基于改进YOLOX 的自然环境下核桃识别算法研究
2024-03-09钟正扬云利军杨璇玺陈载清
钟正扬,云利军,杨璇玺,陈载清
(1.云南师范大学信息学院,云南 昆明 650500;2.云南省教育厅计算机视觉与智能控制技术工程研究中心,云南 昆明 650500;3.云南省林业调查规划院生态分院卫星林业应用中心,云南 昆明 650500)
核桃作为云南省第一大木本经济作物,截至2020 年底,全省种植面积达28 670 km2[1],产业综合产值412.36 亿元,核桃种植已经成为广大群众增收致富的重要产业。传统的人工采摘方式耗时长、效率低,且伴有一定危险性,不能很好地满足当下采摘需求,使用机器人代替人工进行核桃采摘作业是未来的发展趋势。核桃的识别作为自动化采摘的首要任务,其识别精度将直接影响采摘的效果。因此,高精度、高速度的核桃识别方法对采摘工作至关重要。针对近背景色果实识别问题,国内外研究学者提出了很多解决方法。袁国勇等[2]提出利用黄瓜果实与果梗叶片在颜色深度上的差异,分别提取RGB 颜色分量信息,采用Bayes 分类判别模型进行果实的判别并达到73%以上的分割正确率。袁挺等[3]提出利用黄瓜果实、茎、叶在各光谱波段的分光反射特性来区分近色系目标和背景,并利用果实的灰度特征,使用P参数阈值法进行图像分割,对黄瓜果实的识别准确率为83.3%。章云等[4]提出利用2R-G-B 色差模型将核桃从背景中提取出来,采用最佳阈值函数进行图像分割,最后经形态学滤波后采用Canny 算子进行边缘检测,对山核桃果实的有效识别率可达86.7%。传统机器视觉方法虽然可以基本实现果实识别,但太过于依赖工程师对图片中重要特征的提取,不仅需要长时间的调试和误差处理,在复杂场景下的准确率也明显下降。卷积神经网络(CNN)在目标检测领域的异军突起,为实现高精度、高速率的果实识别提供了新方法。樊湘鹏等[5]提出在Faster R-CNN 模型框架下使用VGG16特征提取器并加入批归一化处理和感兴趣区域校准算法,对核桃园林中青皮核桃识别与定位的平均精确率为97.56%;王梁等[6]提出一种基于Mask-RCNN 的自然场景下油茶果目标与检测算法,对油茶果目标识别的平均检测精度为89.42%;郝建军等[7]在YOLOv3 模型的基础上,使用Mobile Net-V3作为骨干网络,并辅以预训练模型、锚框缩放调整以及Mixup 数据增强等方法,对青皮核桃平均检测精度可达94.52%。现有的目标检测网络多以串行的方式不断对特征图进行下采样以增大感受野,图片中的小目标由于所占像素较少,特征信息随着网络层数的加深而逐渐丢失,影响了网络对小目标检测的准确度。本研究利用多层特征融合模块将Swin Transformer 提取的特征信息与主干网络的特征图进行特征融合,以减少小目标特征信息的丢失。在此基础上引入Repblock 模块和Transition Block 模块进一步提升模型的整体性能,最终获得一个检测精度高、速度快且参数量适中的核桃检测算法。
1 材料和方法
1.1 数据采集
试验所需核桃图像采集于云南省凤庆县正义村核桃示范点,采集时间为2022 年9 月2 日。采集设备为大疆Phantom 4 Pro 无人机,无人机镜头有效像素为2 000 万,利用无人机在自然光照条件下对多棵山核桃树上的成熟待采摘果实进行多角度环绕拍摄,无人机镜头距离核桃1~2 m。采集到的图像尺寸为5 472 像素×3 648 像素(宽高比为3∶2),共采集图像1 471 张,包括顺光、逆光、密集小目标、遮挡等多种果实场景,图像存储格式为JPG。
1.2 数据预处理
无人机环绕拍摄过程中会产生一定数量的重复图片,为了降低这部分图片对模型训练的干扰,通过人工筛选的方式将这部分图片筛选出来并进行删除。由于无人机原始拍摄图像分辨率为5 472像素×3 648 像素,远大于正常深度学习训练图像的大小,因此按照原始图像的宽高比(3∶2)对原始图像进行裁剪,裁剪后的图像大小为684 像素×456 像素,人工筛选出不清晰图片以及不包含核桃图片并进行删除,最终得到包含核桃果实图片2 680 张。对数据集图片按照9∶1的比例随机划分训练验证数据和测试数据,并将训练验证数据按照9∶1 的比例随机划分训练数据和验证数据,最终得到训练集图片2 170 张、验证集图片242 张及测试集图片268张。选择LabelImg 软件作为数据集标注软件,采取人工标注的方式按照PASCAL VOC2007 的标准对数据集中核桃果实进行框选,对遮挡面积超过核桃60%的核桃不作标注,同时针对少数遮挡面积百分比不明确的情况,在标注时会结合LabelImg 软件提供的核桃边界坐标对遮挡面积进行判定。标注信息包含目标框的位置坐标以及类别信息,存储为xml格式,共标记核桃样本10 173个。
1.3 相关算法
1.3.1 YOLOX-S 算法 目前,目标检测算法主要分为以Faster R-CNN[8]为代表的Two-Stage 目标检测算法及以YOLO 和SSD[9]为代表的One-Stage 目标检测算法。YOLOX 算法[10]由旷视科技研究院于2021 年提出,共有5 种标准模型,YOLOX-S 在保持高性能、高实时性的同时相较于其他标准模型更具轻量化,利于部署到计算资源有限的移动设备或边缘设备上,其网络结构如图1 所示。YOLOX-S 的输入端在采用了和YOLOv5 一样的Mosaic[11]数据增强的基础上,还引入了一种额外的增强策略Mixup[12]对图片进行预处理,高效的数据增强方式使得模型在无预训练权重的情况下依旧有较好的检测效果。在主干网络和颈部2 个部分,沿用了YOLOv5 的CSPDarknet 结构及PANet 结构[13],不同的是,在YOLOX-S 中采用了SiLU 函数替代LeakyReLU 函数作为激活函数。在头部部分,YOLOX-S 使用Decoupled Head 作为检测部分并采用了Achor free、Multi positives 和SimOTA 的方式对颈部输出的3 个尺度的特征图进行检测。

