结合空间—光谱信息的快速自训练高光谱遥感影像分类
2024-03-09金垚董燕妮杜博
金垚,董燕妮,杜博
1.中国地质大学(武汉) 地球物理与空间信息学院,武汉 430074;2.湖北珞珈实验室,武汉 430079;3.武汉大学 测绘遥感信息工程国家重点实验室,武汉 430079;4.武汉大学 资源与环境科学学院,武汉 430079;5.武汉大学 计算机学院,武汉 430072
1 引言
高光谱遥感光谱分辨率高,波段数目众多,具有图谱合一的特性。这些特点使得髙光谱遥感影像拥有更为丰富的光谱波段信息,能够实现地物精准分类,被广泛应用于精准农业、生态监测、土地利用分类等领域(Dong 等,2022;Plaza 等,2009;Jin等,2022)。
传统的分类算法大多数为监督分类算法,即通过标记样本提供的先验信息完成对分类器的训练,然后使用经过训练的分类器对未标记样本进行分类(Blaschke,2010)。在监督分类算法中,根据有无空间信息的参与,可以进一步分为基于光谱信息的分类算法和基于空—谱信息的分类算法。基于光谱信息的分类算法仅仅依靠光谱信息对高光谱图像进行分类,其中最为经典的算法就是支持向量机SVM(Support Vector Machines)(Zhang 等,2004)和多层感知机MLP(Multilayer Perceptron)(Zerguine 等,2001)。SVM 以结构风险最小化为准则,寻找最佳的分类面实现分类;MLP 则以神经网络的结构来对输入数据进行高效分类。而基于空—谱信息的分类算法在利用光谱信息的同时,还利用了高光谱图像中蕴含的空间信息。其中基于组合核CK(Composite Kernel)(Camps-Valls 等,2006)的方法是最基础的空—谱分类方法,CK 采用空间窗口提取窗口中心样本点的邻域信息,得到空间信息核,然后与光谱信息核相结合,得到CK 替换SVM 中的核函数,有效提高了高光谱图像的分类精度。
然而,在监督分类算法中训练1个较优的分类器需要大量标记数据的支撑,尤其是高光谱遥感数据,大量的光谱波段意味着需要更多的先验信息(Li等,2018;Ghamisi等,2017)。但是由于各种限制因素,收集标记样本的成本是十分昂贵的,在实际应用中往往无法获得足够的标记样本来支撑分类器的训练(Bioucas-Dias等,2013)。
近些年,已有研究通过半监督分类算法来解决标记样本不足的问题(van Engelen 和Hoos,2020)。半监督分类算法是在只有少量标记数据的条件下,结合未标记数据中蕴含的信息辅助分类器的训练,能够有效增加分类器的泛化性和准确率(Camps-Valls 等,2007)。一般而言,半监督分类算法可以分为:协同训练方法(Li 等,2020)、基于图的方法(Chen 等,2017)以及自训练方法(Ge等,2021)。
