Image Inpainting Technique Incorporating Edge Prior and Attention Mechanism
2024-03-12JinxianBaiYaoFanZhiweiZhaoandLizhiZheng
Jinxian Bai,Yao Fan,Zhiwei Zhao and Lizhi Zheng
College of Information Engineering,Xizang Minzu University,Xianyang,712000,China
ABSTRACT Recently,deep learning-based image inpainting methods have made great strides in reconstructing damaged regions.However,these methods often struggle to produce satisfactory results when dealing with missing images with large holes,leading to distortions in the structure and blurring of textures.To address these problems,we combine the advantages of transformers and convolutions to propose an image inpainting method that incorporates edge priors and attention mechanisms.The proposed method aims to improve the results of inpainting large holes in images by enhancing the accuracy of structure restoration and the ability to recover texture details.This method divides the inpainting task into two phases:edge prediction and image inpainting.Specifically,in the edge prediction phase,a transformer architecture is designed to combine axial attention with standard self-attention.This design enhances the extraction capability of global structural features and location awareness.It also balances the complexity of self-attention operations,resulting in accurate prediction of the edge structure in the defective region.In the image inpainting phase,a multi-scale fusion attention module is introduced.This module makes full use of multi-level distant features and enhances local pixel continuity,thereby significantly improving the quality of image inpainting.To evaluate the performance of our method,comparative experiments are conducted on several datasets,including CelebA,Places2,and Facade.Quantitative experiments show that our method outperforms the other mainstream methods.Specifically,it improves Peak Signal-to-Noise Ratio (PSNR) and Structure Similarity Index Measure(SSIM)by 1.141∼3.234 db and 0.083∼0.235,respectively.Moreover,it reduces Learning Perceptual Image Patch Similarity (LPIPS) and Mean Absolute Error (MAE) by 0.0347∼0.1753 and 0.0104∼0.0402,respectively.Qualitative experiments reveal that our method excels at reconstructing images with complete structural information and clear texture details.Furthermore,our model exhibits impressive performance in terms of the number of parameters,memory cost,and testing time.
KEYWORDS Image inpainting;transformer;edge prior;axial attention;multi-scale fusion attention
1 Introduction
Image inpainting is a challenging computer vision task that aims to construct visually appealing and semantically plausible content for missing regions.It has various practical applications,including restoring damaged photos [1],removing unwanted objects [2],and enhancing image resolution [3].Initially,traditional diffusion-based methods [4,5] were used for image inpainting.These methods gradually spread pixel information into the surrounding areas of damaged regions and synthesize new textures to fill the holes.While effective for repairing small damaged areas like cracks,these methods tend to produce blurry results as the size of the missing regions grows.Pioneering samplebased methods were then developed for image inpainting[6,7]which synthesize texture by searching for matching similar sample blocks in the undamaged areas of the image and copying them to the corresponding positions in the missing regions.These approaches often produce high-quality texture but may introduce incorrect structure and semantics in the restoration.
With the rapid advancement of deep learning in image processing tasks,researchers worldwide have introduced various deep learning techniques to tackle these challenges.Convolutional neural networks(CNNs)[8–10]have been widely adopted in methods that follow an encoder-decoder architecture and incorporate the adversarial idea of generative adversarial networks (GANs) [11].These methods aim to reconstruct missing regions by learning high-level semantic features.Nonetheless,the localized inductive bias of convolutional operations and the limited receptive field make it difficult for the model to learn globally consistent textures in semantics.To address these limitations,attention mechanisms have been introduced in methods [12,13] to find the most similar feature blocks to the masked regions in the feature space of known regions.This enables long-distance feature block matching.However,for images with large missing regions,the attention mechanism cannot provide sufficient information for restoration,resulting in blurred texture details and increased artifacts in the restoration results.In comparison to CNN-based methods,transformer-based solutions [14,15]leverage the strengths of transformers in capturing long-term correlations and extracting global features to reconstruct low-resolution images and then provide CNN-based upsamplers to restore texture details.Nonetheless,the above restoration scheme ignores the significance of the overall image structure,resulting in inconsistent boundaries and a lack of semantics in the results.Moreover,there are high computational and storage costs associated with model training and inference processes.Some methods use edge [16],gradient [17],or semantic [18,19] information for structural restoration.For example,Nazeri et al.[20]utilized the Canny operator to extract edge information from the defective region.Subsequently,the refinement network utilizes the reconstructed edge maps as structural information to guide the content repair continuously,which enhances the repair of structural details to a certain extent.Differently,Xiong et al.[21] utilized predicted foreground contour maps to guide image completion,ensuring the rationality of image content filling and avoiding overlap with foreground objects.However,the above inpainting methods based on structural constraints have certain limitations.Firstly,due to the spatial invariance and local induction priors of convolutional neural networks,they may not perform well in understanding global structures,leading to subpar edge prediction results.Secondly,many factors influence successful texture synthesis in image inpainting.While focusing on structural details is important,successful texture synthesis also requires the effective utilization of long-range features to capture rich contextual information.
To address these issues,this paper presents a two-stage image inpainting framework that combines edge prior and attention mechanism (EPAM).Our framework uses the transformer architecture to accurately predict the edge structure of the defect area.Then in the image inpainting stage,effective edge structures are used to constrain the image content,so as to reconstruct visually plausible and texture-clear images.In summary,the contributions of this paper are as follows:
(1) In the edge prediction phase,this paper proposes an efficient transformer-based edge prediction(TEP)module to accurately extract edges of incomplete regions.Unlike existing CNN-based methods,our TEP module achieves more accurate and comprehensive structural restoration.In the TEP module,axial attention with relative position encoding is used.This improves position awareness while significantly reducing computational complexity,ensuring a balance between performance and efficiency.
(2)In the image inpainting phase,a multi-scale fusion attention(MFA)module is designed.This module aggregates contextual feature information at different levels using dilated convolutions with varying ratios.Additionally,an efficient channel attention mechanism is applied to reduce the impact of redundant features.Furthermore,the attention transfer network is introduced to fully integrate shallow texture details and deep semantic features,thereby avoiding unreasonable or contradictory regions in generated images.This allows our model to accurately reconstruct texture details under the guidance of the edge structure.
(3) Experiments are carried out by comparing the EPAM model to existing state-of-the-art approaches.The EPAM model demonstrates superior performance in both qualitative and quantitative assessments,as observed in the CelebA[22],Facade[23],and Places2[24]datasets.
2 Related Work
In recent years,many methods have been proposed to improve the results of image inpainting by incorporating prior knowledge of image structure.For example,Liao et al.[25] built upon the CE [8] and introduced an edge-aware context encoder to predict the image edge structure.This approach facilitated the learning of scene structure and context.However,the inpainted regions in their results often suffered from significant blurring and artifacts.Cao et al.[26]utilized an encoderdecoder structure to learn a sketch tensor space composed of edges,lines,and connection points.They also introduced a gated convolution and attention module to enhance local details under costsaving conditions.However,this design is not suitable for structural restoration in facial or similar scenes.Some methods have also attempted to incorporate both image structure and texture details to guide image completion.For example,Liao et al.[19]designed a semantic segmentation guidance and evaluation mechanism to interact to iteratively update semantic information and repair images.Nonetheless,obtaining accurate semantic information for images with complex backgrounds can be challenging.Guo et al.[16] proposed a method that shares information between the two branches of texture generation and structure prediction.They also fused an attention module with learnable parameters to further enhance global consistency.Nevertheless,when applied to recover natural images with irregular defects,such coupled methods often lack explicit structural details.
Transformer [27] was originally proposed as a sequence-to-sequence model for machine translation tasks and was later improved and applied to computer vision tasks such as object detection,video processing,and image processing [28].Researchers have recently started exploring the use of transformers for image restoration problems.Wan et al.[14]were among the first to use transformers for image inpainting.They employed bi-directional attention and a masked language model objective similar to BERT[29]to reconstruct low-resolution images with diverse appearances.Zheng et al.[30]designed a mask-aware transformer content reasoning model,which uses a restricted convolutional neural network module to extract tokens.In this model,the transformer encoder uses a replacement weighted self-attention layer to capture the global context,reducing Proximity dominant effects that give rise to semantically incoherent results.Nevertheless,this method cannot understand and imagine high-level semantic content.
The existing image inpainting methods based on structural constraints ignore the positive influence of long-distance features when dealing with large-area irregular defects.Once the reconstructed structure is missing or incorrect,the repair effect obviously deteriorates.It is worth noting that the above transformer-based methods primarily focus on image reconstruction to obtain low-resolution repaired images.However,one limitation of such methods is their long inference time,which can be a drawback in practical applications.For the structural reconstruction problem,edge maps are preferred over smooth or semantic images as they provide accurate structural information of images and have stronger resistance to noise and other interference factors.This paper therefore introduces a novel TEP module that uses the transformer to reconstruct the overall edge structure of an image.The TEP module outperforms CNN-based methods in terms of performance.To address the issue of artifacts in the restoration results,where texture details and inconsistent boundaries,this paper proposes the MFA module.This module enhances the texture inference ability and independently synthesizes new content in regions lacking structural information by mining distant features at different levels.In general,the EPAM model performs structure prediction and texture generation for images by decoupling,which improves the model’s representational ability and ensures the consistency of the overall structure and detailed texture of the restored images.