图1 YOLOX-S网络结构Fig.1 Network structure diagram of YOLOX-S
1.3.2 Swin Transformer 算法 Swin Transformer 由LIU 等[14]提出,是一种采用滑动窗口机制和层次结构的Transformer 网络。Swin Transformer 网络结构分为图像处理、Swin Transformer Stage 2 个部分,其网络结构如图2所示。

图2 Swin Transformer网络结构Fig.2 Network structure of Swin Transformer
图像处理部分通过Patch Partition 层实现,输入的像素分辨率图像先经过Patch Partition 转化为Patches 分辨率图像。Swin Transformer Stage 部分包括 4 个 Stage,由 Linear Embedding 层、Swin Transformer Block 层和Patch Merging 层组成。除第1 个Stage 由Linear Embedding 层和Swin Transformer Block 层组成外,其余的均由Patch Merging 层和Swin Transformer Block 层组成。Linear Embedding层主要实现的是Patches分辨率图像维度的变换,即转换为所需要的维度。Patch Merging 层类似于CSPdarknet 中的Focus 层,作用是使图像的分辨率减半,通道数加倍,从而在Transformer 中实现层次结构。在Swin Transformer 中,Swin Transformer Block 都是成对出现的,由窗口多头注意力(Windows multi-head self-attention,W-MSA)和滑动窗口多头注意力(Shifted windows multi-head self-attention,SW-MSA)组成,如图3所示。

图3 Swin Transformer Block结构Fig.3 Swin Transformer Block structure
1.4 核桃识别算法
基于YOLOX-S 算法,本研究在主干特征提取网络中引入基于Swin Transformer 的多层特征融合模块(Multi-layer feature fusion with swin transformer,MFFWS),通过Swin Transformer 特有的多头注意力机制对核桃特征进行提取,并与主干特征提取网络中得到的特征图进行特征融合,引入Repblock 模块代替原有的CSP 模块并使用Transition Block 模块进行主干部分的下采样操作,改进后的网络结构如图4所示。
1.4.1 引入基于Swin Transformer 的多层特征融合模块 YOLOX-S 使用CSPDarknet 结构作为主干特征提取网络,以串行的方式不断对特征图进行下采样以增大感受野。但图片中的小目标本身所占像素较少,随着网络层数的不断加深,特征信息逐渐丢失,使得高层特征图中小目标的特征信息越来越少,影响了小目标检测的准确度。特征金字塔网络(Feature pyramid network,FPN)[15]中通过将低层高分辨率的特征图与高层强语义的特征图进行特征融合,即Concat 操作,提高了对小目标的识别性能。因此,基于FPN 的思想设计了结合Swin Transformer的多层特征融合模块,用于替换YOLOX-S 主干特征提取网络中的CSP模块,其具体结构如图5所示。