协同训练方法在不同视图上训练得到多个分类器,通过多个分类器之间的协同作用实现对无标记样本的分类。Tri-Training(Zhou 和Li,2005)将标记数据分为3个视图,根据标记数据训练出对应的3个分类器,然后采用集成学习对未标记样本进行标注;TT-AL-MSH(Tri-Training with Active Learning and Multi-Scale Homogeneity)(Tan 等,2016)基于多样性的考量,通过在4个分类器中选择3 个具有相当大差异的分类器,改进了传统的Tri-Training,有效的提高了分类器的分类能力;Multi-Train(Gu 和Jin,2017)将Tri-Training 进一步扩展到更多的视图以提高性能。但是协同训练要求多视图之间存在独立性,在实际应用时往往难以满足(Wang等,2014)。
基于视图的方法认为在特征域中属于同一邻域的样本有更大的概率属于同一类别。LP(Label Propagation)(Wang 和Zhang,2008)根据所有样本之间的相似性构建1个权重图,然后各个样本在其相邻的样本间进行标签传播;NLP(Negative Label Propagation)(Zoidi等,2018)通过负标签信息有效的指导半监督学习的过程;SaGSSL(Safety-Aware Graph-Based Semi-Supervised Learning)(Gan等,2018)通过样本余量来判断所构建的图是否合适,能够自适应地选择合适的图,并学习1个安全的半监督分类器;但是基于图的方法对图构建有很高的计算要求,需要较高的时间成本(Ge等,2021)。
自训练方法作为半监督学习中的经典方法,具有简单以及不需要先验假设的优点(van Engelen和Hoos,2020)。自训练方法首先利用标记数据训练1个初始的分类器对未标记数据进行分类,然后选择置信度比较高的样本进行标记,最后使用扩充后的标记数据集完成对分类器的训练。在整个自训练过程中,最为关键的部分就是如何获得置信度高的分类结果,因为初始的分类器是在少量标记数据上进行的训练,训练样本的数量不足,会导致分类器训练不充分,容易对未标记数据产生误判。而误标记样本产生的错误在迭代过程不断累加,进而导致最终的分类器分类效果较差(Gu,2020)。
