term Memory (LSTM) network have attracted attention.Reference [27] conceptualized a privacypreserving-based framework for IoV,integrating blockchain and LSMT techniques.They separately ensure secure transmission and intrusion detection.The authors of [28] used a Long Short-Term Memory-AutoEncoder(LSTM-AE)to encode data into a new format for private feature extraction.Attention-based Recurrent Neural Network(A-RNN)was adopted for intrusion classification in the IDS part.The performance of this scheme was validated through ToN-IoT and CICIDS2017 datasets.Reservoir computing(RC),as an emerging and promising paradigm in the realm of RNNs,inherits the ability to process temporal data while getting rid of gradient descent-based training methods,thereby alleviating the computational burden and accelerating convergence speed.Reference[17]utilized echo state network,a type of RC,to discriminate attacks.Experimental results showed that ESN can achieve comparable performance to bidirectional LSTM with shorter training time.However,this work only focuses on Denial of Service attacks in the general network.
3 Preliminaries
3.1 Reservoir Computing
Among various types of reservoir computing(RC),the echo state network(ESN)is chosen as the underlying architecture to implement intrusion detection[29].As shown in Fig.1,an ESN comprises an input layer,a reservoir layer withNnonlinear nodes,and an output layer.Mathematically,the reservoir layer and readout layer can be written as follows:
Here,u(t)∈RQis the input vector collected at timet={1,...,T},whereTis the number of data points in the training dataset,andy(t)∈RPis the output vector.r(t)∈RNis the state vector ofNreservoir nodes,which iterates as the input variable is updated.Win∈RN×(1+Q)maps an input to a high-dimensional space,uniformly and randomly distributed in[-1,1].W∈RN×Nis a random sparse matrix generated between[0,1],where the sparsity refers to the connectivity of the internal nodes of the reservoir layer.The spectral radiusρis the maximal absolute eigenvalue ofWand must be scaled to be no greater than 1,ensuring the echo state property of the ESN model[30].The leakage parametera,whose value ranges between[0,1],represents the impact of the previous reservoir state on the current state.Wout∈RQ×(1+Q+N)is the only matrix that needs to be trained between the reservoir and the output layer.The activation functionf(·)used in the ESN is sigmoid or tanh,which introduces nonlinear factors to the nodes,allowing the RC to approximate arbitrary nonlinear functions and models.binandboutare the input and output bias terms,respectively,both set as 1.
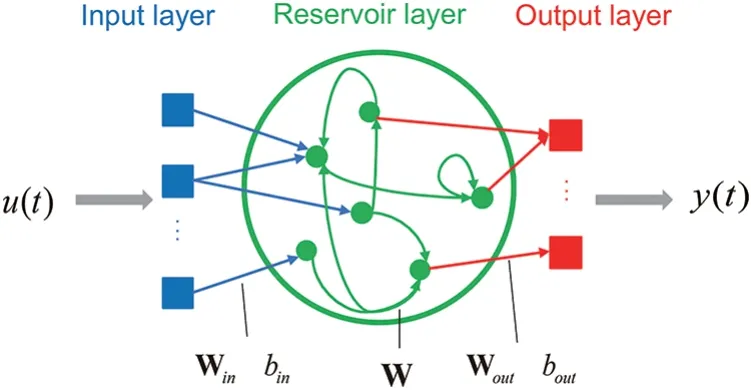
Figure 1:Principle structure diagram of ESN
3.2 Training Algorithm
The computational efficiency of ESN lies in the fact that RC uses only one iteration to calculate the output weights,unlike gradient-based iterative optimization algorithms such as back-propagation which require multiple iterations to obtain optimal weights.
Instead of using the direct pseudoinverse,which is memory-intensive for large state-collecting matricesRand limits the size of the reservoirNand the number of training samples,ESN adopts the ridge regression algorithm,which can be expressed as follows:
Here,I∈R(1+Q+N)×(1+Q+N)is the identity matrix,λis the ridge regression parameter set as 10-8to avoid overfitting and the reservoir nodes’state matrixR∈R(1+Q+N)×T(respectively,limited observable target output vectorY∈RP×T)is the matrix whosei-th column is[bout;u(i);r(i)](respectively,[y(i)]).
4 The Proposed Intrusion Detection System
In this section,we introduce our innovative Intrusion Detection System (IDS) designed to safeguard both in-vehicle and external networks.Our IDS employs a two-fold approach,starting with the transformation of tabular data into images.Subsequently,we unveil the complete IDS scheme,leveraging the power of RC for robust intrusion detection.