图5 多层特征融合模块结构Fig.5 Structure of multi-layer feature fusion module
MFFWS 模块的总体结构借鉴了ResNet[16]中残差结构的思想。MFFWS 模块共有2个输入,分别对应Backbone 中有效特征层的输入和经过修改的Swin Transformer 的输出,经过修改后的Swin Transformer 结构如图6 所示。修改后的Swin Tansformer 只保留了3 个Stage,并且为了减少计算量,每个Stage 中的Swin Transformer Block 的数量均设为2。整个网络共有3个输出,分别与CSPDarknet中的3 个有效特征层一一对应。如图5 所示,来自Backbone 中有效特征层的输入流会通过1个CBS模块来实现下采样,下采样后的特征图会被划分为两部分。其中第一部分的特征图会通过切片操作将特征图的维度一分为二,为减少运算量,仅其中1个分割特征图会通过CSP 模块提取更多的语义特征,另1个分割特征图参照残差结构的设计思想与通过CSP 模块的分割特征图进行跳跃连接,得到第1 个分支的特征图;而第二部分的特征图仅会通过1 个卷积核大小为1×1、步长为1 的卷积进行通道的压缩。最后,来自Swin Transformer 的输入流会通过1个卷积核为1×1、步长为1 的卷积进行通道的压缩,并和第二部分的特征图进行堆叠作为第2 个分支的特征图。将2 个分支的特征图进行堆叠,经过1 个卷积核大小为1×1、步长为1 的卷积进行通道的压缩并作为最终的输出。
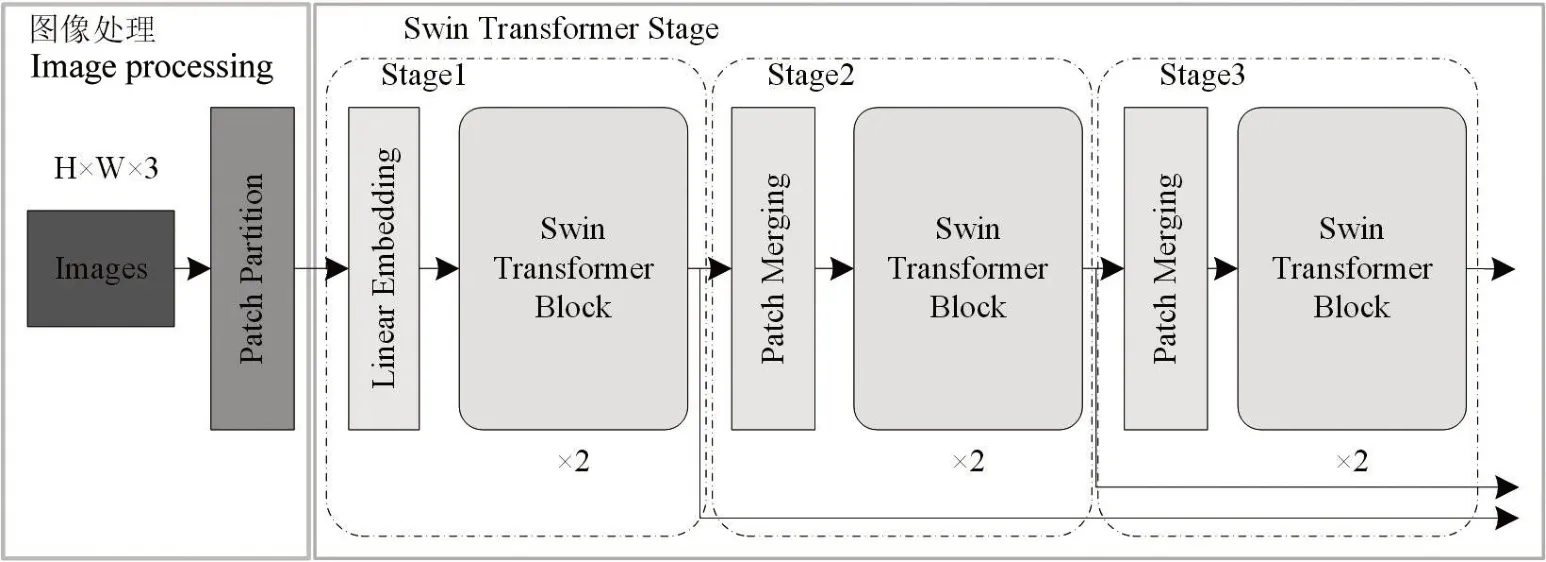
图6 修改后Swin Transformer网络结构Fig.6 Modified Swin Transformer structure
1.4.2 Repblock 模块 Repblock 模块于YOLOv6[17]中被提出,相较于CSP 中的CBS 卷积模块,在Repblock 中使用RepVGG 作为卷积模块。如图7 所示,Repblock由1个RepVGG模块和RepVGG Unit模块组成。其中RepVGG Unit 模块由X 个RepVGG 模块组成。