因此为了提高自训练方法的性能,已有研究提出不同自训练方法的改进版本。TSVM(Transductive Support Vector Machines)(Bruzzone 等,2006)采用动态阈值为基于自训练方法的SVM 分类器选择有信息的样本;SBSL(Segmentation-Based Self-Learning)(Lu 等,2016)使用高分辨影像的分割技术来选择信息量大且多样化的样本,以便在自训练中有效地训练监督分类器;SP-SVM(Self-Training Approach with Pseudo)(Aydav 和Minz,2018)使用伪标签验证集提升模型分类精度,减少误差;ST-HP(Self-Training Hierarchical Prototype-Based)(Gu,2020)利用数据集中存在的层次结构,以自训练的方式训练了1个基于层次结构的分类器,以改善遥感图像的半监督分类。但是以上的自训练方法通常存在着2个问题:(1)忽略了高光谱影像提供的空间信息,导致最终分类精度受到影响;(2)每轮迭代都需要使用分类器对未标记样本进行分类,需要大量的时间成本。
针对上述问题,本文提出1种基于空间—光谱信息的快速自训练方法FST-SS(Fast Self-Training with Spatial-Spectral Information)。FST-SS 在每次迭代中首先利用空间信息为标记样本提取空间近邻点,然后根据标记样本的光谱邻域信息计算自适应阈值对空间近邻点进行筛选得到标记样本的空谱近邻点,最后将空谱近邻点视为标记样本同类点赋予同样的标签并加入到标记样本集中进行下1 次迭代,在训练过程中避免了每次迭代所需的分类过程,大大降低了时间成本。本文采用Washington DC Mall Subimage 和Indian Pines 2 个 常用的高光谱数据集,对比1种常用的监督分类算法以及4种半监督分类算法来验证方法的有效性。
2 空谱信息快速自训练方法
对于高光谱影像,本文使用X=[x1,x2,…,xn]∈Rd×n代表标记样本集,其中d表示影像波段数,n表示标记样本的个数。Y=[y1,y2,…,yn]∈Rn×1表示对应的标签信息。根据已知的标签信息,可以将标记样本集分为两部分。如果yi=yj,标记样本xi和xj属于相似样本对集合S,反之则属于不相似样本对D。
针对传统自训练方法中缺乏对空间信息的考量以及计算效率较低的问题,FST-SS 引入空间信息,通过使用空间—光谱信息直接对未标记数据进行筛选,避免每轮迭代中的分类过程,能够在保证最终精度的同时,极大的提高了计算效率,FST-SS具体流程如图1所示。
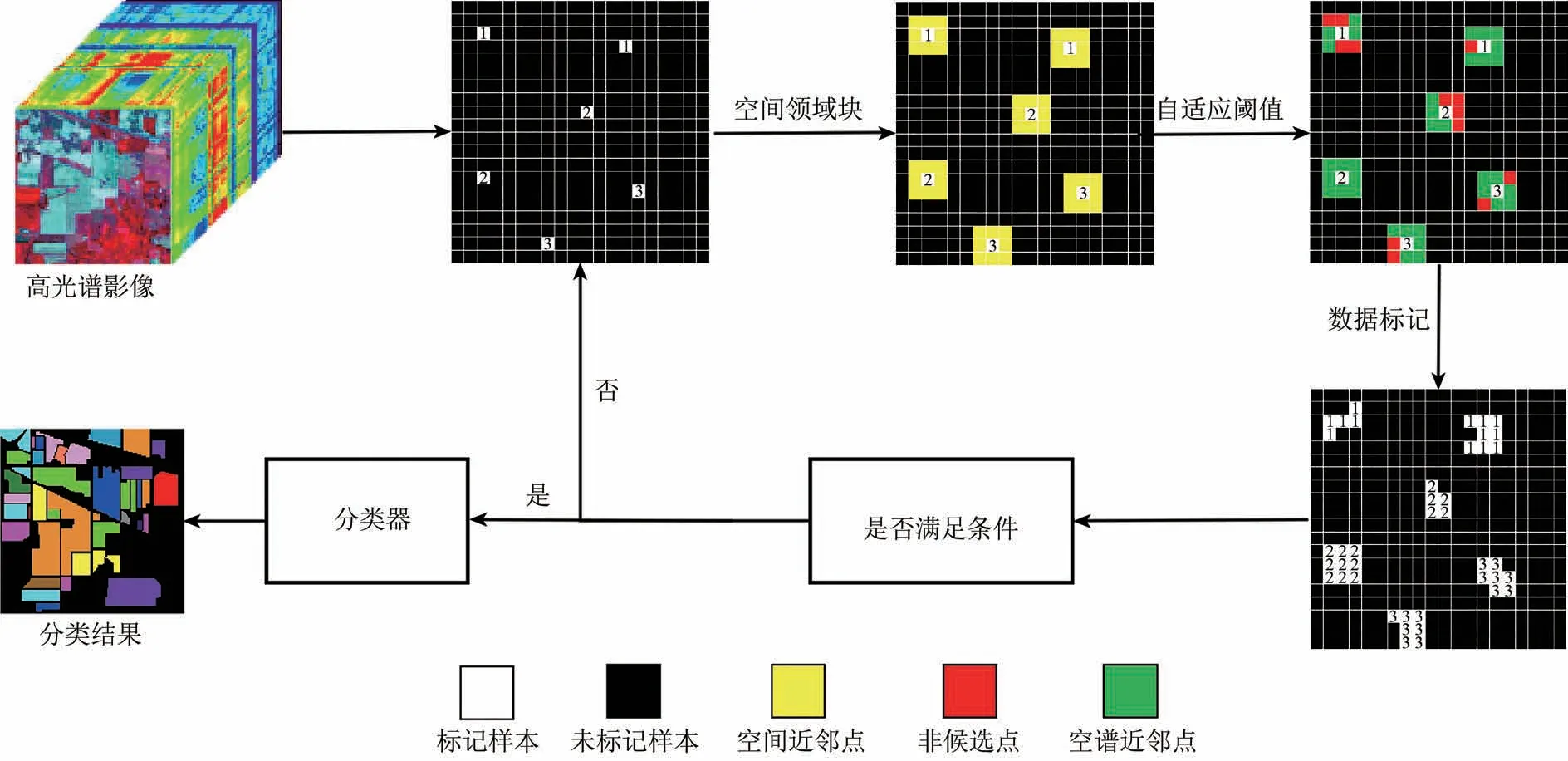
图1 FST-SS流程图Fig.1 FST-SS flow chart
2.1 空间近邻点选择
根据地学第一定律可知,地物之间存在着空间相关性,所以高光谱影像中像素和地物的空间分布在一定范围内是一致的。因此空间上相邻的像素有极大概率是同1 种地物。本文遵循这种假设,使用3*3的空间邻域块为标记样本选择空间近邻点。标记样本处于块的中心,其余的点则为标记样本点的空间近邻点。通过这样一种方式每个标记样本可以最多选择8个空间近邻点,而当标记样本位于影像边缘时,空间近邻点则少于8个。