4.1 Tabular Data to Image Transformation
In the first phase of our IDS development,we focus on the critical process of converting tabular data into images.This transformation method enhances the interpretability and effectiveness of subsequent analysis,allowing for more advanced intrusion detection techniques.
We employ a transformation process that converts the raw tabular data into a structured image format.This transformation serves a fundamental purpose by harnessing principles from both computer vision and statistical data preprocessing.By representing the data as images,we leverage the intrinsic human capacity for visual pattern recognition,enabling the application of visual analysis techniques.
Furthermore,as a crucial preprocessing step,we employ quantile normalization to rescale the network data into a standardized range of 0 to 255,a range commonly associated with pixel values in images.Quantile normalization is a robust statistical technique used to align the probability distribution of two datasets.Given two datasets,XandY,each containingnobservations,the process involves the following steps:
•Sorting:Sort both datasets in ascending order,denoted asXsortedandYsorted.
•Rank Calculation:Calculate the ranks of the observations inXsorted,denoted asRX,and similarly forYsorted,denoted asRY.
•Quantile Values:Compute the quantile values forXsortedandYsortedasand
•Mapping:Map the quantile values ofXto those ofYby finding a functionfsuch thatQY=f(QX).
•Normalization:Apply the mapping functionfto the original datasetXto obtain the quantilenormalized datasetXnormalized.
This process ensures thatXnormalizedandYsortedhave the same quantile values,aligning their distributions.Quantile normalization is particularly useful for comparative analyses,such as microarray data,where it is crucial to remove systematic variations between datasets to make valid statistical inferences.
Preposition 1.Let X and Y be two datasets with the same number of observations,n.After performing quantile normalization on X and Y according to the defined process,Xnormalized and Ynormalized will have identical quantile values,thus aligning their probability distributions.
Proof.LetXsortedandYsortedrepresent the sorted versions of datasetsXandY,respectively.The quantile valuesQXandQYforXsortedandYsortedare defined as:
whereRXandRYare the ranks of the observations inXsortedandYsorted,respectively.
During quantile normalization,we map the quantile values ofXto those ofYusing the functionf,such thatQY=f(QX).This ensures that the quantile values ofXnormalizedandYnormalizedare the same.
Therefore,by construction,the quantile normalization process guarantees thatXnormalizedandYnormalizedhave identical quantile values,aligning their probability distributions.
Quantile normalization ensures that the resulting image representations capture the essential statistical properties of the data distribution while reducing the influence of outliers,which can be especially critical in real-world scenarios where network traffic data may exhibit variability and anomalies.
4.2 Wrapping Up:Malicious Classification Based on RC
Building upon the tabular data-to-image transformation,we present a comprehensive IDS scheme that relies on RC.This scheme empowers us to tackle the complex task of classifying malicious activities with efficiency and precision,ensuring the security of in-vehicle and external networks.
The whole IDS scheme is outlined in Fig.2.Initially,we collect data from the Internet of Vehicles (IoV) environment,followed by data pre-processing to improve data quality.Then,we convert vehicular tabular data into images to assist the RC model in identifying attack patterns in the data flow.As external vehicle data often suffers from class imbalance and feature redundancy issues,we utilize data resampling techniques such ask-means clustering and Synthetic Minority Oversampling Technique(SMOTE),along with feature engineering strategies based on information gain and correlation analysis.The next step involves labeling the generated images to form an image set,after which the RC model performs classification tasks to identify normal and attack behaviors.The details of this process are explained comprehensively in the subsequent subsections.
