结合协方差池化与跨尺度特征提取的高光谱分类
2024-03-09汪乐彭江涛陈娜孙伟伟
汪乐,彭江涛,3,陈娜,孙伟伟
1.湖北大学 数学与统计学学院 应用数学湖北省重点实验室,武汉 430062;2.宁波大学 地理与空间信息技术系,宁波 315211;3.宁波大学 遥感遥测产业技术研究院 宁波拾烨智能科技有限公司,宁波 315211
1 引言
高光谱图像HSI(Hyperspectral image)包含丰富的空间信息和光谱信息。相比于传统的RGB 图像和多光谱图像,高光谱图像的光谱分辨率更高、光谱波段更多,因此能更好表征地物的结构和成分,适用于鉴别地物之间的细微差异。分类是许多高光谱遥感处理与应用的基础任务(杜培军 等,2016;童庆禧 等,2016;彭江涛 等,2020)。分类目的就是将HSI中每个像素分类到已知的地物类别中。目前高光谱图像分类已广泛应用于植被研究(Demarez,1999)、农业和资源管理(Murphy 等,2019)和军事(Shimoni等,2019)等多个领域。
早期基于像素的高光谱分类方法更关注光谱信息,如支持向量机SVM(Support Vector Machine)(Melgani 和Bruzzone,2004)、随机森林(Ham 等,2005)、K 均值聚类(Ma 等,2010)等分类。这些方法仅利用光谱特征而未考虑空间信息,其特征表征能力有限。特征提取的好坏直接影响分类效果(孙伟伟 等,2018),联合利用空间和光谱信息进行特征提取与分类是提升高光谱分类性能的有效途径。Benediktsson等提出一种结合光谱和空间信息的形态学轮廓EMP(Extended Morphological Profiles)特征提取与分类方法(Benediktsson 等,2005);Mura等(2010)提出了扩展多属性剖面方法EMAP(Extended Multi-Attribute Profile)。Li 等(2015)采用局部二值模式LBP(Local Binary Patterns)提取高光谱影像的局部特征。Jia 等(2015)提出一种基于三维Gabor特征的协同表示高光谱影像分类方法。Camps-Valls 等(2006)提出一种结合空间和光谱信息的支持向量机复合核框架SVM-CK(SVM with Composite Kernel)。Peng等(2017)提出了一种理想正则化复合核分类框架,该方法在学习复合核时同时利用了光谱信息、空间信息和标签信息。Chen等提出了联合稀疏表示JSR(Joint Sparse Representation)高光谱分类方法(Chen 等,2011;Peng 等,2019)。这些空谱联合特征提取与分类方法能够有效地提取高光谱图像的空间—光谱特征,但是这些人为设定的特征如EMP 特征、LBP 特征、Gabor 特征并不具备数据自适应变化的特性。
近年来,深度学习的发展极大促进了HSI 分类的研究。深度学习网络能够根据数据的特点自动学习相应的判别特征,已被广泛应用于HSI 分类领域。典型的深度学习框架包括堆叠式自动编码器SAE(Stacked AutoEncoder)、深度信念网络DBN(Deep Belief Networks)、卷积神经网络CNN(Convolutional Neural Networks)等。Chen等(2014)首先将深度学习的概念引入高光谱图像分类中,应用SAE 构建基于深度架构的模型,以无监督的方式学习深度特征。随后,Tao 等(2015)提出了一种基于稀疏约束的改进自编码器。Li 等(2014)基于DBN方法提取深度光谱特征图。然而,这2类深度学习的方法依然存在空间信息缺失的问题。为了充分利用高光谱图像的空间和光谱信息,Zhao和Du(2016)将CNN 用于高光谱图像分类,通过二维卷积神经网络(2D-CNN)提取空间特征,利用平衡局部判别嵌入算法提取光谱特征。CNN 具有局部连接和权重共享的优点,在提取空间信息的同时能够有效减小参数量。考虑到HSI本质是一个三维张量,(Chen 等(2016)及Zhang 等(2017)直接利用三维卷积神经网络(3D-CNN),从原始三维数据中同时提取光谱和空间特征,取得了较好的分类性能。Zhang等(2019)提出了三维DenseNet来处理HSI 分类,采用串联的方式进行密集连接,通过各层之间的直接连接,确保各层之间信息的有效传输。鉴于仅使用二维卷积或三维卷积分别存在缺失通道关系信息或模型复杂的缺点,Roy等(2020)提出了混合光谱卷积神经网络HybridSN(Hybrid Spectral-Net),利用三维卷积进行联合空间光谱特征表示,二维卷积在三维卷积的基础上进一步学习更抽象的空间表示。网络层数的增加能够提升CNN 的特征表达能力。但是,网络加深有可能会出现梯度消失或梯度爆炸问题。