图7 Repblock模块结构Fig.7 Repblock module structure
RepVGG 模块取自于RepVGG[18]网络,其基本思想就是在进行网络训练时引入特殊的残差结构进行辅助训练。如图8 所示,共有3 个分支,第1 个分支为1 个卷积核大小为3×3、步长为1 的卷积加1 个批归一化层;第2 个分支为1 个卷积核大小为1×1、步长为1的卷积加1个批归一化层;第3个分支当且仅当输入通道等于输出通道时才有效,由1 个批归一化层组成。3 个分支的结果会进行相加并经过SiLU 激活函数作为最终的输出。而在预测时,则将这个残差结构等效于一个普通的3×3卷积以降低网络的复杂度。1.4.3 Transition Block 模块 Transition Block 模块取自YOLOv7[19],常用的下采样方式为步长为2的最大池化或卷积核大小为3×3、步长为2 的卷积。Transition Block 模块对这2 种方式进行了整合,其中1 个分支为1 个步长为2 的最大池化加1 个卷积核大小为1×1、步长为1 的卷积,另1 个分支为1 个卷积核大小为1×1、步长为1的卷积加1个卷积核大小为3×3、步长为2 的卷积,2 个分支的结果会进行堆叠并作为最终的输出,从而在实现下采样的同时完成了通道数的翻倍。其结构如图9所示。

图8 RepVGG结构Fig.8 RepVGG structure

图9 Transition Block模块结构Fig.9 Transition Block module structure
1.5 试验环境
试验在基于Python 语言和PyTorch 框架搭建的深度学习环境下进行算法的训练和测试,具体试验环境如表1所示。

表1 试验环境配置Tab.1 Experimental environment configuration
1.6 训练参数设置
迭代轮次(Epoch)的值设为300,批训练大小(Batch_size)设置为2。使用SGD 优化器对学习率进行优化,优化器使用的动量参数值设置为0.937,优化器权重衰减值设为5e-4。初始学习率设为5e-5,最大学习率和最小学习率分别设为5e-4和5e-6,使用线性学习率热身优化策略在前4个迭代轮次线性增加到最大学习率,在达到最大学习率后使用余弦退火衰减策略[20]来降低学习率,最后15 个迭代轮次将学习率设为最小学习率,具体学习率变化曲线如图10所示。为了增强图像的多样性,在训练前对训练集进行随机数据增强,随机数据增强的方式包括随机缩放、翻转和色域变换。前210 迭代轮次还会对训练集随机进行Mosaic 数据增强,其中Mosaic 增强的概率设为50%,在进行Mosaic 增强的前提下有50%的概率会再进行Mixup数据增强。数据增强后会将图像按照原先宽高比缩放为640 像素×640 像素,并更新预测框的位置信息,图像多余部分会添加灰度条。

图10 学习率变化曲线Fig.10 Learning rate variation curve
1.7 评价指标
使用训练得到的权重对测试集进行评估,评价指标包括精准率(Precision,P)、召回率(Recall,R)、平均精度(Average precision,AP)以及每秒识别图像数量(Frames per second,FPS)。精准率、召回率和平均精度的计算表达式如公式(1)—(3)所示:
式中,TP为正样本被正确识别的数量,即被正确识别的核桃数量;FP为负样本被误检为正样本的数量,即背景被误检为核桃的数量;TN为负样本被正确识别的数量,即被正确识别出是背景的数量;FN为未被检测出的正样本数量,即未被正确识别的核桃数量。
平均精度包括AP50 和AP 2 种,均采用Pascal VOC2012 的方式计算,AP50 表示IOU 的值取0.5 时的平均精度;AP 表示IOU 的值从0.5 取到0.95 且步长为0.05时的平均精度。
2 结果与分析
2.1 不同网络模型对比
将改进后的YOLOX-S(Improved YOLOX-S)与当前部分主流算法进行性能对比。为了更直观地比较不同网络模型在训练过程中的检测效果,每间隔50 轮选取最好的平均精度AP50 值进行绘图,不同网络模型在测试集上的平均精度AP50 值如图11所示,具体数据如表2 所示。从表2 可以看出,与Faster R-CNN 相比,YOLO 系列的算法拥有更高的平均精确度、更小计算量以及更快的检测速度,由此可见,YOLO 系列的目标检测算法更适合于自然环境下核桃的识别;与原始的YOLOX-S 相比,改进后的YOLOX-S 算法在AP50 和AP 上分别提升了0.62、0.55 百分点,但由于改进后的YOLOX-S 算法在主干特征提取网络中添加了Swin Transformer 模块,在检测速度上有一定的下降,检测速度为46 f∕s。