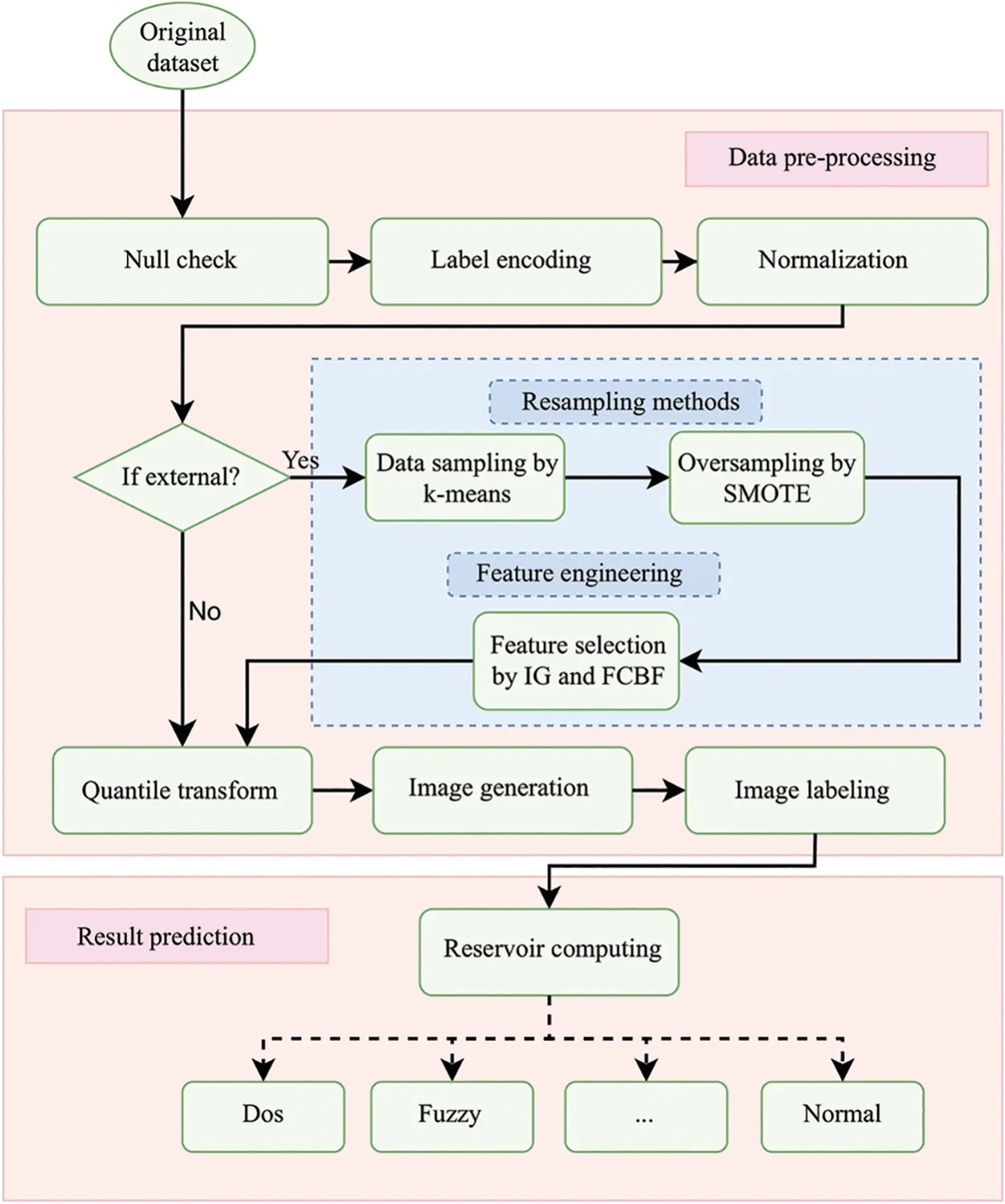
Figure 2:The proposed RC-based IDS framework
4.2.1 Data Pre-Processing
The data pre-processing phase begins with checking for missing values in the dataset.If any rows contain missing values,they are deleted to ensure data integrity.Next,we convert categorical features into numerical values using a label encoder,enabling direct processing by machine learning algorithms.After that,we apply Z-score normalization(ZN)to scale the data,which brings features with different ranges into a normalized range.Letxi(i=1,2,...,D)denote thei-th component of each feature vectorx∈RD.We compute the meanμxand the standard deviationσxof theseDcomponents as follows:
ZN normalization is then applied to obtain the normalized datax(zn)as follows:
Here,1=[1,1,...,1]Tis aD-dimensional vector with all components being ones.This normalization ensures that each feature has a mean of 0 and a standard deviation of 1.
In cases where class imbalance is present,additional data pre-processing steps are required.Since external networks often generate a massive amount of data,it is unnecessary to spend significant time and resources training a machine learning model using redundant data.To address this,we employ thek-means clustering algorithm to reduce the data size and save training time.k-means clustering is a technique that groups similar entities within multiple subsets.The algorithm iteratively updates cluster centroids and boundaries to minimize the sum of squared distances from the data points to the corresponding cluster centers.We select representative subsets from each cluster and randomly discard redundant data.