为此,Zhong 等(2018)提出了空间光谱残差网络SSRN(Spectral-Spatial Residual Network),借助残差连接对网络进行深化。Roy 等提出了一种基于注意力机制的自适应光谱空间核改进残差网络A2S2K-ResNet(Attentionbased Adaptive Spectral-Spatial Kernel ResNet),该网络通过选择性学习三维卷积核,利用改进的三维残差块联合提取光谱空间特征(Roy 等,2021)。以上网络提取单尺度邻域数据作为输入,只利用单尺度下的空间—光谱特征融合,没有考虑多尺度特征融合提供不同视野丰富的互补信息。Lee 和Kwon(2017)设计了上下文交互的深度卷积网络(Contextual deep CNN),将多尺度卷积获得的初始空间特征和光谱特征图组合,最后得到联合空间—光谱特征图。类似地,Gong 等(2019)提出具有多尺度卷积(Multiscale-CNN)的新型卷积神经网络,从高光谱图像中提取深层多尺度特征,并结合多种度量提高分类性能。以上方法仅在网络某一层考虑执行多尺度特征提取,可能不足以全面学习不同尺度下的光谱空间信息。充分利用不同层次之间的互补信息也是一种特征融合的思路。Song等(2018)提出深度特征融合网络DFFN(Deep Feature Fusion Network),引入残差学习简化网络的训练,并融合不同层次的输出,进一步提高了分类精度。Li 等(2019)提出带有辅助分类器的分层多尺度卷积神经网络,多尺度CNN 同时提取不同尺度下的光谱—空间特征,并采用双向长短时记忆网络来捕获多尺度特征之间的相关性。现在多尺度方法仍存在一些问题,如空间信息冗余,计算成本较高,多尺度特征利用不足等。
在上述的深度神经网络框架中,一般采用一阶池化运算来提取特征。近年来,高阶统计量在机器视觉领域显示出巨大的潜力,特别是采用二阶池化得到的二阶统计量,可以有效利用不同通道之间的相关性信息,在图像分类领域取得了优越性能。在经典的浅层结构中,Tuzel 等(2006)提出区域协方差矩阵的特征描述方法;Carreira 等(2015)提出二阶非中心矩池化方法O2P(Secondorder pooling)。在深度结构中,Ionescu 等(2015)提出了DeepO2P 网络,在深度卷积网络的最后一个卷积层后插入二阶池化层,取得了较好分类结果。虽然二阶池化的研究在深度结构中有一定的进展,但仍存在2 个难题:一是稳健协方差估计,二是如何充分利用协方差的黎曼几何结构特性。Li 等(2017a)提出了矩阵幂归一化协方差池化MPN-COV(Matrix power normalized covariance)方法来解决上述2 个问题。为使算法能够在GPU 上进行有效运算,他们进一步构造了迭代矩阵平方根归一化的快速协方差池化iSQRTCOV(Iterative matrix square root normalization of covariance pooling)方法(Li 等,2018)。在HSI 分类应用上,Lin 等(2015)提出双分支卷积神经网络B-CNN(Bilinear CNN),通过聚类局部相邻像素来构造不同光谱波段之间的协方差矩阵。利用协方差池化,从不同的卷积层生成多个叠加特征。该矩阵的每个元素代表2个特征映射之间的协方差,进一步提供更多的互补信息(He 等,2018)。Xue 等(2021)提出了一种基于注意力的二阶池化网络A-SPN(Attention based second order pooling network),计算基于注意力的二阶池化特征,进行HSI 分类。Zheng 等(2021)提出了协方差池化的三维二维混合卷积提取光谱空间特征MCNN-CP(Mixed Convolutions and Covariance Pooling),通过协方差池化从空谱特征图中提取二阶信息。需要注意,上述算法只使用二阶池化,可能会忽略一阶池化所具有的特有信息。此外,采用固定尺度的特征提取器没有考虑到不同感受野获取的互补信息(Lee和Kwon,2017;Xie等,2021)。
因此,为充分利用一阶二阶统计量信息和多尺度互补空谱特征,本文提出了一种结合协方差池化和跨尺度特征提取的高光谱影像分类算法。该方法具有以下几个特点:首先,设计了跨尺度自适应特征提取模块CSAF(Cross Scale Adaptive Feature Extraction),利用多尺度卷积核,进行横向跨尺度特征提取,自适应获取不同尺度在相同深度的互补信息;其次,设计了一阶二阶联合池化与融合模块,其中二阶协方差矩阵可以同时利用空间和光谱信息,矩阵中每个元素代表1个局部空间领域内的2个不同光谱波段的协方差,一定程度反映样本光谱波段之间的相关性。并且,得到的协方差矩阵大小只与光谱波段数量有关,这使得不同尺度构建的协方差矩阵大小相同,在训练过程中不会产生维度障碍。