3 Proposed Method
This paper proposes an image inpainting model that combines structural priors and attention mechanisms.The overall model architecture is shown in Fig.1.The model consists of two cascaded generative adversarial networks (GANs),where the output of the first-stage generator serves as the input of the second-stage generator.These two-stage networks together form an end-to-end inpainting model.In the first stage,the edge prediction network utilizes grayscale inpainted images and incomplete edge information to predict plausible edge contours within the defect regions.Subsequently,the second-stage network utilizes the edge prediction map as a structural prior along with the incomplete RGB image to synthesize suitable texture details within a locally enclosed region surrounded by edges.This process ultimately completes the inpainting task.
In the edge prediction stage,the autoencoder serves as the generator of the edge prediction network,while the PatchGAN architecture is the discriminator.In view of this,this paper proposes the transformer-based edge prediction (TEP) module,which is embedded into the information bottleneck section of the autoencoder.Notably,instead of using deeply stacked convolutional layers,the TEP module uses a transformer-based architecture that allows all visible pixels to have equal flow opportunities,resulting in expressive global structures.In addition,relative position encoding[31]and axial attention blocks[32]are introduced into the TEP module,to enhance spatial relations and reduce memory overhead.Existing attention-based models often suffer from color discrepancies,blurriness,and boundary distortions in the inpainted images.To address these issues,the Multi-scale Fusion Attention (MFA) module is introduced.Cascaded MFA modules are integrated after the encoder.The MFA module captures deep features in different receptive fields by using dilated convolution with varying expansion rates so as to better integrate global contextual information with local details.Then,an Attention Transfer Network(ATN)[33]is constructed on feature maps at four scales to enhance local pixel continuity and make effective use of long-distance dependencies,which notably improves the quality of image inpainting.

Figure 1:Overall network structure.Our proposed EPAM is made up of two sub-networks.The upper half is the edge prediction network,and the lower half is the image inpainting network
The edge prediction network contains a generatorG1and a discriminatorD1.Similarly,the image inpainting network consists of a generatorG2and a discriminatorD2.It,Igs,andEtare the original image,the corresponding grayscale map,and the edge structure map,respectively.In the binary maskIM,the value 1 denotes the hole region pixels and the value 0 denotes the other region pixels.Then,the incomplete image is expressed as=It⊙(1-IM),incomplete grayscale image asIMgs=Igs⊙(1-IM),and the defective edges as=Et⊙(1-IM),where ⊙is element-wise product operation.Then the edge prediction follows the following Eq.(1):
whereEcompis the synthesized edge prediction map.The operation of the image generator is denoted byG2(·).The following Eq.(2)represents the process of image restoration:
Finally,the inpainting output with the same original size is obtained by using Eq.(3).
3.1 Edge Prediction Network
3.1.1 Transformer-Based Edge Prediction Module
The transformer architecture was originally used to solve natural language processing (NLP)tasks.This architecture is entirely based on self-attention and can directly model longer-distance dependencies between input sequences.Recently,researchers have applied it to computer vision tasks and achieved remarkable results.Inspired by ViT[34],this paper introduces the transformer decoder from [27] into the TEP module and then reconstructs the edge information based on the shallow features of the encoder’s output.
In Fig.2,the input feature of the TEP module is represented asF∈RH×W×Cwith height H,width W,and channels C,specifically 32×32×256.The input is reshaped using the View operation to obtain=RC×D,(D=H×W).The processed inputis then embedded in the positional encodingPEand fed into the Transformer Decoder.The output featureYafter position coding is defined as Eq.(4).
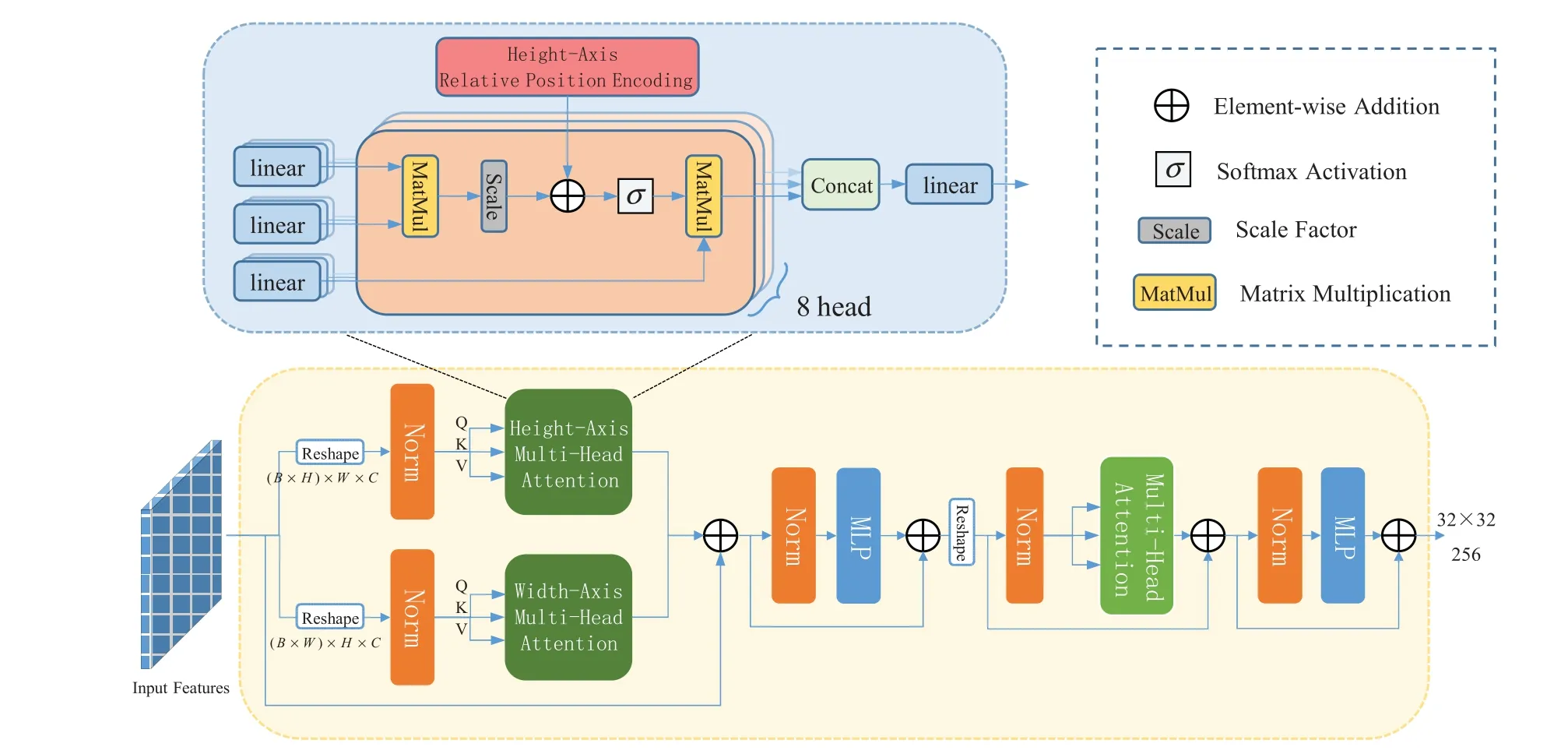
Figure 2:Architecture of the proposed transformer-based edge prediction(TEP)module
To reduce the consumption of feature map computation and storage in the self-attention layer,both the axial attention module and the standard attention module were introduced in the TEP module.Axial attention modules can be implemented by reshaping tensors on the width and height axes,which are then processed with dot-product-based self-attention,respectively.As shown in Fig.3,uni-directional attention only focuses on the contextual constraints before the token.Although bidirectional attention can pay attention to all positions before and after the token,its computational complexity up to isOAxial attention can be the available context in the row and column directions of the token (i.e.,focus on the available information before and after the token),which makes the model more efficient,in addition to the lower computational complexity of axial attention,which is onlyOTo ensure stable training,layer normalization[35]is applied before the featuresYare fed into the axial attention module.In addition,a learnable relative position encoding(RPE)[31]is provided for this module to improve the spatial relationship and the accuracy and effect of inpainting.The following Eq.(5)is the formula of the axial attention score based on the width axis and height axis.yhiandyhjare the feature vectors of columnsiandjof the height axis ofY.Wwq,Wwk,Whq,andWhkare the weight matrix of queries and keys in the width and height axis;is the relative position encoding matrix between the width axisiandj;is the relative position encoding matrix between the height axisiandj.The scaling factoris to find the gradient more stable when backward spreading.