2.2 利用自适应阈值筛选空谱近邻点
尽管标记样本与周围的空间近邻点有着极高的相似度,但是无法保证每1个空间邻近点都与中心的标记样本点类别相同。因此本文引入阈值b对空间近邻点进一步筛选,筛选出空谱近邻点。如果d(xi,xj)>b,则认为xi,xj属于不同类点,如果d(xi,xj)<b,则认为xi,xj属于同一类点。d(xi,xj)为xi,xj之间的光谱距离,计算公式如下:
考虑到每1个标记样本的光谱邻域信息并不相同,当面对复杂的数据时,采用固定的阈值缺乏对邻域信息的考虑,往往难以取得较好的结果。所以为了充分考虑到每1个标记样本的光谱邻域信息,做到具体问题具体分析,本文采用1种自适应阈值,根据每1个标记样本的光谱邻域信息计算相对应的阈值,用于筛选空谱近邻点。具体设置如下:对于每一个标记样本xi,首先根据式(3)计算xi与其同类标记样本之间的光谱欧式距离,得到同类标记样本之间的距离矩阵,将距离xi最近点的距离作为阈值,即
随着迭代次数的不断增加,每次阈值bi的值也会快速减少,被判定为空谱近邻点的要求也会严苛,这样保证了新增标记样本的准确度。但是随着阈值bi不断下降,也有一部分潜在的同类样本没有被纳入到新增标记数据集中去。因此本文还在bi的基础上,考虑到每次迭代bi的缩减,设计了另外1 种阈值bit=,xi,xik∈S,代表xi与其第t近的同类标记样本之间距离,t的值为迭代的次数。这样可以减缓bit的衰减速度,可以把更多的未标记样本纳入标注数据集中。
2.3 迭代训练
通过上述两步可以完成1 次迭代的训练过程,将训练得到的新增标记样本集与初始标记样本集合并后,一起投入下1次的迭代训练中,直至标记数据集数目不在增加或者达到设定的最大迭代次数。由于本文中产生标记数据的方法不是采用传统的分类方法,并不是所有的数据都会被划分进标记数据集,所以当最后的迭代完成后,仍需要使用分类器对结果进行分类。本文采用1NN(1-Nearest Neighbor)分类器,当迭代训练完成后,使用扩充后的标记数据集对分类器进行训练,然后对测试数据完成分类。
3 数据结果处理与分析
3.1 实验数据
3.1.1 Washington DC Mall Subimage 数据集:该数据集由为HYDICE传感器于华盛顿广场获得的子影像区域。影像包括210 个光谱带。波长范围从0.4—2.4 μm,影像大小为280×307 像素。在删除了低信噪比和水吸收带后,总共剩下191个波段用于本次实验。图2(a)和(b)分别显示了对应的假彩色图像和真实地物图。Washington DC Mall Subimage 数据集在8 类地物中共有14266 个样本点,表1中列出了每一类的样本数量。