表1 Indian Pines数据训练集和测试集Table 1 Training and testing sets of Indian Pines data
2 研究方法
本文提出了一种结合协方差池化和跨尺度特征提取CP-CSFE(Covariance Pooling and Cross Scale Feature Extraction)的高光谱分类模型,如图1 所示。该方法由跨尺度自适应特征提取模块和联合池化特征融合模块2个主要部分组成。

图1 结合协方差池化和跨尺度特征提取的高光谱影像分类算法框架Fig.1 The structure of hyperspectral classification algorithm based on covariance pooling and cross scale feature extraction
2.1 跨尺度自适应特征提取
多尺度能够带来不同视野的信息。为了更好地利用不同尺度之间的互补信息,本文设计了CSAF 模块,通过跨尺度提取信息获取丰富的互补空谱特征。采用了3 种不同的尺度,在第1 个三维卷积层中分别设置:8 个大小为(3×3×3)的三维卷积核;8个大小为(5×5×5)的三维卷积核;8个大小为(7×7×7)的三维卷积核。剩下2 个卷积层与第一个类似,但卷积核数量设置不同。三维卷积能够同时学习高光谱图像的空间和光谱特征,在每次卷积操作之后应用批量归一化(BN)和ReLU激活函数,提高训练收敛速率。
以尺度7 为例,CSAF 模块的结构如图2 所示。输入该模块的张量为Xi∈Rh×w×c×m其中,h表示空间的长度,w表示空间的宽度,c表示通道数,m表示特征图个数。首先从上到下分别将输入通过三维卷积映射得到特征图和。然后,应用自适应全局池化操作将映射特征图转换成体现特征图重要性值的一维向量,3 个映射特征图对应得到的结果为和。随后,依次使用大小(1×1×1)的卷积核和用于归一化的Sigmoid 激活函数,进行信息整合。根据具体的任务情况,不同尺度提供信息的重要程度不同。因此,CSAF 模块根据特征映射的重要性分配不同的权重。自适应权重参数α计算公式如下:

图2 CSAF模块结构Fig.2 The structure of CSAF module
式中,Wf和bf分别代表(1×1×1)卷积的权重参数和偏置参数,σ表示Sigmoid激活函数。
类似地,自适应权重参数β和γ由g(Xi)和h(Xi)计算得到,具体公式如下:
最后将尺度3、尺度5 和尺度7 本身的特征,结合自适应参数进行串联连接。提取到跨尺度特征,并作为下一个尺度为7的卷积层的输入,形式为
值得注意的是,除尺度3外,每个尺度都设置2个CSAF 模块。其中尺度5与尺度7不同,只需跨1个尺度,对尺度3和尺度5进行特征提取。
2.2 联合池化特征融合
2.2.1 一阶二阶联合池化
经过多尺度自适应特征提取模块,输出不同尺度下得到的四维张量(H×W×C×M),式中,H表示空间的长,W表示空间的宽,C表示通道数,M表示特征图数量。将第三维和第四维进行连接,可转化为三维张量(H×W×K),其中K=C×M。然后,设置一个二维卷积层提取不同特征图的互补信息,并进入一阶二阶联合池化特征融合。
二阶统计量通常比一阶统计量包含更丰富的信息,但直接替换一阶统计量可能会丢失其独有的信息。因此,采用一阶二阶联合池化,通过平均池化(Avg Pooling)获得一阶统计量;通过快速协方差池化(Fast Covariance Pooling)获得二阶统计量。矩阵平方根归一化在计算协方差池化中起关键作用,现有计算矩阵平方根的方法,在很大程度上依赖于特征分解EIG(Eigen decomposition)或奇异值分解SVD(Singular Value Decomposition),这些方法在GPU 上的运算效率有待进一步提升。为了实现快速计算,本文采用了一种基于牛顿舒尔茨迭代的快速协方差池化,设计了具有循环嵌入有向图结构的元层来计算协方差矩阵的近似平方根。基于牛顿舒尔茨迭代的快速协方差池化,只涉及GPU 友好的矩阵乘法,使网络在GPU 上可以高效运行。
如图3 所示,输入的特征图是大小为(H×W×K)的三维张量。第1 步将三维张量重塑为特征矩阵X∈RK×N,其中N=H×W,每一个列向量代表空间中对应位置的通道信息。第2 步利用特征矩阵X计算得到协方差矩阵Σ,计算公式如下:
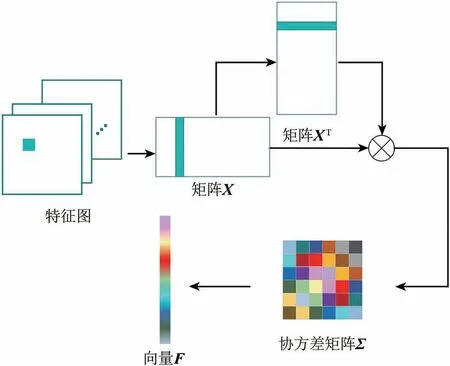
图3 快速协方差池化结构Fig.3 The structure of Fast Covariance Pooling
采用具有循环嵌入的有向图结构,计算协方差矩阵Y的近似平方根,包含预归一化、牛顿舒尔茨迭代和后补偿3个结构层。
第1层:预归一化。通过除以协方差矩阵的迹或F-范数,保证第2 层牛顿舒尔茨迭代的收敛性。具体处理公式如下:
第2层:牛顿舒尔茨迭代。更新牛顿舒尔茨迭代中涉及的耦合矩阵方程,用于计算近似矩阵平方根。具体来说,为计算A的矩阵平方根Y,给定Y0=A和Z0=I,其中K=1,2,…,N。耦合迭代形式如下:
式中,plm和qlm是多项式,l和m是非负整数。式(7)满足局部收敛,即:如果‖A-I‖<1,则Yk和Zk收敛到Y和Y-1。当l=0,m=1 时,称为牛顿舒尔茨迭代,不涉及GPU不友好的矩阵逆的计算:
第3层:后补偿。由于预归一化处理会降低数据的数量级,因此设计后补偿,通过乘以协方差矩阵的迹或F-范数进行数据还原:
通过上述结构输出的结果是一个对称矩阵,第3步对矩阵的上三角进行向量化,得到最终快速协方差池化的结果向量F,维数为K(K+1)/2。
2.2.2 池化特征融合
不同尺度得到的池化特征需进行融合得到最终的特征,从而用于分类。如果直接采用串联连接或相加的方式融合,意味着网络对不同池化特征向量的每个维度同等关注。为此突出不同特征之间的差异性,本文设计了池化特征融合模块。
以快速协方差池化为例。首先,拼接3个尺度对应的快速协方差特征向量vCP∈RK×1,得到特征向量VCP∈R3K×1。接下来,为减少冗余信息,利用线性函数对特征向量VCP降维,得到与融合前维数相同的融合协方差池化向量V'CP∈RK×1。最后使用归一化指数函数Softmax 计算每个维度的权重向量θ,用以强化特征。类似地,平均池化通过相同的操作得到融合平均池化向量V'Avg。据此,给出融合向量E'的形式:
式中,θ表示池化特征向量对应的权重向量,能够反映每个元素的重要程度。由于池化特征融合模块位于模型的深层,为避免梯度消失问题,采用残差连接,将池化融合特征向量E'与原始特征融合。具体形式如下:
最终将得到的融合向量E送入全连接层,得到分类结果。
3 结果与分析
3.1 实验数据
(1)Indian Pines(IP)数据集。利用AVIRIS传感器于1992 年6 月获取的印第安纳州西北部印第安松树试验场的高光谱分辨率影像。影像大小为145像素×145像素。传感器的空间分辨率为20 m,波长范围400—2500 nm;共包含220个波段。剔除104—108、150—163、220 这20 个坏波段,余下200 个波段用于分类。影像共标注地物类别16 类,主要以森林、植物和农作物为主。影像伪彩色合成图像和类别标记图如图4所示。每类按比例随机选取5%的样本作为训练集,其余作为测试集,具体信息见表1,其中训练集和测试集样本总数分别为512和9737。
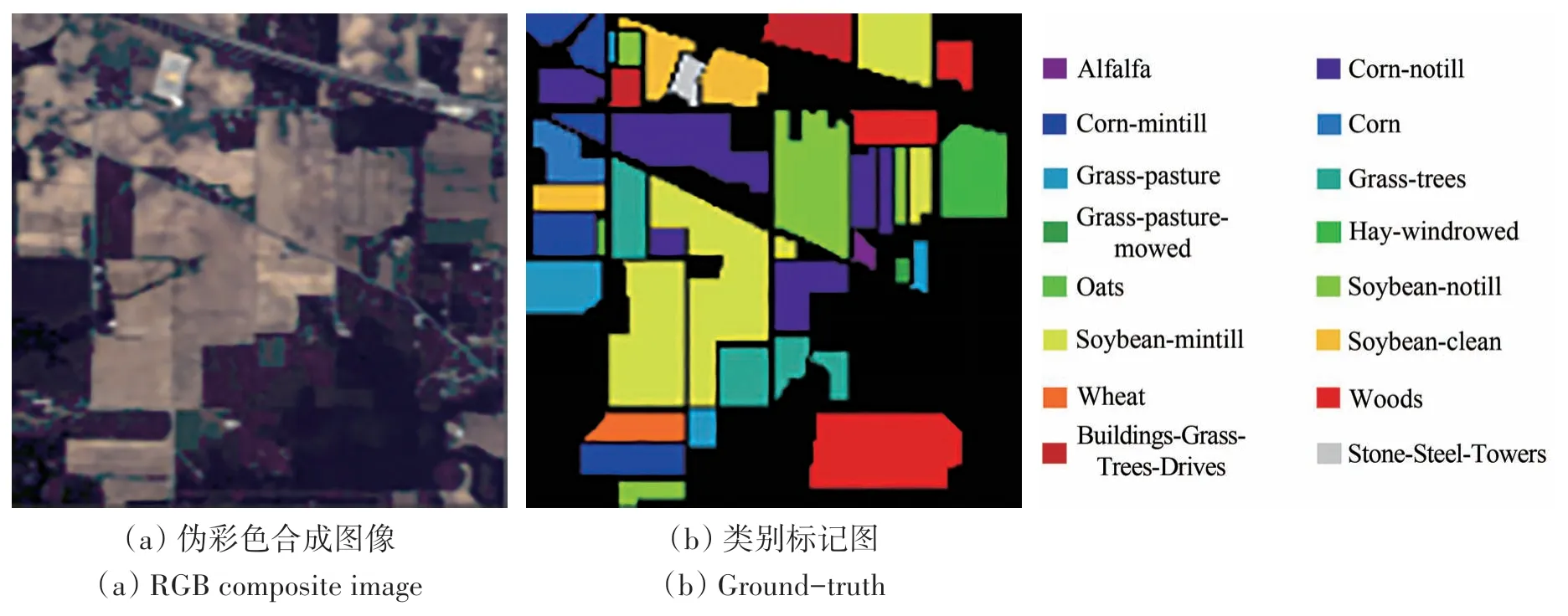
图4 Indian Pines高光谱图像数据Fig.4 Indian Pines Hyperspectral image
(2)Houston(HU)数据集。利用ITRES CASI-1500 传感器于2013 年获取的休斯顿大学校园和邻近城市地区的高光谱影像。该影像大小为349×1905 像素,传感器的空间分辨率为2.5 m,波长范围380—1050 nm;包含144个波段。影像共标注地物类别15 类,主要以植被、住宅为主。影像伪彩色合成图像和类别标记图如图5所示。每类按比例随机选取5%的样本作为训练集,其余作为测试集,具体信息见表2,其中训练集和测试集样本总数分别为751和14278。