The attention weights are obtained by Softmax operation.The outputof the axial attention layer is given by Eq.(6).

Figure 3:Differences between uni-directional,bi-directional and axial attention
In addition,the standard attention moduleAttentionnormis utilized to learn the global correlation,and then repeat the process of Eq.(7)to obtain the final outputThe specific process is defined as the following Eqs.(8)and(9).
3.1.2 Design of Edge Generator and Discriminator
The edge generator in this paper follows a self-encoder structure to predict edges through encoder data compression,bottleneck layer feature reconstruction,and decoder decompression for a given image feature∈RH×W×C.In the encoding stage,the encoder first uses a 7 × 7 convolution with a reflective padding parameter of 3 and a stride of 1 to obtain rich features,which will adjustto a size of 256 × 256 × 64.Then three consecutive 4 × 4 convolution layers with a stride of 2 are applied to obtain a shallow featurewith a dimension of 32 × 32 × 256.Different from patchbased embedding methods,the above convolution operation injects a beneficial convolution inductive bias for the TEP module.The bottleneck layer does not use the convolution-based residual block but chooses to stack eight TEP modules based on the transformer structure to form the information bottleneck layer to enhance the representation ability of feature information and the ability to capture global structural information,and then complete the missing edge information.Unlike convolutions,self-attention mechanisms can capture non-local information from the entire feature map.However,the computational cost of the similarity calculation is quite large.To address this,the TEP module,the alternating use of the axial attention layer and the standard attention layer is adopted.This ensures that the generator utilizes the global context information to complete image edges that align with overall semantics while considering the performance and parameter quantity of the transformer.In addition,the axial attention layer can acquire multi-directional features by separately computing attention on the height and width axis,thereby enhancing the orientation awareness of feature maps.After passing through the bottleneck layer,a reconstructed feature with a dimension of 32×32×256 is obtained.The features are then upsampled to 256×256×64 by using a 3-layer transposed convolution with a convolution kernel size of 4 × 4,zero padding of 1,and a stride of 2.Subsequently,the output is adjusted to 256×256×1 through a convolution with a convolution kernel size of 7×7,a reflection filling parameter of 3,and a step size of 1,so the predicted complete edge map is obtained.In addition,each convolutional layer of the edge generator adopts instance normalization,which speeds up the model convergence while improving the nonlinear representation of the feature extraction module.Additionally,a ReLU activation function is applied immediately after each convolutional layer to reduce the gradient disappearance phenomenon.
To improve the network’s attention to local details during training,the PatchGAN[36]architecture is used as the basic framework of the edge discriminator.It consists of 5 layers of convolution with strides of 2,2,2,1,1 and a kernel size of 4 × 4.Spectral normalization [37] and the Leaky-ReLU activation function are applied after each convolutional layer.After 5 layers of convolution operations,the input image is converted into a single-channel feature map with dimensions of 30 ×30.Ultimately,the Sigmod function is used to map the output to a scalar in the range of[0,1],which can effectively distinguish the authenticity of the input samples and promote the generation of highquality restoration results.
3.2 Image Inpainting Network
3.2.1 Multi-Scale Fusion Attention Module
In the texture synthesis stage,traditional methods often extract feature information from shallow details to high-level semantics through convolutional layer stacking.However,this approach has limitations.The extraction of rich spatial structural information and texture details is performed serially with a fixed-size convolutional kernel,leading to varying degrees of feature loss.This also exacerbates inconsistency in global contextual information and causes difficulty in capturing global structural information from distant pixels.To address this problem,the MFA module is introduced.It first extracts information at different scales in parallel by applying convolution operations with different expansion factors to the input features.Then,the features at each scale are scaled and fed into the ATN module to facilitate the transfer of information between features at different levels.This helps the model to better understand the details and structures in the image,resulting in improved restoration quality and accuracy.In addition,the utilization of efficient channel attention[38]and pixel attention[39]enables the model to selectively focus on important channels and pixels,thus reducing unnecessary computations and parametric quantities.The residual structure and skip connections help to avoid gradient explosion and network convergence difficulties.See Fig.4 for details.
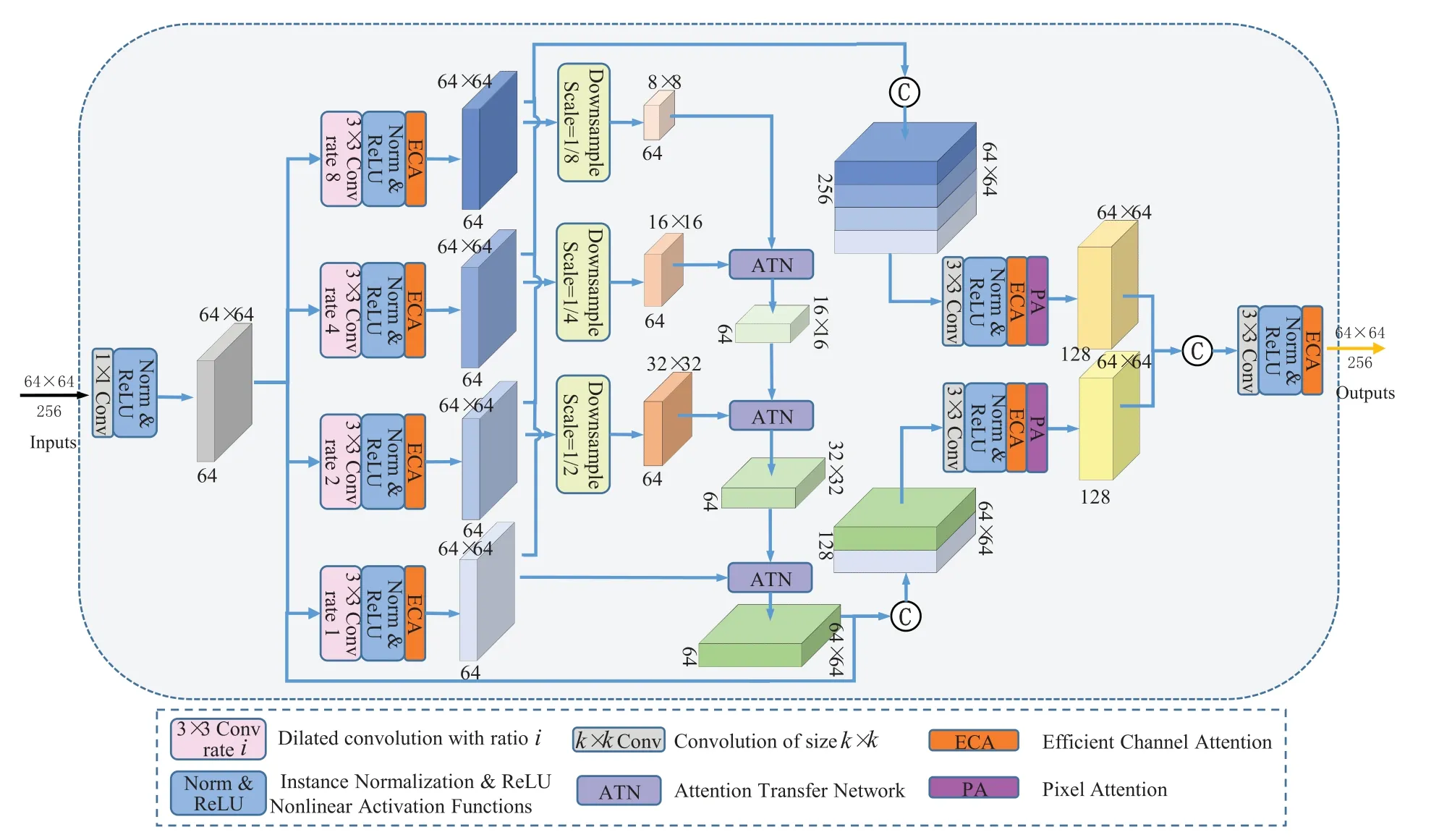
Figure 4:Architecture of the proposed multi-scale fusion attention(MFA)module
Specifically,a 1×1 convolution operation is used to transform the dimension of the input featureFinof the MFA module from 64×64×256 to 64×64×64.This paper usesf1×1(·)to represent the 1×1 convolution operation,andτto represent the instance normalization and ReLU activation function.The transformed input featureis shown in Eq.(10)as follows:
Subsequently,Parallel expansion convolution is used to extract multilevel featureswith expansion ratesRiof 8,4,2,and 1 (i=1,2,3,4) and convolution size of 3 × 3.Convolution with a smaller expansion rate can better perceive texture and position information whereas convolution with a larger one can perceive advanced and global feature information.Then,the Efficient Channel Attention (ECA) module is introduced,which effectively captures the information of cross-channel interactions and reduces the effect of redundant features.The computational formula can be expressed by the following Eq.(11):
Since deep feature maps are usually more compact,scaling is applied to the features of each layer.·)is the bilinear interpolation downsampling operation with scaling factorSi.As shown in Fig.4,the scaling factorSiis 1/8,1/4,1/2,and 1 in turn.The scaling process defines the following Eq.(12).