The second step in combating skewed data distribution involves using the Synthetic Minority Over-sampling Technique (SMOTE) to generate substantial new artificial samples.In our case,the minority class refers to malicious attacks,which make up a negligible portion of the dataset and can result in a bias towards the normal class when training a model.SMOTE interpolates between randomly selected minority observations and their neighboring minority observations,creating new samples that are more representative of the minority class.The process can be described as follows:for a randomly chosen minority observationa,we select instancebamong itsk-nearest minority class neighbors.To create a new sample,we interpolate between the two samples using a random weightwranging from 0 to 1.The new samplejis generated as:
4.2.2 Feature Engineering
Feature engineering aims to remove irrelevant or redundant features,thereby obtaining optimal feature subsets to enhance the performance of the subsequent classification algorithm.We employ a two-step process for feature engineering: feature selection based on information gain and a fast correlation-based filter(FCBF).
• The information gain-based algorithm selects features based on the amount of information that can be gained from these features from an information theory perspective.By calculating entropy and mutual information,we obtain the subset of the most relevant features that contain the most information.The feature evaluation function is given by:
whereI(F|C)is the mutual information between the feature subsetFand the classC,measuring the interdependence between them.H(F)is the entropy of the discrete feature subsetF.Given eventse1,...,emoccurring with probabilitiesp1,...,pm,the information entropy is defined as:
H(F|C)is the conditional entropy of the discrete feature subsetF,quantifying the uncertainty ofFgiven the classC.Mathematically,H(F|C)is defined as:
wherep(f,c)represents the joint probability ofFtaking the valuefandCtaking the valuec,andp(f|c)represents the conditional probability.Based on the ranking of the information gain values,we select the most important features that contain the most information.
• We further use the fast correlation-based filter to remove redundant features.Although we have selected the most relevant features,some unimportant features may still exist.The symmetrical uncertainty(SU)is computed to measure the correlation between features,and it is defined as follows:
A larger SU value indicates a higher correlation between the two given features,suggesting redundancy.In such cases,one of the redundant features needs to be removed.
Hereby we show that the combination of information gain-based feature selection and FCBF leads to a feature subset(FFCBF)containing the most relevant information while removing redundancy.
Preposition 2.Feature selection based on information gain and the fast correlation-based filter ensures that the selected feature subset contains the most relevant information while removing redundancy.
Proof.To begin,notice that the information gain(I(FIG|C))is maximized during information gainbased feature selection.This ensures that the selected feature subsetFIGcontains the most relevant information for classifying instances.
Regarding FCBF for redundancy removal,notice that FCBF refines the feature subsetFIGby maximizing symmetrical uncertainty(SU(FIG,C)).This step ensures that features inFFCBFare highly correlated with the class(C)while minimizing inter-feature correlation(redundancy).Mathematically,FCBF selects features that satisfy:
Therefore,by maximizing I(FIG|C) and subsequently selectingFFCBFbased onSU(FFCBF,C),we ensure thatFFCBFcontains the most relevant information while effectively removing redundancy among features.This completes the proof.
4.2.3 Configuration
The final step involves directly feeding the generated images into the ESN model without any additional feature extraction.This enables us to obtain a well-trained model capable of performing intrusion detection on test images.Specifically,we begin by constructing the ESN using randomly generated,but fixed,matricesWinandW.The training dataset,consisting of labeled images,is then input into the ESN for classification.Subsequently,the ESN is trained,and the matrixWoutis determined.Finally,the ESN,equipped withWin,W,and the trainedWout,is employed to classify vehicular traffic data into different categories.
As mentioned earlier in the ESN preliminaries,several paramters significantly impact the performance of ESN models,particularly the reservoir sizeNand the leakage ratea.The reservoir sizeNdetermines the ESN’s ability to approximate complex transformations.However,increasingNwithin a certain range improves performance at the cost of increased computational time.Beyond this range,further increases inNno longer yield better performance(i.e.,overfitting occurs),resulting in wasted computational resources.The leakage rateais related to the dynamics of reservoir updates.It represents the influence of previous states in the reservoir on the current state and also affects prediction performance to a certain extent.Therefore,we develop the optimal ESN model by adjusting the reservoir sizeNand the leakage ratea.
4.3 Performance Analysis
To justify the performance of Reservoir Computing(RC)in intrusion detection,we establish the Universal Approximation Theorem for Reservoir Computing(UAT-RC).