表2 Houston数据训练集和测试集Table 2 Training and testing sets of Houston data

图5 Houston高光谱图像数据Fig.5 Houston Hyperspectral image data
(3)Pavia University(PU)数据集:利用ROSIS 传感器于2003 年获取的意大利北部帕维亚大学的高光谱影像。影像大小为610×340像素。传感器的空间分辨率为1.3 m,波长范围430—860 nm。剔除12 个受噪声影响的波段,余下103 个波段用于分类。影像共标注地物类别9类,主要以树、沥青为主。影像如图6 所示。每类按比例随机选取1%的样本作为训练集,其余作为测试集,具体信息见表3,其中训练集和测试集样本总数分别为427和42349。

表3 Pavia University数据训练集和测试集Table 3 Training and testing sets of Pavia University data

图6 Pavia University高光谱图像数据Fig.6 Pavia University Hyperspectral image data
3.2 对比算法与实验设置
本文所提出的结合协方差池化和跨尺度特征提取的高光谱分类算法与下面采用的主流算法进行对比实验:
(1)SVM(Support Vector Machine):支持向量机;
(2)2D-CNN(2D-Convolutional Neural Networks):二维卷积神经网络分类算法(Makantasis 等,2015);
(3)HybirdSN(Hybrid Spectral-Net):结合3D-CNN和2D-CNN提取空间和光谱信息(Roy等,2020);
(4)SSRN(Spectral-Spatial Residual Network):光谱—空间残差网络(Zhong等,2018);
(5)A2S2KResNet(Attention Based Adaptive Spectral Spatial Kernel ResNet):基于注意力机制和空间光谱核学习的残差网络(Roy等,2020);
(6)A-SPN(Attention-Based Second-Order Pooling Network):基于注意力的二阶池化网络(Xue等,2021);
(7)MCNN-CP(Mixed Convolutions and Covariance Pooling):协方差池化的混合CNN 卷积(Zheng 等,2021)。
本文算法实验结果为随机选取训练样本重复运行10 次的平均值。分类性能评价指标为总体分类准确率OA(Overall Accuracy),平均分类准确率AA(Average Accuracy)和Kappa系数K。
本文实验基于Pytorch 深度学习框架,在配备2.7 GHz Intel Xeon Gold 6258R CPU 和2 块NVIDIA GeForce RTX 2080 Ti GPU 的计算机上完成。为减少网络运算开销,首先通过PCA 将高光谱数据降维至30维,然后投入网络。对于本文提出的方法,使用Adam 优化器,初始学习率为0.001,迭代次数为50,批次训练集大小为16。所有对比算法的参数设置与其原文保持一致。表4列出了各算法的具体参数设置,包括窗口大小、批次大小和学习率等。可见:由于网络特性不同,各算法参数有一定差异,其中窗口大小最大为25 最小为7;批次大小基本不固定;学习率常设为0.001。

表4 各算法参数设置Table 4 Parameter setting of each algorithm
3.3 实验结果
(1)Indian Pines 数据实验结果。Indian Pines数据不同算法的分类精度如表5所示。不同算法的分类结果如图7所示。可知只使用光谱特征的SVM算法和2D-CNN 算法的分类图中有明显的椒盐噪声。分类图左上角16 和12 类部分容易出现错分,在此部分本文算法分类结果基本正确。由表5可知与其他对比算法相比,本文算法效果最佳,在不同分类指标上有明显提升。其中,2—4 类是大豆子类、10—12类是玉米子类,同一子类的类间相似度高不易区分。本文算法与对比算法相比具有更高的鉴别能力,在第3、4、11、12类中取得最优分类性能,在第2、10类中取得次优分类性能。第7、9类样本数少,其中第9 类取得最好分类准确率,第7类取得次优分类准确率,说明本文算法在小样本分类中也有不错效果。同样采用多尺度思想的MCNN-CP 算法的OA、AA 和K分别为96.033%、89.627%和95.473%,而本文算法得到的结果可以达到97.630%、95.517%和97.296%,总体分类准确率提高了1.6%。与MCNN-CP相比,本文所提出的跨尺度特征融合,具有较好的特征学习能力。
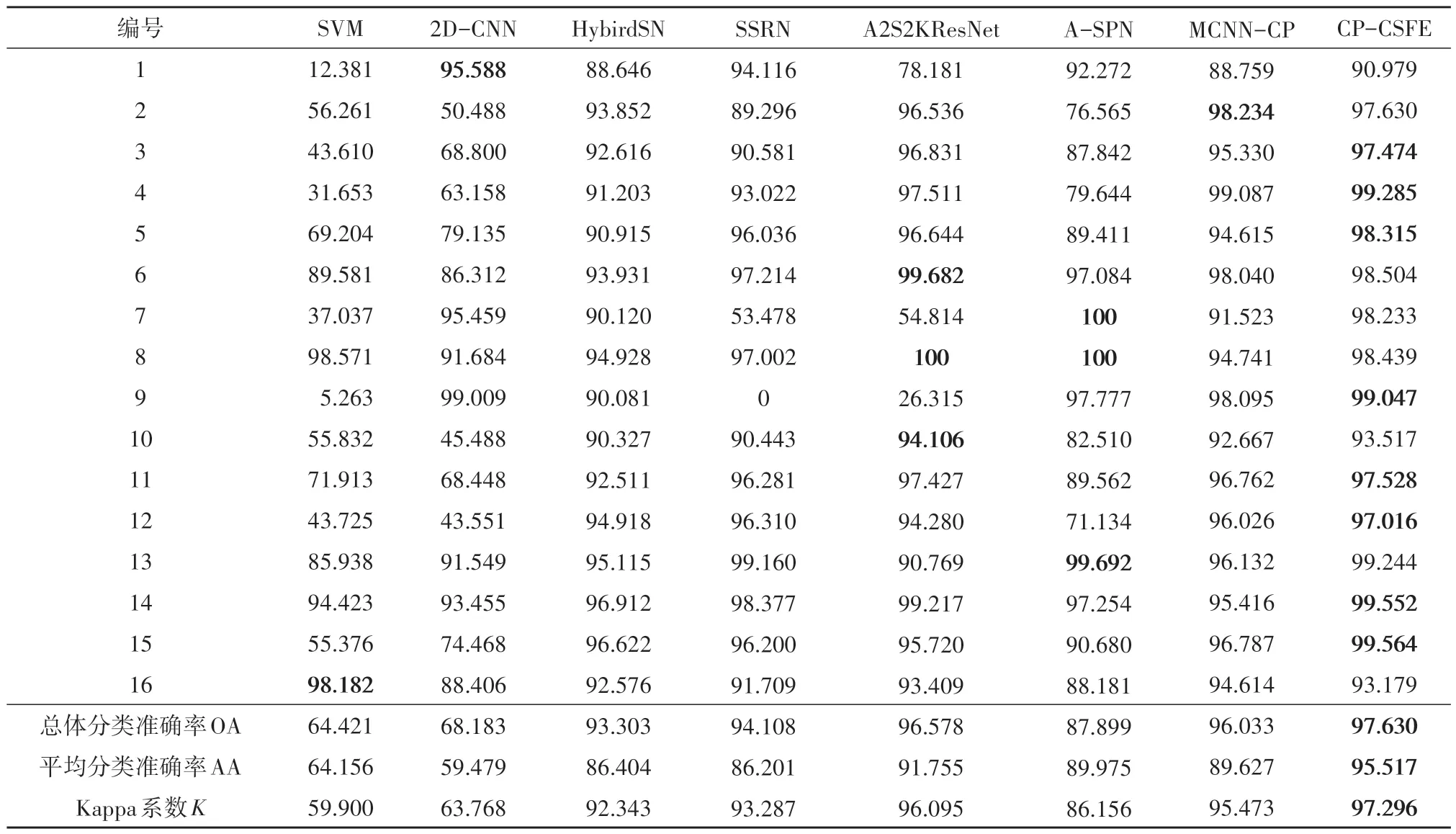
表5 Indian Pines数据不同算法的分类精度Table 5 Classification results of different methods on the Indian Pines data /%