表1 Washington DC Mall Subimage数据真实地物样本信息Table 1 Ground truth of main classes on Washington DC Mall Subimage

图2 Washington DC Mall Subimage 数据集Fig.2 Washington DC Mall Subimage dataset
3.1.2 Indian Pines 数据集:由NASA 的机载可见光/红外成像光谱仪(AVIRIS)于1996 年在印第安纳州西北部农业区获得。这个场景包括220个光谱带,波长范围从0.4—2.5 μm,影像大小为145×145 像素。在删除了低信噪比和水吸收带后,总共剩下200 个通道用于本次实验。图3(a)和(b)分别显示了对应的假彩色图像和真实地面图。该数据集在16类特征中共有10249个样本点,表2中列出了每1类的样本数量。
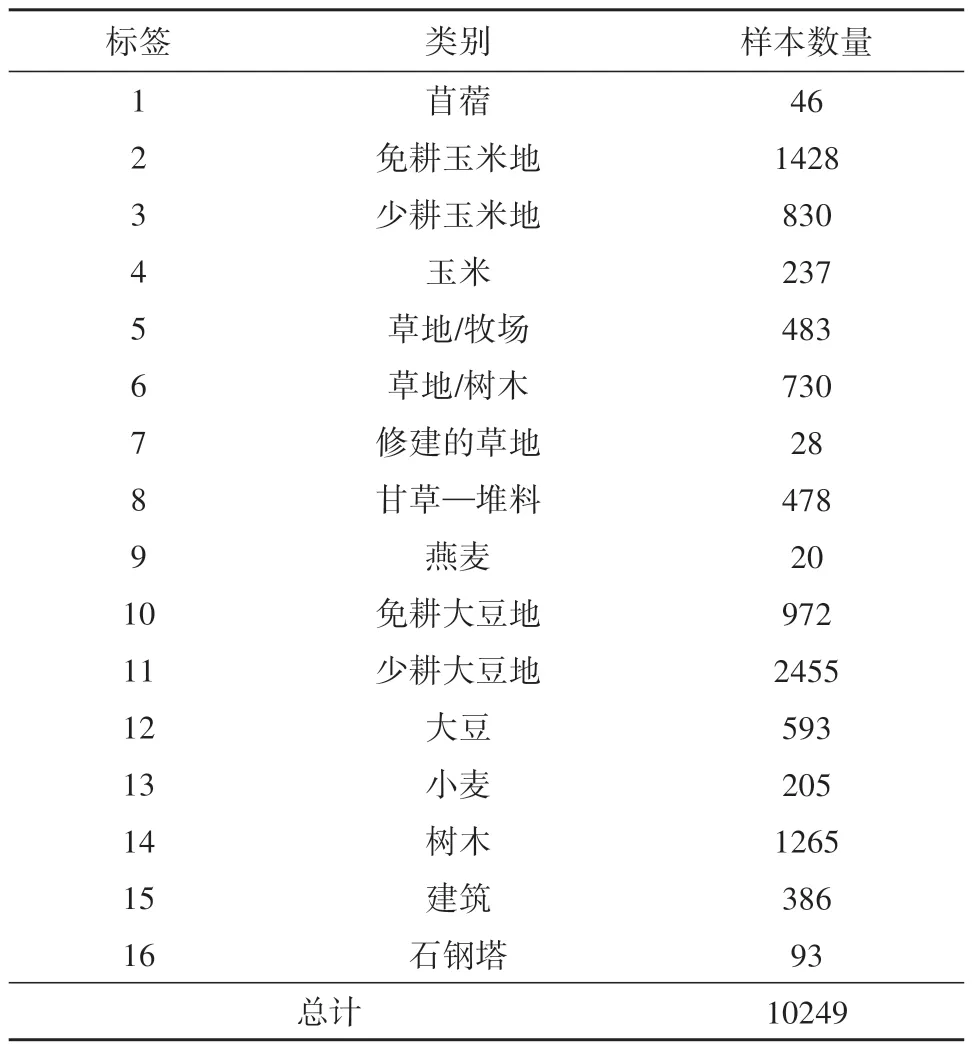
表2 Indian Pines数据真实地物样本信息Table 2 Ground truth of main classes on Indian Pines