Theorem 1.Let X be a compact subset ofRn,and Y be a subset ofRm.For any continuous function g:X→Y,there exist suitable parameters for a reservoir computing system(e.g.,an Echo State Network-ESN)such as the reservoir size N and the leakage rate a such that the system can approximate g with arbitrary accuracy.That is,for any ∊>0,there exist reservoir parameters N and a and a readout layer such that the following holds:
for all x∈X,where g(x)is the true function value,‖·‖denotes the L2norm.
Proof: Step 1: Approximation of Continuous Functions.First,we establish that a reservoir computing system,specifically an Echo State Network(ESN),can approximate continuous functions on a compact subset of Rnwith arbitrary accuracy.For this purpose,consider any continuous functiong:X→Y,whereXis a compact subset of RnandYis a subset of Rm.By the Stone-Weierstrass Theorem,which states that the set of all polynomials is dense in the space of continuous functions,we know that for any∊>0 and any continuous functiong:X→Y,there exists a polynomialp(x)such that:
Step 2: Approximation with Reservoir Computing.Now,we aim to approximate the polynomialp(x)using a reservoir computing system.Given the polynomialp(x),we can set up an ESN with suitable parameters.
The ESN consists of a reservoir layer withNnonlinear nodes,and its dynamics are governed by the following equation:
wherer(t)is the state vector,WinandWare weight matrices,ais the leakage parameter,andf(·)is the activation function.We can train the readout layer of the ESN,represented byWout,using a suitable algorithm(e.g.,ridge regression)on the polynomialp(x).
Step 3:Achieving Arbitrary Accuracy.By the properties of ESNs and the approximation properties of polynomials,we can choose the reservoir sizeNand the leakage rateasuch that:
This proves that for any continuous functiong(x),there exist suitable parameters for an ESN,includingNanda,and a readout layer such that the ESN can approximateg(x)with an error less than∊.
The above theorem demonstrates that ESNs can approximate continuous functions on a compact subset of Rnwith arbitrary accuracy.This demonstrates the effectiveness of Reservoir Computing in approximating complex relationships in network traffic data,justifying its utility in intrusion detection.
5 Simulation Results
The experiments were conducted on a Windows 10 64-bit operating system using a Python 3.9 environment running on an Intel Core i7-10700 CPU (2.90 GHz).We will compare RC-based IDS with the most relevant and representative neural networks-based methods in the Related Work section.The research focus of [27] and [28] also includes privacy-preserving techniques based on blockchain,therefore,the benchmark algorithms employed for comparison were the following:1-dimensional CNN(1DCNN)[11],deep convolutional neural network(DCNN)[12],feed-forward neural network[13](FFNN),and transfer learning and optimized CNN-based IDS[14],referred to as CNN(Concatenation)and CNN(Confidence Averaging).
5.1 Settings
We utilize two benchmark datasets to represent in-vehicle and external networks:the Car-Hacking dataset and the CICIDS2017 dataset,respectively.The Car-Hacking dataset was constructed by capturing Controller Area Network(CAN)traffic logs from an actual vehicle.Table 1 provides details of the 5%Car-Hacking dataset,which consists of four attacks:Denial of Service(DoS),Fuzzy,Gear Spoofing,and RPM Spoofing.The dataset includes the CAN ID and the 8-bit data of CAN packets(DATA [0]-DATA [7]).On the other hand,the CICIDS2017 dataset contains normal and common attack behaviors.It consists of 2,830,743 rows,with each row consisting of 79 features and labeled as either benign or one of 14 attack types.The attacks can be categorized into five main types based on[31].Table 2 presents the distribution of the different attack types and the number of benign rows in the CICIDS2017 dataset.