图7 IP数据分类结果(RGB composite image指伪彩色合成图像;Ground-truth指类别标记图)Fig.7 IP data classification maps
(2)Houston数据实验结果。Houston数据集不同算法的分类精度见表6。可见使用5%数据训练,本文算法的OA、AA和K分别达到98.482%,98.473%和98.359%,该结果比对比算法相比分类效果有所提升。同时,在合成草、土壤、水、贸易区、公路、铁路、停车场1 和网球场8 个地物类别中分类准确率高于99%。在第6—12类中达到所列算法里的最高分类精度。观察HU 数据分类结果图图8,可见本文方法的分类结果更接近地面的真实值。

表6 Houston数据集不同算法的分类精度Table 6 Classification results of different methods on the Houston data /%

图8 HU数据分类结果Fig.8 HU data classification results
(3)Pavia University 数据实验结果。图9 为不同算法的分类结果图,从分类图上可以观察到,只使用光谱信息的SVM、2D-CNN算法有明显的椒盐噪声。浅蓝色是第3 类沙砾,红色是第8 类砖块,这2类极易相互混淆错分,本文算法混淆情况很少。Pavia University 数据集不同算法的分类精度测算结果见表7。可知:在使用1%标记样本进行训练时,本文算法得到的OA、AA和K结果可以达到98.211%、96.211%和97.626%,与其他算法相比具有更好的分类性能其中2 类地物的分类OA 高于99%,3类地物的分类OA高于97%。7种方法对第8 类是砖块的分类精度不高,错分的情况比较多,本文提出的方法取得了最好的结果,与采用二阶统计量的A-SPN算法相比,提高5%以上。

表7 Pavia University数据集不同算法的分类精度Table 7 Classification results of different methods on the Pavia University data /%