图3 Indian Pines数据集Fig.3 Indian Pines dataset
3.2 实验设置
为了证明FST-SS的有效性,本文将FST-SS与监督分类算法1NN、半监督分类算法Tri-Training、Star-SVM(Self-Training with Adaptive Regularization Support Vector Machine)(Cheung 和Li,2017)、ST-DP(Self-training based on density peaks of data)(Wu等,2018)以 及LeMA(Learnable Manifold Alignment)(Hong 等,2019)进行对比实验,其中FST-SSfixed 表示使用阈值bi、FST-SS-unfixed 表示使用阈值bit,所有算法均使用相同的训练样本进行实验,以保证对比的公平性。对于每1种数据集,本文在每类地物中随机选择2、10样本作为训练样本,余下数据作为测试样本。
图4是对最大迭代次数的参数分析结果图。可见:FST-SS 在迭代次数为50 时结果已经趋于稳定;迭代次数未达到50 次时就停止了训练。因此本文设置最大迭代次数为50。此外为了减少随机取样带来的误差,每组实验独立进行5次,最终结果为5次实验的平均值。实验中采用整体分类精度OA 以及kappa 作为定量评价指标,结果中加粗结果为最好结果。
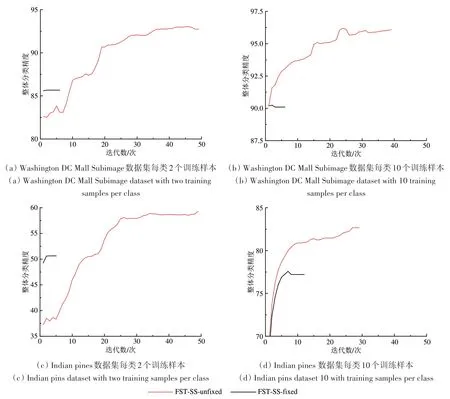
图4 不同数据集下最大迭代次数参数分析图Fig.4 Parameter analysis diagram of the maximum number of iterations under different datasets
3.3 实验结果
3.3.1 Washington DC Mall Subimage 数据集
表3 和表4 分别表示是每类随机选择2 和10 个训练样本的定量评价结果,从结果中可以发现,本文提出的FST-SS-unfixed、FST-SS-fixed 拥有最优和次优的精度和kappa 值,而且在大多数地物分类中都能取得优异的分类精度。在每类随机选择2 个训练样本的实验组中,4 种对比的半监督分类算法的精度相较于1NN 分类器都有不错的提升。所提出的算法分别取得最优和次优的精度,其中FST-SS-fixed 精度的提升较小,而FST-SSunfixed 提升最多可达16%,这也证明了FST-SS 算法在小样本条件下的适用性。而随着训练样本的增多,在每类选择10 个训练样本的实验组中,提出的算法同样保持着最优和次优的精度,在训练样本增多的情况下FST-SS-fixed 的精度大幅度增加,远远超出其他的对比算法,而 FST-SSunfixed 则依旧保持最高的精度。图5 和图6 分别为Washington DC Mall Subimage 数据集上不同初始训练样本的分类结果。可见:在每类选择2 个训练样本时,本文提出的算法在第6 类房屋3(黄色地块)中有着最优的分类结果,其分类准确度远超其他对比算法,而FST-SS-unfixed 相较于FSTSS-fixed 而言,在第5 类阴影(紫色地块)中拥有更平滑的分类结果;在每类选择10 个训练样本时,本文提出的算法在第3 类房屋1(浅蓝色地块)拥有更好的分类结果。图7 为不同标记样本下的整体分类精度OA 值。可见分类精度会随着初始标记样本数的增加而增加,当每类标记样本数到达20 时OA 值趋于稳定。
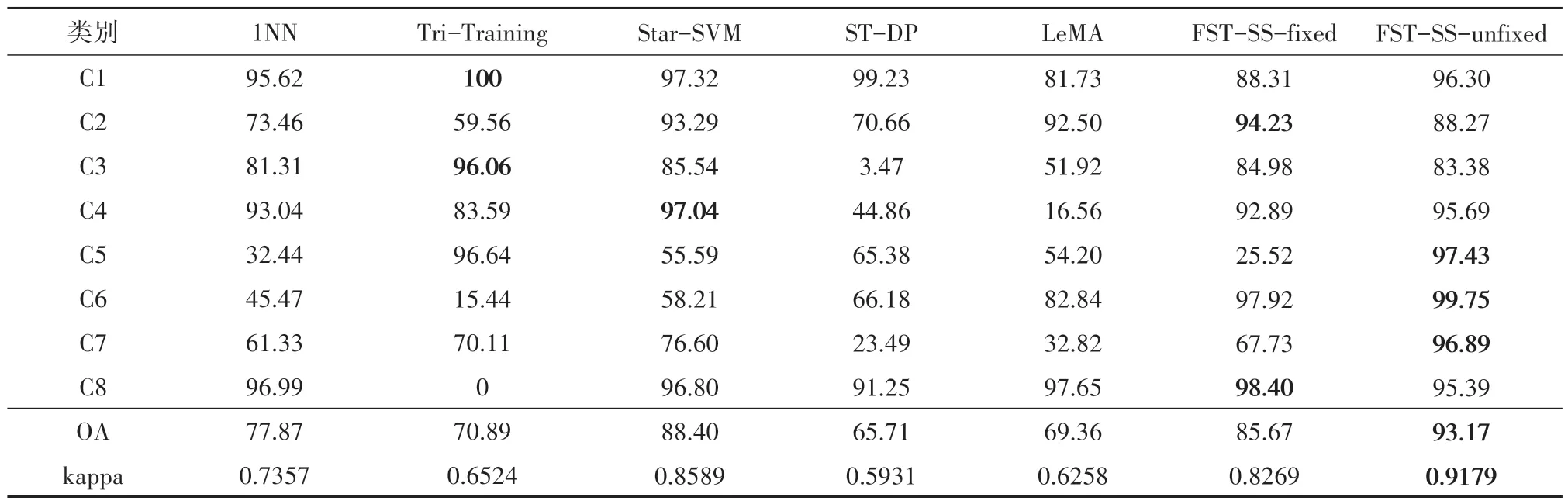
表3 Washington DC Mall Subimage 数据集分类精度Table 3 Classification accuracy of Washington DC Mall Subimage dataset