表2 不同网络模型比较结果Tab.2 Comparision results of different network models

图11 不同网络模型测试结果Fig.11 Test results of different network models
2.2 消融试验结果
为了验证本研究改进的每一个部分对模型性能的提升效果,在保证配置环境及初始训练参数一致的情况下,使用YOLOX-S 作为基线模型进行消融试验,逐步添加各个改进方法,消融试验共设4组(表3),第1组为原始YOLOX-S算法(G1);第2组为在主干特征提取网络添加多层特征融合模块(G2);第3 组是在第2 组的基础上将CSP 模块更换为Repblock 模块(G3);第4 组是在第3 组的基础上使用Transition Block 完成主干特征提取网络部分的下采样(G4)。

表3 消融试验结果对比Tab.3 Comparison of ablation test results
从表3 可以看出,与G1 相比,G2 在主干特征提取网络中添加MFFWS 模块,AP50 提高了0.32 百分点,这是因为核桃大小不一,较小核桃的特征信息随着网络层数的加深逐渐丢失,通过Swin Transformer 进行特征提取并进行特征融合可以使其特征信息在高层特征图得到保留,使网络对核桃的识别效果变好;但AP 却有所下降,这主要是因为其在IOU 阈值大于0.75 时的平均精确率过低,说明加入MFFWS 模块使得模型对难以定位物体检测效果不佳。与G2 相比,G3 的AP50 提高了0.21 百分点,AP 提高了0.94 百分点,说明加入Repblock 模块进一步提高了模型对于难以定位物体的检测效果。与G3 相比,G4 的AP50 提高了0.09 百分点,参数量减少了1.76 M,说明使用Transition Block 可以提高精度同时还可以有效减少参数量。
2.3 可视化结果分析
改进后的YOLOX-S 算法和YOLOX-S 检测结果的对比图如图12所示,改进后的YOLOX-S算法有效提升了被遮挡环境下核桃的识别效果(图12C1);对于近背景色的核桃目标,YOLOX-S 算法存在大量漏检情况,而改进后的YOLOX-S 算法可以检测出部分目标(图12C2);如图12B3、C3 所示,由于光照导致部分树叶颜色与核桃一致,YOLOX-S 算法错误地将其识别为核桃目标,而改进后的YOLOXS 算法通过添加多层特征融合模块,加强了网络对小目标特征信息的学习,可以最大限度地减少背景的负面影响,从而降低误检率。改进后的YOLOXS 算法相比原始YOLOX-S 对核桃具有更好的检测效果。

图12 YOLOX-S改进前后检测结果对比Fig.12 Comparison of detection results before and after YOLOX-S improvement
3 结论与讨论
针对核桃体积小且与背景色相似情况,本研究提出了一种基于改进YOLOX 的自然环境下核桃识别算法。首先,在主干特征提取网络中加入多层特征融合模块,通过Swin Transformer 特殊的多头注意力机制提取出不同特征图下的核桃语义信息,并将提取到的语义信息与CSPDarknet 中的特征图进行融合,改善了原高层特征图中小目标信息较少的问题,在提升模型检测精度的同时降低检测目标的误检率;其次,将CSP 模块替换为Repblock 模块,提升了模型对难以定位物体的检测效果;最后,引入Transition Block 模块,将池化和卷积2 种下采样方式结合,进一步提高网络的检测精度,减少参数量。结果表明,相较于其他模型,使用改进后的YOLOX-S 算法可以改善核桃识别中漏检和误检情况,对于核桃的识别有着更好的表现,AP50 达到了96.72%。
目前,对于自然环境下的核桃识别依旧存在许多不足,其中最艰巨的挑战是核桃的遮挡问题。尽管本研究提出的方法在识别遮挡核桃方面取得了一定的改进,但仍需进一步提高算法的性能,以满足农业生产需要。此外,受光照影响,部分核桃呈现出与树叶相近的颜色,增加了算法区分它们的难度。后续会针对光照因素进行研究,寻找最佳的光照条件,从而避免光照因素所带来的干扰。最后,增加Swin Transformer 模块使模型在检测速度方面有一定的下降,还具有可提升的空间。在后续的研究工作中,将不断对算法进行优化,实现对核桃准确和快速识别的最终目标,为后续的核桃产业智能化提供良好的识别技术方案。