图9 PU数据分类结果Fig.9 HU data classification maps
3.4 参数分析及消融实验
3.4.1 参数敏感性分析
采用参数敏感性实验,分别观察窗口大小、批次大小以及学习率对算法分类精度的影响。为分析窗口大小对OA 的影响,设置窗口大小范围为{7×7,9×9,11×11,13×13,15×15,17×17,19×19},结果见图10。可见:OA 随窗口增大呈上升趋势,窗口大小取15 时效果最好。对于批次大小,图中结果显示批次大小对OA 影响不大,批次大小选定为16 时效果相对更好,因此在实验过程中选定批次大小为16。为分析学习率对算法的影响,设置学习率取值范围为{0.0001,0.001,0.003,0.01,0.03},在3 个数据集上OA 均随学习率增加而减小。当学习率取0.001 时达到最好分类效果,因此在实验过程中,设学习率为0.001。
3.4.2 快速协方差池化
为验证从光谱特征图中提取的二阶统计量对分类精度提升有效,将本文算法和只含平均池化的网络和只含快速协方差池化的网络进行比较,实验结果如表8。可见:在3 个数据集上,只含平均池化的网络和只含快速协方差池化的网络的总体分类准确率均低于一阶二阶联合池化的算法。结果表明快速协方差池化所提供的二阶统计量可能提供了更丰富的高阶信息,有助于分类准确率的提升;一阶池化所提供的一阶统计量也能提供特定特征。合理结合一阶二阶统计量能提升分类精度。

表8 有或无快速协方差池化的分类精度Table 8 Overall accuracy values with/without fast covariance pooling /%
3.4.3 多尺度特征提取
为验证多尺度特征提取可以获得更具有鉴别能力的特征,从而提升分类精度,将多尺度特征提取相关实验结果展示如表9。可见:只采用单尺度时,不存在跨尺度特征提取,联合池化部分只有单尺度下的一阶统计量和二阶统计量,故无需池化特征融合模块,直接将2 种池化结果拼接即可;采用2 种尺度时,CSAF 模块只需使用一次,利用自适应参数进行跨尺度特征提取。后续的池化特征融合模块对2 个尺度下的池化结果进行融合;在印第安松树试验场IP、休斯顿大学校园和临近城市地区HU和意大利北部帕维亚大学PU这3个数据集上,跨尺度特征提取的网络总体分类准确率最高。这说明多尺度特征提取模块能有效聚合3种尺度下不同互补信息,产生更具判别性特征。

表9 有或无多尺度特征提取的分类精度Table 9 Overall accuracy values with/without multiscale feature extraction /%
3.4.4 样本泛化性实验
针对3个数据集,观察不同的训练样本量对算法分类结果的影响,测试不同算法的泛化能力,结果见表10。可见:随着训练样本数量的增加,算法整体精度提高,本文算法在小样本情况下也取得较好的分类效果,达到最高分类精度;本文算法在IP 数据集上,用1%数据做训练样本OA 到达84.68%,使用10%数据做训练样本,则可以到达99.17%;PU 数据空间分辨率高,仅使用0.5%的样本数据总体分类精度也能达到95.97%;对于HU数据集,本文算法的分类效果在1%、5%、10%的训练样本比例上都优于其他算法。

表10 样本泛化性实验Table 10 Sample generalization experiment
3.4.5 算法运算效率对比
为比较算法运算效率,各算法的网络参数量、每轮次训练时间、测试时间的结果的对比如表11所示。可见多尺度会带来更多参数,相比于其他算法计算时间更长。其中:MCNN-CP 和CP-CSFE网络采用多尺度特征提取,相比于SSRN、A-SPN、A2S2KResNet 算法具有更多的参数量;从训练和测试时间来看,本文CP-CSFE 算法训练时间比HybirdSN和A2S2KResNet稍慢,但明显优于A-SPN和MCNN-CP 等算法。综合来看,本文算法在保证分类性能较优的情况下,并未显著增加计算时间,整体训练时长仍在可接受范围内。

表11 各算法运算效率对比Table 11 Comparison of Calculation efficiency of each algorithm
4 结论
为了充分提取空间和光谱信息,以获得更好的分类性能,本文中提出一种用于HSI分类的结合协方差池化和跨尺度特征提取的算法,主要结论如下:(1)该模型跨越3个尺度进行空谱信息的选择和提取,调节不同尺度映射特征图的重要性,得到更具适应性互补特征;(2)引入快速协方差池化,提出联合池化和池化特征融合策略学习到更具判别性特征提高了分类性能;(3)本文提出的算法分类结果优于本文采用的其他7种主流对比算法。
通过实验发现,多尺度特征融合在提升分类性能的同时带来更多的网络参数,导数训练时间增加。深入研究应结合高光谱图像的数据特性,进一步优化多尺度组合方式,并且应考虑如何减少网络参数构建轻量化网络,在保证分类性能的同时,提高计算效率。