Then,Attention Transfer Network (ATN) [33] is introduced to guide the complementation of low-level features layer by layer from high-level features,which makes the complementation content semantically sound and texture clear.ATN(·)is the attention transfer operation,andis the feature map reconstructed by the ATN of thei-th layer.The specific operation can be expressed as Eq.(13).
Local residual connections are built on the feature map of the last ATN reconstruction to reduce information loss.After 3 × 3 convolution,τlayer,ECA layer,and Pixel Attention (PA) layer,the feature map F is obtained,which is defined as the following Eq.(14):
In addition,to ensure the consistency of local contextual feature information,operations such as skip connection and 3 × 3 convolution are employed to fuse multilevel featuresof the same size into a 64×64×128 feature map.Finally,the fused output of feature mapsandis expressed in the following Eq.(15):
3.2.2 Design of Image Generator and Discriminator
Image generators are an improvement over autoencoders.Since the bottleneck layer does not use the transformer structure,inputting a large-size feature map into the bottleneck layer will not cause excessive computational complexity.In this case,the encoder only downsamples to a feature map dimension of 64×64×256.To synthesize realistic textures in different regions,the bottleneck layer employs stacked 4 MFA modules instead of fully connected layers.Through hierarchical atrous convolutions and attention transfer strategies,the generator is able to synthesize semantically correct new content independently even in the absence of local edge information.Otherwise,the image generator has the same network structure and parameter settings as its counterpart in the edge generator.
The image discriminator has a similar structure to the edge prediction discriminator.It uses a 70 × 70 PatchGAN discriminator network,which consists of five layers of convolutions with a kernel size of 4 × 4.The discriminator network performs spectral normalization and Leaky-ReLU activation function processing after each layer of convolution operation.The output of the last layer is a two-dimensional matrix ofN×N,where each element corresponds to the true or false value of a 70 × 70 region block.The average value of all elements is used as the output value of the discriminator.Compared to the traditional GAN discriminator,the PatchGan discriminator determines the authenticity of each Patch,which allows more attention to texture details and thus improves the quality of the generated image.
3.3 Loss Functions
3.3.1 Loss of Edge Prediction Network
To obtain a clear and realistic edge prediction map,the edge prediction network uses a joint loss for model training,including adversarial loss[11]and feature matching loss[40].Given the mathematical expectation E,the discriminator functionD1,the expression for the adversarial losscan be written as Eq.(16).
The feature matching lossLfmevaluates the quality of generated edges by measuring the Euclidean distance between the predicted edge and the original edge in the feature space.LetSdenote the total number of layers ofD1,denote the activation map of thek-th layer ofD1,Nkdenote the number of elements in,and‖·‖denote the Euclidean distance.This loss can be defined as Eq.(17).
Let the loss weightsandαfmdenote the weights of the adversarial loss and the feature matching loss,respectively.The joint lossLEof the edge prediction network is expressed as the following Eq.(18):
3.3.2 Loss of Image Inpainting Network
To ensure the image inpainting result has reasonable semantic content,consistent structure,and clear texture,this paper uses various loss functions including adversarial loss,perceptual loss[41],style loss[42],and reconstruction loss to train the image inpainting network.The network uses Eq.(19)to represent the adversarial loss
Next,the pre-trained VGG-19 [43] network is adopted to convert the differences between the pixel values of the repaired imageIpredand the real imageItinto differences in the feature space so as to better preserve the high-level semantic information of the images.The following Eq.(20)is the formula of the perceptual lossLperc,whereMkis the feature map size of thek-th layer,andϕkis the feature representation of thek-th layer in the loss network.
Style loss usually uses the Gram matrix (gram) to calculate the difference of feature maps,expressing the correlation of style features on different channels,so that the inpainted image is closer to the reference image’s style.LetGϕk=ϕkT(·)ϕk(·)be the Gram matrix constructed byϕk.The style lossLstyleis specifically defined as Eq.(21).
The reconstruction lossLrecis minimized by theL1loss to calculate the absolute difference between the output resultIpredand the real imageIt.This ensures that the overall contour of the result is roughly consistent with the target.Its specific calculation process is shown in Eq.(22)below:
The total lossLG2of the second-stage network is expressed by Eq.(23).
4 Experiments
4.1 Experimental Design and Implementation
The experimental hardware configuration in this paper is a single Intel(R) Core i7-11700 CPU,a single NVIDIA GeForce RTX 3090 24 GB GPU,64.0 GB RAM,and the software environment is Windows 10,Pytorch v1.7.0,CUDA v11.0.
4.1.1 Experimental Datasets
Training and evaluation were conducted on 3 publicly available datasets: CelebA [22],Facade[23],and Places2 [24].The CelebA dataset contains 202,599 face images of celebrities and was commonly used in face-related computer vision experiments.The Places2 contains various unique scene categories,such as restaurants,beaches,courtyards,valleys,etc.The Facade dataset mainly consists of highly structured facades of cities worldwide.The distribution of the dataset in this paper is shown in Table 1.In terms of irregular masks,the test set of the irregular mask dataset proposed by Liu et al.[44]is adopted,which contains 12,000 masks equally divided into 6 intervals.During the experiments,images were randomly masked using the mask test set with different scale ranges.All images and irregular masks were resized to 256×256 pixels.

Table 1: Setup of the CelebA,Facade,and Places2 datasets
4.1.2 Parameter Settings
Referring to the parameter settings of the EC model,Both the two-stage network are trained with Adam optimizer(β1=0.0,β2=0.9),the batch size is 8,and the initial learning rates of generatorG1,G2,and discriminatorD1,D2are 1×10-4and 1×10-5,respectively.The experiments in this paper learn to generate realistic samples faster by giving the generator a higher learning rate.In Table 2,this paper conducts 5 sets of experiments on Attention head and embedding dimension.When the Multi-Head Attention of the TEP module is set to 8 and the embedding dimension is set to 256,the model parameter count is reasonable and the accuracy and recall are the highest.
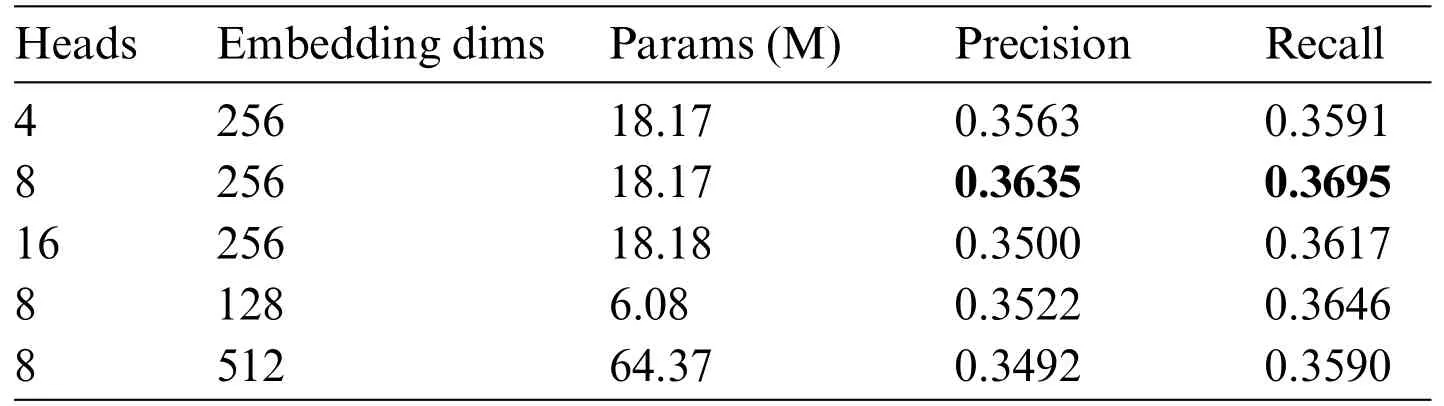
Table 2: Performance of edge prediction network with different combinations of hyperparameters
For the weights of different loss terms in the two-stage model,this paper adjusted one weight at a time for comparison experiments based on the parameter settings of the EC method.Specifically,the network restarted training after adjusting the weight parameters each time.After 500 epochs,the model ends training and is saved.Eventually,the loss weightsandαfmof the edge prediction network were set to 1 and 15,respectively.The loss weights of the image restoration network were set to=0.2,αperc=0.1,αstyle=200,andαrec=0.5,respectively.As can be seen in Fig.5,whenis set to 0.8,there are breaks in the lines around the window.Whenis set to 1.2,the predicted edges look reasonable but the window in the middle of the mask is incorrectly predicted as a line.When the weight of feature matching loss is 13.0,there are busy lines in the defective region,which may affect the subsequent repair work.When the weightαfmis 17.0,the generation of lines beyond the windows is unreasonable.As can be seen from Fig.5c,according to the weights set in this article,the model predicts lines with high local closure and consistent semantics.The experiments on the weights for the second stage of the network were conducted with the assurance of the consistency of the edge information used.As can be seen in Figs.6c and 6d,too large or too small weights for adversarial loss can adversely affect the color of the repaired windows.Other unreasonable weights also affect the repair performance of the model.It can be seen from Fig.6b that the weights set in this paper have some advantages.On the one hand,the color consistency between the inside and outside of the holes is enhanced,and on the other hand,the edges of the repair results are more visible.