表4 Washington DC Mall Subimage 数据集分类精度Table 4 Classification accuracy of Washington DC Mall Subimage dataset

图5 Washington DC Mall Subimage 数据集每类2个训练样本分类结果图Fig.5 Classification results with the Washington DC Mall Subimage dataset with two training samples per class

图6 Washington DC Mall Subimage 数据集每类10个训练样本分类结果图Fig.6 Classification results with the Washington DC Mall Subimage dataset with 10 training samples per class

图7 Washington DC Mall Subimage 数据集中不同标记样本下的整体分类精度OA图Fig.7 Classification OA for different labeled samples in the Washington DC Mall Subimage dataset
3.3.2 Indian Pines数据集
表5 和表6 分别为每类随机选择2、10 个训练样本在Indian Pines 数据集上的定量评价结果。可见:在每类随机选择2个训练样本的实验组中,提出的算法分别取得最优和次优的精度,其中FSTSS-fixed 精度的提升达到18%,而FST-SS-unfixed提升最多可达27%;在每类选择10 个训练样本的实验组中,提出的算法同样保持着最优和次优的精度。图8和图9分别为Indian Pines 数据集上不同训练样本的分类结果图。可见由于始训练样本数目少,所以整体精度较低,分类结果图中噪声较多;本文提出的FST-SS 拥有更为平滑的分类结果,例如在第8 类甘草—堆料(红色地块)和第15 类建筑(浅蓝色地块)中可以明显的看出不同地块的边界,整体的噪声比较少。图10 展示了不同标记样本下的整体分类精度OA 图,由于Indian Pines 数据集样本分布不均匀,部分类别总体样本较少,所以第1、7、9 类选择初始标记样本时,选择50% 作为初始标记样本。得到的结果与Washington DC Mall Subimage 据集一致,分类精度会随着初始标记样本数的增加而增加,当每类标记样本数到达40时趋于稳定。

表5 Indian Pines数据集分类精度Table 5 Classification accuracy of Indian Pines dataset /%

表6 Indian Pines数据集分类精度Table 6 Classification accuracy of Indian Pines dataset /%

图8 Indian Pine数据集每类2个训练样本分类结果图Fig.8 Classification results with the Indian Pine dataset with two training samples per class

图9 Indian Pine数据集每类10个训练样本分类结果图Fig.9 Classification results with the Indian Pine dataset with ten training samples per class

图10 Indian Pines数据集中不同标记样本下的整体分类精度Fig.10 Classification OA for different labeled samples in the Indian Pines dataset
3.3.3 计算效率分析
表7 展示了不同算法的计算效率对比。从表7中可以发现FST-SS-fixed 运行效率要略高于FSTSS-unfixed,这是因为FST-SS-fixed 在训练过程中阈值的衰减速度要快于FST-SS-unfixed,所以FST-SS-fixed 在训练过程中考虑标注的样本少于FST-SS-unfixed,因此FST-SS-fixed 所需的计算时间更少,但是FST-SS-unfixed 最终的计算精度要优于FST-SS-fixed。整体而言FST-SS-fixed 和FST-SS-unfixed 所需的计算时间都远远小于4 种对比的半监督分类算法。这样验证了所提出算法的有效性。

表7 运行时间分析Table 7 Run time analysis
4 结论
本文提出FST-SS 算法来克服传统自训练方法中标注精度低、训练效率低的问题。针对标注精度低的问题,FST-SS 通过利用高光谱图像中地物空间分布的一致性,将高光谱图像中的空间信息作为补充,弥补了标记样本数目过少所导致的先验信息的不足,从而提高了对未标记样本的标注精度。而针对自训练方法训练效率低的问题,FST-SS 没有沿用传统自训练学习使用分类器对未标记数据进行标记,而是利用空间—光谱信息对未标记样本进行多次筛选,然后对筛选出的样本直接赋予标记,避免了多次分类产生的高额时间成本,大大的提高了算法的计算效率。同时考虑到阈值在迭代过程中衰减速度过快,本文还设计了一种新的阈值计算方法减缓阈值的衰减。在两组真实的数据集上的实验结果证明,FST-SS 相对于传统自训练方法在小样本条件下能取得更为优秀的分类结果,同时计算效率也远远优于传统自训练方法,证明了所提出算法的有效性。
此外,本文提出的FST-SS 方法还有进一步研究的空间。本文中自适应阈值的计算直接在原始欧式空间中进行,而欧氏空间不具备良好的判别能力,导致样本标注不够准确,后续工作尝试将测度学习引入迭代训练过程中,将数据从原始欧式空间映射到具有高判别力的测度空间后,再进行样本标注,通过测度学习提高标记数据的准确率。