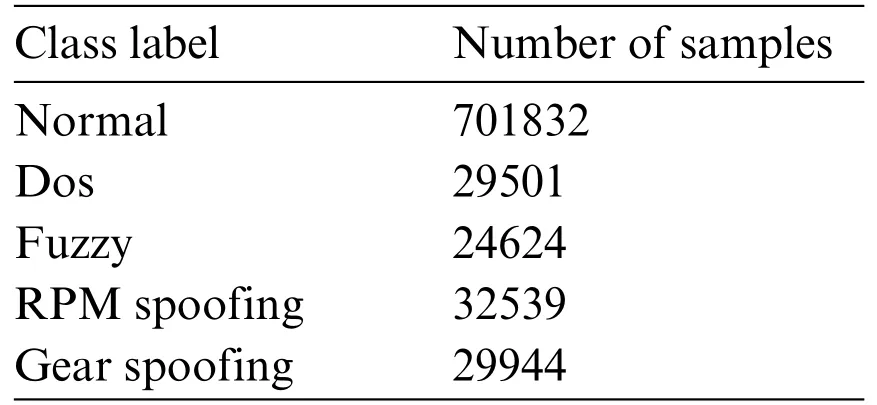
Table 1: Details of the 5%Car-Hacking dataset
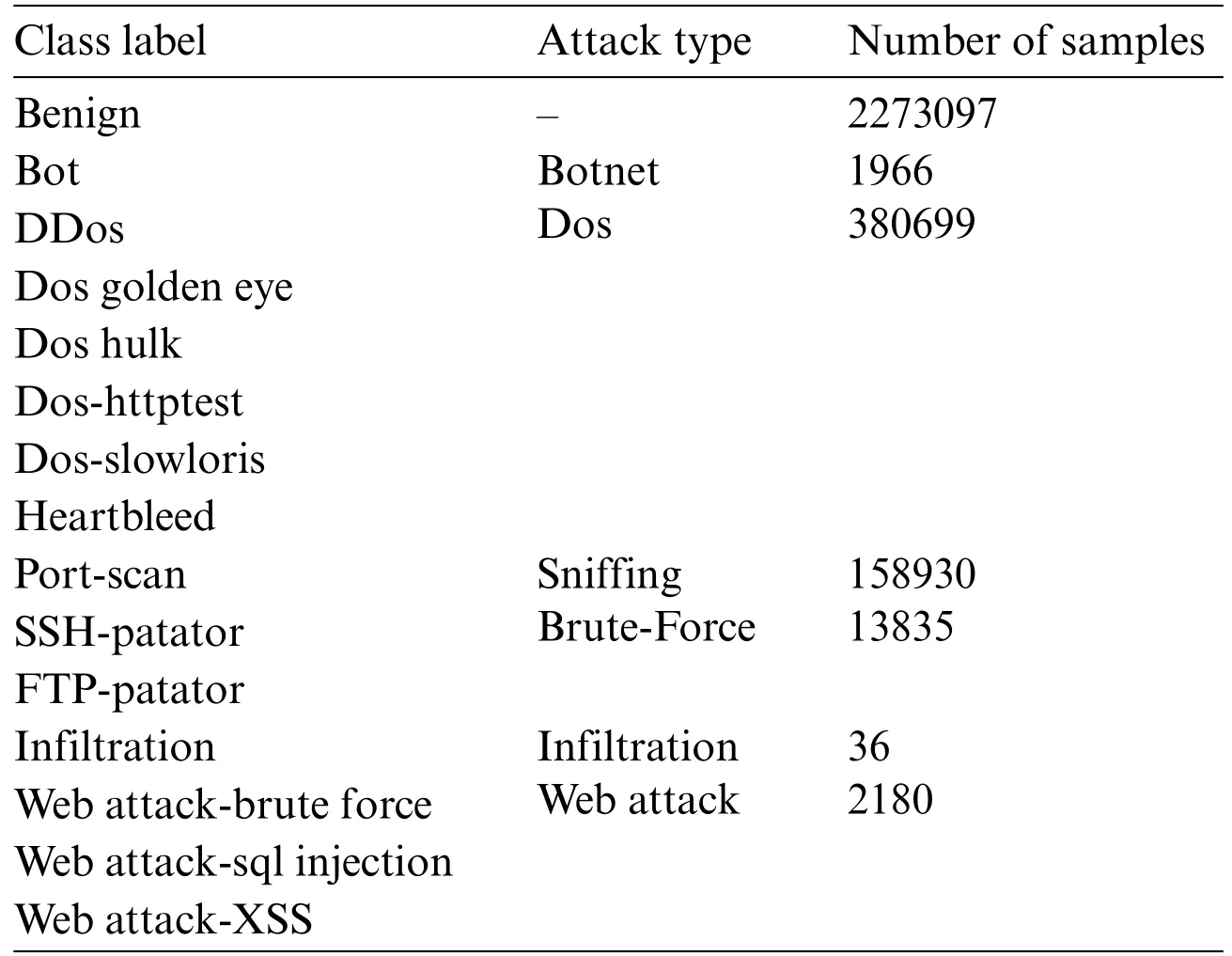
Table 2: Details of the CICIDS2017 dataset
The normalized tabular data is divided into chunks based on timestamps and feature sizes to exploit the temporal correlation of traffic data for the Recurrent Classifier(RC).For the Car-Hacking dataset,we select 27 consecutive samples to form an image with a size of 9×9×3.This dataset has 9 features,and the resulting image has 3 channels.For the CICIDS2017 dataset,we apply feature engineering to select the most relevant 20 features.Therefore,the transformed image size of the CICIDS2017 dataset is 20×20×3,based on 20×3 consecutive data rows.The labels of the images are assigned based on the highest proportion of attack types present.If an image contains no malicious attacks,it is labeled as“normal”.The shuffled datasets are then split into two parts,with 80%of the images allocated to the training dataset and the remaining 20%to the test dataset.