Figure 5:Comparison of loss function weights of edge prediction network
4.1.3 Training Strategy
The training of the EPAM model involved three steps.First,G1was trained using grayscale images and edge binary images as training samples.After theG1loss was balanced,the learning rate was adjusted to 1×10-5for further training until the model converged,thereby generating a prediction edge.Next,the complete image edge information detected by the Canny operator combined with the damaged image was used as the input ofG2to trainG2separately.After the loss of the image generator was balanced,the learning rate was lower to 1×10-5for continued training until convergence.Finally,G1andG2were cascaded,and the edge discriminatorD1was removed.After that,the generatorsG1andG2were trained end-to-end at a learning rate of 1×10-6until the model converged.

Figure 6:Comparison of loss function weights of image inpainting network
4.1.4 Implementation Details
Fig.7 shows the training loss plot of the proposed model on the Places2 dataset.Throughout the training process,the loss values of the latest batch of data were recorded every 5000 iterations.Both phases of the network underwent 2 million iterations each.Due to the large span of each loss value in the network,the red area of the curve was enlarged for better visualization.Fig.7a shows the variation tendency of different loss functions during the training of the edge prediction network.The adversarial loss ofG1fluctuates within the range of(0.5,1.7),and the adversarial loss ofD1oscillates in a smaller range of (0.45,0.75).This indicates thatG1andD1are undergoing adversarial training and gradually approaching a balance.As the number of iterations increases,the feature matching loss stabilizes the training by constraining the outputs of the intermediate layers of the discriminator.As shown in Fig.7b,the reconstruction loss,perceptual loss,and style loss gradually decline as the training progresses.This suggests that the gap between generated samples and real samples at the feature map or pixel level is narrowing,and the quality of generated samples is steadily improving.
4.2 Experimental Results and Analysis
To quantitatively evaluate the efficiency of the proposed EPAM model,this model is compared with some of the advanced inpainting algorithms,including EC [20],CTSDG [16],ICT [14],MAT[45],and PUT [46].To reflect the generalization of the proposed method,irregular masks,center rectangle masks,and human-labeled masks are randomly used to perform occlusion experiments on samples for qualitative comparison.In addition,extensive quantitative comparisons,ablation studies,and visualization analysis are conducted to demonstrate the effectiveness of TEP and MFA.
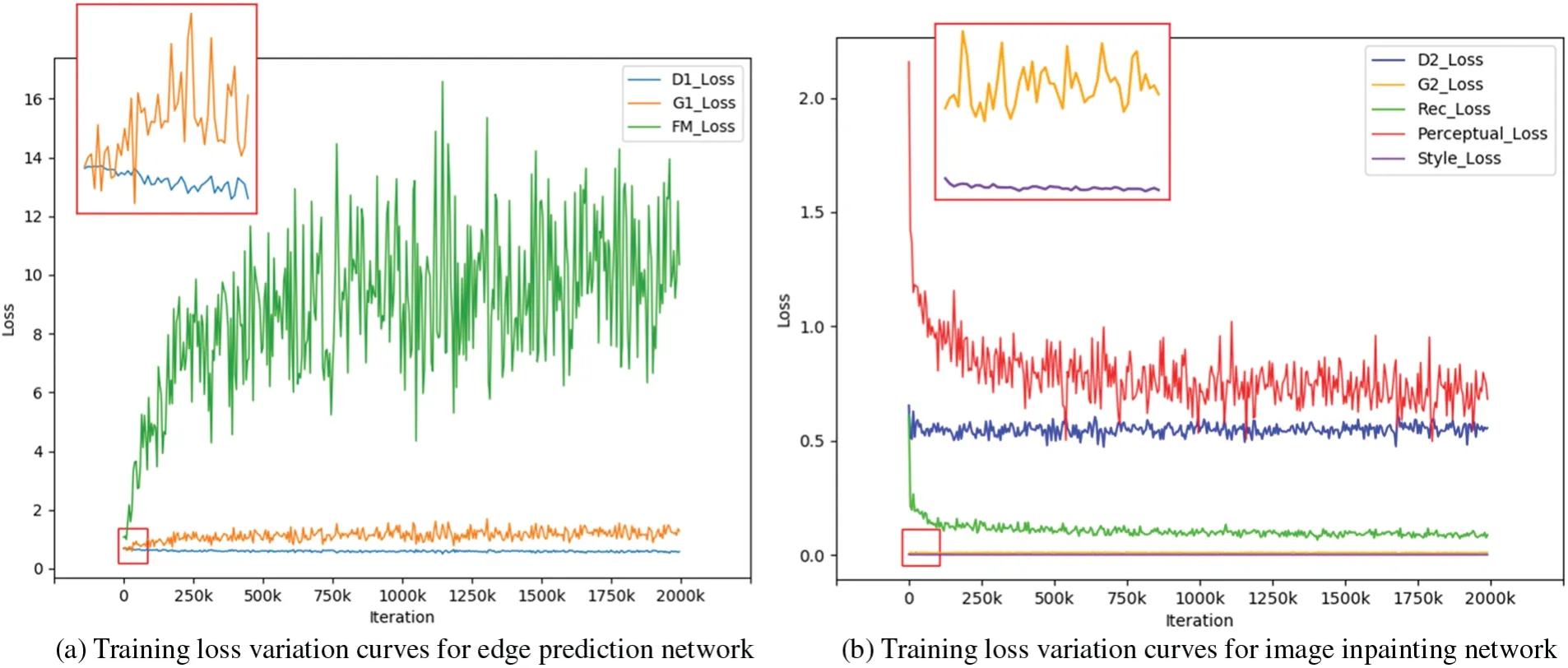
Figure 7:Two-stage training loss line charts of the EPAM model
4.2.1 Quantitative Comparisons
Four commonly used metrics are applied to evaluate the inpainting results of the proposed method and other methods for comparison.Peak Signal-to-Noise Ratio (PSNR) is a widely used objective measurement for image quality,although its results may not align perfectly with human perception.Structure Similarity Index Measure (SSIM) uses use three factors in line with human perception to evaluate the similarity between images,namely brightness,contrast,and structure.The window size used for SSIM calculation is set to 51.Learning Perceptual Image Patch Similarity (LPIPS) [47]is a perception-based metric that quantifies the differences between images and can better reflect human perception and understanding of images.Mean Absolute Error(MAE)refers to the average absolute errors between two values.The evaluation scores of our method with those of state-of-the-art approaches on datasets with irregular mask ratios of 20%–40%,40%–60%,and random masks.
Table 3 presents the evaluation results on the CelebA dataset,where our model achieves the highest scores in both PSNR and SSIM.However,in some cases,our model may not rank as high in terms of LIPIPS and MAE.This discrepancy can be attributed to the use of dilated convolutions with different expansion factors to capture multi-scale context information and long-distance feature information of the defect image.The excessive zero-padding operation of the dilated convolution introduces certain edge artifacts in the patched image,which may affect these indicators.Distinct from other metrics,LPIPS compares the Euclidean distance between the repaired image and the feature representation of the real image obtained at an intermediate layer of a deep neural network.Therefore,there may be some similarities that cannot be captured by LPIPS,resulting in bias at the metric level.On the Facade dataset,our algorithm outperforms other methods by a significant margin in the first two metrics.This indicates that our algorithm is more effective in repairing fine structural details when dealing with highly structured objects.On the Places2 dataset,even though both PUT and MAT use the transformer architecture,our method consistently achieves superior performance across various metrics.This demonstrates the effectiveness of the proposed transformer-based edge prediction strategy and the multi-scale fusion attention strategy in improving the overall performance of the model.