The evaluation metrics utilized in the analysis include accuracy,precision,recall,and F1-scores,which are calculated based on the elements of the confusion matrix:true positive(TP),false positive(FP),true negative(TN),and false negative(FN).The definitions of these metrics are as follows:
The training time of each method was also recorded.
5.2 Performance Analysis
The comparison results are presented in Tables 3 and 4.Multiple experiments were conducted to determine the optimal parameters for the Echo State Network(ESN).In the notation ESN-A-N,Arepresents the leakage rate,andNdenotes the number of reservoir nodes.For the Car-Hacking dataset,the number of reservoir nodes was fixed at 100,while for the CICIDS2017 dataset,it was set to 1000 due to the increased complexity of the attack patterns requiring more neurons for detection.In the experimentation process,the leakage rate was varied from 0.2 to 0.8 with an interval of 0.2.After identifying the best leakage rate for the Car-Hacking dataset,the number of nodes was gradually increased to strike a balance between performance and training time.
The training time of the ESN model consists of two parts: the iteration time for updating the reservoir state and the time for ridge regression.
From the results presented in Table 3 for the Car-Hacking dataset,it can be observed that when the number of reservoir nodes is fixed at 100,the best performance is achieved with a leakage rate of 0.6.As the number of nodes(N)increases,both the performance and training time increase.However,when the number of nodes reaches 200,the performance becomes saturated.It is important to note that while both ESN and CNN achieve 100%accuracy,precision,recall,and F1-scores,the training time of ESN is significantly faster compared to CNN-based methods.

Table 3: Performance comparisons on the Car-Hacking dataset
When analyzing the CICIDS2017 dataset(Table 4),it can be observed that the best leakage rate for this dataset is 0.4.The ESN-0.4-5000 method achieves an accuracy of 98.47%and a precision of 99.62%while only requiring 2531.0 s of training time.The performance of ESN on the CICIDS2017 dataset is slightly less significant compared to other methods,but it still demonstrates comparable performance while offering advantages in terms of training time and storage size.
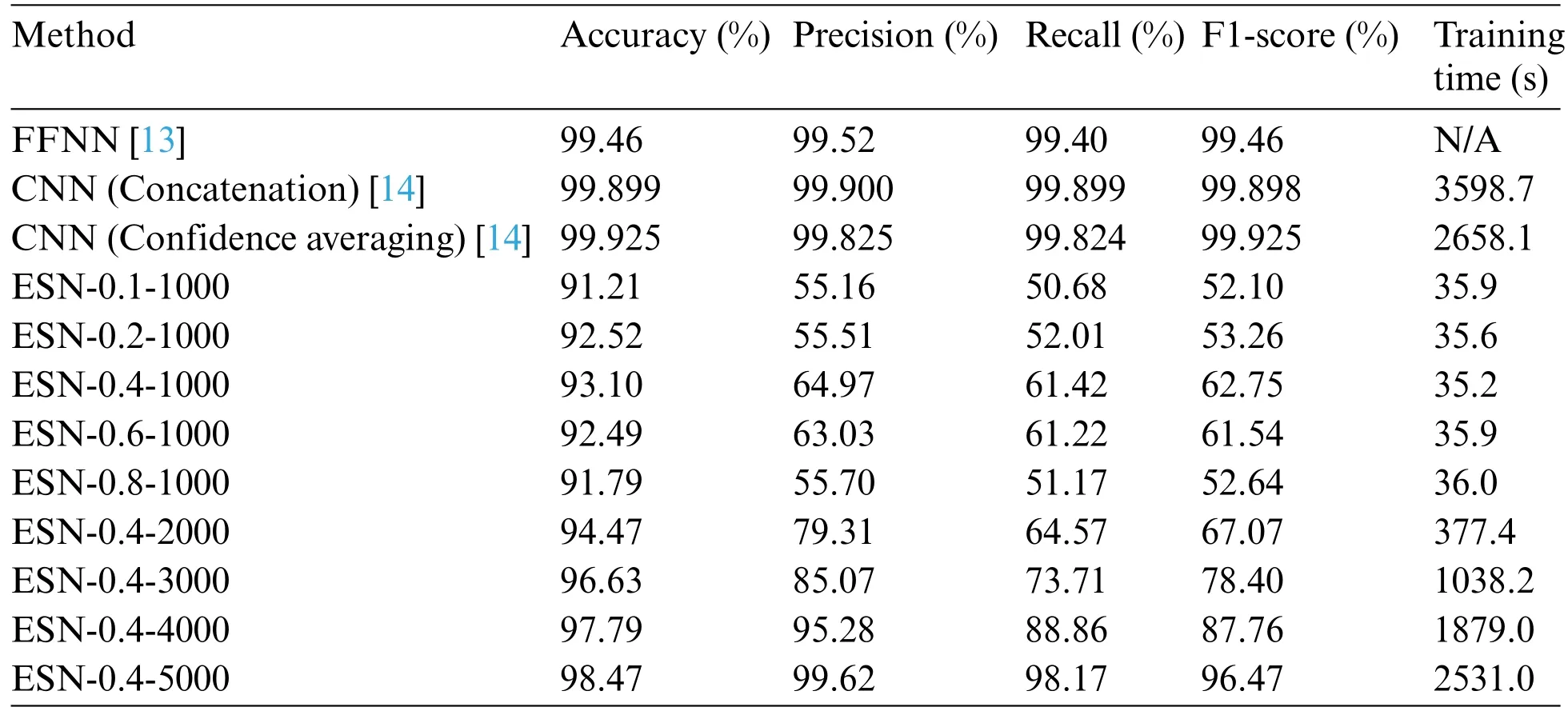
Table 4: Performance comparisons on the CICIDS2017 dataset
ESN also has a significant advantage in terms of model storage.The number of well-trained parameters,represented by the readout layer weights,for ESN is onlyNatt×(N+L+1),whereNattis the number of attack types(e.g.,Natt=6 in CICIDS2017),andLis the image length.This is in contrast to traditional CNN models such as VGG16,which have trained ImageNet weights of approximately 528 MB.