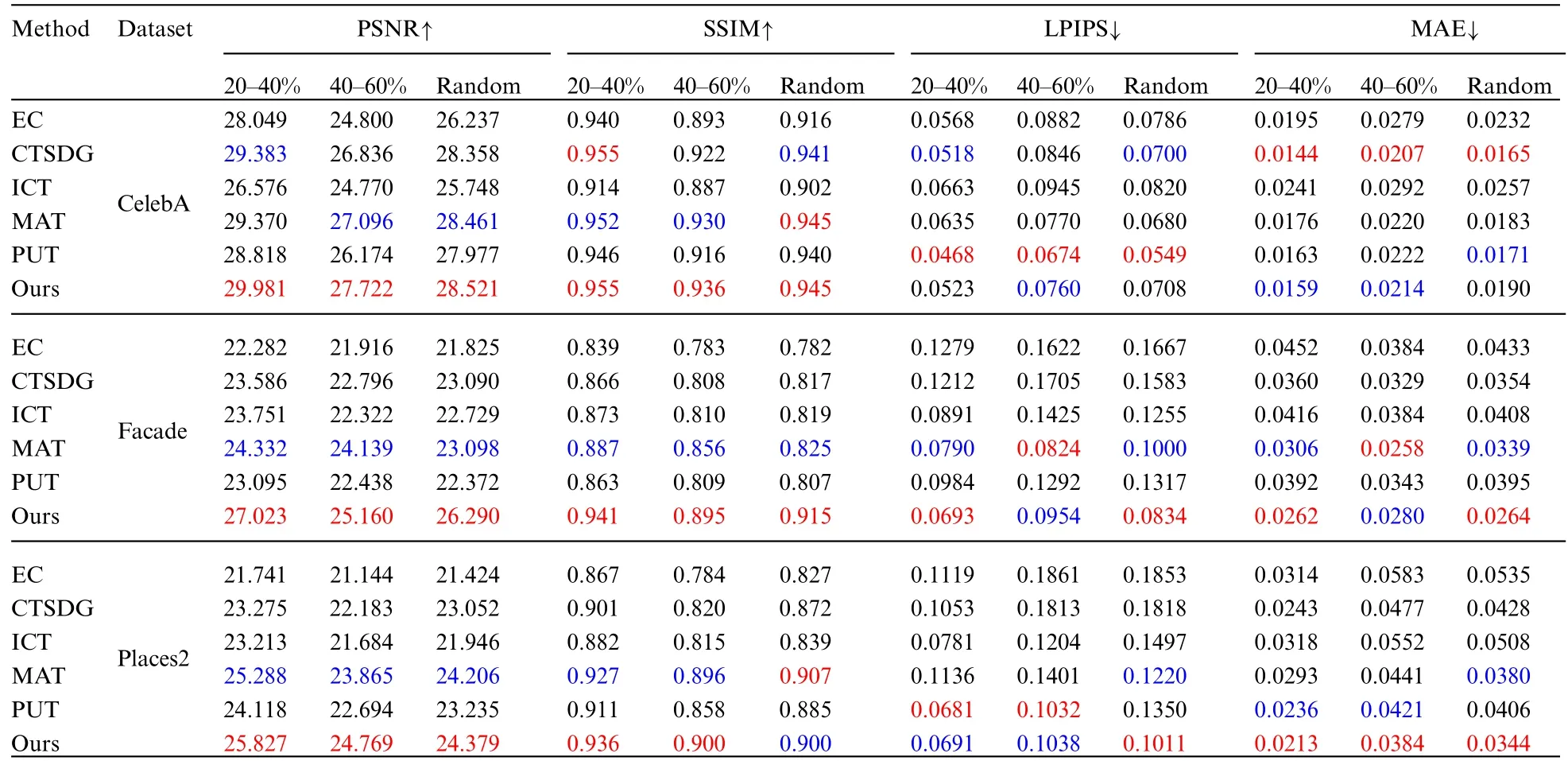
Table 3: Quantitative comparison results of our method with EC,CTSDG,ICT,MAT,PUT on CelebA,Facade and Places2 datasets with different mask ratios.↓indicates the lower the better.↑indicates higher the better.The best and second best results are in red and blue,respectively
4.2.2 Qualitative Comparisons
The EPAM model is compared with existing methods on the CelebA dataset containing face images with similar semantics.As shown in Fig.8,EC [20] is an inpainting method that starts with structure and then texture.However,the structure prediction in the previous step is incomplete,which will affect the detail restoration in the latter step.This results in blurry edges and unclear texture,as seen in the eyes and lips of the characters in rows 1 and 5 in Fig.8b.CTSDG attempts to balance texture and structure generation,but it often fails to achieve a good balance,leading to local boundary artifacts.For example,the mouth of the face image in Fig.8c exhibits distortion and missing parts,and the eyes do not appear natural enough.
ICT employs a transformer to reconstruct the visual prior and then uses conventional CNN to fill in texture details.However,the large-scale downsampling in this process causes the loss of important semantic information in the generated results.This is evident in the repaired eyes in Fig.8d,which are either missing or deformed.MAT addresses large missing areas using a mask perception mechanism but falls short in dealing with small missing areas.For example,the eyes in rows 2,4,and 5 in Fig.8e are asymmetrical and inconsistent in size.PUT improves image quality using a non-quantized transformer,but it cannot fully understand the semantic features.For example,in Fig.8f,the repaired eyeball part does not match the face.In comparison,our method excels in understanding global semantics and preserving more realistic texture details.It generates structurally and color-consistent face images,as shown in Fig.8g.

Figure 8:Qualitative comparison results of our method with existing methods on the CelebA dataset with irregular and artificially drawn holes
The effect of our method on the Facade dataset is visually analyzed,and the results are shown in Fig.9.When EC faces a large-scale rectangular defect,the windows of the building will be missing,resulting in noticeable color discrepancies in the restoration results.The visualization results of CTSDG demonstrate its inability to handle large holes,leading to the loss of essential components and image distortion.While ICT recovers occluded regions at the pixel level,it fails to capture the global structural semantics well.This can be observed in the irregularities of the windows and their surrounding contours in rows 1 and 2 of Fig.9d.MAT utilizes long-range context to reconstruct structures and textures.However,the reconstructed masked regions in row 2 of Fig.9e exhibit incoherent colors and unreasonable semantic objects.Although the image synthesized by PUT(Fig.9f) appears to produce reasonable results,it is plagued by noticeable artifacts.In contrast,our model not only infers reasonable structural-semantic information but also effectively alleviates mesh artifacts and loss of texture information in local regions,thereby enhancing perceptual quality.For example,in rows 1 and 2 of Fig.9g,the window edges repaired by our method exhibit clear outlines and visually appealing results.In addition,the small windows predicted by the mask area in row 3 are arranged regularly and possess reasonable semantics.

Figure 9:Qualitative comparison results of our method with existing methods on the Facade dataset with irregular,center-regular and artificially drawn holes
Our model is further evaluated on the Places2 dataset containing images with different semantics,as shown in Fig.10.In such challenging scenarios,the structure-texture-based methods such as EC[20] and CTSDG [16] cannot understand the global background well,resulting in incomplete and unreasonable restorations.In contrast,methods using the Transformer architecture(ICT,MAT,and PUT) demonstrate improved capability in capturing global context information for complex image inpainting tasks.Nevertheless,due to the lack of constraints on global structural information,these methods often exhibit boundary inconsistencies and missing semantics in the inpainting results.This can be observed in column 6 of Fig.10,where the target structure for occluded region reconstruction appears incoherent.In comparison to the above methods,our method incorporates a Transformerbased structure repair module that reconstructs the semantic content accurately.Additionally,our method employs an attention shift strategy,applied layer by layer to the MFA module,to combine shallow detail texture information and deep structural-semantic information based on a precise appearance prior.This strategy mitigates the loss of long-distance features in deep networks and greatly enhances the consistency between global and local features of the image.For example,rows 1–4 in Fig.10g show high-quality texture and structural details in missing regions.
To further demonstrate the effectiveness of our method,the trained model is compared with similar inpainting schemes(EC and CTSDG).Fig.11 shows the edge prediction and image inpainting results of EC,CTSDG,and our method on three datasets: CelebA,Facade,and Places2.Upon closer observation of columns 2 and 3,it becomes evident that the edge priors reconstructed by these inpainting methods fail to accurately predict semantic contours such as building windows and doors of drum washing machines.Similarly,it can be observed in columns 5 and 6 that although the color details are similar,the overall structure cannot show the characteristics of the original image.Overall,both EC and CTSDG are unable to restore reasonable images such as buildings and faces based on the biased edge prior.In contrast,our method introduces relative position coding and self-attention mechanisms to enhance the extraction capability of edge features.This enables the restoration of core edge information (Fig.11d) and target boundaries that align with the scene semantics in the central region of a wide range of masks.In addition,as shown in column 7 of Fig.11,the inpainting output generated by our method exhibits more detailed texture and a more realistic visual perception.Furthermore,in cases where there is insufficient priori information about local edges,the MFA module also fuses global contextual features and shallow features to guide the model to synthesize novel content,as shown in the square structure in the right gate in row 6 of Fig.11g.

Figure 10:Qualitative comparison results of our method with existing methods on the Places2 dataset with irregular and artificially drawn holes
4.2.3 Visual Analysis
To demonstrate the effectiveness of the TEP module in applying position-sensitive axial attention,the attention weights of the axial attention layer are visualized on the CelebA dataset.As shown in Fig.12,block 2 of the TEP module is chosen to visualize the heat map of the 8 heads of column(height axis) and row (width axis) attention,respectively.To better visualize the focus areas of each head,the 32×32 pixel Attention Map is enlarged to 256×256 and overlaid on the original image,creating a heatmap of the attention weights.It is worth noting that some heads learn to concentrate on relatively local regions,whereas others concentrate on distant contexts.For example,in column-wise attention,column heads 1,5,and 6 exhibit a preference for relatively local regions of the head,while column heads 2,3,and 8 cover the entire image.Regarding row-wise attention,row heads 1,2,and 3 are associated with local semantic concepts such as eyes,mouth,and nose of faces.Row heads 4,5,and 7 place greater emphasis on the long-distance row-wise contextual relationships.

Figure 11:Visual comparison of the proposed method against other structure-based methods on the CelebA,Facade,and Places2 datasets: (a) input corrupted image;(b)–(d) are the edge structures generated by EC [20],CTSDG [16],and our method,respectively;(e)–(g) are the corresponding inpainting effects of EC[20],CTSDG[16],and our method,respectively;and(h)Ground-Truth

Figure 12:Axial attention maps in block 2 mapped onto the original image
To verify the effectiveness of the ATN structure applied in the MFA module,the attention score heatmaps of ATN at different scales are visualized.Specifically,represents the ATN attention score heat map with a resolution of 8×8 in thei-th block of the MFA module,and the visualization result is shown in Fig.13.Columns 2 to 4 show different attention score matrices from deep to shallow,achieving attention from point to local,and gradually to the entire domain.This can effectively enhance the consistency of context features and improve the network’s capability to process features of different scales.Furthermore,part of the ATN feature map of the MFA module is visualized.Specifically,ATNrepresents the ATN feature map of thek-th block of the MFA module with a size of 64 × 64.As depicted in columns 2 to 5 of Fig.14,the MFA module obtains feature maps with multi-level semantic information by applying the attention transfer strategy.This strategy reduces information loss or confusion resulting from feature scale changes.Feature maps are progressively reconstructed and optimized from the first to the fourth block.
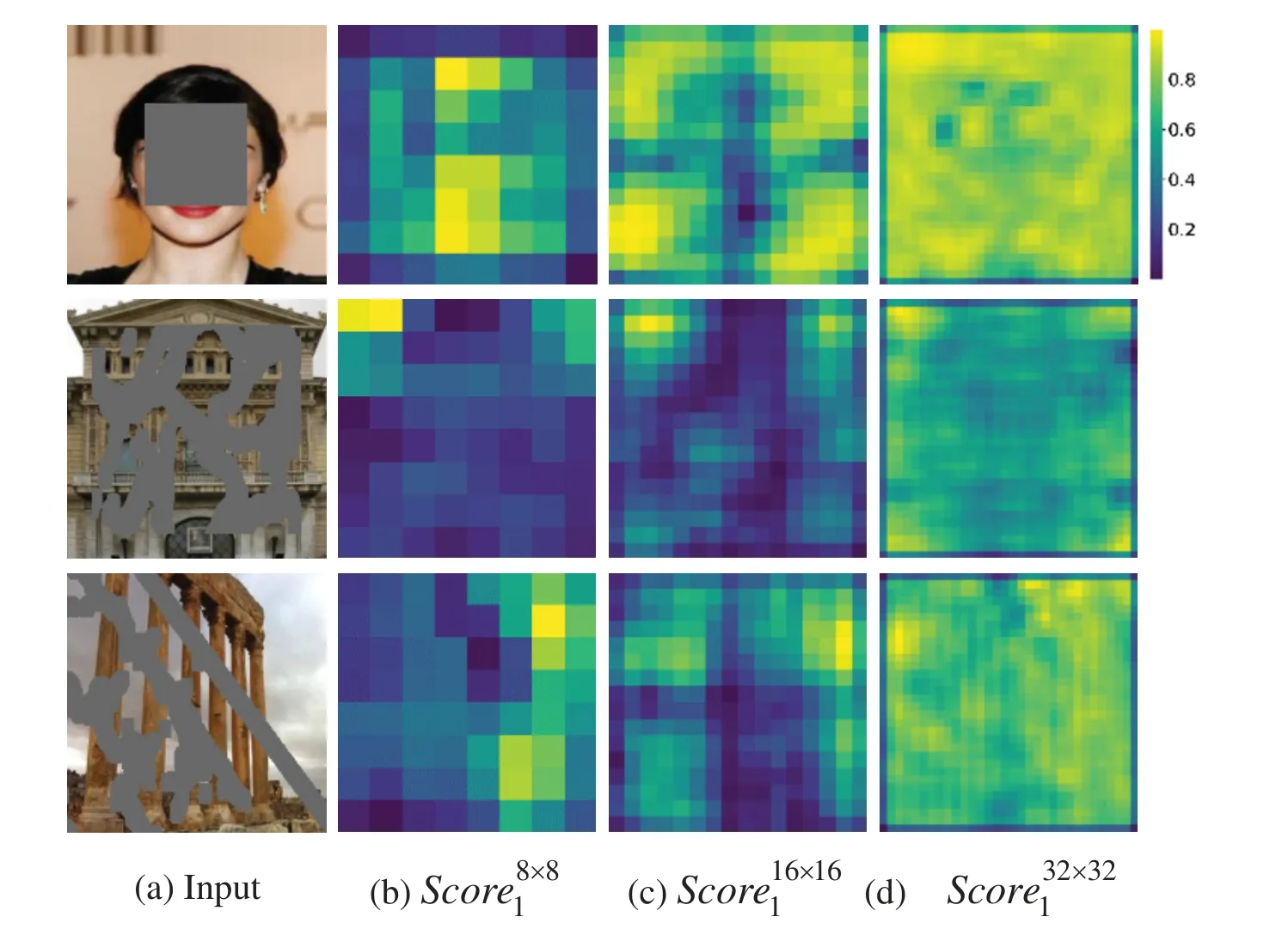
Figure 13:Attention score matrix of ATN at different scales
4.3 Ablation Study
Ablation experiments were conducted on the Facade dataset to analyze the qualitative and quantitative differences between different components of our proposed model.As indicated in Fig.15 and Table 4,various network combinations were tested.These experiments included: (b) removing the entire TEP module and the MFA module and replacing them with residual blocks from EC(-TER-MFA),(c)removing the entire TEP module and replacing it with 8 residual blocks(-TER);(d) removing only the Axial-attention in the TEP module (-AA);(e) removing the MFA module and replacing it with 4 residual blocks (-MFA),(f) applying the complete TEP module and MFA module(+TER+MFA),namely our network structure.As shown in column(c)of Fig.15,the network composed of residual blocks lacks understanding and analysis of the global structure.Consequently,this component cannot accurately predict the edge information of the window in the central region of the large mask.It can be observed from column(d)of Fig.15 that in the case of large irregular masks,only the edge prediction network of self-attention cannot explicitly encode the position information.This restricts the model’s ability to model the local structure of the image,resulting in poor repair results.To address these issues,the image inpainting network herein introduces the MFA module.This module helps to enhance the relevance of multi-level features,balance the attention on visual content and generated content,and realistically restore the texture details and color information of the damaged area.As shown in columns (e) and (f) of Fig.15,when the edge priors are consistent,the composite image obtained in the absence of the MFA module exhibits inconsistent wall color information inside and outside the hole.Nonetheless,our method achieves a more natural visual effect inside and outside the hole,with the smallest area of blurred texture.

Figure 14:ATN feature maps

Figure 15:Analysis of different configurations of the proposed method
Table 4 presents the quantitative comparison of the models composed of different components in terms of metrics such as PSNR,SSIM,LPIPS,and MAE.As shown in rows 3,4,and 6,the fusion of axial attention and self-attention significantly enhances the model’s performance.Fig.16 shows the accuracy and precision curves with/without axial attention.The red curve,which represents the use of axial attention,demonstrates better performance.In the inpainting network,the MFA module is employed to learn from various levels of distant features,so as to extract the contextual information from the input feature map.The quantitative results in row 6 of Table 4 exhibit significant improvement compared to the residual block (row 5 of Table 4).This suggests that the MFA module assists the image inpainting generator in learning more effective information about the image features,thereby enhancing the model’s performance in texture synthesis.