6 Conclusions
In this study,we proposed an RC-based IDS framework to protect IoV systems against intravehicle and external network attacks.This research marks the first example of applying RC in IoV intrusion detection,effectively mitigating the computational resource and memory space constraints associated with traditional machine learning models.The data preprocessing steps,including resampling,feature engineering,and data transformation,make this RC-based IDS framework more robust.We conducted experiments using both the Car-Hacking dataset and the CICIDS2017 dataset.The optimal number of nodes and leakage rate in the ESN were explored.The results indicate that our proposed framework performs well on intra-vehicle datasets with minimal training time.Although the superiority of the CICIDS2017 dataset is less significant,the comparable performance demonstrates lightweight properties in terms of training time and storage size.In future work,we plan to apply Reservoir Computing(RC)to detect zero-day attacks,aiming to further enhance the security of IoV.
Acknowledgement:The authors appreciate the valuable comments from the reviewers.
Funding Statement:This work was supported in part by the Open Research Fund of Joint Laboratory on Cyberspace Security,China Southern Power Grid (Grant No.CSS2022KF03),and the Science and Technology Planning Project of Guangzhou,China(Grant No.202201010388),the Fundamental Research Funds for the Central Universities.
Author Contributions:The authors confirm contribution to the paper as follows: original draft preparation: Jiarui Deng;draft review and edition: Wuqiang Shen,Yihua Feng,Guosheng Lu;conceptualization supervision and revision: Shanxiang Lyu.All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials:The Car-Hacking and CICIDS2017 datasets used in this paper can be accessed at https://ocslab.hksecurity.net/Datasets/car-hacking-dataset and https://www.unb.ca/cic/datasets/ids-2017.html,respectively.
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
杂志排行

Computers Materials&Continua的其它文章
- Fuzzing:Progress,Challenges,and Perspectives
- A Review of Lightweight Security and Privacy for Resource-Constrained IoT Devices
- Software Defect Prediction Method Based on Stable Learning
- Multi-Stream Temporally Enhanced Network for Video Salient Object Detection
- Facial Image-Based Autism Detection:A Comparative Study of Deep Neural Network Classifiers
- Deep Learning Approach for Hand Gesture Recognition:Applications in Deaf Communication and Healthcare