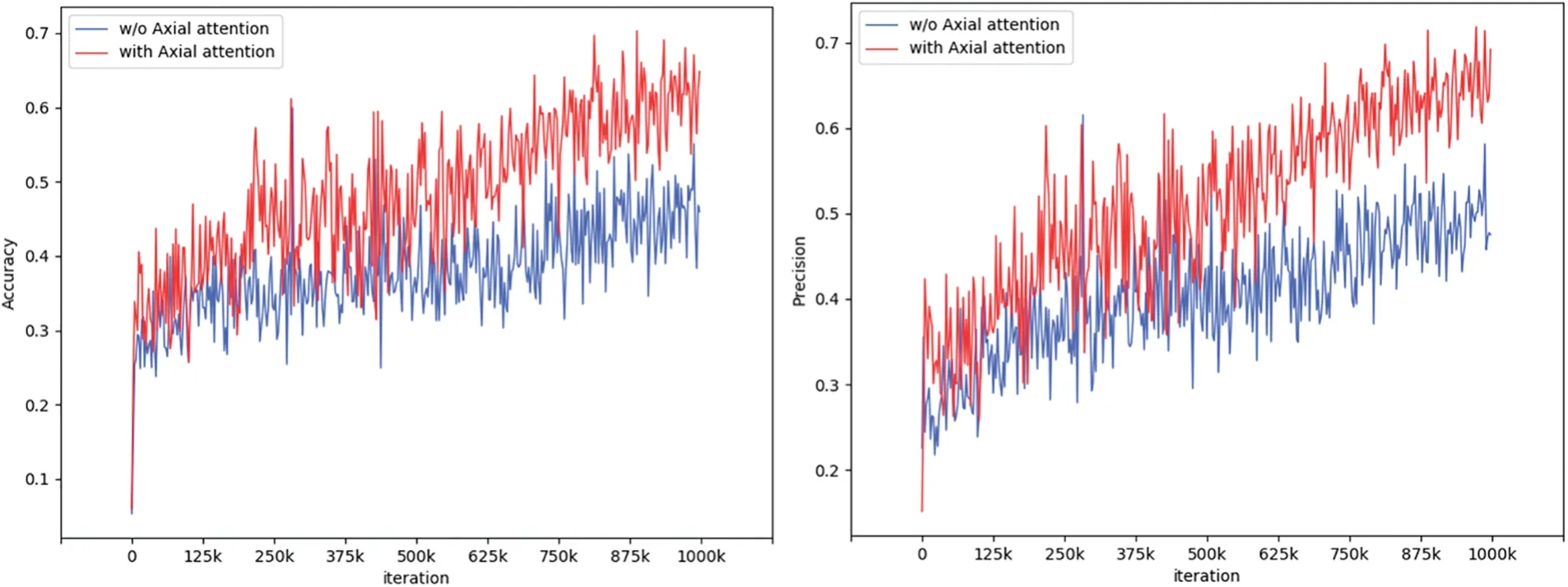
Figure 16:Accuracy and precision curves with/without Axial attention
4.4 Model Complexity Analysis
To analyze the computational complexity of the model,a comparison is made between the EPAM model and other methods in terms of the number of total parameters,memory consumption,and testing time.The term“total parameters”refers to the combined number of trainable and untrainable parameters.“Total memory” means the memory space required during model testing.“Runtime”represents the time taken to repair a single image.Table 5 clearly demonstrates that our model has the fewest parameters and the lowest memory cost compared to other transformer-based methods(ICT,MAT,and PUT).Additionally,our method is also the fastest in inpainting a single image.
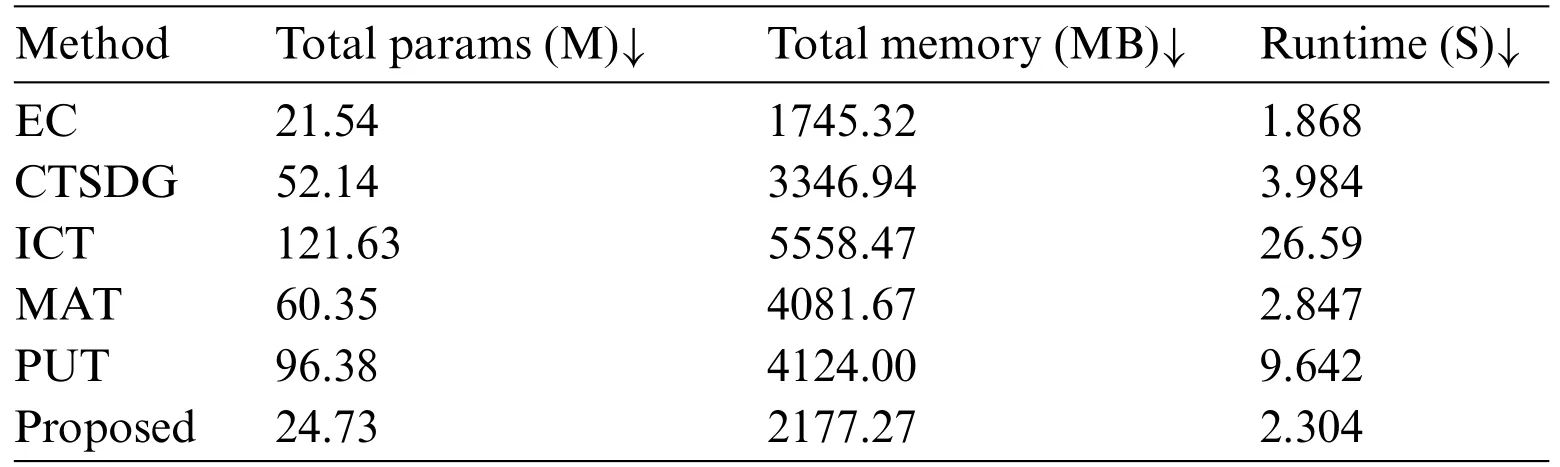
Table 5: Complexity analysis of different models,lower values are better
5 Conclusion
This paper proposes the EPAM image inpainting model which consists of two phases: edge prediction and image restoration.The edge prediction phase incorporates an efficient transformerbased edge prediction(TEP)module,which can better obtain the edge structure of the defect area and reduce the computational cost.The second phase introduces a multi-scale fusion attention (MFA)module,which can extract effective features at multiple scales and enhance the continuity of local pixels through layer-by-layer filling from deep semantics to shallow details.According to qualitative and quantitative comparisons on the CelebA,Facade,and Places2 datasets with irregular masks,our method demonstrates superior performance in repairing complex and large holes.Next,our method utilizes attention and feature visualization to observe the distribution of attention weights and judge the rationality of the feature map.In addition,this paper conducted multiple ablation analyses to verify the effectiveness of each component in the EPAM model from visual effects and quantitative indicators.Finally,through complexity analysis experiments,it is intuitively shown that our proposed method has lower complexity.
The proposed EPAM can only handle images with 256×256 resolution.Due to the constraint of structural information,our model is not suitable for pluralistic image inpainting.In addition,when dealing with complex structures and scenes,the repair results may not meet expectations.For example,when dealing with small accessories such as earrings and necklaces around people’s faces or trees around buildings,this method still has the problem of obvious repair traces.In recent years,multimodal (e.g.,text,depth map,and pose) guided image inpainting has been a challenging research direction.Future research could explore how to perform joint restoration in multi-modal data to produce novel and diverse inpainting results.
Acknowledgement:The authors gratefully acknowledge the equipment support from the Key Laboratory of Optical Information Processing and Visualization Technology at Xizang Minzu University.
Funding Statement:This work was supported in part by the National Natural Science Foundation of China under Grant 62062061,author Y.F,https://www.nsfc.gov.cn/;in part by the Major Project Cultivation Fund of Xizang Minzu University under Grant 324112300447,author Y.F,https://www.xzmu.edu.cn/.
Author Contributions:Study conception and design:J.X.Bai,Y.Fan;data collection and visualization:Z.W.Zhao,L.Z.Zheng;analysis and interpretation of results:J.X.Bai;draft manuscript preparation:J.X.Bai;supervision:Y.Fan.All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials:All data generated or analysed during this study are included in this published article.
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
杂志排行

Computers Materials&Continua的其它文章
- Fuzzing:Progress,Challenges,and Perspectives
- A Review of Lightweight Security and Privacy for Resource-Constrained IoT Devices
- Software Defect Prediction Method Based on Stable Learning
- Multi-Stream Temporally Enhanced Network for Video Salient Object Detection
- Facial Image-Based Autism Detection:A Comparative Study of Deep Neural Network Classifiers
- Deep Learning Approach for Hand Gesture Recognition:Applications in Deaf Communication and Healthcare